
- 1【原】UCS-2和UTF-8的互相转换
- 2数学规划(Python cvxpy、scipy.optimize)
- 3MongoDB爬虫数据存储与分析流程指南_掌握mongodb的查询语法,存储语法,充当爬虫过滤层
- 4理解机器学习中的潜在空间(Understanding Latent Space in Machine Learning)_深度学习 潜在空间
- 5mac外接显示器 字体发虚解决方案_macbook外接显示器字体小
- 6(一)人脸识别技术之人脸识别过程及识别算法简介_人脸匹配过程
- 7合泰杯 | 合泰单片机入门 环境搭建安装(一)_合泰杯单片机难度大么
- 8探索RIS代码集合:一个强大的工程实践资源库
- 9黑龙江能源职业学院软件工程计算机方向毕业设计课题选题参考目录
- 10数学建模--深入剖析线性规划(模型全方位解读+代码分析)_线性规划模型
Apache Spark分布式计算框架架构介绍
赞
踩
目录
一、概述
Apache Spark 是通用的分布式大数据计算引擎 Spark UC Berkeley AMPLab(美国加州大学伯克 利分校的 AMP 实验室)开源的通用并行框架。 Spark 拥有 Hadoop MapReduce 所具有的优点,但不同于 Hadoop MapReduce 的是, Hadoop 每次经过 Job行的中间结果都存储到 HDFS 磁盘上,而 Spark Job 中间输出结果可以保存在内存中,而不再需要读写 HDFS 。因为内存的读写速度与磁盘的读写速度不在一个数量级上,所以Spark 利用内存中的数据能更快速地完成数据的处理。
Spark 启用了弹性分布式数据集( Resilient Distributed Dataset , RDD) ,除了能够提高交互式查询效率,还可以优化迭代器的工作负载。由于弹性分布式数据集的存在,使得数据挖掘与机器学习等需要迭代的 MapReduce 的算法更容易实现。
官网地址:spark.apache.org
二、Apache Spark架构组件栈
2.1 概述
Spark 基于 Spark Core 建立了 Spark SQL、Spark Streaming、MLlib、GraphX、SparkR 核心组件,基于不同组件可以实现不同的计算任务,这些计算任务的运行模式有:本地模式、独立模式(Standalone)、Mesos 模式、 YARN 模式。Spark 任务的计算可以从 HDFS、S3、Hypertable、HBase或Cassandra等多种数据源中存取数据。
2.2 架构图

2.3 架构分层组件说明
2.3.1 支持数据源
Spark 任务的计算可以从 HDFS、S3、Hypertable、HBase或Cassandra等多种数据源中存取数据。
2.3.2 调度运行模式
Spark 的运行模式主要包括 Local模式、 Standalone 模式、 On YARN、 On Mesos 和运行在 AWS 等公有云平台上。

2.3.3 Spark Core核心
Spark 的核心功能实现包括基础设施、存储系统、调度系统和计算引擎。
2.3.3.1 基础设施
Spark 中有很多基础设施,这些基础设施被 Spark 中的各种组件广泛使用,包括 SparkConf (配置信息) 、SparkContext ( Spark 上下文) 、Spark RPC (远程过程调用)、ListenerBu (事件总线) 、MetricsSystem (度量系统) 、SparkEnv (环境变量)等。
2.3.3.2 存储系统
Spark 存储系统用于管理 Spark 运行过程中依赖的数据的存储方式和存储位置。Spark 存储系统首先考虑在各节点的内存中存储数据,当内存不足时会将数据存储到磁盘上,这种内存优先的存储策略使得 Spark 的计算性能无论在实时流计算还是在批量'计算的场景下都表现很好。 Spark 的内存存储空间和执行存储空间之间的边界可以
灵活控制。
2.3.3.3 调度系统
Spark 调度系统主要由 DAGScheduler 、TaskScheduler组成。DAGScheduler 负责创建 Job 、将 DAG 中的RDD 划分到不同 Stage 、为 Stage 创建对应的Task 、批量提交 Task 等。 TaskScheduler 负责按照 FIFO (First Input First Output. 先进先出 ) 或 FAIR (公平调度)等调度算法对 Task 进行批量调度。
