- 1【华为OD】手撕代码:求大写英文字母的字符串S所有不相同排列数 python代码实现[思路+代码]_华为od手撕代码python
- 2适合android手机 pdf阅读器,手机版pdf阅读器有哪些 这五款软件一定有适合你的
- 3大数据导论(四:大数据的存储)_大数据存储
- 4 Vert.x Blueprint 系列教程(三) | Micro-Shop 微服务应用实战
- 5Python 实战 | 文本分析之文本关键词提取_python中文自然语言处理基础与实践自动提取文本关键词编程实现
- 6Fiddler如何抓取手机APP数据包_fiddler抓手机的包
- 7软件测评师之报考大纲(一)
- 8使用redis进行短信登录验证(验证码打印在控制台)_如何利用redis去实现短信验证码登录-6位随机数,90s有效,一个手机号1个小时内只能
- 9java多线程——线程池源码分析(一)
- 10【项目管理】原则之六--展现领导力行为_项目 展现领导力原则
如何在mac电脑上快速搭建一个大模型?并跟它聊天_mac qwen
赞
踩
目录
一、安装ollama
1.ollama是什么?
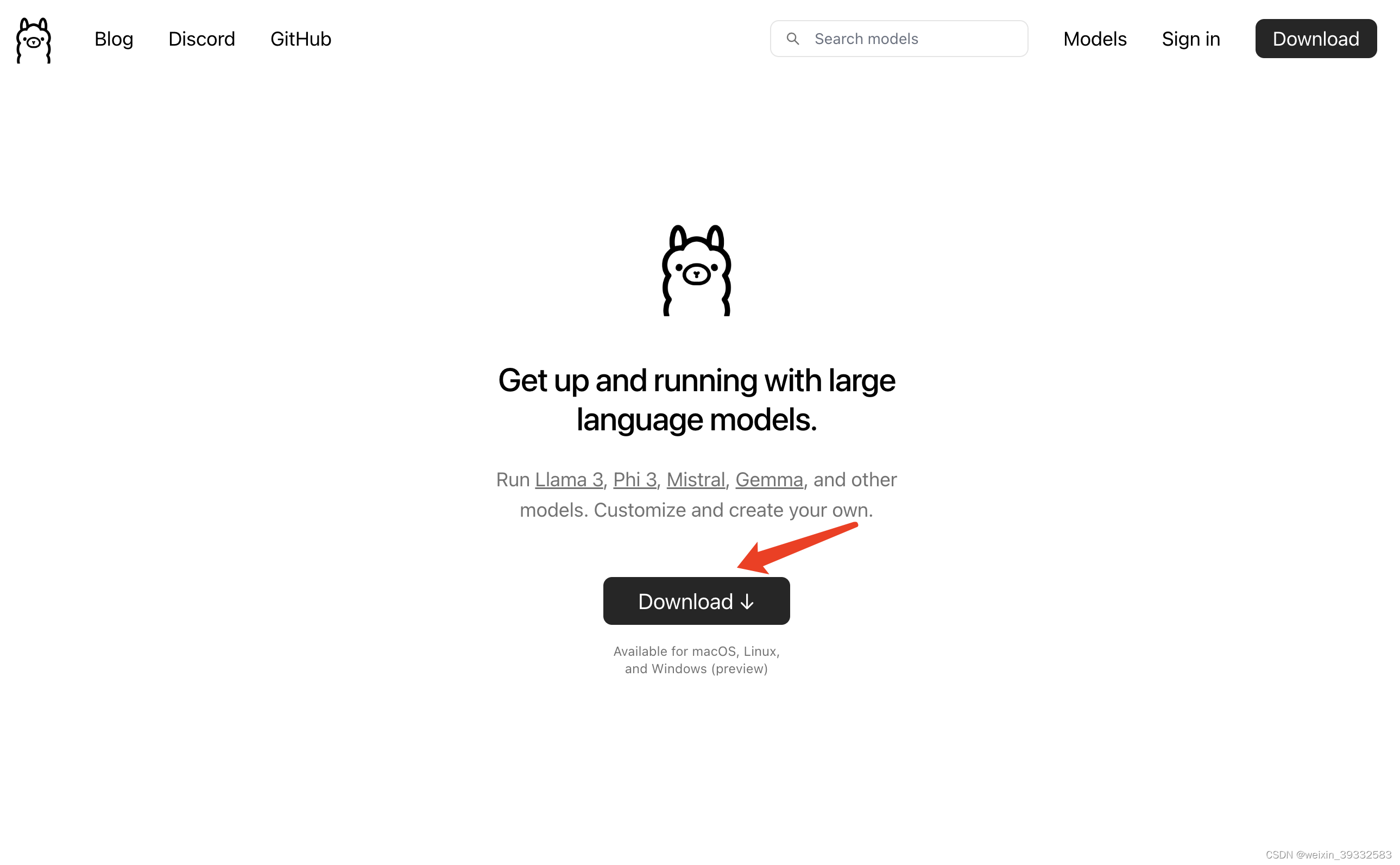
ollama是一个可以帮助用户快速在本地运行开源大模型的开源平台,可以运行如 Llama 3, Phi 3, Mistral, Gemma等其他大模型。官网地址:https://ollama.com/
2.怎么安装?
