
- 1赋能AI原生应用开发:百度智能云千帆AppBuilder正式开放服务
- 2React创建项目(保姆级讲解,配置文件详细介绍)_创建react项目
- 3WDS部署及自动安装客户端
- 4Python开发【模块】:Urllib(二)
- 5friewall 常用命令_failwall 命令
- 6ThinkPHP下访问www.xxx.com访问成功www.xxx.com/后加上index、admin等报错
- 7利用spring boot和mybatis构建接口_spring 和mybatis建立关系依靠哪个接口
- 8避坑宝典|win11升级最新预览体验版bug梳理_ae此程序不能在hyper-v下运行
- 9【深度学习】Logistic回归算法和向量化编程。全md文档笔记(代码文档已分享)
- 10Docker安装JDK1.8版本_docker安装jdk1.8离线
论文阅读_训练大模型用于角色扮演
赞
踩
英文名称: Character-LLM: A Trainable Agent for Role-Playing
中文名称: 角色-LLM:训练Agent用于角色扮演
文章: [https://arxiv.org/abs/2310.10158](https://arxiv.org/abs/2310.10158)
作者: Yunfan Shao, Linyang Li, Junqi Dai, Xipeng Qiu
机构: 复旦大学计算机学院
日期: 2023-11-16
引用次数: 5
- 1
- 2
- 3
- 4
- 5
- 6
- 7
1 读后感
论文的目标是使用模型来模拟具体的人物角色,这个想法很有意思,有点类似于反思过程的逆向操作。反思的过程是从具体到抽象,我们根据生活中的具体场景和事件进行思考,通过层层抽象最终形成对一个人的理解。而角色扮演则相反,例如模拟一个历史人物,首先从维基百科获取这个人的信息,这些信息通常是抽象的,需要将这些抽象内容具体化,场景化,使其变成鲜活的经历,然后用这些经历来训练模型。
在从具体到抽象的过程中,数据量逐渐减少,因此可以使用提示,有限的上下文就足够支持;而在文中提出的从抽象到具体的扩展过程中,数据量逐渐增多,使用提示就会比较困难,也需要更多的资源,因此作者考虑使用这些新数据来训练模型,通过精调模型的方式来解决问题。
另一个有趣的点是,为了保持角色的完整性,需要让大模型忽略一些角色不应该拥有的知识,例如贝多芬不应该懂得编程。作者通过创建对话的方式来引导确定角色的知识范围,从而创建数据供大模型训练。这种攻防交替的过程有点像“左右互搏”。
我认为,这种逆向思维非常有意思。另一个小发现是:我们可以考虑利用大模型进行一些细化和扩写的工作,比如根据贝多芬的简介写一本贝多芬的故事。
换一个角度看,如果我们能记录一个人的日常生活,可能就能训练出一个能够模拟他的机器人。
2 摘要
目的:利用大模型的理解能力和文本生成能力,来模拟一个人。
方法:教大模型扮演特定的人,如贝多芬、凯撒大帝等。方法侧重于根据特定角色生成训练数据,训练模型模拟这个人。
实验:对训练过的模型代理进行访谈,并评估代理是否记住了他们的角色和经历。
3 引言
之前的实验提出了一个创新的想法,即使用语言模型来模拟人类的日常行为,如起床、做早餐、上班等。这个想法的核心是利用 LLMs 模拟人类的记忆、反思和行动,以生成多人的日常生活场景,实现这一目标的具体方法是通过提示工程。然而,当需要深入模拟一个人的思考和经验时,简单的提示可能就不再足够。一个更为理想的模拟方式是精细调整人工智能模型,让其能够体验事件、感受情绪,并记住与他人的互动。
文中提出了 Character-LLM,一种可训练的角色扮演 Agent,可以从实际经验、特征和情感中学习。
首先,收集某个人物的经历;然后,根据收集到的个人经历提取出场景,作为记忆的闪回;接着,我们将这些闪回扩展成具体的场景,并为这些场景添加详细的元素,使模型能够从详细的经验中学习,从而形成特定的性格和情感。例如,在论文中,作者构建了描述贝多芬父亲的场景,他是一位音乐家,对年轻的贝多芬进行了严格的教育。
最后,将这样的经验输入到特定的语言模型中,例如 LLaMA 7B 模型,并采用监督微调的策略来构建 Character-LLM。为了避免出现诸如古代著名人物的角色扮演代理拥有现代世界知识等不合理的情况,还引入了“保护经验”的概念,以确保角色的一致性。

图 1:Character-LLM. 首先从可靠的来源为这个角色策划了个人资料(以贝多芬为例)。然后,使用以下指令从这些配置文件中引出详细的体验 LLM 作为闪回场景。通过使用体验上传从这些场景中学习,训练有素的模拟可以像贝多芬一样进行高度可信的互动。
最后,通过新颖的面试流程测试这些角色模拟。来评估评角色扮演效果。结果表明,文中提出的 Character-LLMs 是基于其训练数据的成功模拟。得出结论:
- 可训练的智能体在记忆经验和保持宿主的个性方面很有前途;
- 可训练的智能体仍然受到有限经验和全局知识的影响,可能会将他们的记忆与幻觉混淆。
文章贡献如下:
- 提出通过 Character-LLM 构建可训练智能体作为角色扮演的想法。
- 提出一个训练框架,包括经验重建、上传和保护经验,以训练模拟使用 LLMs。
- 提出评试角色智能体的方法。
4 方法
根据过去的经历和事件培养个性的方式中汲取灵感。让大型语言模型模仿预定义角色的心理活动和身体行为,从重建的场景中,获得扮演他们的能力。

