
- 1与机器对话,阿里达摩院挑战新一代人机对话技术_阿里 多轮问答
- 2sprite的大小 unity_Unity中的Sprite纹理压缩(Sprite texture compression in Unity)
- 3C#中对类的序列化和反序列化操作_c# 按照类的私有字段进行反序列化
- 4shader实例(unity内置shader)_unity自带shader有哪些
- 5react开发者必备vscode插件【2024最新】
- 6SVN Cleanup失败的解决方法_svn cleanup失败的解决办法
- 7C# Winform UI Ant Design 5.0 设计语言
- 8Android Screen Brightness 屏幕亮度 的获取和修改_android screenbrightness
- 9C语言位操作:将某一位置1,或将某一位置0_c语言某一位置0
- 10el+vue 实战 ⑨ el-button按钮悬浮、el-button按钮背景图片自定义、el-button按钮点击之后样式复原_elementui悬浮按钮
tensorflow的GPU加速计算_tensorflow gpu
赞
踩
参考 tensorflow的GPU加速计算 - 云+社区 - 腾讯云
一、概述
tensorflow程序可以通过tf.device函数来指定运行每一个操作的设备,这个设备可以是本地的CPU或者GPU,也可以是某一台远程的服务器。tensorflow会给每一个可用的设备一个名称,tf.device函数可以通过设备的名称来指定执行运算的设备,比如CPU在tensorflow中的名称为/cpu:0。在默认情况下,即使机器有多CPU,tensorflow也不会区分它们,所有CPU都使用/cpu:0作为名称。而一台机器上不同为/gpu:0,第二个GPU名称为/gpu:1,以此类推。
tensorflow提供了一个快捷的方式来查看运行每一个运算的设备。在生成会话时,可以通过设置log_device_placement参数来打印运行每一个运算的设备。以下程序展示了如何使用log_device_placement这个参数。
- import tensorflow as tf
-
- a = tf.constant([1.0, 2.0, 3.0], shape=[3], name='a')
- b = tf.constant([1.0, 2.0, 3.0], shape=[3], name='b')
- c = a + b
-
- # 通过log_device_placement参数来输出运行每一个运算的设备。
- sess = tf.Session(config=tf.ConfigProto(log_device_placement=True))
- print sess.run(c)
-
- '''
- 在没有GPU的机器上运行以上代码可以得到类似以下的输出。
- Device mapping: no known devices.
- add: (Add): /job:localhost/replacement/replica:0/task:0/cpu:0
- b: (Add): /job:localhost/replacement/replica:0/task:0/cpu:0
- a: (Add): /job:localhost/replacement/replica:0/task:0/cpu:0
- [2. 4. 6.]
- '''

在以上代码中,tensorflow程序会生成会话时加入了参数log_device_placement=True,所以程序会将运行每一个操作的设备输出到屏幕。于是除了可以看到最后的计算结果,还可以看到类似"add: (Add): /job:localhost/replacement/replica:0/task:0/cpu:0
"这样的输出。这些输出显示了执行每一个运算的设备。比如加法操作add是通过CPU来运行的,因为它的设备名称中包含了/cpu:0。
在配置好GPU环境的tensorflow中,如果操作没有明确地指定运行设备,那么tensorflow会优先选择GPU。比如将以上代码在亚马逊(Amazon Web Services, AWS)的g2.8xlarge实例上运行时,会得到类似以下的运行结果。
- Device mapping:
- /job:localhost/replica:0/task:0/gpu:0 -> device: 0, name: GRID K520, pci bus
- id: 0000:00:03.0
- /job:localhost/replica:0/task:0/gpu:0 -> device: 1, name: GRID K520, pci bus
- id: 0000:00:04.0
- /job:localhost/replica:0/task:0/gpu:0 -> device: 2, name: GRID K520, pci bus
- id: 0000:00:05.0
- /job:localhost/replica:0/task:0/gpu:0 -> device: 3, name: GRID K520, pci bus
- id: 0000:00:06.0
-
- add: (Add): /job:localhost/replace:0/task:0/gpu:0
- a: (Const): /job:localhost/replace:0/task:0/gpu:0
- b: (Const): /job:localhost/replace:0/task:0/gpu:0
- [ 2. 4. 6. ]
从以上输出可以看出在配置好GPU环境的tensorflow中,tensorflow会自动优先将运算放置在GPU上。不过,尽管g2.8xlarge示例中有4个GPU,在默认情况下,tensorflow只会将运算优先放到/gpu:0上。于是可以看见在以上程序中,所有的运算都被放在了/gpu:0上。如果需要将某些运算放到不同的GPU或者CPU上,就需要通过tf.device来手工指定。以下程序给出了一个通过tf.device手工指定运行设备的样例。
- import tensorflow as tf
-
- # 通过tf.device将运算指定到特定的设备上。
- with tf.device('/cpu:0'):
- a = tf.constant([1.0 2.0 3.0], shape=[3], name='a')
- b = tf.constant([1.0 2.0 3.0], shape=[3], name='b')
-
- with tf.device('/gpu:1')
- c = a + b
-
- sess = tf.Session(config=tf.ConfigProto(log_device_palcement+=True))
- print sess.run(c)
-
- '''
- 在AWS g2.8xlarge实例上的运行上述代码可以得到以下结果:
- Device mapping:
- /job:localhost/replica:0/task:0/gpu:0 -> device: 0, name: GRID K520, pci bus
- id: 0000:00:03.0
- /job:localhost/replica:0/task:0/gpu:0 -> device: 1, name: GRID K520, pci bus
- id: 0000:00:04.0
- /job:localhost/replica:0/task:0/gpu:0 -> device: 2, name: GRID K520, pci bus
- id: 0000:00:05.0
- /job:localhost/replica:0/task:0/gpu:0 -> device: 3, name: GRID K520, pci bus
- id: 0000:00:06.0
- add: (Add): /job:localhost/replace:0/task:0/gpu:1
- a: (Const): /job:localhost/replace:0/task:0/gpu:0
- b: (Const): /job:localhost/replace:0/task:0/gpu:0
- [2. 4. 6.]
在以上代码中可以看到生成常量a和b的操作被加载到了CPU上,而加法操作被放到了第二个GPU上"/gpu:1"上。在tensorflow中,不是所有的操作都可以被放在GPU上,如果强行将无法放在GPU上的操作指定到GPU上,那么程序将会报错。以下代码给出了一个报错的样例。
- import tensorflow as tf
-
- # 在CPU上运行tf.Variable
- a_cpu = tf.Variable(0, name="a_gpu")
-
- with tf.device('/gpu:0'):
- # 将tf.Variable强制放在GPU上。
- a_gpu = tf.Variable(0, name="a_gpu")
-
- sess = tf.Session(config=tf.ConfigProto(log_device_palcement=True))
- sess.run(tf.initialize_all_variables())
-
-
- '''
- 运行以上程序将会报出以下错误:
- tensorflow.python.framework.errors.InvalidArgumentError: Cannot assign a
- device to node 'a_gpu': Could not satisfy explicit device specification
- '/device:GPU:0' because no supported kernel for GPU device is available.
