
- 1linux中lvs命令详解,Linux集群LVS之一LVS类型详解
- 2FPGA AXI4总线信号介绍篇_axi4有哪些接口信号
- 3探索知识的未来,就用Globe.Engineer AI来开启新篇章,来试试_globe engineer
- 4SQL基础试题
- 5VUE学习笔记--vue-cli_vue-cli-service.js
- 6人工智能与数据安全
- 7前端文件上传及后端接收(el-upload标签的使用)_el upload上传文件,后端怎么接收
- 8自动化操作读写Excel —— xlrd 和 xlwt 模块参数说明与代码实战_xlrd xlwt
- 9elasticsearch filters特性
- 102024最新版Python安装详细教程!Python安装不用愁_安装python最新版
时间序列 - 论文笔记本_时间序列机器学习
赞
踩
前言:
关于时间序列:我做了很多摸索探究,这里做一个简单的总结记录
文章目录
预测质量评价指标
R 平方: 可决系数,取值范围为
[
0
,
+
∞
)
[0, +\infty)
[0,+∞) ,其值越大,表示拟合效果越好 调用接口为 sklearn.metrics.r2_score,计算公式如下:
R 2 = 1 − S S r e s S S t o t R^2 = 1 - \frac{SS_{res}}{SS_{tot}} R2=1−SStotSSres
平均绝对误差: 即所有单个观测值与算术平均值的偏差的绝对值的平均。这是一个可解释的指标,因为它与初始系列具有相同的计量单位。取值范围为
[
0
,
+
∞
)
[0, +\infty)
[0,+∞) ,调用接口为 sklearn.metrics.mean_absolute_error ,计算公式如下:
M A E = ∑ i = 1 n ∣ y i − y ^ i ∣ n MAE = \frac{\sum\limits_{i=1}^{n} |y_i - \hat{y}_i|}{n} MAE=ni=1∑n∣yi−y^i∣
中值绝对误差: 与平均绝对误差类似,即所有单个观测值与算术平均值的偏差的绝对值的中值。而且它对异常值是不敏感。取值范围为
[
0
,
+
∞
)
[0, +\infty)
[0,+∞) ,调用接口为 sklearn.metrics.median_absolute_error ,计算公式如下:
M
e
d
A
E
=
m
e
d
i
a
n
(
∣
y
1
−
y
^
1
∣
,
.
.
.
,
∣
y
n
−
y
^
n
∣
)
MedAE = median(|y_1 - \hat{y}_1|, ... , |y_n - \hat{y}_n|)
MedAE=median(∣y1−y^1∣,...,∣yn−y^n∣)
均方差:最常用的度量标准,对大偏差给予较高的惩罚,反之亦然,取值范围为
[
0
,
+
∞
)
[0, +\infty)
[0,+∞) ,调用接口为 sklearn.metrics.mean_squared_error ,计算公式如下:
M
S
E
=
1
n
∑
i
=
1
n
(
y
i
−
y
^
i
)
2
MSE = \frac{1}{n}\sum\limits_{i=1}^{n} (y_i - \hat{y}_i)^2
MSE=n1i=1∑n(yi−y^i)2
均方对数误差: 这个与均方差类似,通过对均方差取对数而得到。因此,该评价指标也更重视小偏差。这指标通常用在呈指数趋势的数据。取值范围为
[
0
,
+
∞
)
[0, +\infty)
[0,+∞) ,调用接口为 sklearn.metrics.mean_squared_log_error ,计算公式如下:
M
S
L
E
=
1
n
∑
i
=
1
n
(
l
o
g
(
1
+
y
i
)
−
l
o
g
(
1
+
y
^
i
)
)
2
MSLE = \frac{1}{n}\sum\limits_{i=1}^{n} (log(1+y_i) - log(1+\hat{y}_i))^2
MSLE=n1i=1∑n(log(1+yi)−log(1+y^i))2
平均绝对百分比误差:这与 MAE 相同,但是是以百分比计算的。取值范围为 [ 0 , + ∞ ) [0, +\infty) [0,+∞) ,计算公式如下: M A P E = 100 n ∑ i = 1 n ∣ y i − y ^ i ∣ y i MAPE = \frac{100}{n}\sum\limits_{i=1}^{n} \frac{|y_i - \hat{y}_i|}{y_i} MAPE=n100i=1∑nyi∣yi−y^i∣
平均绝对百分比误差的实现如下:
def mean_absolute_percentage_error(y_true, y_pred):
return np.mean(np.abs((y_true - y_pred) / y_true)) * 100
- 1
- 2
导入上述的评价指标:
from sklearn.metrics import (mean_absolute_error, mean_squared_error,
mean_squared_log_error, median_absolute_error,
r2_score)
- 1
- 2
- 3
差分
为什么要差分?