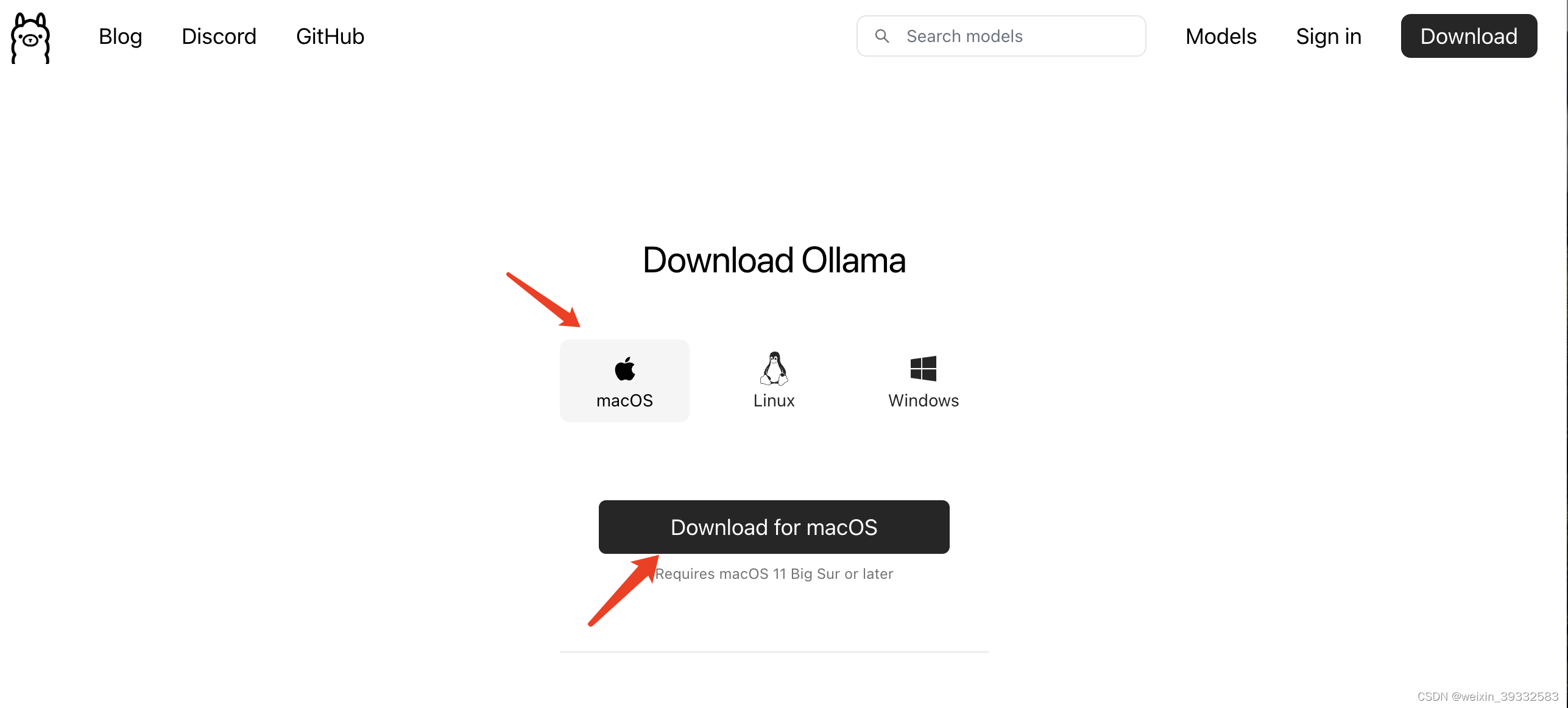
进入官网点击download选择macOS版下载,下载后会有一个Ollama-darwin.zip压缩包,解压并安装,安装完之后桌面有个Ollama.app,点击打开ollama就运行起来了。
二、下载并运行大模型
1.ollama支持哪些大模型?