- Colocation Debug Info:
- Colocation group had the following types and devices:
- Identity:CPU
- Assign:CPU
- Variable:CPU
- [[Node: a_gpu = Variable[container="", dtype=DT_INT32, shape=[],shared_name="", _device="/device:GPU:0"]()]]
- '''
不同版本的tensorflow对GPU的支持不一样,如果程序中全部使用强制指定设备的方式会降低程序的可移植性。在tesnorflow的kernel中定义了哪些操作可以泡在GPU上。比如可以在variable_ops.cc程序中找到以下定义。
- # define REGISTER_GPU_KERNELS(type)
- REGISTER_KERNEL_BUILDER(
- Name("Variable").Device(DEVICE_GPU).TypeConstraint<type>("dtype"),
- VariableOp);
- ...
- TF_CALL_GPU_NUMBER_TYPES(REGISTER_GPU_KERNELS);
在这段定义中可以看到GPU只在部分数据类型上支持tf.Variable操作。如果在tensorflow代码库中搜索调用这段代码的宏TF_CALL_NUMBER_TYPES,可以发现在GPU上,tf.Variable操作只支持实数型(float16, float32和double)的参数。而在报错的样例代码中给定参数是整数型的,所以不支持在GPU上运行。为避免这个问题,tensorflow在声称会话时可以指定allow_soft_placement参数。当allow_soft_placement参数设置为True时,如果运算无法由GPU执行,那么tensorflow参数设置为True时,如果运算无法由GPU执行,那么tensorflow会自动将它放到CPU上执行。以下代码给出了一个使用allow_soft_placement参数的样例。
- import tensorflow as tf
-
- a_cpu = tf.Variable(9, name="a_cpu")
- with tf.device('/gpu:0'):
- a_gpu = tf.Variable(0, name="a_gpu")
-
-
- # 通过allow_soft_placement参数自动将无法在GPU上的操作放回CPU上。
- sess = tf.Session(config=tf.ConfigProto(allow_soft_placement=True, log_device_placement=True))
- sess.run(tf.initializ_all_variables())
-
-
- '''
- 运行上面这段程序可以得到以下结果:
- Device mapping:
- /job:localhost/replica:0/task:0/gpu:0 -> device: 0, name: GRID K520, pci bus
- id: 0000:00:03.0
- /job:localhost/replica:0/task:0/gpu:0 -> device: 1, name: GRID K520, pci bus
- id: 0000:00:04.0
- /job:localhost/replica:0/task:0/gpu:0 -> device: 2, name: GRID K520, pci bus
- id: 0000:00:05.0
- /job:localhost/replica:0/task:0/gpu:0 -> device: 3, name: GRID K520, pci bus
- id: 0000:00:06.0
- a_gpu: /job:localhost/replaca:0/task:0/gpu:1
- a_gpu/read: /job:localhost/replaca:0/task:0/gpu:0
- a_gpu/Assign: /job:localhost/replaca:0/task:0/gpu:0
- init/NoOp_1: /job:localhost/replaca:0/task:0/gpu:0
- a_gpu: /job:localhost/replaca:0/task:0/gpu:1
- a_gpu/read: /job:localhost/replaca:0/task:0/gpu:0
- a_gpu/Assign: /job:localhost/replaca:0/task:0/gpu:0
- init/NoOp: /job:localhost/replaca:0/task:0/gpu:0
- init: /job:localhost/replaca:0/task:0/gpu:0
- a_gpu/initial_value: /job:localhost/replaca:0/task:0/gpu:0
- a_gpu/initial_value: /job:localhost/replaca:0/task:0/gpu:0
- 从输出的日志中可以看到再生成变量a_gpu时,无法放到GPU上的运算被自动调整到了CPU上(比如a_gpu和a_gpu/read),而可以被GPU执行的命令(比如a_gpu/initial_value)依旧由GPU执行。
- '''
虽然GPU可以加速tensorflow的计算,但一般来说不会把所有的操作全部放在GPU上,一个比较好的实践是将计算密集型的运算放在GPU上,而把其他操作放到CPU上。GPU是机器中相对独立的资源,将计算放入或者转出GPU都需要额外的时间。而且GPU需要将计算时用到的数据从内存复制到GPU设备上,这也需要额外的时间。tensorflow可以自动完成这些操作而不需要用户特别处理,但为了提高程序运行的速度,用户也需要尽量将相关的运算放在同一个设备上。
tensorflow默认会占用设备的所有GPU以及每个GPU的所有程序。如果在一个tensorflow程序中只需要使用GPU,可以通过设置CUDA_VISIBLE_DEVICES环境变量来控制。以下样例介绍了如何在运行是设置这个环境变量。
- # 只使用第二块GPU(GPU编号从0开始)。在demo_code.py中,机器上的第二块GPU的
- # 名称变成/gpu:0,不过在运行时所有/gpu:0的运算将被放在第二块GPU上。
- CUDA_VISIBLE_DEVICES=1 python demo_code.py
- # 只使用第一块和第二块GPU。
- CUDA_VISIBLE_DEVICES=0, 1 python demo_code.py
tensorflow也支持在程序中设置环境变量,以下代码展示了如何在程序中设置这些环境变量。
- import os
-
- # 只使用第三块GPU。
- os.environ["CUDA_VISIBLE_DEVICES"] = "2"
虽然tensorflow默认会一次性占用一个GPU所有显存,但是tensorflow也支持动态分配GPU的显存,使得一块GPU上可以同时运行多个任务。下面给出了tensorflow动态分配显存的方法。
- config = tf.ConfigProto()
-
- # 让tensorflow按需分配显存。
- config.gpu_options.allow_growth = True
-
-
- # 或者直接按照固定的比例分配。以下代码会占用所有可使用GPU的40%显存。
- # config.gpu_options.per_process_gpu_memeory_fraction = 0.4
- session = tf.Session(config=config, ...)