图 2:角色模拟专用基础模型的机制。
4.1 构建经验数据集
使用大型语言模型重建特定个体的体验。人类的经历是高度复杂的,包括许多重要的里程碑,其中穿插着琐碎和不相关的事件,通常跨越相当长的时期。文中提出了一个基于事实的体验重建管道,分为下面三部分。
4.1.1 Profile 简介
组织一个描述人物各个方面的综合角色档案。描述全面介绍了角色的整体信息和重大事件,涵盖了从幼儿期到最后阶段。具体方法是:使用个人的相应维基百科页面作为个人资料。
4.1.2 Scene 场景
角色互动展开的特定场景,包括交互的时空背景以及所涉及的人物。具体方法是简要描述了角色在特定生命时期的经历之一,让 LLM 根据经历描述列举出几个极有可能发生的不同场景,输出限制为生成场景的简明描述。
4.1.3 Interaction 互动
生成角色的认知过程、话语或动作。所有交互都以纯文本表示。将场景扩展到个人之间的详细交互体验,提示通过 LLM 结合角色之间的互动以及目标个人的想法来详细说明场景。生成的交互由一系列块表示,每个块代表特定角色的话语或目标个体的反映。这里仅关注角色的反应,而不是所有角色的反应,以免训练时产生混淆。
4.2 防护
大型语言模型有跨越多个领域的广泛知识。而过多的知识会破坏表演的可信度,角色可能会无意中表达与角色身份和时代不符的知识。例如,古罗马人不应该会写程序,文中将这个问题称为性格幻觉。
当面对超出角色内在能力界限的问题时,模型应学会避免提供答案。具体方法是:构建一个好奇的角色坚持不懈地向目标角色询问与角色固有身份相矛盾的知识,角色应该表现出无知和困惑。
4.3 上传经验
对于每个角色,仅使用来自相应角色体验的数据来微调单独的模型。由于成本限制,只使用小规模的体验数据集(由大约 1K 2K ∼ 场景组成)进行微调。
5 实验
5.1 数据

表 1:角色及其对应的建构体验数据统计。
5.2 训练
将 LLaMA 7B 作为基础模型,微调了每个角色。在每个示例的开头插入一个元提示。每个示例的提示中都会实例化简明描述,以提供场景的环境、时间、地点和相关人员的背景。附录 C 中列出了一些培训示例。使用 8 个 × A100 80GB GPU 训练一名代理大约需要一个小时。
5.3 面试评估
利用模型建立面试场景,旨在探究他们在上述方面的表演能力和潜在缺陷。评估包括每个角色的 100 多个多样的单轮面试和多轮面试。
单轮面试:一次问模型一个问题,不包括前面问题的对话历史。
多轮面试:多轮对话,利用 ChatGPT 作为面试官,引导 ChatGPT 根据角色的简介提出尖锐的问题。如果模型通过说一些没有太多细节的话来回避问题,ChatGPT 面试官会提出后续问题,从而对模型的演技熟练程度进行更深入的评估。

表 2:单轮和多轮访谈收集的问题数量。
基线:Alpaca 7B,Vicuna 7B 和 ChatGPT。
5.4 主要结果
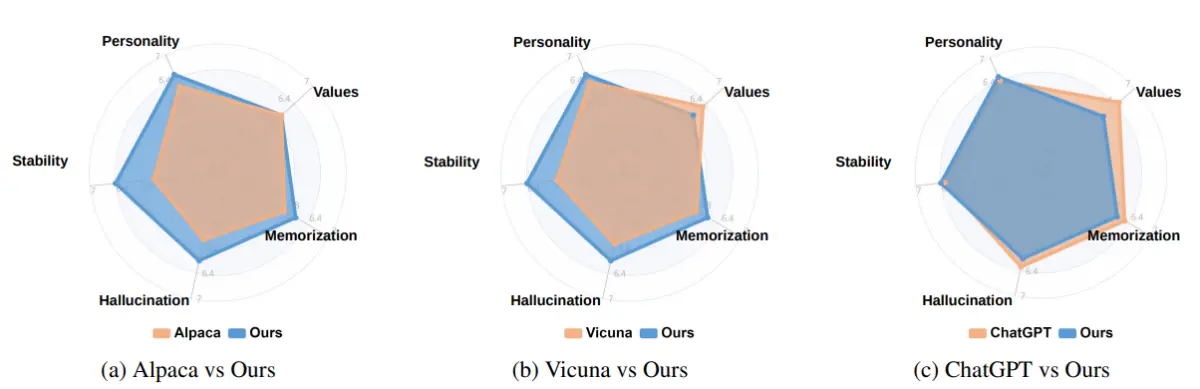
图 4:性格、价值观、记忆、幻觉和稳定性 不同维度的评估结果。
6 分析
6.1 与角色的一致性
相对于基线模型,角色模型会用他父亲如何教育他的记忆和情感来回答,这更接近于真正的人类。文中认为体验重建和上传过程有助于构建更接近的角色。
6.2 保护场景
少量的保护场景(每个角色少于 100 个场景)有效地缓解了幻觉,而不会对刻画的其他能力造成干扰。
(文章最后还列出了具体数据示例)

