
- 1从零开始的ChatGLM 配置详细教程
- 2tcp三次握手和四次挥手_tcp 的三次握手和四次挥手
- 31015: 计算时间间隔_输入有两行,第一行开始时间,第二行为结束时间,时间都有xx比yy笔记记表示xx表
- 4ModuleNotFoundError: No module named ‘tensorrt‘_modulenotfounderror: no module named 'tensorrt
- 5【毕业设计】深度学习人体跌倒检测 -yolo 机器视觉 opencv python_yolo摔倒检测
- 6ChatGPT的大致原理
- 7Linux创建进程
- 8金融数据挖掘Jupyter—北京市二手房数据分析—课设_jupyter数据处理课设
- 9uni-app微信小程序canvas中使用canvasToTempFilePath在手机上导出图片尺寸与实际不符_uni.canvastotempfilepath上传图片像素密度
- 10改变Ubuntu内核版本_ubuntu22.04 更改内核
途牛谭俊青:多数据中心状态同步&两地三中心的理论
赞
踩
声明:本文首发于CSDN,禁止未经许可的任何形式转载,可咨询文末的责编。
本文分享了跨数据中心状态同步两地三中心的理论技术,涉及数据库相关,其中会交代“如何去做”,以及会让大家理解“为什么要这么去做”。
分布式协议/概念

关于分布式协议的概念。以今年的“双十一”阿里的创造的惊人交易额为例,它的技术团队出来做技术分享时提到一点,就是支付宝交易每秒钟到了 8.5 万笔,这其中有很多东西可可供分析。
这其中就包含分布式协议。全球范围内真正能够实现分布式一致性算法的只有两个:一个是 Paxos,另一个是 Raft。Paxos 拥有很长的历史,它最早是谷歌实现的。2012年,有两位教授发表了一篇论文叫做Raft,非常值得去学习。论文中有一个组建使用的也是Paxos 的算法。要真正实现分布式数据状态协议的话,一般会选择Paxos 和Raft。从容易实现的角度考虑的话,就采用Raft。
远距离跨机房同步问题

途牛最初的系统都在南京,但为了照顾用户体验,公司就将网站迁到了北京。原因是技术团队进行了调用,发现其中存在很多问题,包括远距离跨机房同步问题,以及专线稳定性对服务质量的影响。一般的系统网络都是 4 个9 或以上,还有宽带挤占、各个系统调用等,还有下面要具体讲的数据库同步延时。
途牛的后台系统允许客户注册,在网站上注册可以选择南京或北京。技术团队选择南京,是因为更多的用户集中在南京这边。如果注册时到北京去,我们读的就是北京数据库。而一旦出现延时就无法登录,这样用户体验是非常糟糕的。除此之外,就是不能做强一致性高可用。如果在两地做,万一出问题需要切换,数据可能会丢失,这需要极力避免。
CAP 中,我们的选择
关于“CAP”,很多人都了解它的含义,就是一致性、可用性、分区容错性。但这三者不可兼得,因此分区是必然的。对电商来说,它对数据的要求比较高,所以选择Consistency(一致性)。
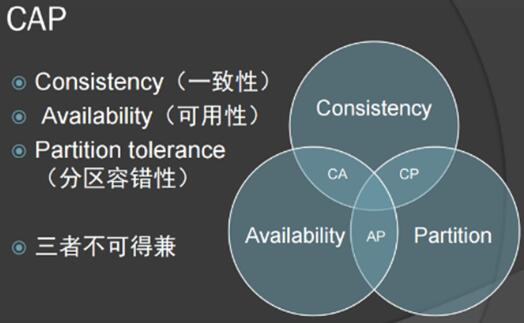
上图中的重合区域只有一个“小三角”,它说明这个数据很难落地,三者的优点很难兼顾。因此看上去 CAP 能够满足需求的,而实际情况并不是这样。

上文提到,途牛的选择是针对当前的这种开源,或者是技术实现。技术团队现在用开源数据库,来实现:
- 主从复制、做高可用;
- 防止丢失数据;
- 只牺牲一定的性能,等待数据被同步。
但远距离机房延时太大,从而影响了系统吞吐量,所以决定做了机房搬迁。今年公司把整个北京机房搬迁到了南京,与主要系统合为一处。
数据的传输
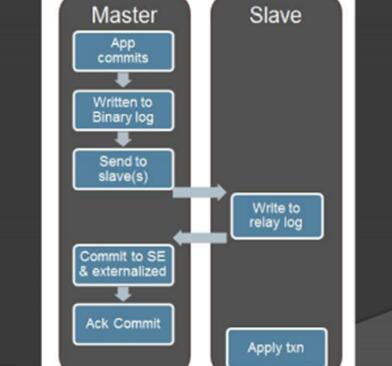
上面的图片,相信很多人都见过。途牛的应用是先向数据库发起事务,这个事务完成后,它会写到日志里面,然后返回应用。
这种专线最终落地是什么?就是光纤传输。可以算一下它的传输性能:真空中光速30万千米/S,光纤材质折射率 1.45 左右,全反射传输,路径大于光纤长度,折算下来小于20KM/0.1MS,如果算同城的话,是1000ms / 0.2ms=5000(TPS)。可以通过技术提升这个速度,这与业务具体架构相关。