2.3.3.4 计算引擎
计算引擎由内存管理器、任务管理器、 Task Shuffle 管理器等组成。
2.3.4 生态组件
2.3.4.1 Spark SQL
Spark SQL 提供基于 SQL 的数据处理方式,使得分布式数据的处理变得更加简单。此外,Spark 提供了对 Hive SQL 的支持。
2.3.4.2 Spark Streaming
Spark Streaming 提供流计算能力,支持 Kafka 、flume、 Kinesis 、TCP 多种流式数据源。此外,Spark Streaming 提供了基于时间窗口的批量流操作,用于对一定时间周期内的流数据执行批量处理。
2.3.4.3 GraphX
GraphX 用于分布式图计算。通过 Pregel 提供的 API 可以快速解决图计算中的常见问题。
2.3.4.4 Spark MLlib
Spark MLlib 为 Spark机器学习库 。Spark MLlib 提供了统计、分类、回归等多种机器学习算法的实现,其简单易用的 API 接口降低 了机器学习的门槛。
2.3.4.5 Spark R
Spark R是一个R语言包, 提供了轻量级R语言使用Spark的方式。Spark R实现了分布式的数据框,支持类似查询、过滤及聚合的操作(类似R语言中的数据框包dplyr ),使得基于R语言能够更方便处理大规模的数据集。同时Spark R 支持基于Spark MLlib 进行机器学习。
三、Apache Spark 的运行时架构
3.1 概述
Spark 的集群架构主要由 Cluster Manager (管理器)、 Worker (工作节点)、 Executor(执行器)、 Driver (驱动器)、 Application (应用程序) 五部分组成。
3.2 架构图

3.3 组件角色说明
3.3.1 Cluster Manager
Spark 集群管理器,主要用于整个集群资源的管理和分配。根据部署模式的不同,可以分为 Local、 Standalone、 YARN、Mesos、AWS。
3.3.2 Worker
Spark 的工作节点,用于执行提交的任务。 Worker 的工作职责如下:
- 通过注册机制向Cluster Manager 汇报自身的CPU和内存等资源使用信息。
- 在Master 的指示下创建并启动 Executor,Executor 是真正的计算单元。
- 将资源和任务进一步分配给Executor 并运行。
- 同步资源信息和Executor 状态信息给Cluster Manager。
3.3.3 Executor
真正执行计算任务的组件,是某个Application 运行在 Worker 上的一 个进程。该进程负责 Task 的运行并且将运行的结果数据保存到内存或磁盘上。
Task 是运行在 Executor 上的任务单元,Spark 应用程序最终被划分为经过优化的多个 Task 的集合。
3.3.4 Driver
Application 的驱动程序,可以理解为驱动程序运行中的 main()函数,Driver 在运行过程中会创建SparkContext。Application 通过 Driver 与 Cluster Manager 和Executor 进行通信。Driver 可以运行在 Application 上,也可以由 Application 提交给Cluster Manager,再由 Cluster Manager 安排 Worker 运行。Driver 的主要职责如下:
- 运行应用程序的main()函数。
- 创建SparkContext。
- 划分RDD并生成 DAG。
- 构建Job 并将每个 Job 都拆分为多个 Task,这些 Task 的集合被称为Stage。各个Stage 相互独立,由于 Stage 由多个 Task 构成,因此也被称为 Task Set。Job 是由多个Task构建的并行计算任务,具体为 Spark 中的 Action操作(例如collect、save 等)。
- 与Spark中的其他组件进行资源协调。