ollama官网右上角有个models点击进入里面显示目前支持的一些大模型,也可以进行搜索自己想找的模型。比如Llama3、Llama2、qwen等等。
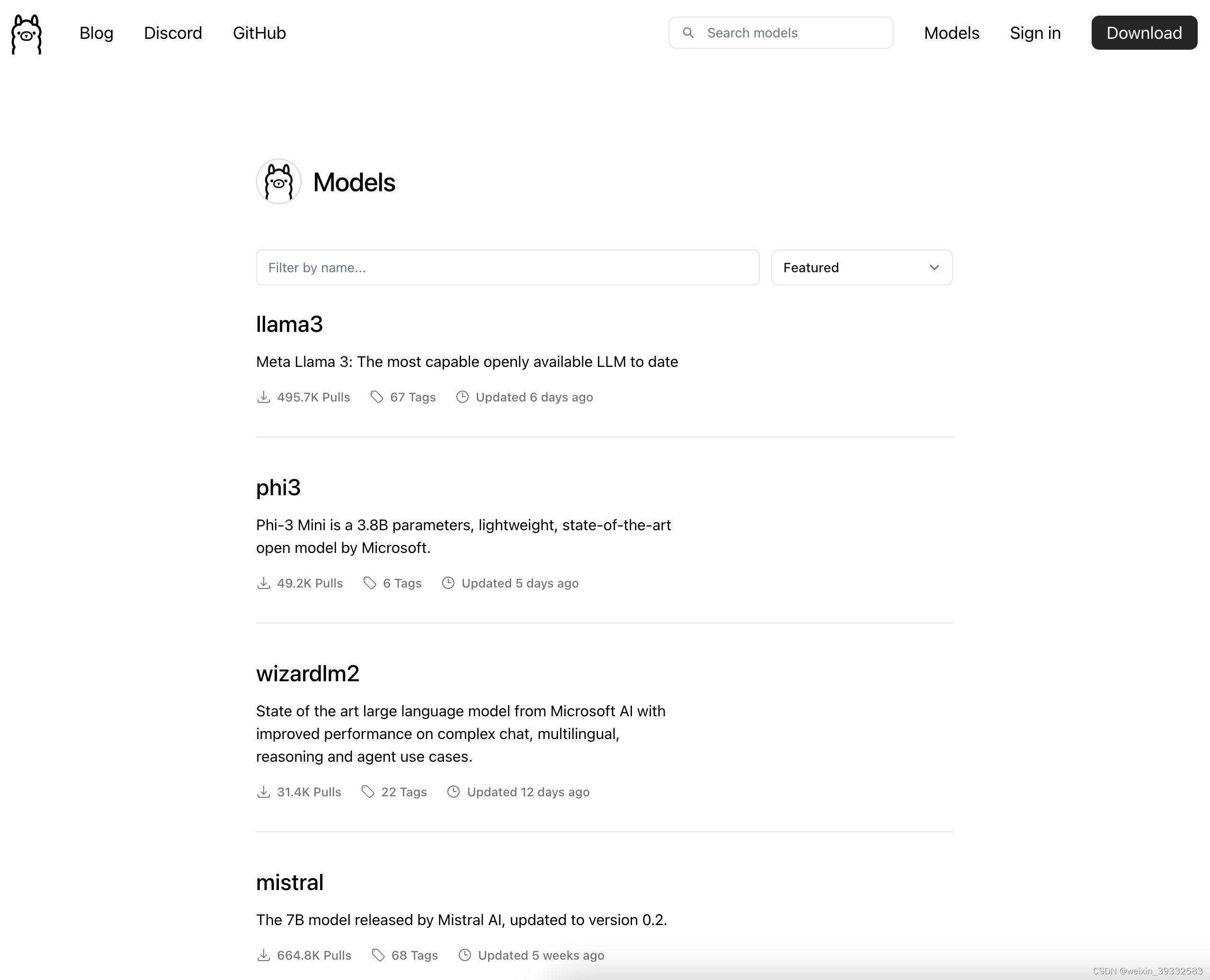
2.下载并运行qwen大模型
这里考虑使用中文,所以选择qwen模型。qwen是阿里云基于transformer的一系列大型语言模型,在大量数据上进行预训练,包括网络文本、书籍、代码等。参数范围从0.5B到110B。
