
- 1Unity - Timeline 之 Changing clip play speed(调整剪辑播放速度)_unity timeline speed
- 2sql语句之根据起始结束日期获取每一天、周、月、年_sql根据起始和结束生成结果
- 3python常用pandas函数nlargest / nsmallest及其手动实现_python nlargest
- 4python下的橡皮线_ObjectARX常用类和函数
- 5mysql 回收内存空间_MySQL ibdata 存储空间的回收
- 6Python 数据分析:Matplotlib 绘图_使用matplotlib绘制,where='post
- 7Halcon三维测量以及demo_halcon 三维测量
- 8【Unity3D 教程系列第 14 篇】如何解决启动 Unity 时,一直卡在 Loading 界面不动的问题?_unity启动卡在lmporting
- 9激光SLAM原理
- 10Unity Shader 画网格_unity shader 3dgrid网格效果
人脸识别项目总结
赞
踩
前言
本文是对人脸识别项目的一个总结,以此来进一步巩固所学算法知识。
切入点进行总结概括:
- 算法的需求及应用场景
- 算法的调研和初步方案的制定
- 数据的准备(包括数据标注和数据增强)
- 算法的介绍(包括输入输出,loss,backbone,训练细节等)
- 算法优化(为什么要这样改?)
- 算法是否兼顾到参数量和推理速度等
一、算法的需求及应用场景
该项目主要目的是将人脸识别各个部分的算法移植到嵌入式端,并且能完成人脸识别的任务。本人在该项目中主要负责数据采集,模型搭建,精度优化,训练调参等任务。
二、算法的调研和初步方案的制定
在人脸识别项目上,最开始是参照市面上已存在的开源代码进行学习和分析。人脸识别主要分为三个部分:人脸检测、人脸对齐(关键点检测)、人脸比对。前两个部分是使用MTCNN网络,而人脸比对可基于人脸分类进行修改。于是开始对图像分类的神经网络进行研究,最经典的ResNet就成为主要的研究对象。
三、数据准备
1. 数据集准备
尽可能收集网上所存在的开源数据集,如:VGGFace2(330万张图片,9000个不同的人)、MS-Celeb-1M。利用这些开源数据集进行训练,后面发现验证推理的效果不是很理想。因为项目工程中的代码是没有预训练模型的,需要从头开始训练。
于是在数据集上,参照SeetaFace的经验——增加亚洲人脸的占比可以使得检测效果变好(因为我们的应用市场主要还是国内,所以增加亚洲人的比重会起到更好的效果)。
后续就利用爬虫来采集中国,日本,韩国的明星照片。主要是从百度网站-百度图片上检索前300页的明星图片,然后利用MTCNN进行人脸检测进行筛选。最后筛选出40+万张图片加入到我们的训练集。
2. 数据增强
数据准备的第二点就是做数据增强,主要是两个操作:
- 图像随机水平翻转(keras自带的操作方式:
horizontal_flip=True) - 自定义图像预处理参数整定(具体如何整定下面会讲到)
四、算法介绍
[1] Multi-task convolutional neural network(MTCNN)
MTCNN是网络上比较经典的人脸检测模型,由于开源的效果也不错,且占用空间很小,只有8MB不到,于是就直接移植了。没有涉及太多的更改。
实现流程:
1. 构建图像金字塔
首先将图像进行不同尺度的变换,构建图像金字塔,以适应不同大小的人脸以进行检测。
2. P-Net
全称为Proposal Network,基本构造是一个全卷积网络(FCN)。通过一个FCN,对构建完成的图像金字塔进行初步特征提取与标定边框,并进行Bounding-Box Regression调整窗口与NMS进行大部分窗口的过滤。