二、深度学习的多GPU并行训练模式
tensorflow可以很容易地利用单个GPU加速深度学习模型的训练过程,但是利用更多的GPU或者机器,需要了解如何并行化地训练深度学习模型。常用的并行化深度学习模型训练方式有两种,同步模式和异步模式。
深度学习模型的训练是一个迭代的过程。在每一轮迭代中,前向传播算法会根据当前参数的取值计算出在一小部分训练数据上的预测值,然后反向传播算法再根据损失函数计算参数的梯度并更新参数。在并行化地训练深度学习模型时,不同设备(GPU或CPU)可以在不同训练数据上运行这个迭代过程,而不同并行模式的区别在于不同的参数更新方式。
下图展示了异步训练模式。在每一轮迭代时,不同设备会读取参数最新的取值,但因为当前参数的取值和随机获取的一小部分训练数据,不同设备各自运行反向传播的过程并独立更新参数。可以简单地认为异步模式就是单机模式复制了多份,每一份使用不同的训练数据进行训练。在异步模式下,不同设备之间是完全独立的。
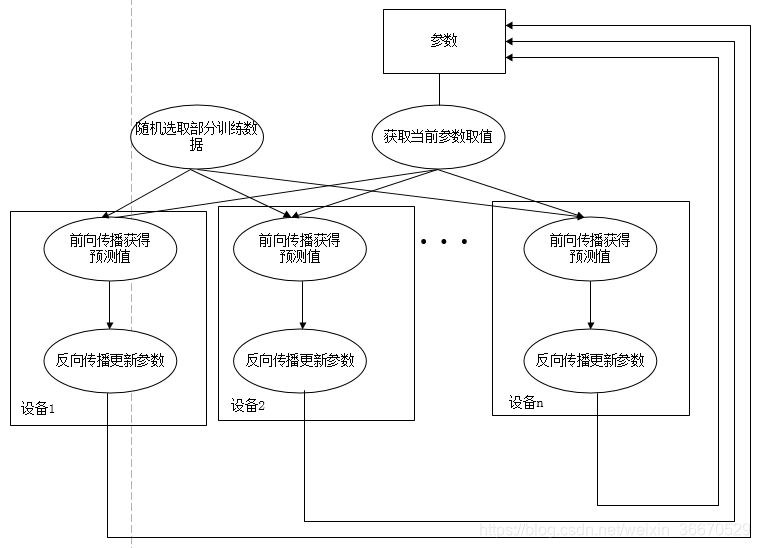
然而使用异步模式训练的深处学习模型有可能无法达到较优的结果。下图给出了一个具体的样例来说明异步模式的问题。其中黑色曲线展示了模型的损失函数,黑色小球表示了在t0时刻参数所对应的损失函数的大小。假设两个设备d0和d1在时间t0同时读取了参数的取值,那么设备d0和d1计算出来的梯度都会将小黑球向左移动。假设在时间t1设备d0已将完成了反向传播的计算并更新了参数,修改后的参数处于下图中小灰球的位置。然而这时的设备d1并不知道参数已经被更新了,所以在时间t2时,设备d1会继续将小球向左移动,使得小球的位置达到下图中白球的位置。

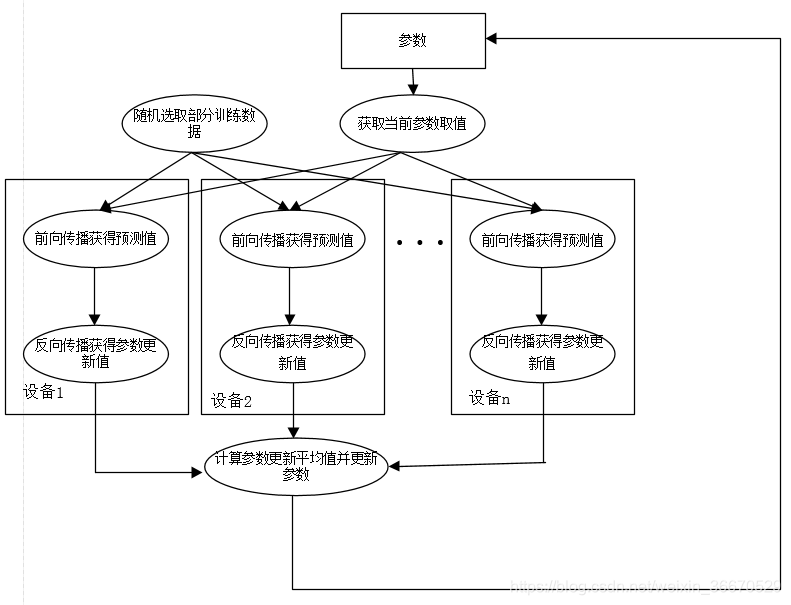
为了避免更新不同步的问题,可以使用同步模式。在同步模式下,所有的设备同时读取参数的取值,并且当反向传播算法完成之后同步更新参数的取值。单个设备不会单独对参数进行更新,而会等待所有设备都完成反向传播之后再统一更新参数。上图展示了同步模式的训练过程,在每一轮迭代时,不同设备首先统一读取当前参数的取值,并随机获取一小部分数据。然后在不同设备上运行反向传播过程得到在各自训练数据上参数的梯度。注意虽然所有设备使用的参数是一致的 ,但是因为训练数据不同,所以得到参数的梯度就可能不一样。当所有设备完成反向传播的计算之后,需要计算出不同设备上参数梯度的平均值,最后再根据平均值对参数进行更新。
同步模式解决了异步模式中存在的参数更新问题,然而同步模式的效率却低于异步模式。在同步模式下,每一轮迭代都需要设备统一开始、统一结束。如果设备的运行速度不一致,那么每一轮训练都需要等待最慢的设备结束才能开始、统一结束。如果设备的运行速度不一致,那么每一轮训练都需要等待最慢的设备结束才能开始更新参数,于是很多时间将被花在等待上。虽然理论上异步模式存在缺陷,但因为训练深度学习模型时使用的随机梯度下降本身就是梯度下降的一个近似解法,而且即使是梯度下降也无法保证达到全局最优解,所以在实际应用中,在相同的时间内,使用异步模式训练的模型不一定比同步模式差。所以两种训练模式在实践中都有非常广泛的应用。
下面给出具体的tensorflow代码,在一台机器的多个GPU上并行训练深度学习模型。因为一般来说一台机器上的多个GPU性能相似,所以在这种设置下会更多地采用同步训练深度学习模型。下面给出了具体代码,在多GPU上训练深度学习模型解决MNIST问题。使用mnist_inference.py程序来完成神经网络的前向传播过程。以下代码给出了新的神经网络训练程序mnist_multi_gpu_train.py。
- # coding=utf-8
- from datetime import datetime
- import os
- import time
-
- import tensorflow as tf
- import mnist_inference
-
- # 定义训练神经网络时需要的参数。
- BATCH_SIZE = 100
- LEARNING_RATE_BASE = 0.001
- LEARNING_RATE_DECAY = 0.99
- REGULARAZTION_RATE = 0.0001
- TRAINING_STEPS = 1000
- MOVING_AVERAGE_DECAY = 0.99
- N_GPU = 2
-
- # 定义日志和模型输出的路径。
- MODEL_SAVE_PATH = "logs_and_models/"
- MODEL_NAME = "model.ckpt"
-
-
- # 定义数据存储的路径。因为需要为不同的GPU提供不同的训练数据,所以通过placeholder
- # 的方式就需要动手准备多分数据。为了方便训练数据的获取过程,可采用Dataset的方式从
- # TFRecord中读取数据。于是在这里提供的数据文件路径为MNIST训练数据转化为TFRecord
- # 格式之后的路径。
- DATA_PATH = "otput.tfrecord"
-
- # 定义输入队列得到训练数据
- def get_input():
- dataset = tf.contrib.data.TFRecordDataset([DATA_PATH])
-
- # 定义数据解析格式。
- def parser(record):
- features = tf.place_single_example(
- record,
- features={
- 'image_raw': tf.FixedLenFeature([], tf.string),
- 'pixels': tf.FixedLenFeature([], tf.int64),
- 'label': tf.FixedLenFeature([], tf.int64),
- })
- # 解析图片和标签信息
- decoded_image = tf.decoded_raw(features['image_raw'], tf.unit8)
- reshaped_image = tf.reshape(decoded_image, [784])
- retyped_image = tf.cast(reshaped_image, tf.float32)
- label = tf.cast(feature['label'], tf.init32)
-
- return retyped_image, label
-
- # 定义输入队列。
- dataset = dataset.map(parser)
- dataset = dataset.shuffle(buffer_size=10000)
- dataset = dataset.repeat(10)
- dataset = dataset.batch(BATCH_SIZE)
- iterator = dataset.make_one_shot_iterator()
-
- feature, labels = iterator.get_next()
- return feature, labels
-
- # 定义损失函数。对于给定的训练数据、正则化损失计算规则和命名空间,计算在这个命名空间
- # 下的总损失。之所以需要给定命名空间是因为不同的GPU上计算得出的正则化损失都会加入名为
- # loss的集合,如果不通过命名空间就会将不同GPU上的正则化损失都加进来。
- def get_loss(x, y_, regularizer, scope, reuse_variables=None):
- with tf.variable_scope(tf.get_variable_scope(),
- reuse=reuse_variables):
- y = mnist_inference.inference(x, regularizer)
- # 计算交叉熵损失。
- cross_entropy = tf.reduce_mean(
- tf.nn.sparse_softmax_cross_entropy_with_logits(
- logits=y, labels=y_))
- # 计算当前GPU上计算得到的正则化损失。
- regularization_loss = tf.add(tf.get_collection('losses', scope))
- # 计算最终的总损失。
- loss = cross_entropy + regularization_liss
- return loss
-
- # 计算每一个变量梯度的平均值。
- def average_gradients(tower_grads):
- average_grads = []
-
- # 枚举所有的变量和变量在不同GPU上计算得出的梯度。
- for grad_and_vars in zip(*tower_grads):
- # 计算所有GPU上的梯度平均值。
- grads = []
- for g, _ in grad_and_vars:
- expend_g = tf.expend_dims(g, 0)
- grads.append(extend_g)
- grad = tf.concat(grads, 0)
- grad = tf.reduce_mean(grad, 0)