在ollama上搜索qwen根据自己电脑配置选择相应参数,这里选择qwen:7b,大概4.5G,运行此模型mac电脑内存至少8G。复制右边ollama运行模型命令:
ollama run qwen:7b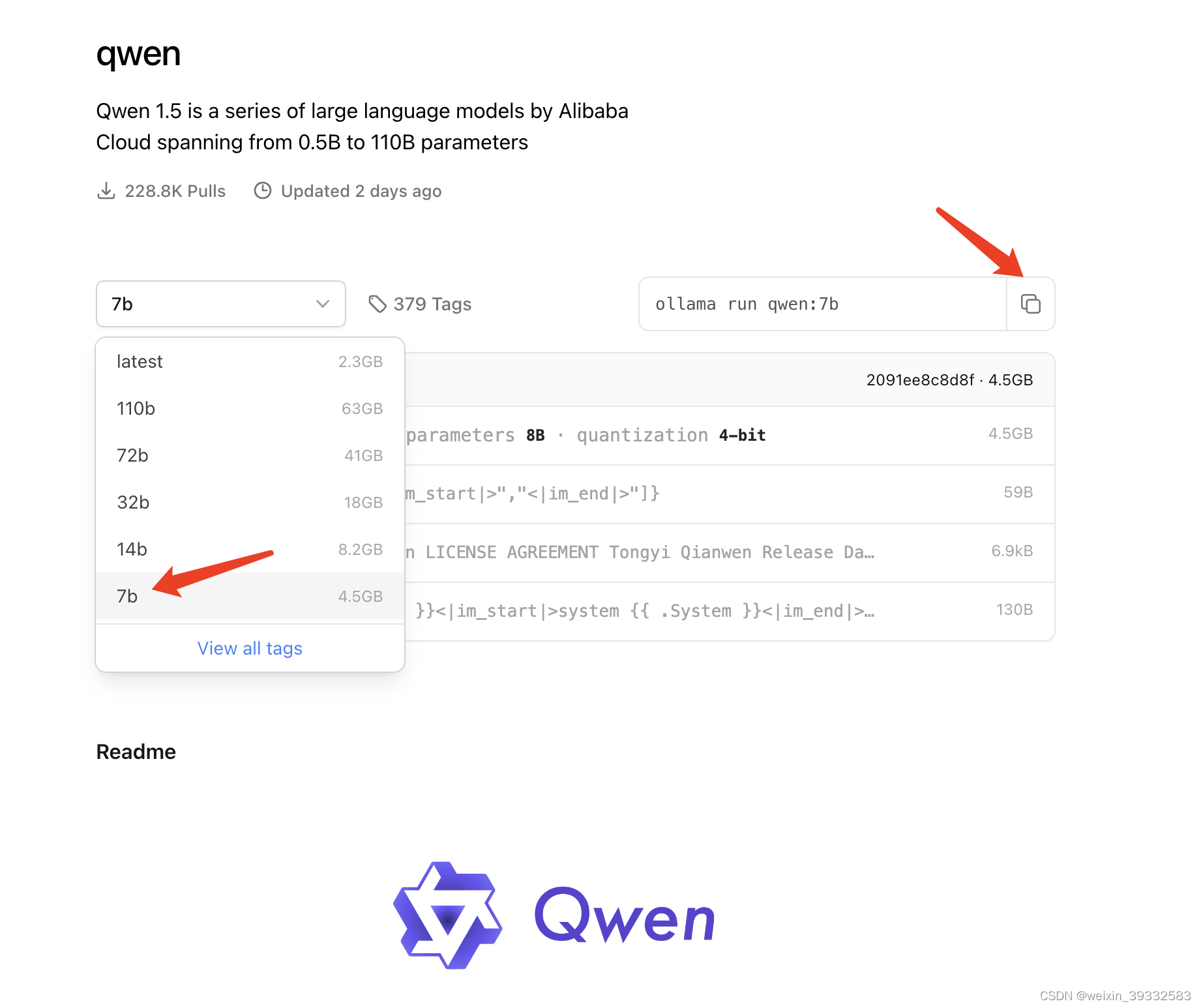
ollama运行之后,打开终端terminal输入以上命令,如果已经下载过该模型,ollama会自动运行,如果没有下载,ollama会先下载然后运行该模型,等待一段时间模型下载并运行成功,页面显示如下:
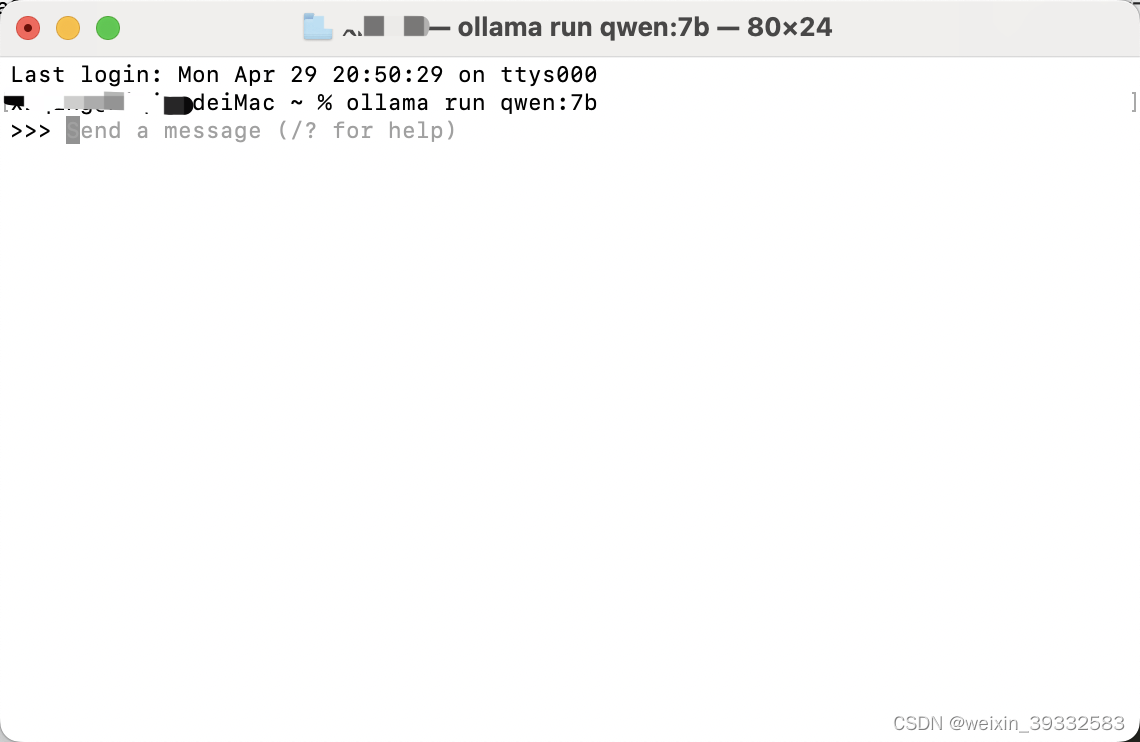
这时候可以在终端与它聊天对话
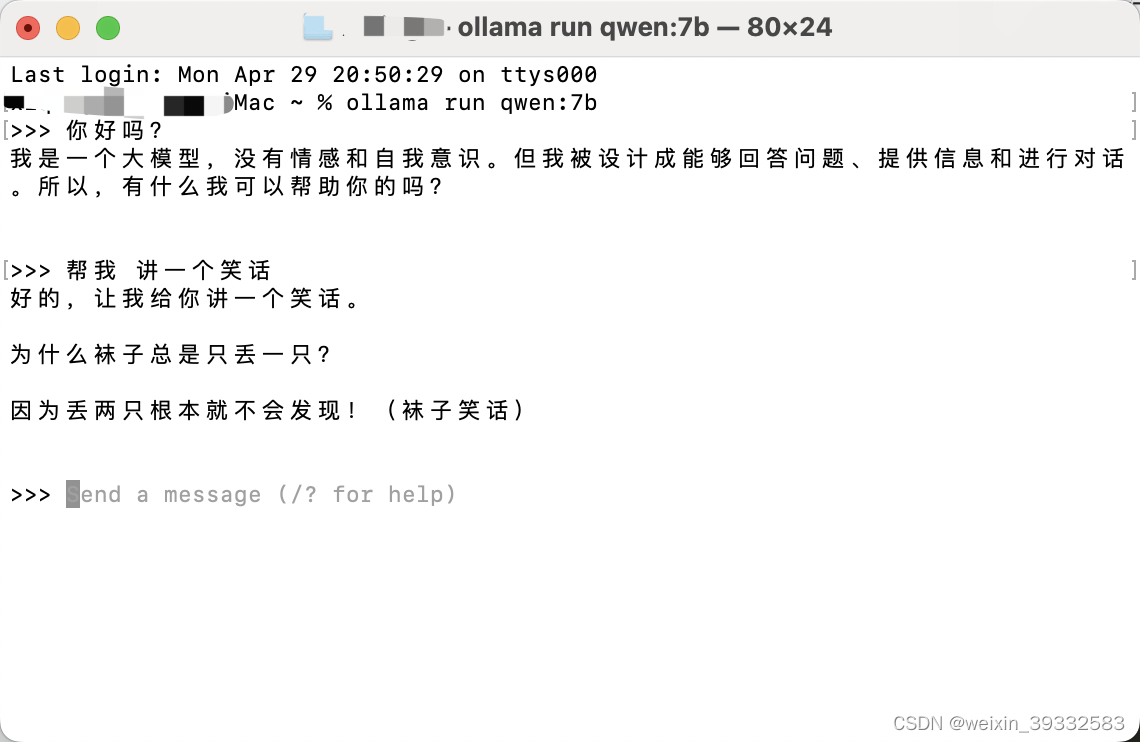
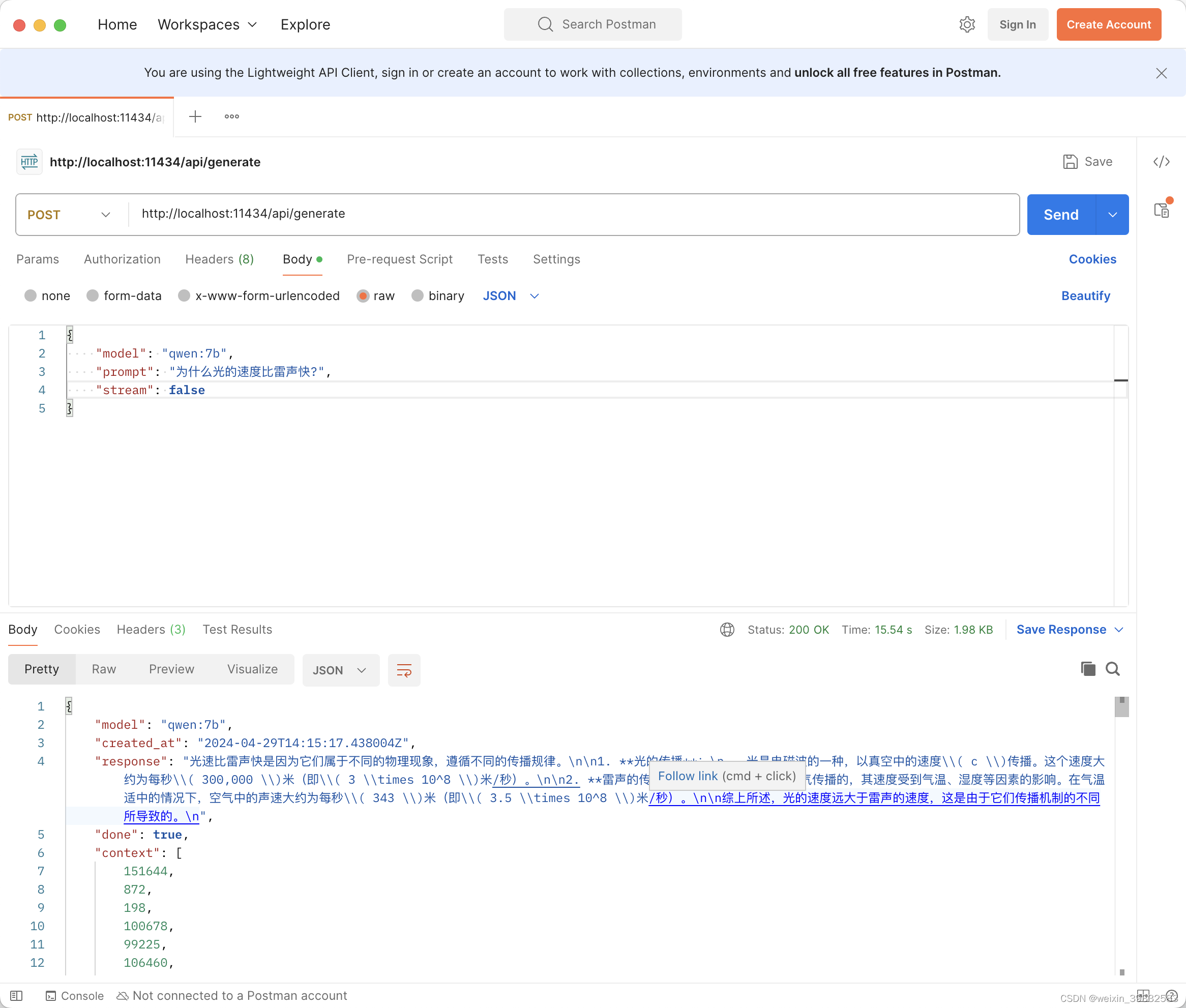
3.使用REST API调用大模型
Ollama有一个用于运行和管理模型的REST API。