
- 1V字形研发模式中的测试_v字测试流程
- 2项目管理工具git_git管理工具
- 3LVGL移植到ARM开发板(GEC6818)_gec6818移植lvgl
- 4LeetCode 算法:找到字符串中所有字母异位词c++
- 5《IT 领域准新生暑期预习指南:开启未来科技之旅》
- 6在Linux系统yum安装报错Cannot find a valid baseurl for repo解决方案_error: cannot find a valid baseurl for repo: livna
- 7谷粒商城--分布式基础篇(P1~P27)_谷粒商城分布式基础篇课件
- 8在ROS中用opencv订阅摄像头图像并显示_ros2查看订阅到的图片
- 9dockerfile更改docker镜像源(1)_dockerfile指定镜像源
- 10pycorrector训练自己的模型,pycharm如何训练模型_pycharm中基于keras的模型搭建
最全Deeplearning4j【基础 01】初识Java深度学习框架DL4J_dl4j java,最详细的解释小白也能听懂
赞
踩
最后总结
搞定算法,面试字节再不怕,有需要文章中分享的这些二叉树、链表、字符串、栈和队列等等各大面试高频知识点及解析
最后再分享一份终极手撕架构的大礼包(学习笔记):分布式+微服务+开源框架+性能优化

- 跨平台(硬件:CUDA GPU,
x86,ARM,PowerPC;操作系统:Windows/Mac/Linux/Android)。
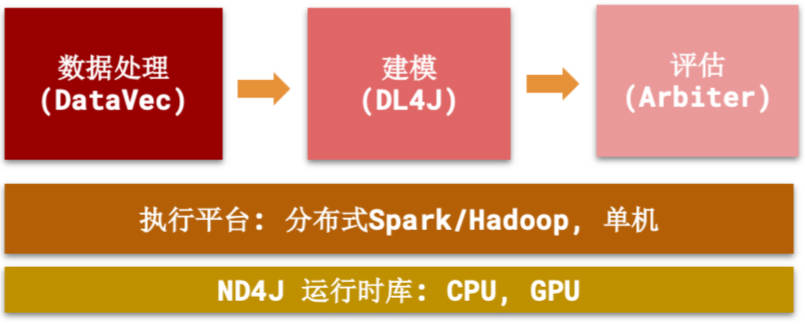
小结一下:模型构建、模型训练和部署一条龙,兼容性强,多线程,跨平台(特别注意Android平台,支持端侧模型)?
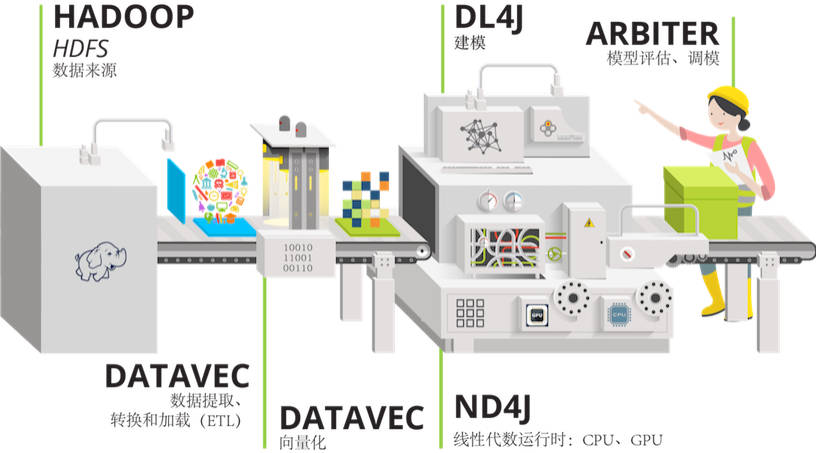
3.组件
Deeplearning4j实际上是一堆项目,旨在支持基于 JVM 的深度学习应用程序的所有需求。除了 Deeplearning4j 本身(高级 API),它还包括:
- Deeplearning4j/ScalNet:JVM和Spark上运行神经网络构建、训练和部署的基础框架库;
- ND4J/libND4J:支持CPU/GPU加速的高性能数值计算库,可以说是JVM上的Numpy;
- SameDiff:用于符合微分和计算图库;
- DataVec:数据处理库,提供采样、过滤、变换等操作;
- Arbiter:神经网络超参数搜索和优化库;
- RL4J:JVM上的强化学习库;
- Model Import:模型导入库,可以导入ONNX,TensorFlow,Keras(Caffe)模型;
- Jumpy:ND4J对应Python语言API;
- Python4j:可以在JVM里运行Python脚本语言。
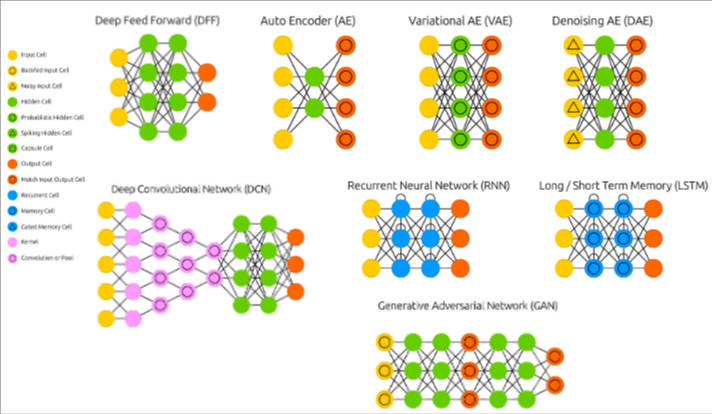
