- 1Shell—编程实战_shell 高阶开发实战,轻松应对集群化,分布式环境
- 2测试开发必备技能:安全测试漏洞靶场实战
- 3PVE(Proxmox VE) 显卡直通_pve编辑文件
- 4chatgpt赋能Python-python_excel_宏_python excel宏
- 5Python实现采集热门城市的景点数据,并制作简单的数据可视化_基于python的旅游城市满意度数据分析与可视化—以青岛为例
- 6使用GitHub API 查询开源项目信息
- 7VNC连接到麒麟服务器系统黑屏,已解决_vnc viewer 银河麒麟操作系统v10 远程桌面黑屏
- 8基于C#制作一个桌面宠物_桌宠是如何实现的csdn c
- 9鸿蒙Harmony应用开发—ArkTS声明式开发(通用属性:图形变换)
- 10关于使用typora时图片不显示的问题_typora笔记图片失效
【网络结构设计】6、CSPNet | 一种加强 CNN 模型学习能力的主干网络
赞
踩

论文:CSPNet: A new backbone that can enhance learning capability of CNN
代码:https://github.com/open-mmlab/mmdetection/blob/master/mmdet/models/backbones/csp_darknet.py
出处:CVPR2019
CSPNet 的提出解决了什么问题:
- 强化 CNN 的学习能力:现有 CNN 网络一般在轻量化以后就会降低效果,CSPNet 希望能够在轻量化的同时保持良好的效果。CSPNet 在嵌入分类任务的 ResNet、ResNeXt、DenseNet 等网络后,可以在保持原有效果的同时,降低计算量 10%~20%