自回归模型在概念上类似于线性回归,后者所做的假设在这里也成立。
时间序列数据必须是静止的,以消除与过去数据的任何明显相关性和共线性。
- 也就是,在固定时间序列数据中,样本观察的属性或值不取决于观察它的时间戳。
例如,给定一个地区的年度人口的假设数据集,如果观察到人口每年增加两倍或增加固定数量,则该数据是非平稳的。
任何给定的观察都高度依赖于年份,因为人口价值将取决于它与任意过去一年的差距。在使用时间序列数据训练模型时,这种依赖性会导致不正确的偏差。
- 为了消除这种相关性,ARIMA 使用差分使数据平稳。最简单的差分涉及取两个相邻数据点的差值。
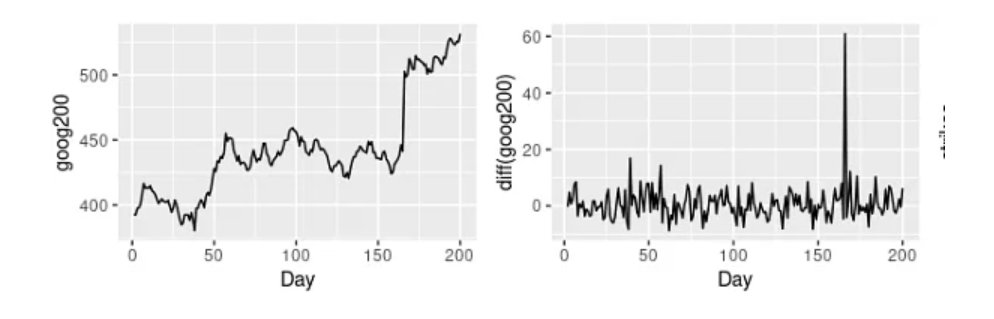
例如,上图左图显示了谷歌 200 天的股价。右边的图是第一张图的不同版本——这意味着它显示了谷歌股票 200 天的变化。在第一张图中可以观察到一种模式(每过100天就会上涨),这些趋势是非平稳时间序列数据的标志。
然而,在第二张图中没有观察到趋势或季节性,也没有观察到增加的方差。因此,我们可以说差分版本是平稳的。
平滑
一般情况下,处理时间序列的核心任务就是根据历史数据来对未来进行预测。这可以通过许多模型来完成。先来介绍一个最老也是最简单的模型:移动平均。
在移动平均中,假设 y ^ t \hat{y}_{t} y^t 仅仅依赖 k k k 个最相近的值,对这 k k k 个值求平均值得到 y ^ t \hat{y}_{t} y^t 。公式如下式所示: y ^ t = 1 k ∑ n = 1 k y t − n \hat{y}_{t} = \frac{1}{k} \displaystyle\sum^{k}_{n=1} y_{t-n} y^t=k1n=1∑kyt−n
很明显,这种方法不能预测未来很久的数据。因为,为了预测下一个的值,就需要实际观察到之前的值。但这种方法可以对原始数据进行平滑。在进行平滑时,窗口越宽,也就是 k 的值越大,趋势越平滑。对于波动非常大的数据,这种处理可以使其更易于分析。
we try something!