-
- v = grad_and_vars[0][1]
- grad_and_var = (grad, v)
- # 将变量和它的平均梯度对应起来。
- average_grads.append(grad_and_var)
- # 返回所有变量的平均梯度,这个将被用于变量的更新
- return average_grade
-
- # 主训练过程。
- def main(argv=None):
- # 将简单的运算放在CPU上,只有神经网络的训练过程放在GPU上。
- with tf.Graph().as_default(), tf.device('/cpu:0'):
- # 定义基本的训练过程
- x, y_ = get_input()
- regularizer = tf.contrib.layers.l2_regularizer(REGULARIZATION_RATE)
-
- global_step = tf.get_variable(
- 'global_step', [], initializer=tf.constant_initializer(0),
- trainable=False)
- learning_rate = tf.train.exponential_decay(
- LEARNING_RATE_BASE, global_step,
- 60000 / BATCH_SIZE, LEARNING_RATE_DECAY)
-
- opt = tf.train.GradientDescentOptimizer(learning_rate)
-
- tower_grads = []
- reuse_variables = False
- # 将神经网络的优化过程跑在不同的GPU上。
- for i in range(N_GPU):
- # 将优化过程指定在一个GPU上。
- with tf.device('/gpu:%d' % i):
- with tf.name_scope('GPU_%d' % i) as scopes:
- cur_loss = get_loss(
- x, y_, regularizer, scope, reuse_variables)
- # 在第一次声明变量以后,将控制变量重用的参数设置为True。这样可以计算
- # 让不同的GPU更新同一组参数。
- reuse_variables = True
- grads = opt.compute_gradients(cut_Loss)
- tower_grads.append(grads)
- # 计算变量的平均梯度
- grads = average_gradients(tower_grads)
- for grad, var in grads:
- if grad is not None:
- tf.summary.histogram('gradients_on_averages/%s' % var.op.name, grad)
-
- # 使用平均梯度更新参数
- apply_gradients_op = opt.apply_gradients(
- grads, global_step=global_step)
- for var in tf.trainable_variables():
- tf.summary.histogram(var.op.name, var)
-
- # 计算变量的滑动平均值。
- variable_averages = tf.train.ExponentialMOvingAverage(
- MOVING_AVERAGE_DECAY, global_step)
- variables_to_average = (
- tf.trainable_variables() + tf.moving_average_variables())
- varaibles_averages_op = variable_averages.apply(
- variables_to_average)
-
- # 每一轮迭代需要更新变量的取值并更新变量的滑动平均值。
- train_op = tf.group(apply_gradient_op, variables_averages_op)
-
- saver = tf.train.Saver()
- summmary_op = tf.summary.merge_all()
- init = tf.global_variable_initializer()
- with tf.Session(config=tf.ConfigProto(
- allow_soft_placement=True,
- log_device_placement=True)) as sess:
- # 初始化所有变量并启动队列。
- init.run()
- summary_writer = tf.summary.FileWriter(
- MODEL_SAVE_PATH, sess.graph)
-
- for step in range(TRAINING_STEPS):
- # 执行神经网络训练操作,并记录训练操作的运行时间。
- start_time = time.time()
- _, loss_value = sess.run([train_op, cur_loss])
- duration = time.time() - start_time
-
- # 每隔一段时间输出当前的训练进度,并统计训练速度。
- if step != 0 and step % 10 == 0:
- # 计算使用过的训练数据个数。因为在每一次运行训练操作时,每一个GPU
- # 都会使用一个batch的训练数据,所以总共用到的训练数据个数为
- # batch大小 X GPU个数。
- num_example_per_step = BATCH_SIZE * N_GPU
-
- # num_examples_per_step为本次迭代使用到的训练数据个数,
- # duration为运行当前训练过程中使用的时间,于是每秒可以处理的训
- # 练数据个数为num_examples_per_step / duration。
- examples_per_sec = num_examples_per_step / duration
-
- # duration为运行当前训练过程使用的时间,因为在每一个训练过程中,
- # 每一个GPU都会使用一个batch的训练数据,所以在单个batch上的训练数据
- # 所需要的时间为duration / GPU个数。
- sec_per_batch = duration / N_GPU
-
- # 输出训练信息。
- format_str = ('%s: step %d, loss = %.2f(
- %.1f examples/sec; %.3f sec/batch)')
- print (format_str % (datetime.now(), step, loss_value,
- examples_per_sec, sec_per_batch))
-
- # 通过tensorflow可视化训练过程。
- summary = sess.run(summary_op)
- summary_writer.add_summary(summary, step)
-
- # 每隔一段时间保存当前的模型。
- if step % 1000 == 0 or (step + 1) == TRAINING_STEPS:
- checkpoint_path = os.path.join(
- MODEL_SAVE_PATH, MODEL_NAME)
- saver.save(sess, checkpoint_path, global_step=step)
-
- if __name__ == '__main__':
- tf.app.run()
-
- '''
- 在AWS的g2.8xlarge实例上运行上面这段代码可以得到类似下面的结果:
- step 10, loss = 71.90 (15292.3 examples/sec; 0.007 sec/batch)
- step 20, loss = 37.97 (18758.3 examples/sec; 0.005 sec/batch)
- step 30, loss = 9.54 (16313.3 examples/sec; 0.006 sec/batch)
- step 40, loss = 11.84 (14199.0 examples/sec; 0.007 sec/batch)
- '''
- step 980, loss = 0.66 (15034.7 examples/sec; 0.007 sec/batch)
- step 990, loss = 1.56 (16134.1 examples/sec; 0.006 sec/batch)
- '''
三、分布式tensorflow
1.分布式tensorflow原理
以下代码创建了一个最简单的tensorflow集群:
- import tensorflow as tf
-
- c = tf.constant("Hello, distuributed Tensorflow!")