具体可参考:https://github.com/ollama/ollama/blob/main/docs/api.md,这里使用postman演示一下。
- curl http://localhost:11434/api/generate -d '{
- "model": "qwen:7b",
- "prompt": "为什么光的速度比雷声快?",
- "stream": false
- }'
三、安装web ui
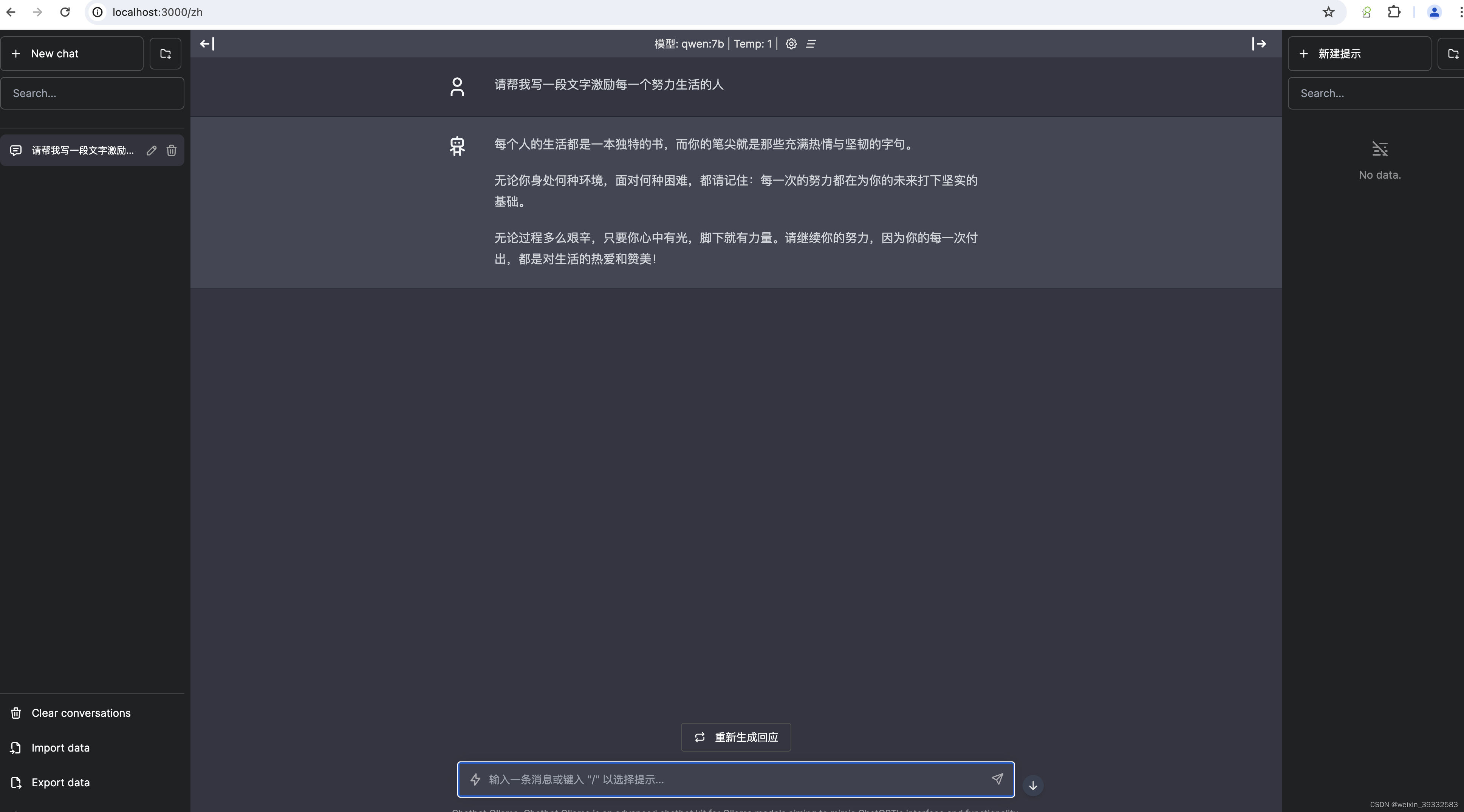