P-Net是一个人脸区域的区域建议网络,该网络的将特征输入结果三个卷积层之后,通过一个人脸分类器判断该区域是否是人脸,同时使用边框回归和一个面部关键点的定位器来进行人脸区域的初步提议,该部分最终将输出很多张可能存在人脸的人脸区域,并将这些区域输入R-Net进行进一步处理。这一部分的基本思想是使用较为浅层、较为简单的CNN快速生成人脸候选窗口。
3. R-Net
全称为Refine Network,基本构造也是一个全卷积神经网络,相对于P-Net来说,多了一个全连接层,因此对于数据的筛选会更加严格。
经过P-Net后,会留下许多预测窗口,将其送入R-net,R-net会滤除大量效果比较差的候选框,再对结果进行Bounding-Box Regression和NMS进一步优化预测结果。
因为P-Net的输出只是具有一定可信度的可能的人脸区域,在这个网络中,将对输入进行细化选择,并且舍去大部分的错误输入,并再次使用边框回归和面部关键点定位器进行人脸区域的边框回归和关键点定位,最后将输出较为可信的人脸区域,供O-Net使用。
对比与P-Net使用全卷积输出的1x1x32的特征,R-Net使用在最后一个卷积层之后使用了一个128的全连接层,保留了更多的图像特征,准确度性能也优于P-Net。R-Net的思想是使用一个相对于P-Net更复杂的网络结构来对P-Net生成的可能是人脸区域区域窗口进行进一步选择和调整,从而达到高精度过滤和人脸区域优化的效果。
4. O-Net
全称为Output Network,基本结构是较为复杂的卷积神经网络,相对于R-Net多了一个卷积层。O-Net会通过更多的监督来识别面部的区域,而且会对人的面部特征点进行回归,最终输出五个人脸面部特征点。是一个更复杂的卷积网络,该网络的输入特征更多,在网络结构的最后同样是一个更大的256的全连接层,保留了更多的图像特征,同时再进行人脸判别、人脸区域边框回归和人脸特征定位,最终输出人脸区域的左上角坐标和右下角坐标与人脸区域的五个特征点。O-Net拥有特征更多的输入和更复杂的网络结构,也具有更好的性能,这一层的输出作为最终的网络模型输出。O-Net的思想和R-Net类似,使用更复杂的网络对模型性能进行优化。
[2] ResNet-50
ResNet的设计初衷是为了解决网络退化问题。随着网络层数的增加,会产生许多对减小损失提供不到帮助的网络层,这些层不仅会使得网络更为复杂,也有可能使得损失不降反增。ResNet因此诞生,主要应用于图像的分类上。
模型输入
ResNet-50模型的输入就是之前MTCNN模块的输出,即尺寸大小为224×224的人脸图片。
Loss
项目中用到的损失函数为多分类交叉熵损失:CategoricalCrossentropy, 下图为其公式。一般配和softmax用于分类。
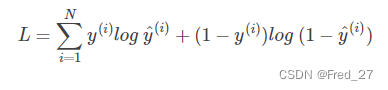
Backbone
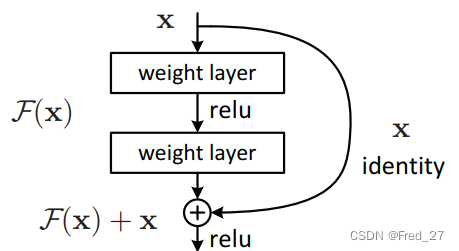
ResNet-50的Backbone很简单。主要就是引入了残差模块。ResNet通过残差恒等映射,只学习残差与输入之间的关系,即F(x)和x。当网络到达最优时,只学习residual,那么这条分支就会慢慢趋近于0,而identity就会成为需要的支路完成模型构建。
如下图所示,红色框的部分就是ResNet-50的Backbone。
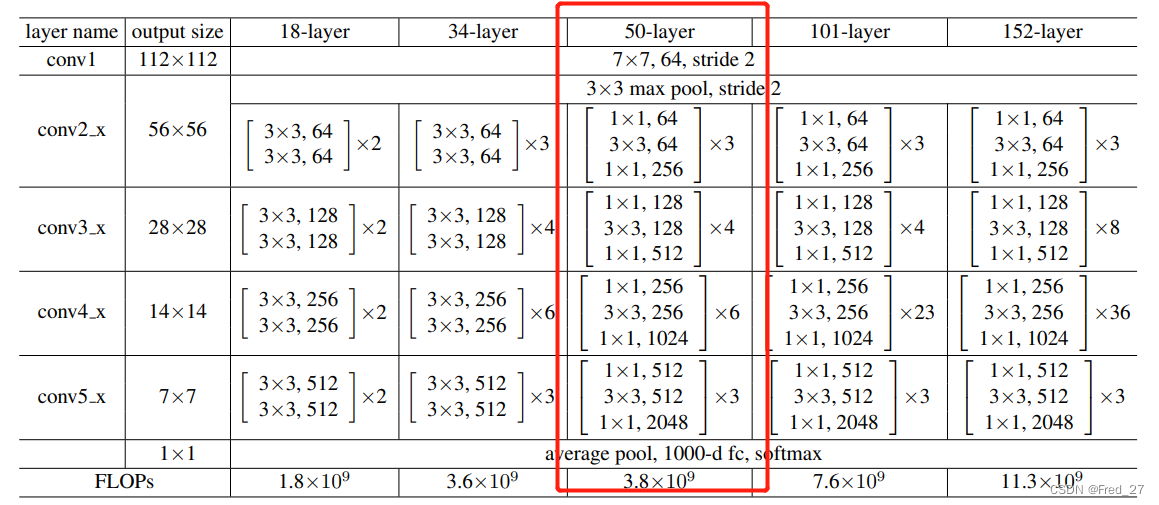
输出
ResNet-50以全连接层作输出层,输出维度为:1×类别数。
算法优化
(1)更改图像预处理
补上之前说的数据增强部分——图像预处理操作。许多开源代码都是直接在三通道上减去各自通道的均值。参照了FaceNet的预处理方式:减去均值做差,再除以标准差。这样最后的识别率提升了1.6%。但是其中具体是为什么查了很多资料,也没有解释清楚。
def pre_function(img):