- # 创建一个本地tensorflow集群
- server = tf.train.Server.create_local_server()
- # 在集群上创建一个会话。
- sess = tf.Session(server.target)
- # 输出Hello, distributed Tensorflow!
- print sess.run(c)
在以上代码中,首先通过tf.train.Server.create_local_server函数在本地创建了一个只有一台机器的tensorflow集群。然后在该集群上生成了一个会话,并通过生成的会话将运算运行在创建的tensorflow集群上。虽然这只是一个单机集群,但它大致反映了tensorflow集群的工作流程。tensorflow集群通过一系列任务(tasks)来执行tesnorflow计算图中的运算。一般来说,不同任务跑在不同机器上。最主要的例外是使用GPU时,不同任务可以使用同一台机器上的不同GPU。tensorflow集群中的任务也会被聚合成工作(jobs),每个工作包含一个或者多个任务。比如在训练深度学习模型时,一台运行反向传播的机器是一个任务,而所有运行反向传播机器的集合是一种工作。
以上样例代码是只有一个任务的集群。当一个tensorflow集群有多个任务时,需要使用tf.train.ClusterSpec来指定运行每一个任务的机器。比如以下代码展示了在本地运行有两个任务的tensorflow集群。第一个任务的代码如下:
- import tensorflow as tf
- c = tf.constant("Hello from server!")
-
- # 生成一个有两个任务的集群,一个任务跑在本地2222端口,另外一个跑在本地2223端口。
- cluster = tf.train.ClusterSpec(
- {"local": ["localhost:2222", "localhost:2223"]})
-
- # 通过上面生成的集群配置生成Server,并通过job_name和task_index指定当前所启动
- # 的任务。因为该任务是第一个任务,所以task_index为0。
- server = tf.train.Server(cluster, job_name="local", task_index=0)
-
- # 通过server.target生成会话来使用Tensorflow集群中的资源。通过设置
- # log_device_placement可以看到执行每一个操作的任务。
- sess = tf.Session(
- server.target, config=tf.ConfigProto(log_device_placement=True))
- print sess.run(c)
- server.join()
下面给出了第二个任务的代码:
- import tensorflow as tf
- c = tf.constant("Hello from server2!")
-
- # 和第一个程序一样的集群配置。集群中的每一个任务需要采样相同的配置。
- cluster = tf.train.ClusterSpec(
- {"local":["localhost:2222", "localhost:2223"]})
- # 指定task_index为1,所以这个程序将在localhost:2223启动服务。
- server = tf.train.Server(cluster, job_Name="local", task_index=1)
- # 剩下的代码都和第一个任务的代码一致。
- ...
启动第一个任务后,可以得到类似下面的输出:
- tensorflow/core/distributed_runtime/rpc/grpc_channel.cc:215] Initialize
- GrpcChannelCache for job local -> {0 -> localhost:2222, 1 -> localhost:2223}
- tensorflow/core/distributed_runtime/rpc/grpc_server_lib.cc:316] Started
- serve with target: grpc://localhost:2222
- tensorflow/core/distributed_runtime/master.cc:209] CreateSession still
- waiting for response from worker: /job:local/replica:0/task:1
- tensorflow/core/distributed_runtime/master.cc:209] CreateSession still
- waiting for response from worker: /job:local/replica:0/task:1
- tensorflow/core/distributed_runtime/master_session.cc:998] Start master
- session 67a422339d0b7833 with config: log_device_Placement: true
- Const: (Const): /job:local/replica:0/task:0/cpu:0
- tensorflow/core/common_runtime/simple_place.cc:872]
- (Const) /job:local/replica:0/task:0/cpu:0
- Hello from server1!
从第一个任务输出中可以看到,当只启动第一个任务时,程序会停下来等待第二个任务启动,而且持续输出CreateSession still waiting for response from worker: /job:local/replica:0/task:0/task:1。当第二个任务启动后,可以看到从第一个任务中会输出Hello from server1!的结果。第二个任务的输出如下:
- tensorflow/core/distributed_runtime/rpc/grpc_channel.cc:215] Initialize
- GrpcChannelCache for job local -> {0 -> localhost:2222, 1 -> localhost:2223}
- tensorflow/core/distributed_runtime/rpc/grpc_server_lib.cc:316] Started
- serve with target: grpc://localhost:2223
- tensorflow/core/distributed_runtime/master_session.cc:998] Start master
- session 67a422339d0b7833 with config: log_device_Placement: true
- Const: (Const): /job:local/replica:0/task:0/cpu:0
- tensorflow/core/common_runtime/simple_place.cc:872]
- (Const) /job:local/replica:0/task:0/cpu:0
- Hello from server2!
值得注意的是第二个任务中定义的计算定义也被放在了设备/job:local/replica:0/task:0/cpu:0上。也就是说这个计算将由第一个任务来执行。从上面这个样例可以看到,通过tf.train.Server.target生成的会话可以统一管理整个tensorflow集群中的资源。
和使用多GPU类似,tensorflow支持通过tf.device来指定操作运行在哪个任务上。比如将第二个任务重定义计算的语句改为以下代码,就可以看到这个计算被调度到/job:local/replica:0/task:1/cpu:0上面。
- with tf.device("/job:local/task:1")
- c = tf.constant("Hello from server2!")