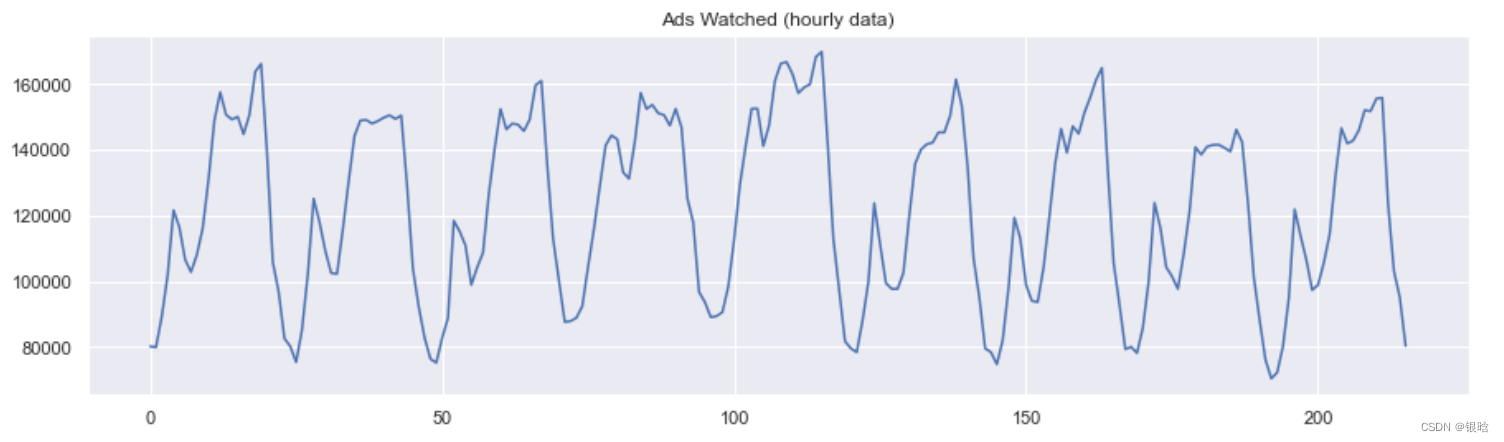
通过举个例子来进行说明,这里有一份真实的手机游戏数据,记录的是用户每小时观看的广告和每天游戏货币的支出
- 画图函数
def plotMovingAverage(
series, window, plot_intervals=False, scale=1.96, plot_anomalies=False
):
"""
series - 时间序列
window - 滑动窗口尺寸
plot_intervals -置信区间
plot_anomalies - 显示异常值
"""
rolling_mean = series.rolling(window=window).mean()
plt.figure(figsize=(15, 4))
plt.title("Moving average\n window size = {}".format(window))
plt.plot(rolling_mean, "g", label="Rolling mean trend")
# 画出置信区间
if plot_intervals:
mae = mean_absolute_error(series[window:], rolling_mean[window:])
deviation = np.std(series[window:] - rolling_mean[window:])
lower_bond = rolling_mean - (mae + scale * deviation)
upper_bond = rolling_mean + (mae + scale * deviation)
plt.plot(upper_bond, "r--", label="Upper Bond / Lower Bond")
plt.plot(lower_bond, "r--")
# 画出奇异值,upper_bond:上界 ,lowwer_bond下界
if plot_anomalies:
anomalies = pd.DataFrame(index=series.index, columns=series.columns)
anomalies[series < lower_bond] = series[series < lower_bond]
anomalies[series > upper_bond] = series[series > upper_bond]
plt.plot(anomalies, "ro", markersize=10)
plt.plot(series[window:], label="Actual values")
plt.legend(loc="upper left")
plt.grid(True)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
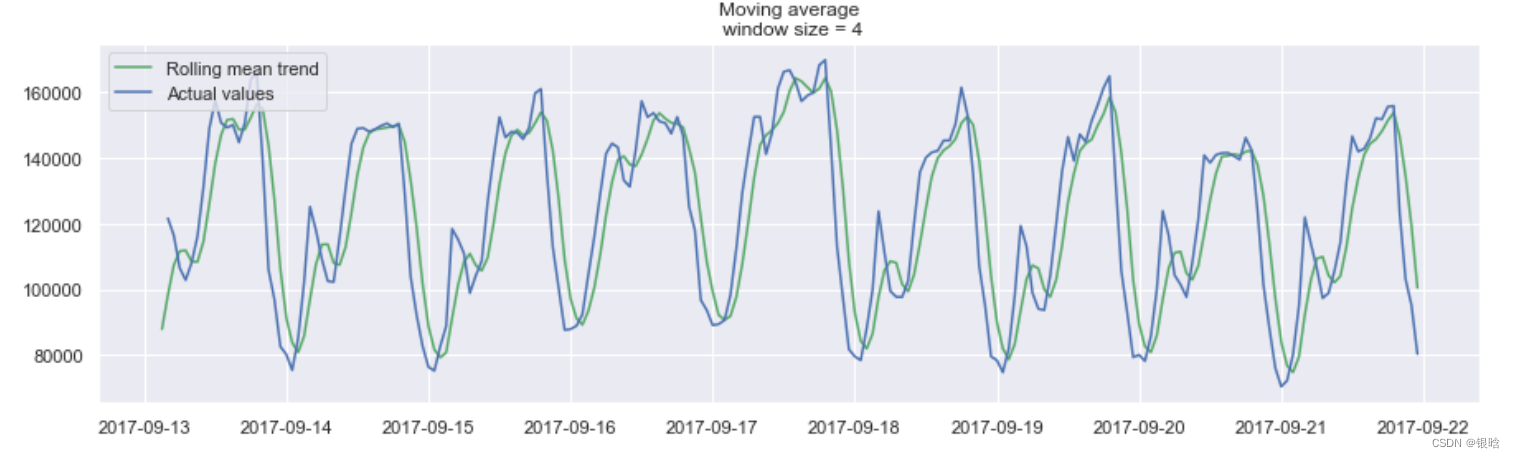
- 窗口平滑(hour=4)
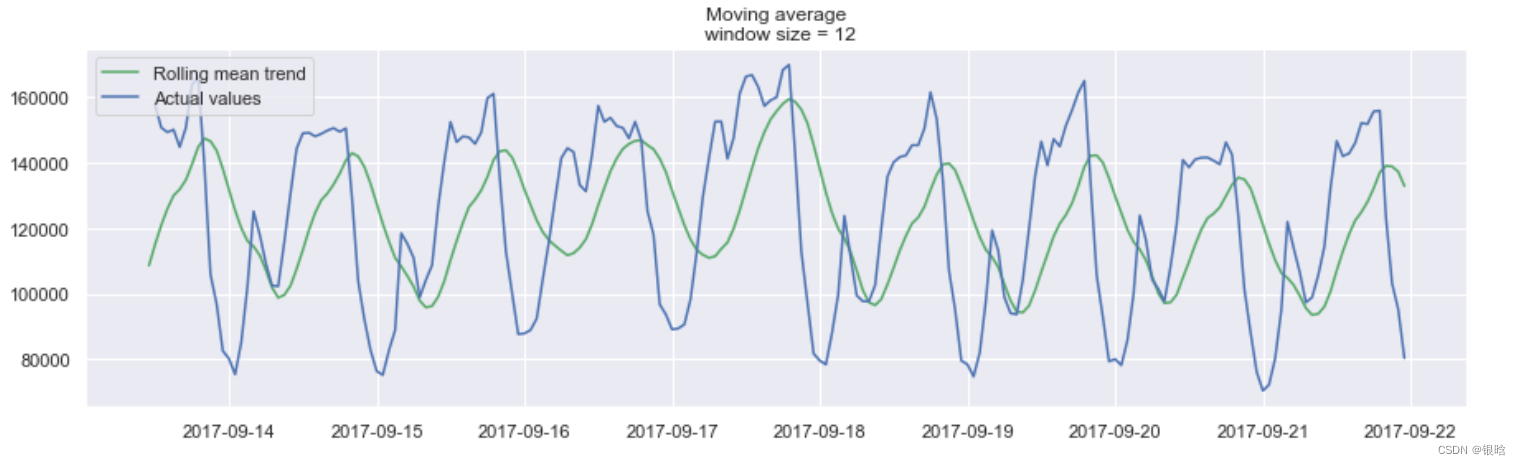
- 窗口平滑(hour=12)
- 窗口平滑(hour=24)
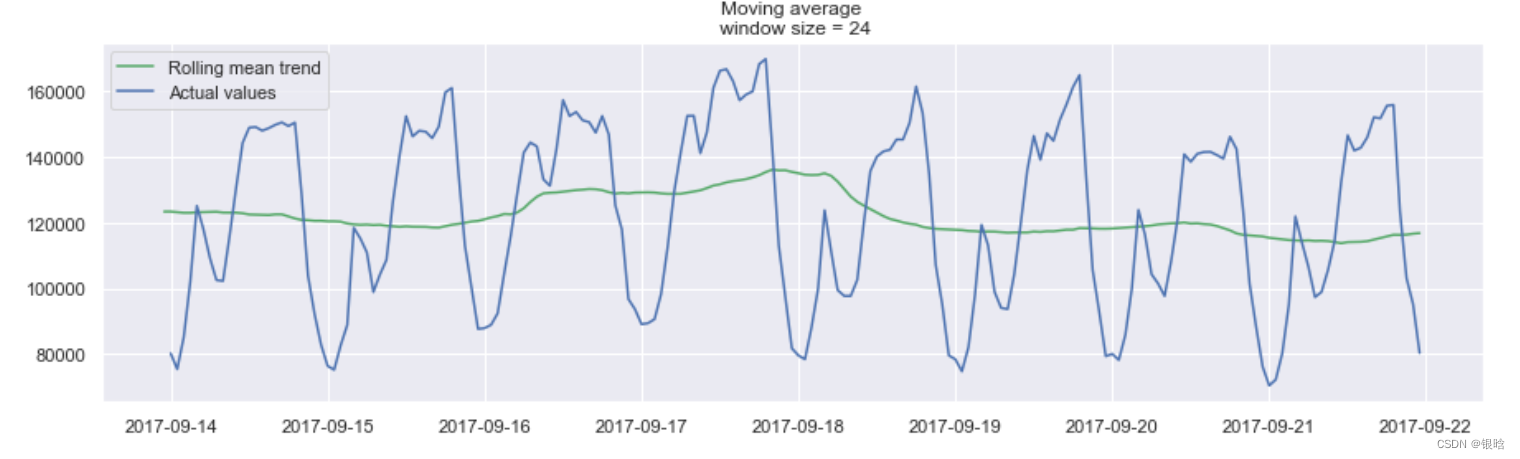
平滑的目的不是预测的有多准确,而是得到变化趋势,上图所示,是24小时(每天的趋势)
当对时间数据进行平滑时,可以清楚的看到整个用户查看广告的动态过程。在整个周末期间(2017-09-16),整个值变得很高,这是因为周末许多人都会有更多的时间。
- 给出置信区间
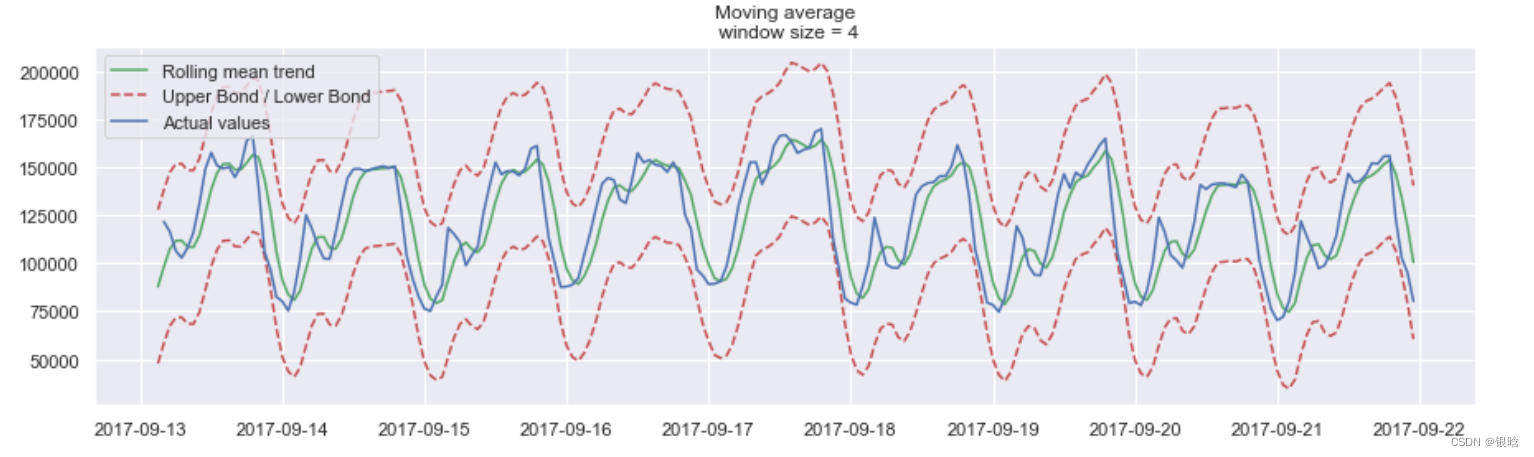
