
- 1我的测试成长心得_测试的成长思路怎么写
- 2压缩感知常用测试集 SET5, SET11, SET14下载_set5数据集下载
- 3Qt 制作安装程序(使用 binarycreator.exe)
- 4视觉SLAM理论与实践第四节课习题_在优化中经常会遇到矩阵微分的问题。例如,当自变量为向量 x,求标量函数 u(x) 对 x
- 5vscode官方网站下载,显示网络错误。_vscode下载一直显示网络问题
- 6python 淘宝联盟_Python 淘宝联盟-佣金设置 批量设置佣金和服务费
- 7用python制作简单的小游戏,用python设计一个小游戏_python编写简单小游戏
- 8关于 java.lang.NullPointerException: null 的一种情况及处理_cause: java.lang.nullpointerexception] with root c
- 9dicom坐标系以及确定两平面交点_dicom location imageposition
- 10阿里云服务器租用价格表最新发布,持续更新
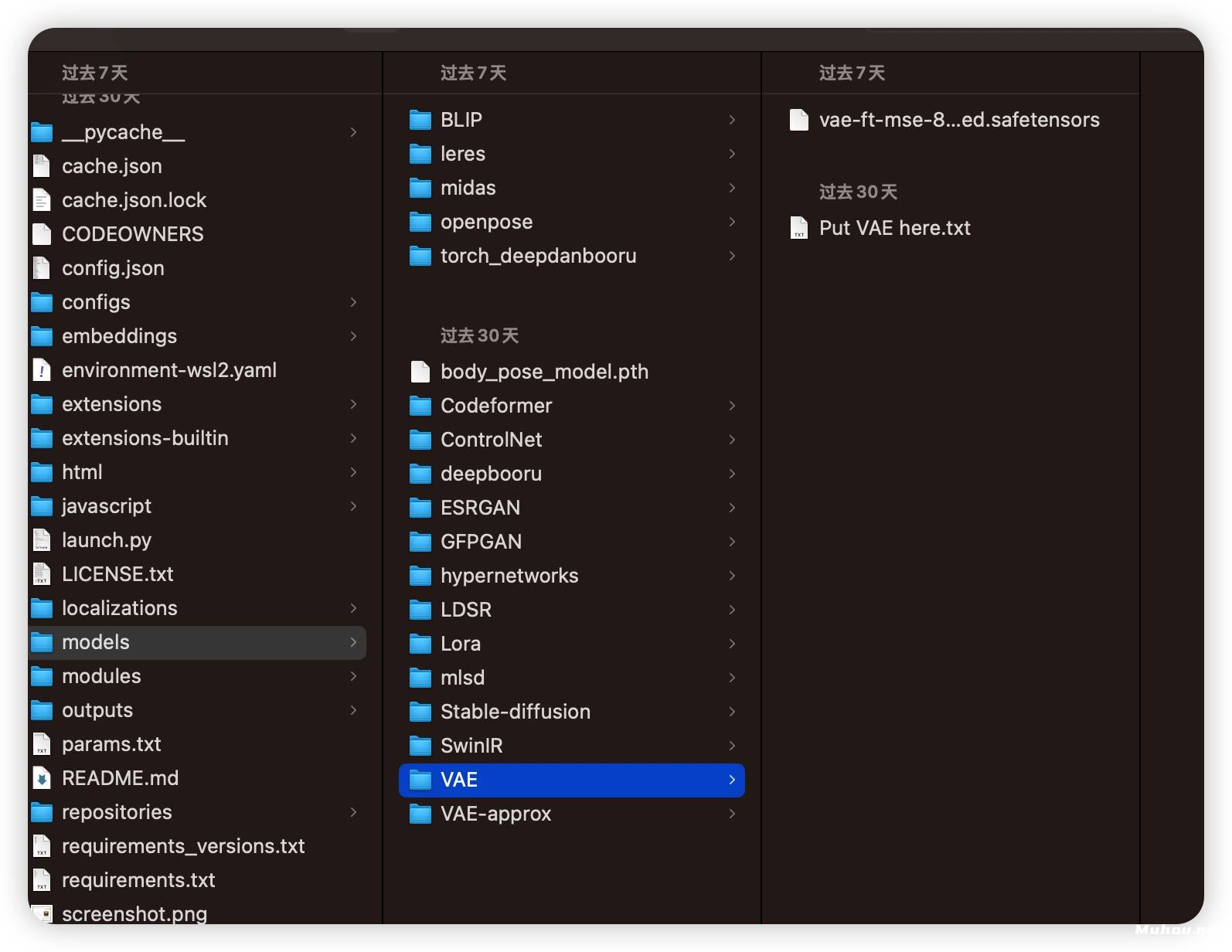
AI绘画软件Stable Diffusion模型/Lora/VAE文件存放位置_stabilityai/stable-diffusion-2-inpainting 512-inpa
赞
踩
型下载说明(下载模型后输入对应参数即可生成)
建议直接去civitai.com找模型,如果无法找到可以在幕后模型区找也可以去,
下载好后放入对应的文件夹。进入127.0.0.1:7680 左上角刷新即可看到新的模型。
模型种类
大模型
大模型特指标准的latent-diffusion模型。拥有完整的TextEncoder、U-Net、VAE。
由于想要训练一个大模型非常困难,需要极高的显卡算力,所以更多的人选择去训练小型模型。