南京到北京,距离近千公里,光纤不会是直线布置,中间会包含很多的弯和网络设备。在这种情况下,南北传输,可以达到 1000MS / 50MS=20(TPS)水平。
基于 HA 的数据中心系统构建
之前途牛会员系统的后台并不完善。有时会被用户刷会员,甚至被刷坏掉。当时系统支持的事务量很小,这个情况跟创业公司有点类似:在高速发展阶段,团队整体的效率没那么高,但为了降低成本,可能会让一个功能快速上线,但中间如何优化、如何实现都没有考虑过。这样的系统,经过多年累积,其中就会出现了很多问题。后来,技术团队使用了异步的方式解决了这个问题。
双十一阿里如何做到8万5千笔/秒的交易频率的?最早从腾讯开始,通过 QQ 号取模的方式,其中道理是一样的。一个整体,如果是串行,它的分布量是比较有限的。前文提到的 0.2 毫秒,而理论上只能达到 5 千每秒,如何去提升呢?在编程上面要作调整,当性能发展到一定规模后,需要提升整个系统吞吐量,就必须考虑低层的架构,哪怕谷歌也是一样:曾经谷歌发现这里面数据库识别越来越多,各种不可用,谷歌就把系统迁移到自己开发。这么大的数据量怎么去做?如下图中所述。

HA 组建及双中心 HA 缺陷。这里面有 heartbeat、keepalived等,也是一样的,但是缺少第三方仲裁,会导致“脑裂”,特别在偶数的下面。如果两部分都正常,可能会引起数据不一致,进而造成数据丢失等。一般来说,会选择F=1,或者是2,就是5个节点,我们选用比较成熟的解决方案。还有很多 15 节点的方案,进一步提高了可能性,它允许两个节点失效。

双中心HA缺少仲裁,因此途牛选择三中心HA。三中心有仲裁,三个节点,至少不会发生“脑裂”的现象。这三中心的分布是“同城加异地”,这比较容易理解:同城可以保证一定的吞吐量——同城数据中心降低的同步延时,低延时极大提升了吞吐量,第三数据中心参与选择仲裁及灾备恢复。出于安全考虑,第三中心一般距离会比较远。比如在南京的机房会远一点,就是为了避免出现地震等自然灾害同时影响三个中心的情况发生。

吞吐量提升,是可以采用各种各样的方法来实现的。阿里双十一的峰值可以达到8万5千笔/秒的交易。他们引以为傲的,是去年只有 10% 的交易在Oceanbase,而今年在 100% 都迁到Cceanbase。这是如何实现的?Sharding 分区是避免不了的。采用发号器避免冲突,实现高并发,分区间用 2PC 实现分布式事务。这其中还涉及到全局,还有部分采用队列异步处理。做全局索引对业务影响并不大,因此一般统计的时候,往往通过异步去实现。
最后总结一下。根据只是把逻辑思维展现出来;两地三中心一定是同城,因为要保证它的吞吐量、保证业务可用性,如果选择 CP (一致性&分区容错性)可能达不到理想的效果。三中心对应状态同步的三节点,两地是照顾到安全和性能。另外,需要把第三个机房放到异地或者比较远的地方去。(责编/钱曙光)
分享人:谭俊青,途牛运维总监。他曾担任架构委员会会长,参与、负责公司公司底层网络、数据中心建设、数据库(监控、备份、HA)、系统、安全、系统架构设计,致力于推动工具化、平台化、自动化建设。多年来从事底层系统架构、网站架构、分布式系统、缓存、数据库系统及相关工具的设计、研发(切分、负载均衡、高可用等、DFS、RAFT),TB级数据库的咨询、设计、优化、研发。
- 1
本文整理自途牛运维总监谭俊青日前在“UPYUN架构与运维大会·上海站”上的主题演讲。UPYUN 架构与运维大会是国内领先的新一代云CDN服务商UPYUN独家主办的大型技术会议。大会面向全国运维和架构从业者,邀请业内一线的架构师和运维专家进行纯干货分享,旨在推动各项运维技术、产品架构等在互联网和移动互联网的研发和应用。
「CSDN 高级架构师群」,内有诸多知名互联网公司的大牛架构师,欢迎架构师加微信qshuguang2008入群,备注姓名+公司+职位。