置信区间:【rolling_mean - (mae + scale * deviation),rolling_mean + (mae + scale * deviation)】
- 找出异常值
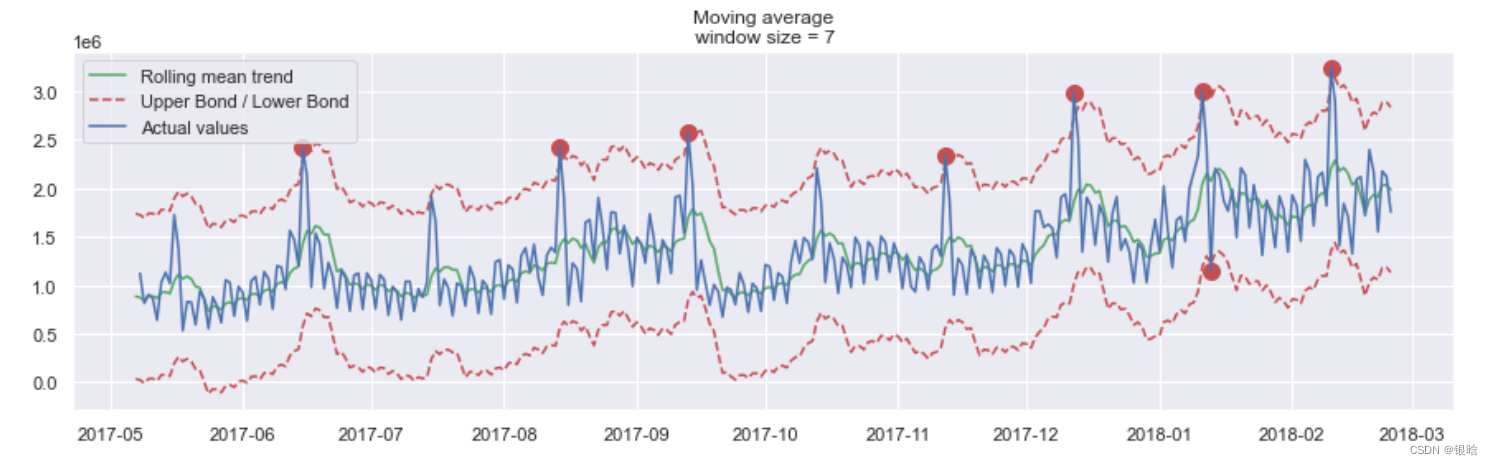
在这里的检测结果出乎意料,从图中可以看到该方法的缺点:它没有捕获数据中的每月季节性,并将几乎所有的峰值标记为异常。
指数平滑
与加权平滑不同,加权平滑只是加权时间序列最后的 k 个值,而 指数平滑 则是一开始加权所有可用的观测值,而当每一步向后移动窗口时,进行指数地减小权重,这个过程可以使用下面的公式进行表达。 y ^ t = α ⋅ y t + ( 1 − α ) ⋅ y ^ t − 1 \hat{y}_{t} = \alpha \cdot y_t + (1-\alpha) \cdot \hat y_{t-1} y^t=α⋅yt+(1−α)⋅y^t−1
这里,预测值是当前真实值和先前预测值之间的加权平均值。 本文内容由网友自发贡献,转载请注明出处:【wpsshop博客】
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