- 生成并发送Task到Executor。
3.3.5 Application
基于Spark API编写的应用程序,其中包括实现 Driver 功能的代码和在集群中多个节点上运行的 Executor 代码。Application 通过 Spark API创建RDD、对RDD进行转换、创建DAG、通过Driver将Application 注册到 Cluster Manager。
3.4 Spark 运行流程
3.4.1 概述
Spark 的数据计算主要通过 RDD的选代完成,RDD是弹性分布式数据集,可以看作是对各种数据计算模型的统一抽象。在 RDD 的迭代计算过程中,其数据被分为多个分区并行计算,分区数量取决于应用程序设定的 Partition 数量,每个分区的数据都只会在一个Task上计算。所有分区可以在多个机器节点的 Executor 上并行执行。
3.4.2 运行流程图

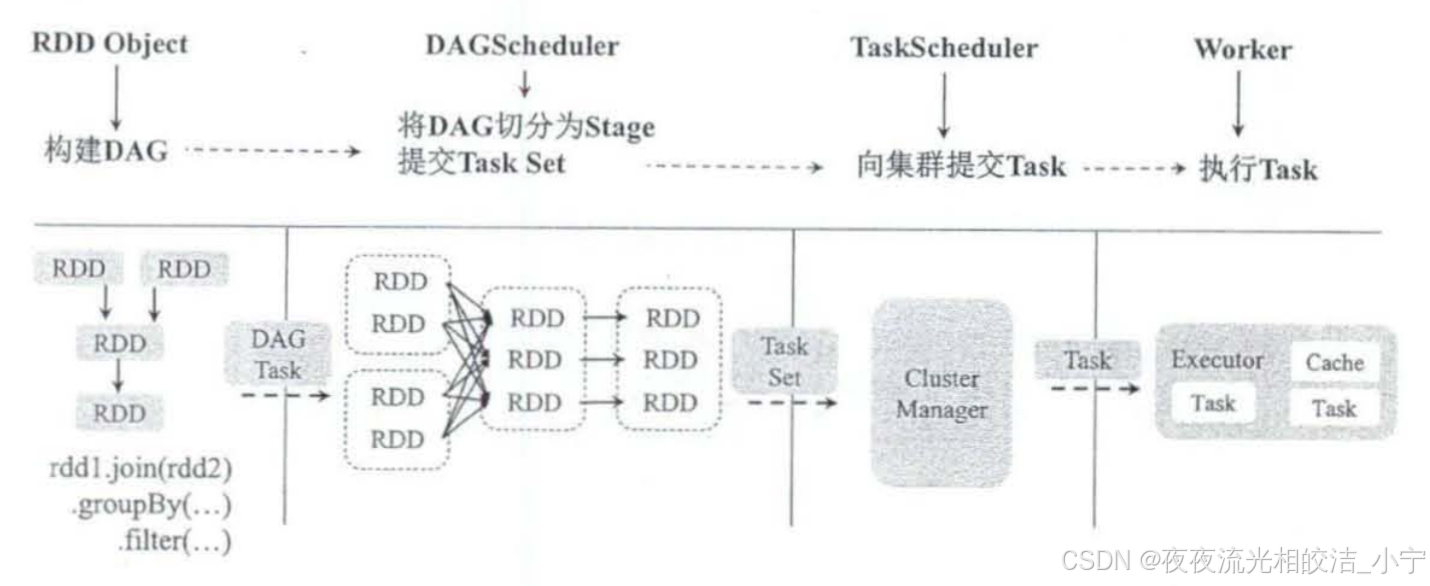
3.4.3 运行流程步骤说明
- 创建RDD对象,计算 RDD 之间的依赖关系,并将RDD生成一个DAG。
- DAGScheduler 将 DAG划分为多个 Stage,并将 Stage 对应的 Task Set 提交到集群管理中心。划分 Stage 的一个主要依据是当前计算因子的输人是否确定。如果确定,则将其分到同一个 Stage 中,避免多个 Stage 之间传递消息产生的系统资源开销。
- TaskScheduler 通过集群管理中心为每个 Task 都申请系统资源,并将 Task 提交到Worker
- Worker的Executor 执行具体的 Task。
四、Spark 的特点
4.1 计算速度快
Spark将每个任务都构造成一个DAG(Directed Acyclic Graph,有向无环图)来执行,其内部计算过程基于弹性分布式数据集在内存中对数据进行迭代计算,因此其运行效率很高。官方数据表明,如果计算的数据从磁盘上读取,则 Spark 的速度是 Hadoop MapReduce的10倍以上;如果计算的数据从内存中读取,则 Spark 的计算速度是Hadoop MapReduce的100倍以上。
4.2 易于使用
Spark 提供了 80多个高级运算操作,支持丰富的算子,开发人员只需要按照其封装好的API实现即可,不需要关心 Spark 的底层架构。同时,Spark 支持多种语言开发,包括Java、Scala、Python。
4.3 通用大数据框架
Spark 提供了多种类型的开发库,包括 Spark Core、Spark SQL(即时查询)、Spark Streaming(实时流处理)、Spark MLlib、GraphX(图计算),使得开发人员可以在同一个应用程序中无缝组合使用这些库,而不用像传统的大数据方案那样将离线任务放在Hadoop MapReduce 上运行,将实时流计算任务放在 Storm 上运行,并维护多个平台。Spark 提供了从实时流计算、MapReduce 离线计算、SOL计算、机器学习到图计算的一站式整体解决方案。
4.4 支持多种资源管理器
Spark 支持单机、Standalone、Hadoop YARN、Apache Mesos 等多种资源管理器,用户可以根据现有的大数据平台灵活地选择运行模式。
4.5 生态圈丰富
Spark生态圈以Spark Core 为核心,支持从HDFS、S3、HBase 等多种持久化层读取数据。同时,Spark 支持以 Hadoop YARN、Apache Mesos 和 Standalone 为资源管理器调度Job,完成Spark应用程序的计算。Spark 应用程序可以基于不同的组件实现,如SparkShell、Spark Submit 、Spark Streaming 、SparkSOL、BlinkDB(权衡查询)、MLlib/MLbase(机器学习)、GraphX 和SparkR(数学计算)等。Spark 生态圈已经从大数据计算和数据挖掘扩展到机器学习、自然语言处理和语音识别等领域。
今天Spark相关内容的介绍就分享到这里,可以关注Spark专栏《Spark》,后续不定期分享相关技术文章。如果帮助到大家,欢迎大家点赞+关注+收藏,有疑问也欢迎大家评论留言!