- 移除计算瓶颈:过高的计算瓶颈会导致推理时间更长,在其计算的过程中其他很多单元空闲,所以作者期望所有的计算单元的效率差不太多,从而提升每个单元的利用率,减少不必要的损耗。
- 减少内存占用:CSPNet 使用 cross-channel pooling 的方法来压缩特征图
一、背景
为了实现更好的效果,深度神经网络一直在往更深和更宽的方向发展,但也带来了一系列计算量的上升,难以在边端小型设备使用。有一些为移动端 CPU 设计的方法,如深度可分离卷积,不适用于工业 IC,如 Application-Specifific Integrated Circuit (ASIC)。
本文作者认为,这种大量计算主要来自于梯度的冗余,就是同一个梯度会在不同的模块中被计算。所以提出了高效计算模块,可以让诸如 ResNet、DenseNet 的网络同时在 CPU 和 GPU 上无损耗的部署。
实现方法:分割梯度流,让梯度在不同的路径中传播,降低梯度冗余
二、方法

Cross Stage Partial Network (CSPNet) 的主要设计思想:让网络中的梯度进行丰富的结合,降低冗余,减少计算量
2.1 DenseNet 网络结构
在介绍 CSPNet 之前,先看看 DenseNet 的结构
图 2a 展示了 DenseNet 的一个 stage 结构:
- 每个 stage 都包括一个 dense block + transition layer
- 每个 dense block 由 k 个 dense layer 组成
- 每个 dense layer 的输出会作为下一个 dense layer 的输入
- transition layer: BN+ 1x1 conv + 2x2 avg pooling
DenseNet 的过程可以用如下方式表示,其中 * 表示卷积, x i x_i xi 表示第 i i i 个 dense layer 的输出。