在以上样例中只定义了一个工作"local"。但一般在训练深度学习模型时,会定义两个工作。一个专门负责存储、获取以及更新变量的取值,这个工作所包含的任务统称为参数服务器(parameter server, ps)。另外一个工作负责运行反向传播算法来获取参数梯度,这个工作包含的任务统称为计算服务器(worker)。下面给出了一个比较常见的用于训练深度学习模型的tensorflow集群配置方法。
- tf.train.clusterSpec({
- "worker": [
- "tf-worker0:2222",
- "tf-worker1:2222",
- "tf-worker2:2222"
- ],
- "ps": [
- "tf-ps0:2222",
- "tf-ps1:2222"
- ]})
使用分布式tensorflow训练神经学习模型一般有两种方式。一种方式叫做计算图内分布式(in-graph replication)。使用这种分布式训练方式时,所有的任务都会使用一个tensorflow计算图中的变量(也就是深度学习中的参数),而只是将计算部分发布到不同的计算服务器上。多GPU样例程序将计算复制了多份,每一份放到一个GPU上进行计算。但不同的GPU使用的参数都是在一个tensorflow计算图中的。因为参数都是存在同一个计算图中,所以同步更新参数比较容易控制。因为计算图内分布式需要有一个中心节点来生成这个计算图并分配计算任务,所以当数据量太大时,这个中心节点容易造成性能瓶颈。
另一种分布式tensorflow训练深度学习模型的方法叫计算图之间分布式(between-graph replication)。使用这种分布式方式时,在每一个计算服务器上都会创建一个独立的tensorflow计算图,但不同计算图中的相同参数需要一种固定的方式放到同一个参数服务器上。tensorflow提供了tf.train.replica_device_setter函数来帮助完成这一个过程。因为每个计算服务器的tensorflow计算图是独立的,所以这种方式的并行度要更高。但在计算图之间分布式下进行参数的同步更新比较困难。为了解决这个问题,tensorflow提供了tf.train.SyncReplicasOptimizer函数来帮助实现参数的同步更新。这让计算图之间分布式方式更加广泛地应用。
2.分布式tensorflow模型训练
下面将给出两个样例程序分别实现使用计算图之间分布式(Between-graph replication)完成分布式深度学习模型训练的一步更新和同步更新。第一部分将给出使用计算图之间分布式实现异步更新的tensorflow程序。这一部分也会给出具体的命令行将该程序分布式的运行在一个参数服务器和两个计算服务器上,并通过tensorflow可视化在第一个服务器上的tensorflow计算图。第二部分将给出计算图之间分布式实现同步参数更新的tesnorflow程序。同步参数更新的代码大部分和异步更新相似,所以这一部分中将重点介绍他们之间的不同之处。
异步模式样例程序
以下代码实现可异步模式的分布式神经网络的训练过程。
- # coding=utf-8
- import time
- import tensorflow as tf
- from tensorflow.example.tutorials.mnist import input_data
-
- import mnist_inference
-
-
- # 配置神经网络的参数
- BATCH_SIZE = 100
- LEARNING_RATE_BASE = 0.01
- LEARNING_RATE_DECAY = 0.99
- REGULARAZTION_RATE = 0.0001
- TRAINING_STEPS = 20000
- MOVING_AVERAGE_DECAY = 0.99
-
- # 模型保存的路径。
- MODEL_SAVE_PATH = "logs/log_async"
- # MNIST数据路径。
- DATA_PATH = "path/to/mnist/data"
-
-
- # 通过flags指定运行的参数。
- # 但这不是一种可扩展的方式。这里将使用运行程序时给出的参数来配置在不同
- # 任务中运行的程序。
- FLAGS = tf.app.flags.FLAGS
- # 指定当前运行的是参数服务器还是计算服务器。参数服务器只负责Tensorflow中变量的维护
- # 和管理,计算服务器负责每一轮迭代时运行反向传播过程。
- tf.app.flags.DEFINE_string('job_name', 'worker', ' "ps" or "worker"')
- # 指定集群中的参数服务器地址。
- tf.app.flags.DEFINE_string(
- 'ps_hosts', 'tf-ps0:2222,tf-ps1:1111',
- 'Comma-separated list of hostname:port for the parameter server '
- 'joba. e.g. "tf-ps0:2222, tf-ps1:1111" ')
-
- # 指定集群中的计算服务器地址。
- tf.app.flags.DEFINE_string(
- 'worker_hosts', 'tf-worker0:2222, tf-worker1:1111',
- 'Comma-separated list of homename:port for the worker jobs. '
- 'e.g. "tf-worked0:2222, tf-worker1:1111" ')
-
-
- # 指定当前程序的任务ID。tensorflow会根据参数服务器/计算服务器列表中的端口号
- # 来启动服务器。注意参数服务器和计算服务器的编号都是从0开始的。
- tf.app.flags.DEFINE_integer(
- 'task_id', 0, 'Task ID of the worker/replica running the training.')
-
- # 定义tensorflow的计算图,并返回每一轮迭代时需要运行的操作。
- def build_model(x, y_, is_chief):
- regularizer = tf.contrib.layer.l2_regularizer(REGULARAZTION_RATE)
- y = mnist_inference.inference(x, regularizer)
- global_step = tf.contrib.framework.get_or_create_global_step()
-
- # 计算损失函数并定义反向传播过程。
- cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(
- logits = y, labels = tf.argmax(y_, 1))
- cross_entropy_mean = tf.reduce_mean(cross_entropy)
- loss = cross_entropy_mean + tf.add_n(tf.get_collection('losses'))
- learning_rate = tf.train.exponential_decay(
- LEARNING_RATE_BASE,
- global_step,
- 60000 / BATCH_SIZE,
- LEARNING_RATE_DECAY)
- train_op = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss,
- global_step = global_step)
- # 定义每一轮迭代需要运行的操作。
- if is_chief:
- # 计算变量的滑动平均值。
- variable_average = tf.train.ExponentialMovingAverage(
- MOVING_AVERGAE_DECAY, global_step)
- variables_average_op = variable_average.apply(
- tf.trainable_variables())
- with tf.control_dependencies([variable_average_op, train_op]):
- train_op = tf.no_op()
- return global_step, loss, train_op
-
- def main(argv = None):
- # 解析flags并通过tf.train.ClusterSpec配置tensorflow集群。
- ps_hosts = FLAGS.ps_hosts.split(',')
- worker_hosts = FLAGS.worker_hosts.split(',')
- cluster = tf.train.ClusterSpec(
- {"ps": ps_hosts, "worker": worker_hosts})
- # 通过tf.train.ClusterSpec以及当前任务共创建tf.train.Server。
- server = tf.train.Server(cluster,
- job_name=FLAGS.job_name,
- task_index=FLAGS.task_id)
- # 参数服务器只需要管理tensorflow中的变量,不需要执行训练的过程。server.join()
- # 会一致停在这条语句上。
- if FLAGS.job_name == 'ps':
- with tf.device("/cpu:0"):
- server.join()
-
- # 定义计算服务器需要运行的操作。
- is_chief = (FLAGS.task_id == 0)
- mnist = input_data.read_data_sets(DATA_PATH, one_hot=True)
-
-
- # 通过tf.train.replica_device_setter函数来指定执行每一个运算的设备。
- # tf.train.replica_device_setter函数会自动将所有的参数分配到参数服务器上,将
- # 计算分配到当前的计算服务器上。
- device_setter = tf.train.replica_device_setter(
- worker_device="/job:worker/task:%d" % FLAGS.task_id,
- cluster=cluster)
-
- with tf.device(device_setter):
- # 定义输入并得到每一轮迭代需要运行的操作。
- x = tf.placeholder(
- tf.float32, [None, mnist_inference.INPUT_NODE],
- name='x-input')
- y_ = tf.placeholder(
- tf.float32, [None, mnist_inference.OUTPUT_NODE],
- name='y-input')
- global_config = tf.ConfigProto(allow_soft_placement=True,
- log_device_placement=False)
-
- # 通过tf.train.MonitoredTrainingSession管理训练深度学习模型的通用功能。
- with tf.train.MonitoredTrainingSession(
- master=server.target,
- is_chief=is_chief,
- checkpoint_dir=MODEL_SAVE_PATH,
- hooks=hooks,
- save_checkpoint_secs=60,
- config=sess_config) as mon_sess:
- print "session started."
