- 1日常运维(1)w命令,vmstat命令,top命令,sar命令,nload命令_vmstat -w 1
- 2git pull 提示Not possible to fast-forward,无法提交也无法更新
- 3Tensorflow--MNIST分类模型_mnist模型
- 4Flink checkpoint机制_flink sql采集checkpoint
- 5大模型从入门到应用——LangChain:模型(Models)-[大型语言模型(LLMs):基础知识]_langchain model适配
- 6JDBC 设置超时时间,避免sql查询时时间过长_jdbc超时时间
- 7MySql事务_read view 匹配条件规则
- 8Oracle 数据去重_oracle去重查询
- 9深入OceanBase分布式数据库:MySQL 模式下的 SQL 基本操作_oceanbase mysql
- 10实用干货丨Eolink Apikit 配置和告警规则的各种用法
6、大模型之RAG,即检索增强式生成(Retrieval Augmented Generation)_rag 增强的长文本生成
赞
踩
什么是RAG?
RAG,即检索增强式生成(Retrieval Augmented Generation),是一种结合了检索和生成两种方 法的自然语言处理技术。它利用检索技术从大量数据中快速找到相关信息,然后使用生成技术对这 些信息进行整合和创造,生成高质量的文本。
RAG的作用
-
提高生成文本的质量和准确性:通过检索技术,RAG可以确保生成的内容基于可靠的信息源,从而提高文本的准确性和质量,减少模型的生成幻觉。
-
增强生成文本的多样性:RAG可以从多个信息源中检索信息,使得生成文本的内容更加丰富和多样化。
-
提高生成速度:检索技术可以快速定位到相关信息,从而加快生成过程。
-
实现长文本生成:RAG可以处理长文本生成任务,因为它可以从多个信息源中检索和整合信息,生成连贯且内容丰富的长文本。
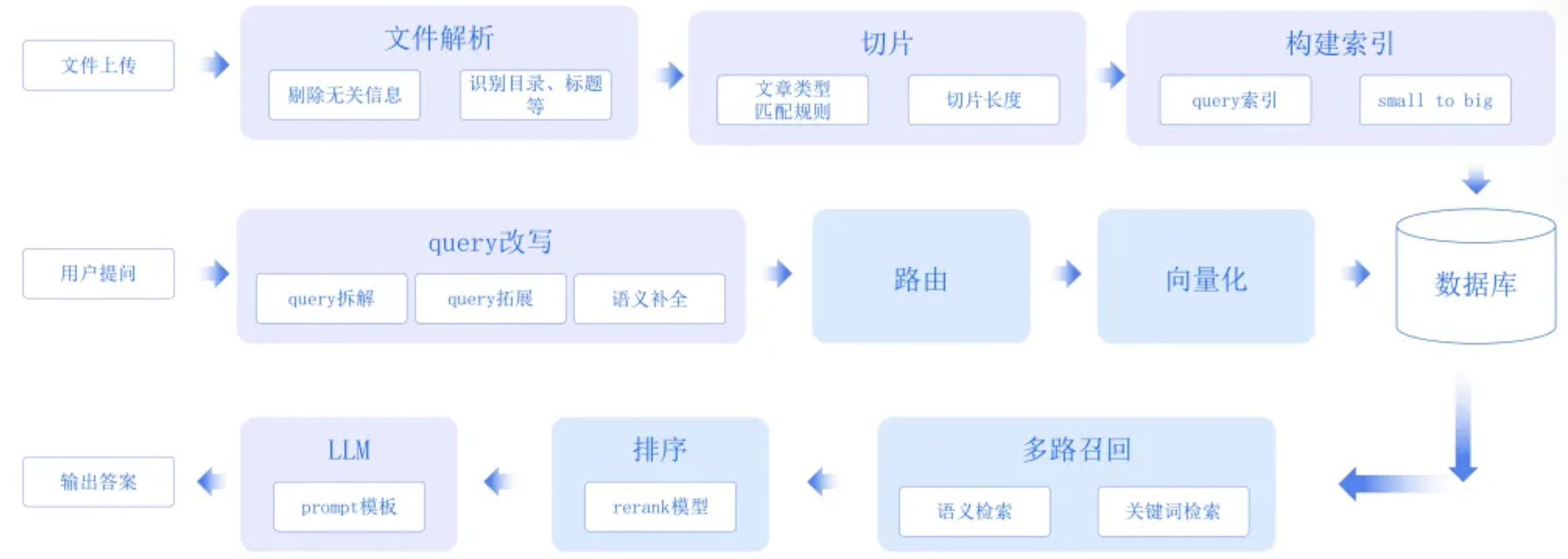
RAG每步难点和要解决的问题
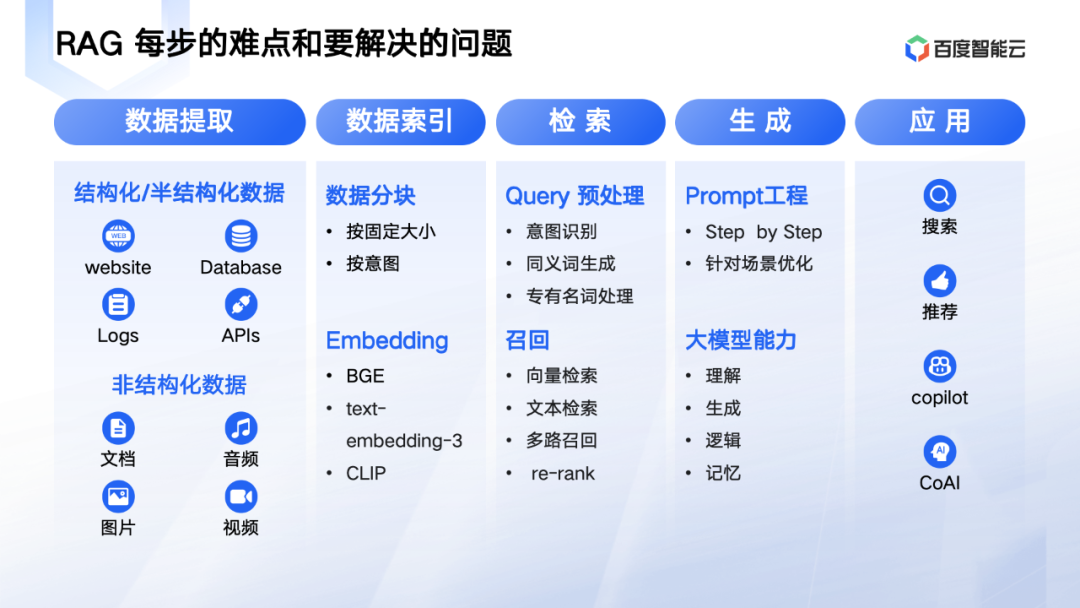
1、首先是数据提取。
这一步的核心是要把各种结构化,非结构化数据能提取出来,用于后面的处理。这里的复杂度主要是:
1.1 文件格式复杂,以 pdf 为例子,不光有文字,还夹杂有图表,图片里面又有文字。
1.2 文件有上下文,要把上文相关的元信息提取出来,后面就更容易处理。如果不提取元信息,那下一步数据分块,就容易切分错误。
