- 1游戏平台如何定制开发?
- 2C++面试 -操作系统-代码能力:磁盘文件系统、虚拟文件系统与文件缓存
- 3Unity VR 开发教程 OpenXR+XR Interaction Toolkit(八)手指触控 Poke Interaction_unityvr开发教程
- 4历史股价分析-python_numpy下载成交日期,开市价,成交最高值,成交最低值,收市价
- 5多线程与多进程的优缺点_多进程和多线程的优缺点
- 6机器学习系列(3)_逻辑回归应用之Kaggle泰坦尼克之灾
- 7Python四 —— 多进程和多线程实际使用和对比_python多线程和多进程哪个快
- 8数据可视化分析大屏全屏系统地图应用之福建福州地图_福建可视化大屏
- 9面试官:讲一讲Mybatis插件的原理及如何实现?
- 10深度学习(Deep Learning)概述_深度学习 自动驾驶
丝析发解丨理想的数据库架构是怎样的
赞
踩
从数据库角度看,大多企业关键业务的特点是:主要操作是交易型(OLTP),也要执行一些分析型(OLAP)操作。对于这样的应用,最理想的数据库架构是什么?是SQL Server/MySQL/PostgreSQL这样单机数据库?还是Oracle RAC这样的基于共享存储的集群?或者是OceanBase、TiDB这样的share nothing分布式集群?
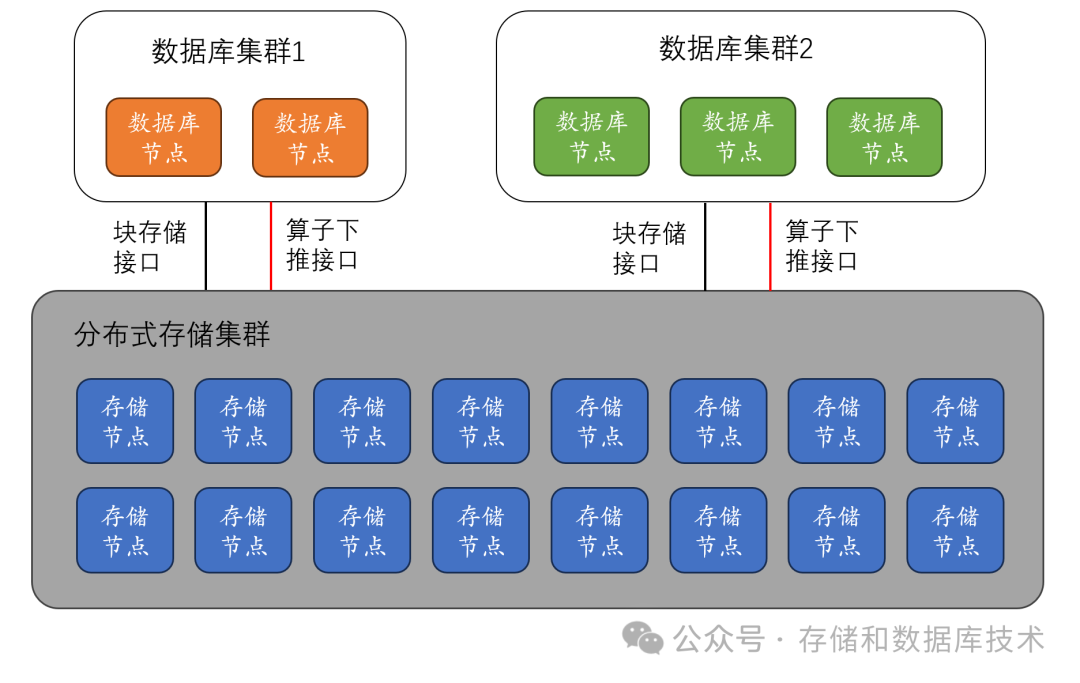
在我看来,理想的数据库架构是:基于共享存储的集群 + 全闪分布式存储 + 算子下推。为什么?
1、为什么不是share nothing的分布式数据库?
分布式数据库的优点是:横向可扩展(scale-out)能力很强、总体聚合性能高、处理分析型负载的能力强。
缺点是:
(1)相对于集中式数据库来说,分布式数据库平均单节点事务处理能力比较低,主要原因是分布式事务处理流程更复杂;
(2)分布式数据库的架构更加复杂,运维成本比较高,精通分布式数据库的专家比较少,故障排查,性能调优等,都比较困难;
(3)分布式数据库对复杂的SQL语句支持不好,例如:触发器、存储过程、JOIN等等,企业应用往往更喜欢使用复杂的SQL语句;
(4)分布式数据库自己管硬盘,少了一层存储抽象,也丢失了很多能力。专业存储都支持快照、克隆、高速的远程复制等,让备份更方便。专业存储支持EC,比三副本每TB成本更低;
(5)存算一体架构,存储和计算强绑定,配比是固定的,无法单独对存储扩容,也不能单独扩容计算能力。
2、为什么不是单机版数据库?
相对于基于共享存储的数据库集群,对单机版数据库定期做冷备份,故障时用冷备数据来恢复业务,故障恢复时间比较长,可用性不高。
另外,PostgreSQL 和 MySQL 的高可用方案复杂,管理成本比较高。
3、为什么是全闪分布式存储,而不是全闪阵列?
全闪阵列是专用硬件,成本比较高,也有单一厂商锁定问题。一般来说,分布式存储也是软件定义存储(SDS),标准化服务器,价格透明,也没有被单一硬件厂商锁定的问题。
全闪阵列一般分为高端、低端等不同系列,高端阵列价格很高,低端阵列可扩展性比较差,
4、为什么需要算子下推?
多数企业应用,并不是只有单纯的交易型操作,也有一些分析型操作。基于共享存储的集群数据库不擅长完成大规模分析型任务,外部存储系统与运行数据库的主机之间带宽有限,如果能够把这些分析型任务拆分之后下发到分布式存储节点上去执行,存储节点把执行结果返回给主机,在主机和存储节点之间,不再需要很高的网络带宽。这将会大大提升执行效率,缩短执行时间。

作者简介
黄岩,云和恩墨分布式存储软件总架构师,十余年存储研发经验,在NAS和备份领域有深入钻研,曾担任某NAS产品性能SE,负责产品性能调优工作,该产品在2011年打破了SPESsfs性能测试世界纪录。
「墨读时刻」特别节目黄岩人物专访即将上线,听一位存储老兵讲述摸爬滚打的这些年和对未来自研存储的洞察,敬请期待... ...


数据驱动,成就未来,云和恩墨,不负所托!
云和恩墨创立于2011年,以“数据驱动,成就未来”为使命,是智能的数据技术提供商。我们致力于将数据技术带给每个行业、每个组织、每个人,构建数据驱动的智能未来。
云和恩墨在数据承载(分布式存储、数据持续保护)、管理(数据库基础软件、数据库云管平台、数据技术服务)、加工(应用开发质量管控、数据模型管控、数字化转型咨询)和应用(数据服务化管理平台、数据智能分析处理、隐私计算)等领域为各个组织提供可信赖的产品、服务和解决方案,围绕用户需求,持续为客户创造价值,激发数据潜能,为成就未来敏捷高效的数字世界而不懈努力。