3.1 Deeplearning4j/ScalNet
- 前向神经网络(Feedforward Neural Networks, FNN)
- 自动编码器(AutoEncoders)
- 卷积神经网络(Convolutional Neural Networks, CNN)
- 循环神经网络(Recurrent Neural Networks ,RNN)
- 生成对抗网络(Generative Adversarial Networks)
- 递归神经网络(Recursive Neural Network )
- 深度信念网络(Deep Belief Networks)和受限制玻尔兹曼机(Restricted Boltzmann Machines)
- 图神经网络(Graph Neural Networks)
3.1.1 Deeplearning4jf(Java)
神经网络高层API库,用于构建具有各种层的多层神经网络(MultiLayerNetworks)和计算图(ComputationGraphs),支持从其他框架导入模型和在Apache Spark上进行分布式训练
3.1.2 ScalNet(Scala)
ScalNet是受Keras启发而为Deeplearning4j开发的Scala语言包装。它通过Spark在多个GPU上运行。功能相当于Keras。
Keras是一个由Python编写的开源人工神经网络库,可以作为Tensorflow、Microsoft-CNTK和Theano的高阶应用程序接口,进行深度学习模型的设计、调试、评估、应用和可视化。
3.2 ND4J/LibND4J
ND4J是Deeplearning4j的数值处理库和张量库,在JVM中实现Numpy的功能:
- Java科学运算引擎,用来驱动矩阵操作;
- JavaCPP功能: Java 到 Objective-C 的桥,可像其他 Java 对象一样来使用 Objective-C 对象;
- CPU 后瑞:OpenMP、OpenBlas 或 MKL、与SIMD的扩展;
- GPU 后瑞:最新CUDA 及 CuDNN。
包含500多种数学、线性代数和神经网络操作。
3.3 SameDiff
SameDiff是具有自动微分功能的张量计算库,其自动微分方法是基于静态图的方法,提供神经网络运算中更为底层的接口,主要用于自定义神经网络拓扑结构。
另外,SameDiff支持导入Tensorflow冻结模型格式的.pd(protobuf)模型。对ONNX、TensorFlow SaveModel和Keras模型的导入正在完善中。可以简单的认为SameDiff和DL4J的关系类似于Tensorflow和Keras。
符合微分和计算图库是深度学习中的两个关键概念:
- 符合微分(Automatic Differentiation,简称AD)
- 符合微分是一种计算梯度的技术,用于优化神经网络中的参数。