# img = im.open('test.jpg')
# img = np.array(img).astype(np.float32)
# img = (img - [_R_MEAN, _G_MEAN, _B_MEAN])
mean1, mean2, mean3 = np.mean(img[:, :, 0]), np.mean(img[:, :, 1]), np.mean(img[:, :, 2])
std1, std2, std3 = np.std(img[:, :, 0]), np.std(img[:, :, 1]), np.std(img[:, :, 2])
i1 = (img[:, :, 0] - mean1) / std1
i2 = (img[:, :, 1] - mean2) / std2
i3 = (img[:, :, 2] - mean3) / std3
img = np.stack([i1, i2, i3], axis=2)
return img
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
(2)优化学习率
原本设定的学习率为恒定值,这样在收敛到全局最优点的时候来回振荡,要让学习率随着训练轮数不断按指数下降,收敛梯度下降地学习步长。于是我给学习率增加了cos衰减。加了cos衰减在前面也不会过多降低训练速度,后续下降得也不明显,但是损失变得更小了。
def scheduler(now_epoch):
initial_lr = 0.1
end_lr_rate = 0.1 # end_lr = initial_lr * end_lr_rate
rate = ((1 + math.cos(now_epoch * math.pi / epochs)) / 2) * (1 - end_lr_rate) + end_lr_rate # cosine
new_lr = rate * initial_lr
return new_lr
- 1
- 2
- 3
- 4
- 5
- 6
(3)更改优化器
将原本的优化器SGD改为Adam。在很多论文中,实验用到的优化器都是SGD,所以很多大佬在写开源代码时都是用的SGD优化器。但其实Adam是目前效果比较好的,也是业界认可的主流优化器之一。下面来简单聊聊这两种优化器。
SGD (Stochastic gradient descent)
随机梯度下降,每次只通过随机选取的数据对 {x_i, y_i}来求梯度,计算速度快,但是由于每次只选取一个样本对进行更新,很可能导致 损失函数震荡的现象,不易收敛。若加上动量的话会加速收敛。对于SGD来说,其学习率都是单调的,即单调递减,因此,这两类算法会使得学习率不断递减,最终收敛到0,模型也得以收敛。
Adam
Adam 算法和传统的随机梯度下降不同。随机梯度下降保持单一的学习率(即 alpha)更新所有的权重,学习率在训练过程中并不会改变。而 Adam 通过计算梯度的一阶矩估计和二阶矩估计而为不同的参数设计独立的自适应性学习率 Adam 算法的提出者描述其为两种随机梯度下降扩展式的优点集合,即:
适应性梯度算法(AdaGrad)为每一个参数保留一个学习率以提升在稀疏梯度(即自然语言和计算机视觉问题)上的性能。
均方根传播(RMSProp)基于权重梯度最近量级的均值为每一个参数适应性地保留学习率。这意味着算法在非稳态和在线问题上有很有优秀的性能。
但是对于Adam,其学习率二阶估计是取固定时间窗口内的动量累加,随着窗口和数据的变化,二阶动量可能会产生的波动,从而引起学习率震荡,导致模型无法收敛。
(4)调整mini-batch的大小
深度学习网络模型训练困难的原因是,cnn包含很多隐含层,每层参数都会随着训练而改变优化,所以隐层的输入分布总会变化,每个隐层都会面临协方差偏移(covariate shift)的问题。这就造成,上一层数据需要适应新的输入分布,数据输入激活函数时,会落入饱和区,使得学习效率过低,甚至梯度消失。而BN就是通过归一化手段,将每层输入强行拉回均值0方差为1的标准正态分布,这样使得激活输入值分布在非线性函数梯度敏感区域,从而避免梯度消失问题,大大加快训练速度。


