
- 1使用Git中遇到的问题_! [remote rejected] develop -> develop (pre-receiv
- 2yum install和apt-get install_yum install apt-get
- 3KEPServerEX 6安装并将数据推送到mysql数据库_kepserver数据写入mysql数据库
- 4两种方式彻底解决请求被中止- 未能创建 SSL-TLS 安全通道_软件装不上显示未能创建安全通道
- 5Spyder 快捷键
- 6【论文速读】| 在安全运营中心使用大语言模型来实现威胁情报分析工作流程的自动化
- 7【前端面试题】前端工程化、Webpack、Vite、Git项目管理相关问题
- 8MRCTF2020 Ezpop wp
- 9团灭LeetCode跳跃游戏(相关话题:贪心,BFS)_跳跃游戏is bfs
- 10使用docker部署EFK-7.8版本详细教程_efk的镜像包
使用Python爬虫雪球APP基金数据_雪球数据爬取
赞
踩
介绍
在本篇博客中,我们将介绍如何使用Python编程语言和一些常用库来爬取雪球网站的数据。雪球网站是一个提供股票、基金等金融信息的平台,我们将通过调用其API来获取用户和标题信息,并将数据保存到CSV文件中。
爬虫实现流程
一、数据来源分析
1、明确需求:明确采集的网站以及数据内容
(1)网址:雪球网-https://xueqiu.com
(2)数据:基金数据
2、抓包分析:分析基金数据;打开开发者工具:F12/右键点击检查选择网络
二、代码实现步骤
1、发送请求-模拟浏览器对于URL发送请求
2、存取数据-获取服务器返回响应数据
3、解析数据-提取所需数据
4、保存数据-保存表格文件<csv/Excel>中
爬取前的准备
1、requests库的安装
打开cmd输入 pip install requests
代码分析
一、导入必要的库
1. `import json`: 导入 Python 的 json 模块,用于处理 JSON 数据。
2. `import requests`: 导入 Python 的 requests 模块,用于发送 HTTP 请求。
以上是导入必要的库,代码一开始导入了json、requests和csv等库,用于处理JSON数据、发送HTTP请求和处理CSV文件。
二、创建CSV文件
1. `import csv`: 导入 Python 的 csv 模块,用于读写 CSV 文件。
2. `f = open('雪球.csv', mode='w', encoding='utf-8', newline='')`: 打开一个名为 '雪球.csv' 的文件,以写入模式('w'),指定编码为 UTF-8,并设置 newline='' 以避免写入空行。
3. `csv_writer = csv.DictWriter(f, fieldnames=['用户', '标题'])`: 创建一个 csv.DictWriter 对象,用于将字典数据写入 CSV 文件,指定字段名为 '用户' 和 '标题'。
4. `csv_writer.writeheader()`: 写入 CSV 文件的表头,即字段名。
创建CSV文件:通过打开文件对象并创建csv.DictWriter对象,定义了CSV文件的字段名和表头。
三、模拟浏览器
`headers = {...}`: 定义了模拟浏览器的请求头信息,包括 Cookie 和 User-Agent。
模拟浏览器:设置了请求头部信息,包括Cookie和User-Agent,模拟了浏览器的行为以访问API。
四、循环请求数据
`for i in range(0, 8)`: 进入一个循环,循环变量为 i,范围是从 0 到 7。
循环请求数据:通过循环8次,构建不同页数的API请求链接,发送请求并获取响应数据。
五、处理JSON数据
1、 `s = json.loads(res.text)`: 将响应的文本数据解析为 JSON 格式。
处理JSON数据:将响应文本数据转换为JSON格式,提取出需要的用户和标题信息。
2、 `data = s['list']`: 从 JSON 数据中获取键为 'list' 的值,这里假设 'list' 是 JSON 数据的一个键。
六、写入CSV文件
`csv_writer.writerow(dit)`: 将 'dit' 中的数据写入 CSV 文件。