2、其次数据索引。
这一步做好文档的切分, embedding 模型,把文件 embedding 成向量,才可以把向量存到向量数据库里面去。这里的难点又有两个:
2.1 数据切分,过大,过小都会有问题。所以一般是按照 300~400 个字节切分。还有处理更精细的,是按意图切分。
2.2 另外就是 embedding 模型,文本类的有 BGE,openAI 的 text-embedding-3;文图关联的只有 CLIP。现在这块的多模态模型是下一步重点。
3、然后就是检索。
检索主要分 query 预处理,召回两个步骤:
3.1 query 预处理主要的步骤是意图识别,同义词生成,专有名词生成等。
3.2 召回主要就是向量数据库的工作,要支持向量检索,文本检索,多路召回能力,召回之后重排技术。
4、最后是生成阶段。
检索出来的结果在给大模型之前,还要 prompt 优化,包括 prompt 加上 step by step ,针对场景的加上相应的提示词等。
RAG的优势
RAG(Retrieval-Augmented Generation)技术结合了信息检索和生成模型的优势,解决了许多传统语言模型的局限性,具体优势如下:
1. 减少模型的生成幻觉
生成幻觉(Hallucination)是指语言模型在生成内容时,有时会产生不准确或虚假的信息。RAG通过首先检索相关的真实信息,然后生成基于这些信息的回答,从而显著减少生成幻觉的发生,提高回答的准确性和可信度。
2. 知识及时更新
由于RAG依赖于外部知识库或文档的检索,系统可以更容易地通过更新这些外部资源来保持最新的知识。这意味着即使模型本身没有重新训练,也能通过更新检索数据库来反映最新的信息和变化。
3. 避免人工整理FAQ
传统的FAQ系统需要人工整理和维护,而RAG技术能够自动从大量的文档和知识库中检索和生成答案,减少了人工整理和更新FAQ的负担,提高了效率。
4. 增加了答案推理
RAG技术不仅能够检索相关信息,还可以利用生成模型进行复杂的答案推理。这使得系统不仅能够提供直接的事实性回答,还能对复杂问题进行更深层次的分析和解答。
5. 增加内容生成的可追溯性
由于RAG在生成答案时依赖于检索到的真实文档和数据,生成的内容具有可追溯性。用户可以追溯到答案来源,验证信息的准确性和可靠性,增强了系统的透明度和用户信任。
6. 增加问答知识范围的管理权限
通过使用RAG技术,系统管理员可以更好地管理和控制问答知识的范围。管理员可以通过更新和管理检索数据库,确保系统回答的内容在预期的知识范围内,避免提供不相关或不准确的信息。
智普RAG技术方案全景