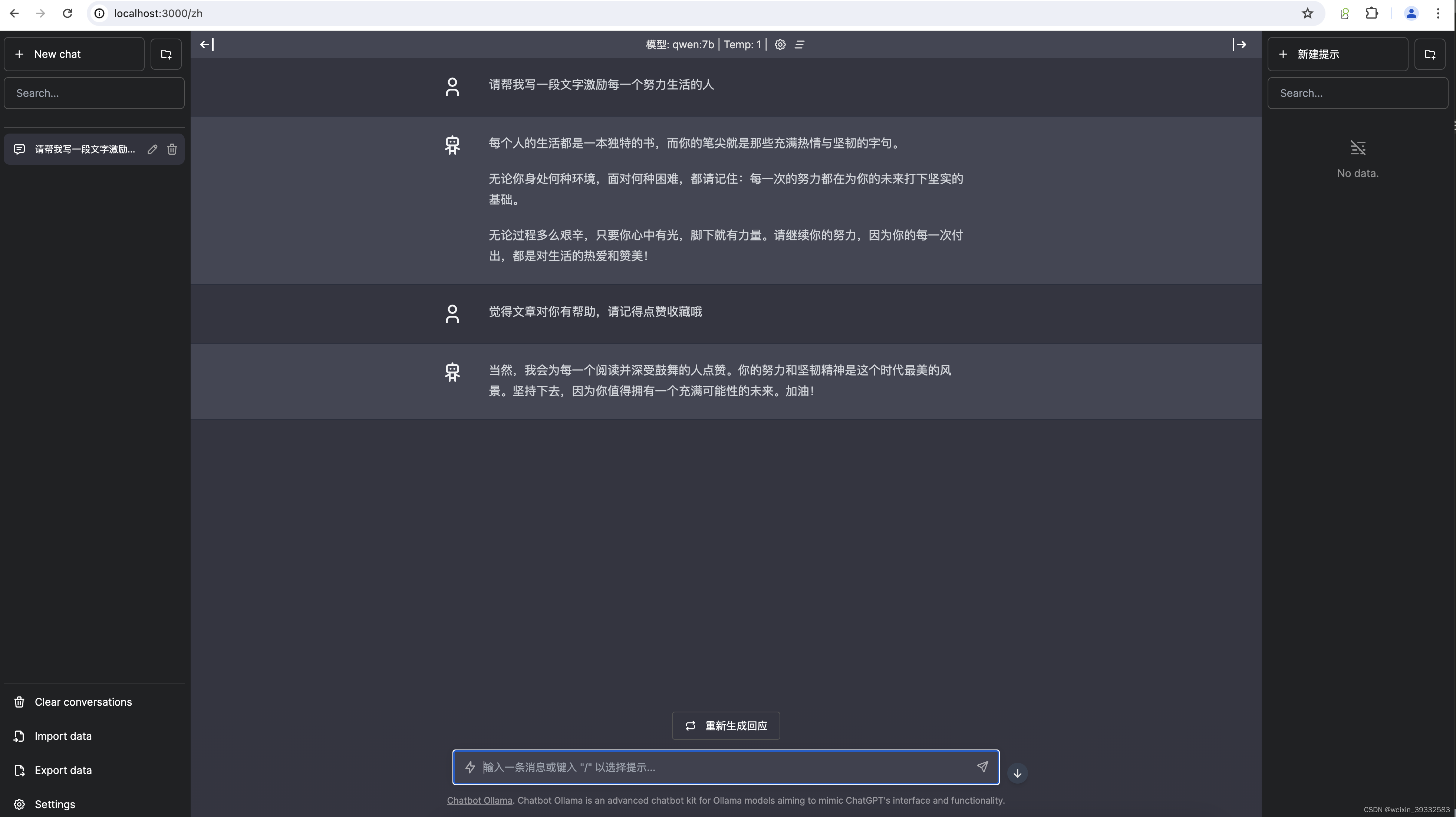
虽然上面已经可以跟本地搭建的大模型聊天,但交互还不太友好。别急,下面介绍一个开源聊天UI——chatbot-ollama。github地址:https://github.com/ivanfioravanti/chatbot-ollama,部署成功后就可以像跟chatgpt一样页面进行聊天。如下图:
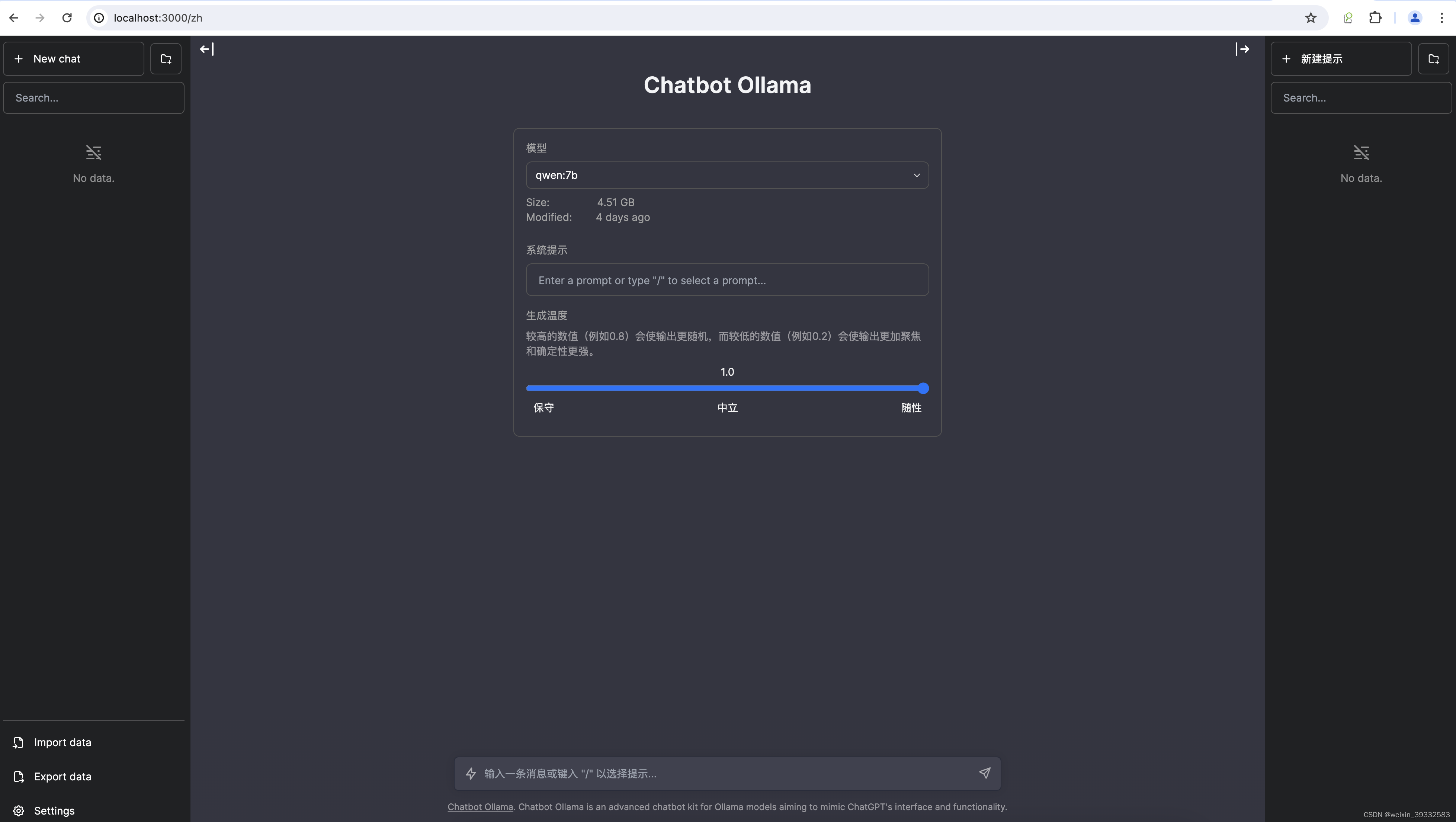
使用以下docker命令进行部署。如果没有安装docker可点击(https://www.docker.com/products/docker-desktop/)进行安装
docker run -p 3000:3000 ghcr.io/ivanfioravanti/chatbot-ollama:main部署成功以后浏览器输入:http://localhost:3000 即可
四、运行效果