CKPT
CKPT格式的全称为CheckPoint(检查点),完整模型的常见格式,模型体积较大,一般单个模型的大小在7GB左右。
文件位置:该模型一般放置在*\stable-diffusion-webui\models\Stable-diffusion目录内。
小模型
小模型一般都是截取大模型的某一特定部分,虽然不如大模型能力那样完整,但是小而精,因为训练的方向各为明确,所以在生成特定内容的情况下,效果更佳。
常见微调模型:Textual inversion (Embedding)、Hypernetwork、VAE、LoRA等,下面一一进行介绍。
VAE
全称:VAE全称Variational autoencoder。变分自编码器,负责将潜空间的数据转换为正常图像。
后缀格式:后缀一般为.pt格式。
功能描述:类似于滤镜一样的东西,他会影响出图的画面的色彩和某些极其微小的细节。大模型本身里面自带 VAE ,但是并不是所有大模型都适合使用VAE,VAE最好搭配指定的模型,避免出现反效果,降低生成质量。
使用方法:设置 -> Stable-Diffusion -> 模型的 VAE (SD VAE),在该选项框内选择VAE模型。
文件位置:该模型一般放置在*\stable-diffusion-webui\models\VAE目录内。
Embedding
常见格式为pt、png、webp格式,文件体积一般只有几KB。
风格模型,即只针对一个风格或一个主题,并将其作为一个模块在生成画作时使用对应TAG在Prompt进行调用。
使用方法:例如本站用数百张海绵宝宝训练了一个Embedding模型,然后将该模型命名为HMBaby,在使用AI绘图时加载名称为HMBaby的Embedding模型,在使用Promat时加入HMBaby的Tag关键字,SD将会自动调用该模型参与AI创作。