- 在神经网络训练过程中,我们需要计算损失函数对模型参数的梯度,以便使用梯度下降等优化算法来更新参数。
- 符合微分通过构建计算图并自动计算每个节点的梯度,使得梯度计算变得高效且不容易出错。
- 常见的深度学习框架(如TensorFlow、PyTorch和Deeplearning4j)都使用符合微分来实现反向传播算法。
- 计算图库
- 计算图是一种表示复杂计算过程的图结构,其中节点表示操作(例如加法、乘法、激活函数等),边表示数据流。
- 计算图库用于构建、管理和执行计算图。
- 在深度学习中,计算图用于描述神经网络的前向传播和反向传播过程。
3.4 DataVec
神经网络专门处理多维数组形式的数值数据。DataVec可以将来自一个CSV文件或一批图像的数据序列化,转换为数值数组。数据的摄取、清理、联接、缩放、标准化和转换是开展任何类型的数据分析时都必须完成的工作。是深度学习的先决条件。DataVec是专为这一流程设计的工具包。数据科学家和开发人员可以用其中的工具将图像、视频、声音、文本和时间序列等原始数据转变为特征向量,输入神经网络。
- 数据的的 ETL (抽取、转换、装载)和向量化;
- DataVec帮助克服机器学习及深度学习实现过程中最重大的障碍之一:将数据转化为神经网络能够识别的格式;
- DataVec使用Apache Spark来进行转换运算。
整体流程如下:
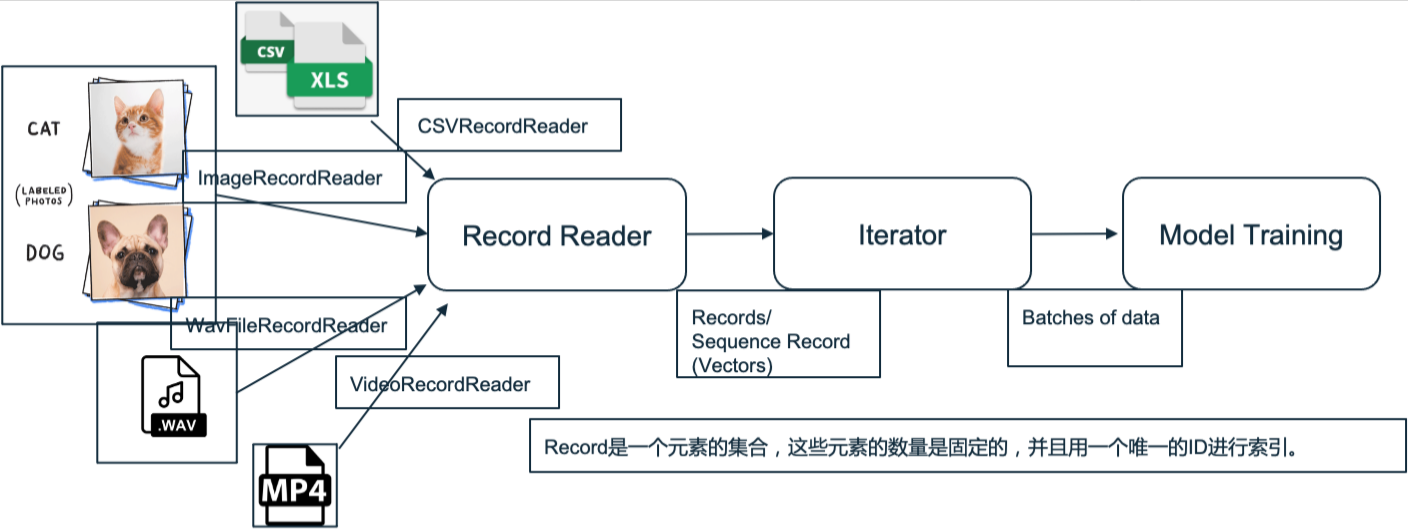
同时,DataVec也支持所有主要类型的输入(CSV、文本、图像、音频、视频和数据库)整体流程如下:

除了明显提供经典数据格式的读取器,DataVec还提供了一个接口用来摄取特定的自定义数据。
3.5 Arbiter
我的面试宝典:一线互联网大厂Java核心面试题库
以下是我个人的一些做法,希望可以给各位提供一些帮助:
整理了很长一段时间,拿来复习面试刷题非常合适,其中包括了Java基础、异常、集合、并发编程、JVM、Spring全家桶、MyBatis、Redis、数据库、中间件MQ、Dubbo、Linux、Tomcat、ZooKeeper、Netty等等,且还会持续的更新…可star一下!

283页的Java进阶核心pdf文档
Java部分:Java基础,集合,并发,多线程,JVM,设计模式
数据结构算法:Java算法,数据结构
开源框架部分:Spring,MyBatis,MVC,netty,tomcat
分布式部分:架构设计,Redis缓存,Zookeeper,kafka,RabbitMQ,负载均衡等
微服务部分:SpringBoot,SpringCloud,Dubbo,Docker

还有源码相关的阅读学习

实战项目源码】](https://bbs.csdn.net/forums/4f45ff00ff254613a03fab5e56a57acb)收录**