- step = 0
- start_time = time.time()
-
- # 执行迭代过程。在迭代过程中tf.train.MonitoredTrainingSession会帮助
- # 完成初始化。从checkpoint中加载训练过程的模型。输出日志并保存模型,所以
- # 以下程序中不需要在调用这些过程。tf.train.StopAtStepHook会帮助判断
- # 是否需要退出。
- while not mon_sess.should_stop():
- xs, ys = mnist.train.next_batch(BATCH_SIZE)
- _, loss_value, global_step_value = mon_sess.run(
- [train_op, loss, global_step], feed_dict = {x:xs, y_: ys})
-
- # 每隔一段时间输出训练信息。不同的计算服务器都会更新全局的训练轮数,
- # 所以这里使用global_step_value得到训练中使用过的batch的总数。
- if step > 0 and step % 100 == 0:
- duration = time.time() - start_time
- sec_per_batch = duration / global_step_value
- format_str = "After %d training steps " +\
- "(%d global steps), loss on training " +\
- "batch is %g. (% .3f sec/batch)"
- print format_str % (step, global_step_value, loss_value,
- sec_per_batch)
- step += 1
-
- if __name__ == "__main__":
- tf.app.run()
假设上面代码的文件名为dist_mnist_saync.py,那么要启动一个拥有一个参数服务器、两个计算服务器的集群,需要先在运行参数服务器的机器上启动以下命令:
- python dist_tf_main_async.py \
- --job_name='ps' \
- --task_id = 0 \
- --ps_hosts='tf-ps0:2222' \
- --worker_hosts='tf-worker0:2222,tf-worker1:2222'
然后在运行第一个服务器的机器上启动以下命令:
- python dist_tf_main_async.py \
- --job_name='worker' \
- --task_id = 0 \
- --ps_hosts='tf-ps0:2222' \
- --worker_hosts='tf-worker0:2222,tf-worker1:2222'
最后在运行第二个计算服务器的机器上启动以下命令:
- python dist_tf_main_async.py \
- --job_name= 'worker' \
- --task_id = 1 \
- --ps_hosts= 'tf-ps0:2222' \
- --worker_hosts= 'tf-worker0:2222,tf-worker1:2222'
最后在运行第二个计算服务器的机器上启动以下命令:
- python dist_tf_main_async.py \
- --job_name='worker' \
- --task_id = 1 \
- --ps_hosts='tf-ps0:2222' \
- --worker_hosts='tf-worker0:2222,tf-worker1:2222'
在启动第一个计算服务器之后,这个计算服务器就会尝试连接其他的服务器(包括计算服务器和参数服务器)。如果其他服务器还没有启动,则被启动的计算服务器会提示等待连接其它服务器。以下代码展示了一个预警信息。
- tensorflow/core/distributed_runtime/master.cc:209] CreateSession still
- waiting for response from worker: /job:worker/replica:0/task:1
不过这不影响tensorflow集群的启动。当tensorflow集群中所有服务器都被启动之后,每一个计算服务器将不再预警。在tensorflow集群完全启动之后,训练过程将被执行。在计算服务器训练神经网络的过程中,第一个计算服务器会输出类似下面的信息。
- After 100 training steps (100 global steps), loss on training batch is 0.302718.
- (0.039 sec/batch)
- After 200 training steps (200 global steps), loss on training batch is 0.269476.
- (0.037 sec/batch)
- After 300 training steps (300 global steps), loss on training batch is 0.286755.
- (0.037 sec/batch)
- After 400 training steps (463 global steps), loss on training batch is 0.349983.
- (0.033 sec/batch)
- After 500 training steps (666 global steps), loss on training batch is 0.229955.
- (0.029 sec/batch)
- After 600 training steps (873 global steps), loss on training batch is 0.245588.
- (0.027 sec/batch)
第二个服务器会输出类似下面的信息。
- After 100 training steps (537 global steps), loss on training batch is 0.223165.
- (0.007 sec/batch)
- After 200 training steps (732 global steps), loss on training batch is 0.186126.
- (0.010 sec/batch)
- After 300 training steps (925 global steps), loss on training batch is 0.228191.
- (0.012 sec/batch)
从输出信息中可以看到,在第二个计算服务器启动之前,第一个计算服务器已经运行了很多轮迭代了。在异步模式下,即使有计算服务器没有正常工作,参数更新的过程仍可继续,而且全局的迭代轮数是所有计算服务器迭代轮数的和。
同步模式样例程序
该代码实现了同步模式的分布式神经网络训练过程。
- # coding = utf-8
- import time
- import tensorflow as tf
- from tensorflow.example.tutorials.mnist import input_data
-
- import mnist_inference
-
- # 配置神经网络的参数。
- BATCH_SIZE = 100
- LEARNING_RATE_BASE = 0.01
- LEARNING_RATE_DECAY = 0.99
- REGULARAZTION_RATE - 0.0001
- TRAINING_STEPS = 20000
- MOVING_AVERAGE_DECAY = 0.99
-
- MODEL_SAVE_PATH = "logs/log_sync"
- DATA_PATH = "/path/to/mnist/data"
-
-
- # 和异步模式类似的设置false。
- FLAGS = tf.app.flags.FLAGS
-
- tf.app.flags.DEFINE_string('job_name', 'worker', ' "ps" or "worker" ')
- tf.app.flags.DEFINE_string(
- 'ps_hosts', ' tf-ps0:2222,tf-ps1:1111',
- 'Comma-separated list of hostname:port for the parameter server '
- 'jobs. e.g. "tf-ps0:2222,tf-ps1:1111" ')
-
- tf.app.flags.DEFINE_string(
- 'ps_hosts', ' tf-ps0:2222,tf-ps1:1111',
- 'Comma-separated list of hostname:port for the worker jobs. '
- 'e.g. "tf-worker0:2222,tf-worker1:1111" ')
- tf.app.flags.DEFINE_integer(
- 'task_id', 0, 'Task ID of the worker/replica running the training.')