文件位置:该模型一般放置在*\stable-diffusion-webui\embeddings目录内。
Hypernetwork
一般为.pt后缀格式,大小一般在几十兆左右。这种模型的可自定义的参数非常之多。
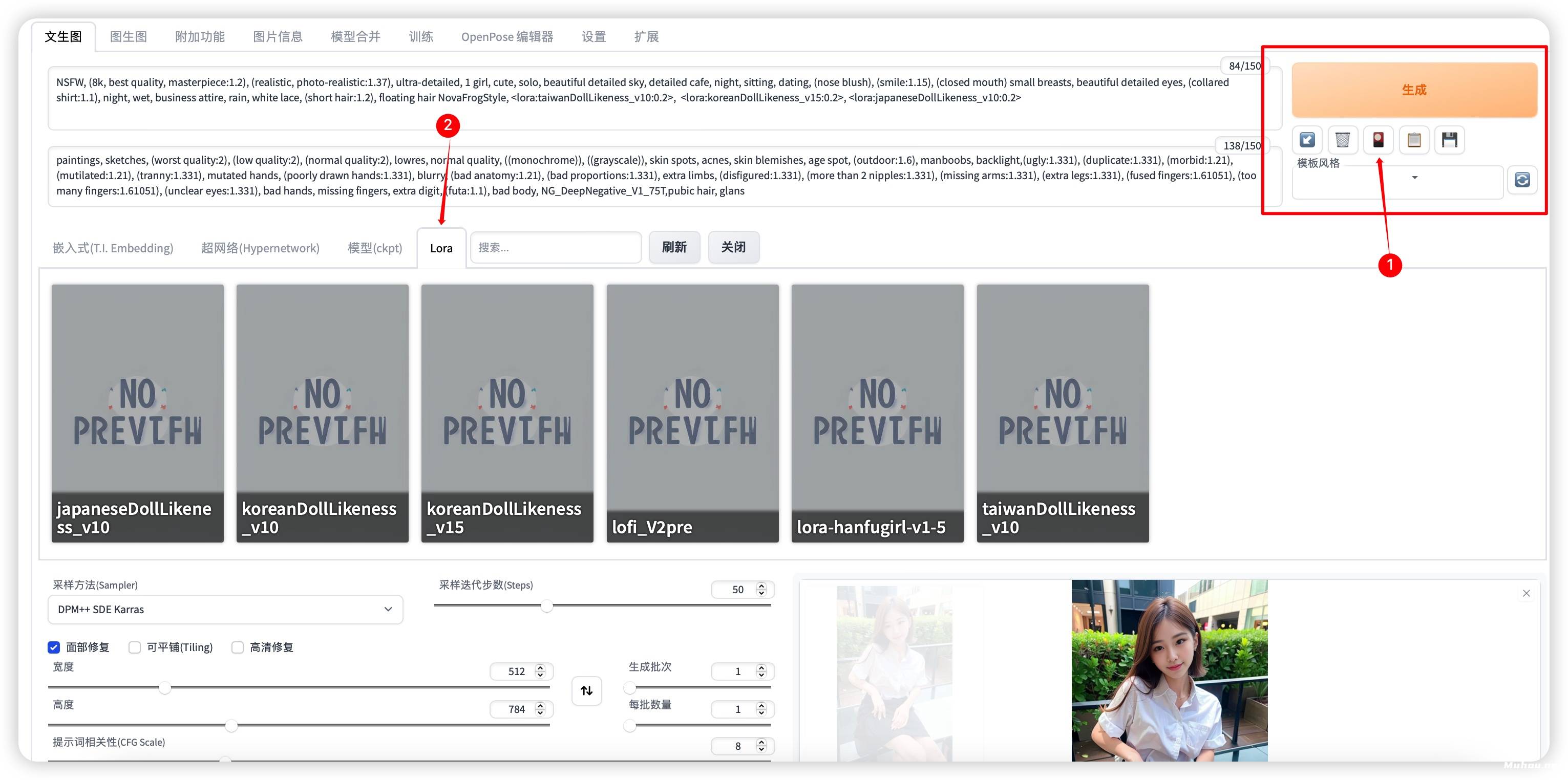
使用方法:使用方法:在SD的文生图或图生图界面内的生成按钮下,可以看到一个红色的图标,该图标名为Show extra networks(显示额外网络),点击该红色图标将会在本页弹出一个面板,在该面板中可以看到Hypernetwork选项卡。
文件位置:该模型一般放置在*\stable-diffusion-webui\models\hypernetworks目录内。
LoRA
LoRA的模型分两种,一种是基础模型,一种是变体。
目前最新版本的Stable-diffusion-WebUI原生支持Lora模型库,非常方便使用。
使用方法:在SD的文生图或图生图界面内的生成按钮下,可以看到一个红色的图标,该图标名为Show extra networks(显示额外网络),点击该红色图标将会在本页弹出一个面板,在该面板中可以看到Lora选项卡,在该选项卡中可以自由选择Lora模型,点击想要使用的模型将会自动在Prompt文本框中插入该Lora模型的Tag名称。
基础模型
名称一般为chilloutmix*,后缀可能为safetensors或CKPT。
基础模型存放位置:*\stable-diffusion-webui\models\Stable-diffusion目录内。
变体模型
变体模型存放位置:*\stable-diffusion-webui\models\Lora目录内。
是放在extensions下的,sd-webui-additional-networks文件夹下的models文件夹里的lora!!
不是主文件夹下的models,别放错了!!!