写入CSV文件:将提取的用户和标题信息写入CSV文件,并在控制台打印输出。
其他代码:
1、`for i in data[1:]:`: 遍历 'data' 中的元素,从第二个元素开始(索引为 1)。
2、 `dit = {...}`: 创建一个字典 'dit',存储 '用户' 和 '标题' 的信息。
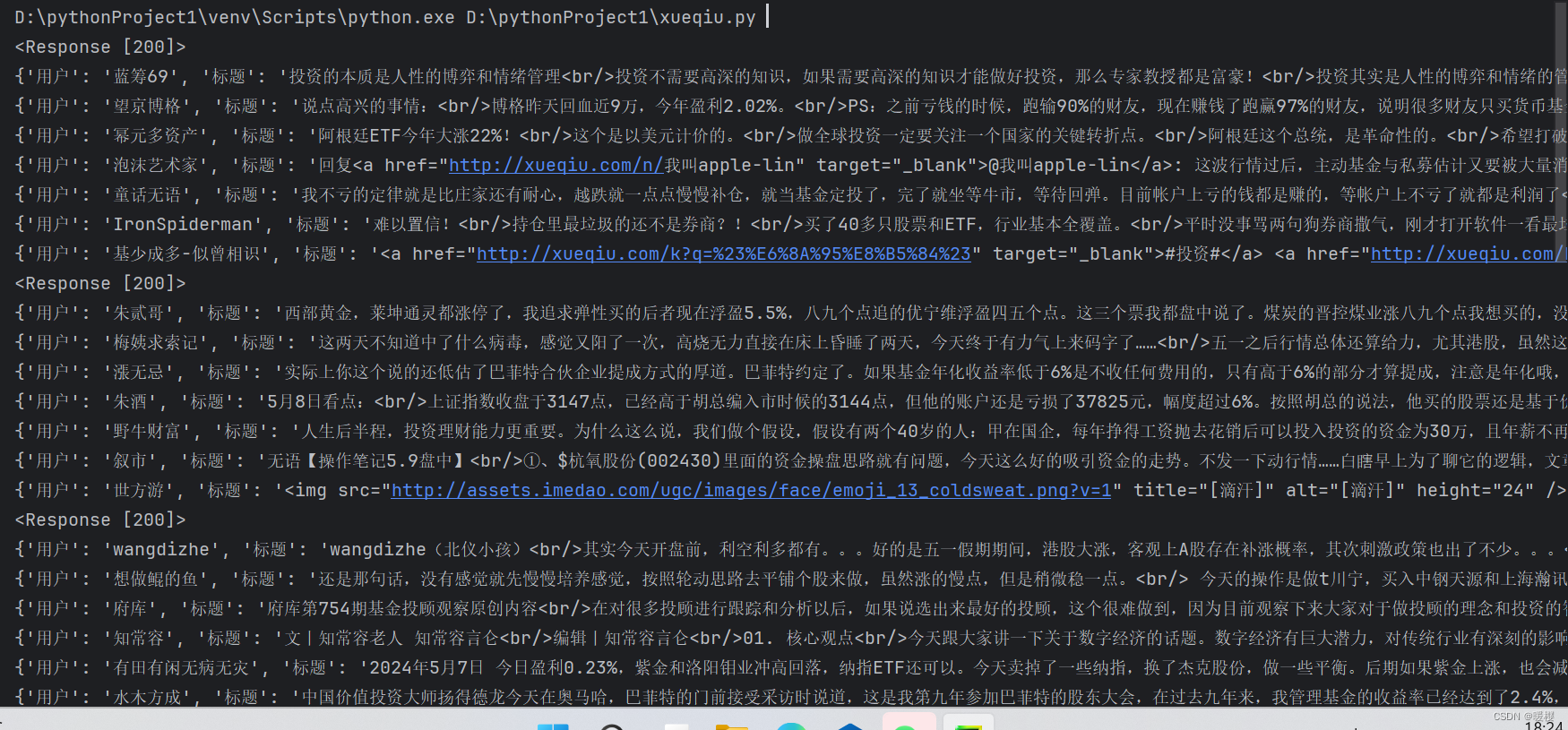
总结
通过以上代码分析,我们实现了从雪球网站APP获取数据并保存到CSV文件的功能。这个实践展示了如何利用Python编程和网络请求库来进行简单的数据爬取操作,为进一步的数据分析和处理提供了基础。
在实际应用中,需要注意网站的使用条款和隐私政策,避免对网站造成不必要的负担或侵犯用户隐私。同时,代码中也可以进一步优化,例如添加异常处理、日志记录等功能,以提高代码的稳定性和可维护性。
希望本篇博客能对您理解数据爬取和Python编程有所帮助,欢迎留言讨论和分享您的想法!
代码
- import json
-
- import requests
-
- import csv
-
- #创建文件对象
- f = open('雪球.csv', mode='w', encoding='utf-8', newline='')
- #fieldnames 字段名,表头第一行的数据
- csv_writer = csv.DictWriter(f, fieldnames=[
- '用户',
- '标题'
- ])
- csv_writer.writeheader()
- #模拟浏览器
- headers = {
- 'Cookie': 'xq_a_token=4150a23b09e99c9b40522a8a88ad25226263fc0b;xq-dj-token=4150a23b09e99c9b40522a8a88ad25226263fc0b;xq_id_token=eyJ0eXAiOiJKV1QiLCJhbGciOiJSUzI1NiJ9.eyJ1aWQiOjUyMTY4NTg3MDksImlzcyI6InVjIiwiZXhwIjoxNzE1Nzg2NTgzLCJjdG0iOjE3MTMxOTQ1ODMxNTUsImNpZCI6IldpQ2lteHBqNUgifQ.bAM5YDwUaXKbX5f-Z4GFwix2AkCvvgh1BPxb_1dpFhOJ7k0TgrqHQTDH3N9uJn-V2eXL431CwceJpBzQMM-4IcEnNz0uaWTxehX6sPwliTDY0kh1TEXDA6cjCl5hN_lfa4BTStrlzu8OkGl3GgL4j8V9dpU5Ii_Wd1YMxnKehxrnBZT-V905CQby6c95YlspUjDfze8Cn5nve8tM5fSBFx31jtA30Iabq3hKaxiFuw78BnueODdu_BIotAUVW_TnErgt5jzbGR-UtZmaqa2H6zPIOpzvTDi1xe5joKLbvcVOR7_F-OtpDFSmj7YoZwJmMwPUybSXu4xq65ISOm4Smw;u=5216858709;xq_is_login=1',
- 'User-Agent': 'Xueqiu iPhone 14.39'}
- #请求网址
- for i in range(0, 8):
- url = 'https://api.xueqiu.com/statuses/fundx/public/list.json?last_id=&page=1' + str(i + 1) + '&size=8'
- #发出请求
- res = requests.get(url=url, headers=headers)
- #查看是否成功
- print(res)
- res.encoding = 'utf-8'
- #response.text 获取响应文本数据 .json()获取响应json数据;.content获取二进制数据<影音>
- s = json.loads(res.text)
- data = s['list']
- for i in data[1:]:
- dit = {
- '用户': i['user']['screen_name'],
- '标题': i['description']
- }
- csv_writer.writerow(dit)
- print(dit)


