
热门标签
热门文章
- 1[Python] Pyshark统计pcap的packet协议字段并柱状图可视化_pyshark only_summaries=
- 2php数据类型以及运算符、判断条件
- 3Java中定时器
- 4centos7以上系统修改时区时间问题_failed to set time: automatic time synchronization
- 5Webpack 4.X 从零配置SPA单页应用_webpack 打包spa单页面应用
- 6如何测试ChatGPT:深度理解和应用示例_对定制的chatgpt进行测试
- 7【C语言】指针经典题分析_c语言指针例题及解析
- 8普中51单片机学习(EEPROM)
- 9「隐语小课」联邦学习之基本方法_联邦学习梯度聚合
- 10微信小程序之会议OA系统首页布局搭建与Mock数据交互_oa系统布局
当前位置: article > 正文
PPO理解_ppo模型详解
作者:Monodyee | 2024-03-01 05:50:16
赞
踩
ppo模型详解
由于TRPO实现起来需要使用二阶近似和共轭梯度,比较复杂,Deepmind又在TRPO的基础上提出了实现较为简单的PPO算法。
TRPO
TRPO的优化目标为
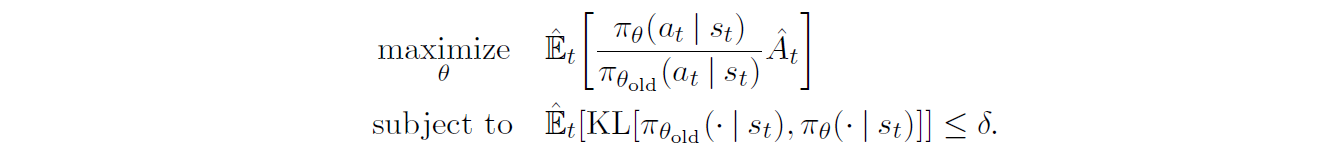
用惩罚项代替约束项后
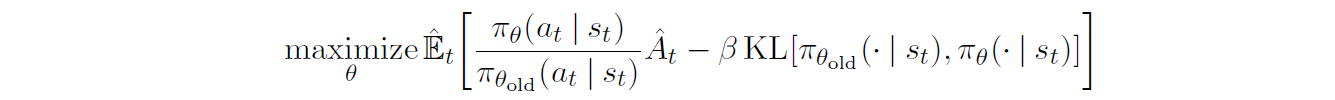
Adaptive KL Penalty Coefficient
PPO1为了避免TRPO中超参数
β
\beta
β的选择,采用自适应确定参数的方法
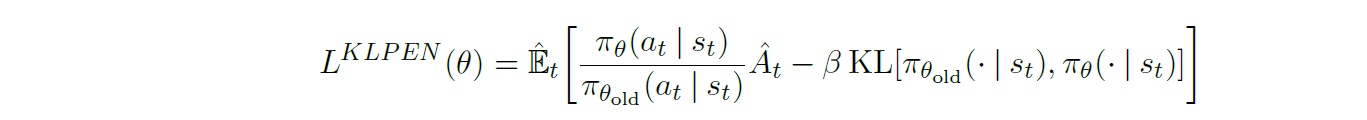
β
\beta
β由以下条件确定


Clipped Surrogate Objective
为了限制更新步长,原文还提出了PPO2,这是默认的PPO算法,因为PPO2的实验效果比PPO1更好。做法是在优化目标中加入一个clip函数
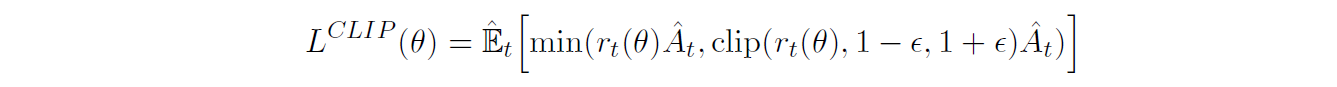
这里
r
(
t
)
r(t)
r(t)代表新旧策略动作的概率比,这样对策略更新速度进行了裁剪,防止参数更新过快
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/Monodyee/article/detail/171420
推荐阅读
相关标签