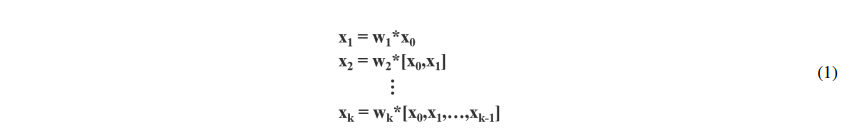
反向传播过程表示如下, g i g_i gi 表示传递给第 i 个 dense layer的梯度。可以看出,大量的梯度信息是被不同 dense layer 重复使用的:

重点:Concat 操作后,不同通道的梯度是如何传递的
- Concat 是将多个通道的特征图进行拼接,互相不影响
- 所以在梯度反向传播的时候,多个通道拼接的特征,只会找对应的找对应通道的特征图进行梯度回传
DenseNet 为什么有大量的梯度重用:
- 每个 layer 会接收前面所有 layer 的输出,也就是 layer i 的输入是 [layer 1 , layer 2 , layer i-1] concat 起来的
- 在梯度回传的时候,layer 1 会接收到 layer 2 ~ layer i 层的梯度回传,相当于回传了很多遍
CSPNet 怎么解决这种梯度重用:
- 将每个 block 的输入分成两部分,一部分经过和 DenseNet 相同的密集连接,然后再经过 transition layer,另一部分经过 transition layer,然后将部分 concat 再经过最后的 transition layer 然后输出
- 其实这里经过 DenseNet 的密集连接的特征图,还是存在梯度重用,真正实现了“梯度不重用”的是这两个分支(经过密集连接和不经过密集连接的这两个分支),因为这两个分支的梯度是不会被重用的(concat 后各自通道负责各自的梯度回传,没有重复计算梯度)
- 所以 CSPNet 并没有完全解决了梯度重用,可以看做只解决了一半通道的梯度重用
2.2 Cross Stage Partial DenseNet
图 2b 展示了 CSPDenseNet 的一个 stage,CSPDenseNet 的组成:
-
Partial dense block:
每个 stage 的特征图都根据 channel 被分为两个部分 x 0 = [ x 0 ′ , x 0 ′ ′ ] x_0 = [x_0', x_0''] x0=[x0′,x0′′]
- x 0 ′ x_0' x0′ :会经过 dense block
- x 0 ′ ′ x_0'' x0′′ :会直接送入 stage 的最后一层
- 每个 stage 的输出可以表示为: [ x 0 ′ ′ , x 1 , . . . , x k ] [x_0'', x_1, ..., x_k] [x0′′,x1,...,xk],然后输入 transition layer
-
Partial transition layer
- 上面的 transition layer 的输出为 x T x_T xT,然后会和 x 0 ′ ′ x_0'' x0′′ 进行 concat ,最后输入后面的 transition layer,得到输出 x U x_U xU,如图 3 所示
由于这里 transition layer 使用的是 concat 方法,而 concat 方法的梯度传播会分开进行,就是还是会传递到对应的来源处去,所以经过密集 block 和未经过密集 block 的特征是分别优化的,梯度单独更新。
CSPNet 的前向传播和反向传播如公式 3 和 4 所示:
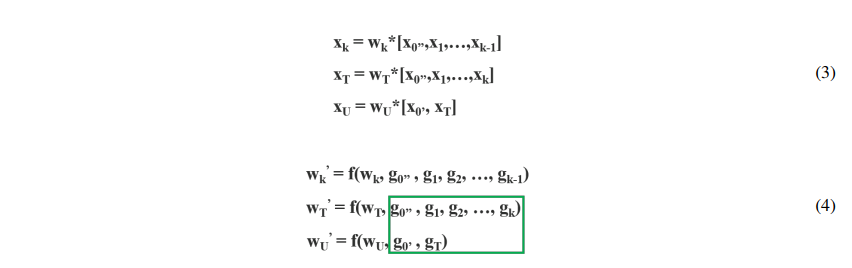
CSPDenseNet 保留了DenseNet 特性重用特性的优点,但同时通过截断梯度流防止了过多的重复梯度信息。该思想通过设计一种分层的特征融合策略来实现,并应用于局部过渡层。
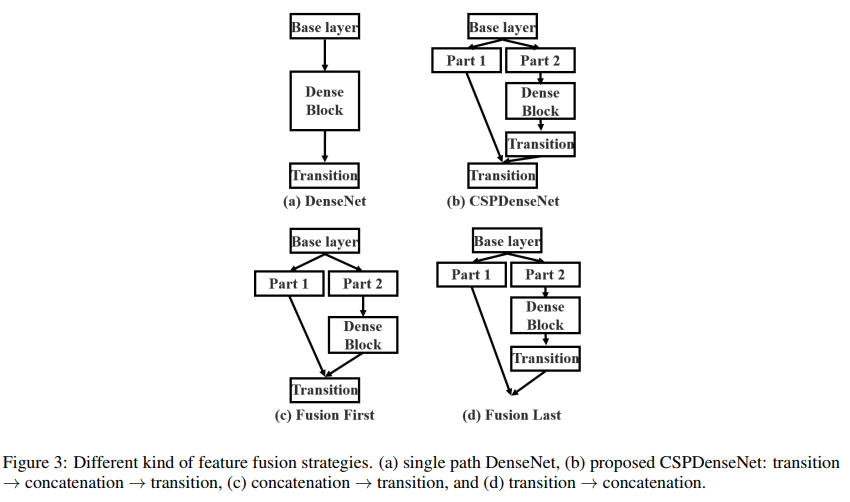
图 3 也展示了不同融合方式:
- c 是 fusion first:经过 dense block 的特征直接和 part1 的特征进行 concat,然后再输入 Transition,这样梯度是可以重复利用的
- d 是 fusion last:经过 dense block 的特征先自己做 transition,然后和 part1 特征 concat,这样梯度是会被截断的,不会重复利用(因为没有融合所以两部分梯度无法共享,造成梯度截断)
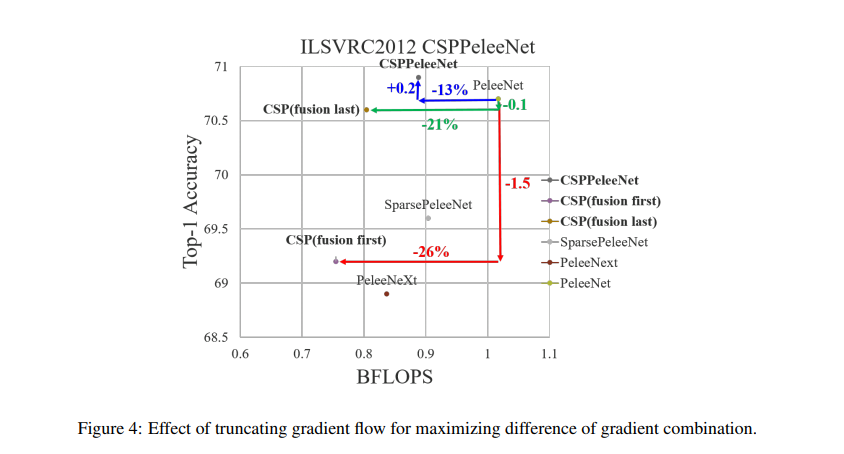
作者也对比了不同的融合方式的效果:
-
使用 Fusion First 中梯度会被大量重复利用,没有明显的计算量下降, top-1 acc 下降了 1.5%
-
使用 Fusion Last 先使用 transition 降低了 dense block 的维度,极大降低了计算量,top-1 acc 仅仅下降了0.1个百分点
-
同时使用 Fusion First 和 Fusion Last 相结合的 CSP 所采用的融合方式可以在降低计算代价的同时,提升准确率。
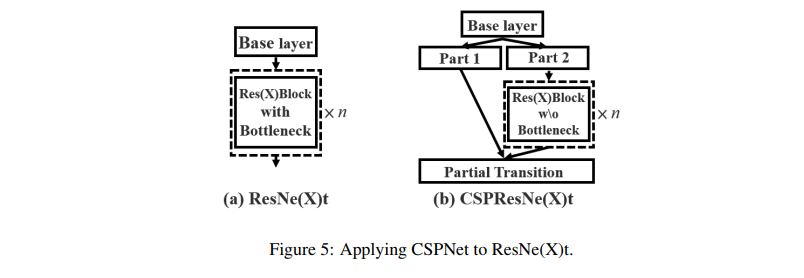
2.3 将 CSPNet 和其他结构结合
如图 5 所示,CSPNet 可以和 ResNet、ResNeXt 进行结合,由于每个 Res block 只有一半的 channel 会经过,所以不需要引入 bottleneck。
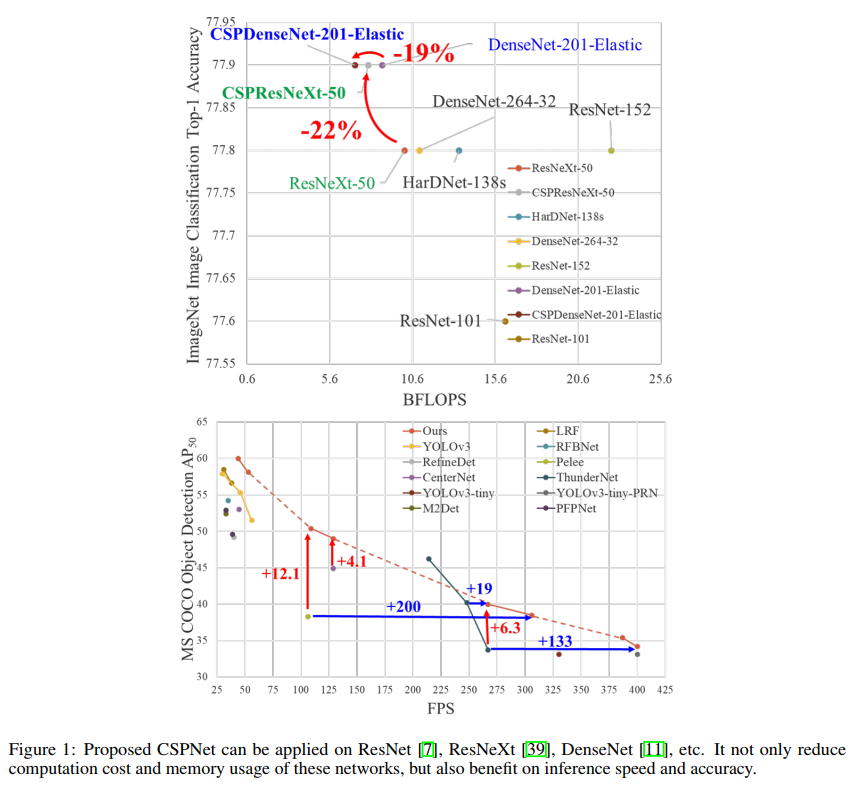
三、效果
1、不同模块的消融实验
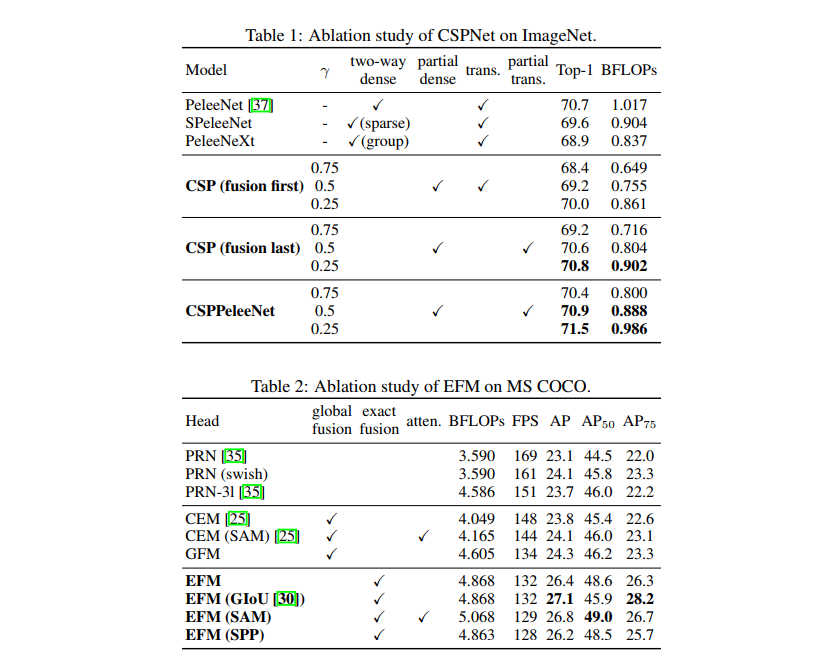
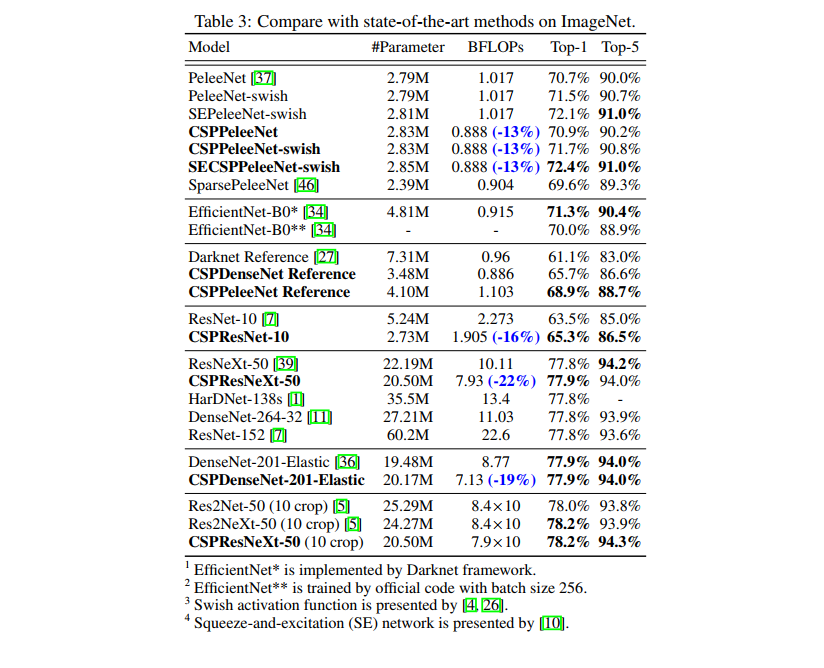
2、在分类任务上和 SOTA 对比
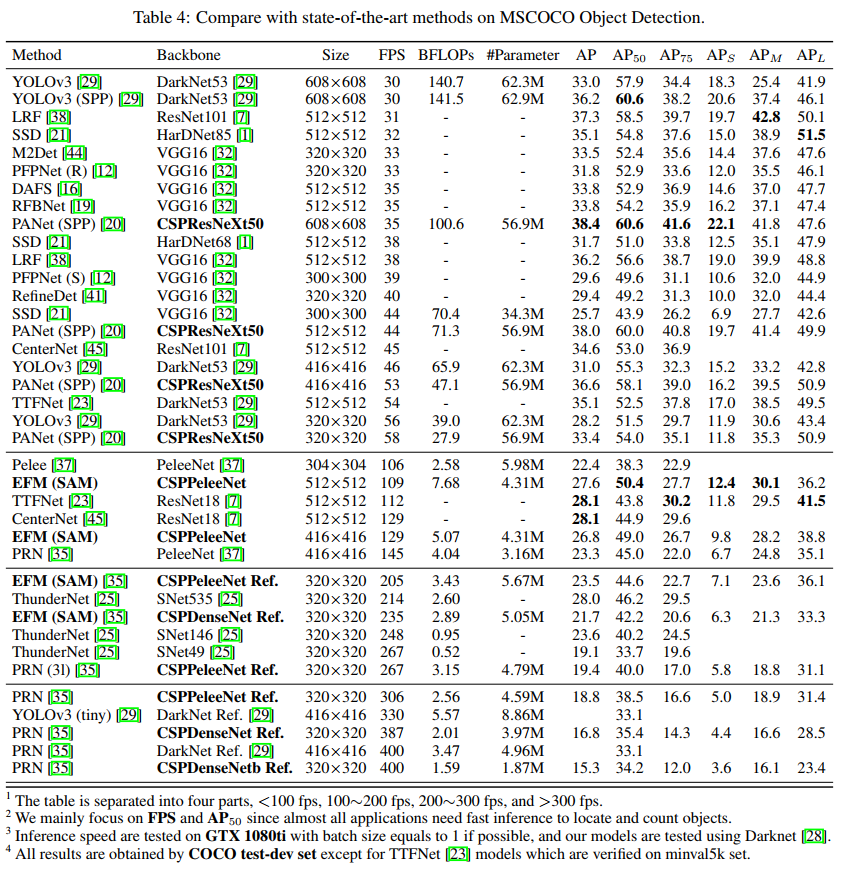
3、在检测任务上和 SOTA 对比