-
- # 和异步模式类似的定义tensorflow的计算图。唯一的区别在于使用
- # tf.train.SyncReplicasOptimizer函数处理同步更新。
- def build_model(x, y_, n_worker, is_chief)
- regularizer = tf.contrib.layers.l2_regularizer(REGULARAZATION_RATE)
- y = mnist_inference.inference(x, regularizer)
- global_step = tf.contrib.framework.get_or_create_global_step()
-
- cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(
- logits=y, labels=tf.argmax(y_, 1))
- cross_entropy_mean = tf.reduce_mean(cross_enropy)
- loss = cross_entropy_mean + tf.add_n(tf.get_collection('lossses'))
- learning_rate = tf.train.exponential_decay(
- LEARNING_RATE_BASE,
- global_step,
- 60000 / BATCH_SIZE,
- LEARNING_RATE_DECAY)
-
- # 通过tf.train.SyncReplicaOptimizer函数实现同步更新。
- opt = tf.train.SyncReplicasOptimizer(
- tf.train.GradientDescentOptimizer(learning_rate),
- replica_to_aggregate=n_workers,
- total_num_replicas = n_workers)
- sync_replicas_hook = opot.make_session_run_hook(is_chief)
- train_op = opt.minimize(loss, global_step=global_step)
-
- if is_chief:
- variable_average = tf.train.ExponentialMovingAverage(
- MOVING_AVERAGE_DECAY, global_step)
- variable_average_op = variable_average.apply(
- tf.trainable_variables())
- with tf.control_dependencies([variables_average_op, train_op]):
- train_op = tf.no_op()
-
- return global_step, loss, train_op, sync_replicas_hook
-
- def main(argv=None):
- # 创建tensorflow集群。
- ps_hosts = FLAGS.ps_hosts.split(',')
- worker_hosts = FLAGS.worker_hosts.split(',')
- n_workers = len(worker_hosts)
- cluster = tf.train.ClusterSpec(
- {"ps": ps_hosts, "worker": worker_hosts})
-
- server = tf.train.Server(cluster,
- job_name=FLAGS.job_name,
- task_index=FALGS.task_id)
-
- if FLAGS.job_name == 'ps':
- with tf.device("/cpu:0"):
- server.join()
- is_chief = (FLAGS.task_id == 0)
- mnist = input_data.read_data_sets(DATA_PATH, one_hot=True)
-
- device_setter = tf.train.replica_device_setter(
- worker_device="/job:worker/task:%d" % FLAGS.task_id
- cluster=cluster)
-
- with tf.device(device_setter):
- x = tf.placeholder(
- tf.float32, [None_inference.INPUT_NODE],
- name='x-input')
- y_ = tf.placeholder(
- tf.float32, [None, mnist_inference.INPUT_NODE],
- name = 'y-input')
- global_step, loss, train_op, sync_replica_hook = build_model(
- x, y_, n_workers, is_chief)
-
- # 把处理同步更新的hook也加进来。
- hooks=[sync_replicas_hook,
- tf.train.StopAtStepHook(last_step=TRAINING_STEPS)]
- sess_config = tf.ConfigProto(allow_soft_placement=True,
- log_device_placement=False)
-
- # 训练过程和异步一致。
- with tf.train.MonitoredTrainingSession(
- master=server.target,
- is_chief=is_chief,
- checkpoint_dir=MODEL_SAVE_PATH,
- hooks=hopoks,
- save_checkpoint_secs=60,
- config=sess_config) as mon_sess:
- print "session started."
- step = 0
- start_time = time.time()
-
- while not mon_sess.should_stop():
- xs, ys = mnist.train.next_batch(BATCH_SIZE)
- _, loss_value, global_step_value = mon_sess.run(
- [train_op, loss, global_step], feed_dict={x: xs, y_: ys})
-
- if step > 0 and step % 100 == 0:
- duration = time.time() - start_time
- sec_per_batch = duration / global_step_value
- fromat_str = "After %d training steps(%d global " +\
- "steps), loss on training " +\
- " batch is %g. (%.3f sec/batch)"
-
- print format_str % (step, global_step_values, loss_values,
- sec_per_batch)
- step += 1
-
- if __name__ == "__main__"
- tf.app.run()
和异步模式类似,在不同机器上运行以上代码就可以启动tensorflow集群。在第一个计算服务器上,可以看到与下面类似的输出。
- After 100 training steps (49 global steps), loss on training batch is 1.60499.
- (0.049 sec/batch)
- After 200 training steps (99 global steps), loss on training batch is 1.10667.
- (0.040 sec/batch)
- After 300 training steps (149 global steps), loss on training batch is 0.968059.
- (0.036 sec/batch)
- After 400 training steps (230 global steps), loss on training batch is 0.833886.
- (0.035 sec/batch)
- After 500 training steps (330 global steps), loss on training batch is 0.846468.
- (0.032 sec/batch)
第二个计算服务器的输出如下:
- After 100 training steps (268 global steps), loss on training batch is 0.810314.
- (0.035 sec/batch)
- After 200 training steps (368 global steps), loss on training batch is 0.602304.
- (0.032 sec/batch)
- After 300 training steps (468 global steps), loss on training batch is 0.72167.
- (0.031 sec/batch)
- After 400 training steps (568 global steps), loss on training batch is 0.529358.
- (0.030 sec/batch)
- After 500 training steps (668 global steps), loss on training batch is 0.626258.
- (0.030 sec/batch)
和异步模式不同。在同步模式下,global_step差不多是两个计算器local_step的平均值。比如在第二个计算服务器还没有开始之前,global_step是第一个服务器local_step的一半。这是因为同步模式要求收集replicas_to_aggragate是第一个服务器local_step的一半。这是因为同步模式要求收集replicas_to_aggregate份梯度才会开始更新(注意这里tensorflow不要求每一份梯度来自不同的计算服务器)。同步模式不仅仅是一次使用多份梯度。tf.train.SyncReplicasOptimizer的实现同时也保证了不会出现陈旧变量的问题。tf.train.SyncReplicasOptimizer函数会记录每一份梯度是不是由最新的变量值计算得到的,如果不是,那么这一份梯度将会被丢弃。