模型后缀解析
| 格式 | 描述 |
|---|---|
| .ckpt | Pytorch的标准模型保存格式,容易遭受Pickle反序列化攻击。 |
| .pt | Pytorch的标准模型保存格式,容易遭受Pickle反序列化攻击。 |
| .pth | Pytorch的标准模型保存格式,容易遭受Pickle反序列化攻击。 |
| .safetensors | safetensors格式可与Pytorch的模型相互格式转换,内容数据无区别。 |
| 其它 | webui 特殊模型保存方法:PNG、WEBP图片格式。 |
Safetensors格式
- Safetensors格式所生成的内容与ckpt等格式完全一致(包括NFSW)。
- Safetensors格式拥有更高的安全性,
- Safetensors比ckpt格式加载速度更快
- 该格式必须在2023年之后的Stable Diffusion内才可以使用,在此之间的SD版本内使用将无法识别。
- Safetensors格式由Huggingface推出,将会逐渐取代ckpt、pt、pth等格式,使用方法上与其它格式完全一致。
Pickle反序列化攻击
可以将字节流转换为一个对象,但是当我们程序接受任意输入时,如果用户的输入包含一些恶意的序列化数据,然后这些数据在服务器上被反序列化,服务器是在将用户的输入转换为一个对象,之后服务器就会被任意代码执行。
模型训练
Embedding (Textual inversion)
可训练:画风√ 人物√ | 推荐训练:人物
配置要求:显存6GB以上。
训练速度:中等 | 训练难度:中等
综合评价:☆☆☆
Hypernetwork
可训练:画风√ 人物√ | 推荐训练:画风
配置要求:显存6GB以上。
训练速度:中等 | 训练难度:难
综合评价:☆☆
评价:非常强大的一种模型,但是想训练好很难,不推荐训练。
LoRA
可训练:画风? 人物√ 概念√ | 推荐训练:人物
配置要求:显存8GB以上。
训练速度:快 | 训练难度:简单
综合评价:☆☆☆☆
评价:非常好训练 好出效果的人物训练,配置要求低,图要求少。
备注:LoRA 本身也应该归类到 Dreambooth,但是这里还是分开讲。
Dreambooth / Native Train
可训练:画风√ 人物√ 概念√ | 推荐训练:Dreambooth 推荐人物,Native Train 推荐画风
配置要求:显存12GB以上。
训练速度:慢 | 训练难度:可以简单可以很难
综合评价:☆☆☆☆☆
评价:微调大模型,非常强大的训练方式,但是使用上会不那么灵活,推荐训练画风用,人物使用 LoRA 训练。
DreamArtist
显存要求6GB(4GB应该也可以),只需要(也只能)使用一张图完成训练,一般用于训练人物(画风没法抓住主次),优点是训练要求极低,成功率高,缺点是容易过拟合,并且不像Embedding可以跨模型应用,这个训练时使用什么模型应用时就要用什么,哪怕调一下CLIP参数生成结果都会完全跑飞。推荐每250步保存模型,后期用X/Y图脚本进行挑选。
模型后缀
仓库内一般存在多个模型文件,文件名后缀各不相同,这里简单介绍下文件名常见后缀及其含义:
ControlNet
ControlNet比之前的img2img要更加的精准和有效,可以直接提取画面的构图,人物的姿势和画
面的深度信息等等。有了它的帮助,就不用频繁的用提示词来碰运气,抽卡式的创作了。
instruct-pix2pix
在 stable-diffusion-webui 中的img2img专用模型 自然语言指导图像编辑 生成速度极快 ,仅需要几秒的时间。
FP16、FP32
代表着精度不同,精度越高所需显存越大,效果也会有所提升。
512|768
代表着默认训练分辨率时512X512还是768X768,理论上默认分辨率高生成效果也会相应更好。
inpaint
代表着是专门为imgtoimg中的inpaint功能训练的模型,在做inpaint时效果会相对来说较好。
depth
代表此模型是能包含处理图片深度信息并进行inpainting和img2img的
EMA
模型文件名中带EMA一般意味着这是个用来继续训练的模型,文件大小相对较大
与之相比,正常的、大小相当较小的那个模型文件是为了做推理生成的
对于那些有兴趣真正理解发生了什么的人来说,应该使用EMA模型来进行推理
小模型实际上有EMA权重。而大模型是一个 “完整版”,既有EMA权重,也有标准权重。因此,如果你想训练这个模型,你应该加载完整的模型,并使用use_ema=False。
EMA权重
就像你作为一个学生在接受训练时,也许你会在最后一次考试表现较差,或者决定作弊并记住答案。所以一般来说,通过使用考试分数的平均值,你可以更好地了解到学生的表现,
由于你不关心幼儿园时的分数,如果你只考虑去年的分数(即只用一组最近的实际数据值来预测),你会得到MA(moving average 移动平均数). 而如果你保留整个历史,但给最近的分数以更大的权重,则会得到EMA(exponential moving average 指数移动平均数)。
这对具有不稳定训练动态的GANs来说是一个非常重要的技巧,但对扩散模型来说,它其实并不是那么重要。
VAE
VAE模型文件并不能和正常模型文件一样独立完成图片生成。

