
- 1基于Java+SpringBoot+Vue前后端分离婚纱影楼管理系统设计和实现_springboot vue婚纱影楼系统
- 2保姆级教程-如何使用LLAMA2 大模型_如何调用 llama 的 api
- 3Jenkins忘记密码解决方案_jenkins忘记用户名和密码
- 4《Python编程:从入门到实践》第12章:武装飞船_python入门到实践中的 ship.bmg
- 52023美赛E题_2023美赛e题 背景 光污染是用来描述任何过度或不良的使用人工光。一些我们称之为
- 6MYSQL 8 UNDO 表空间 你了解多少
- 7vs code解决无法识别已安装python库的问题(Mac版)
- 8初始MyBatis,w字带你解MyBatis
- 9video 标签设置样式_video标签样式
- 10如何在论文中画出漂亮的插图?
LLM基石:RLHF及其替代技术
赞
踩
点击 机器学习算法与Python学习 ,选择加星标
精彩内容不迷路
机器之心编译
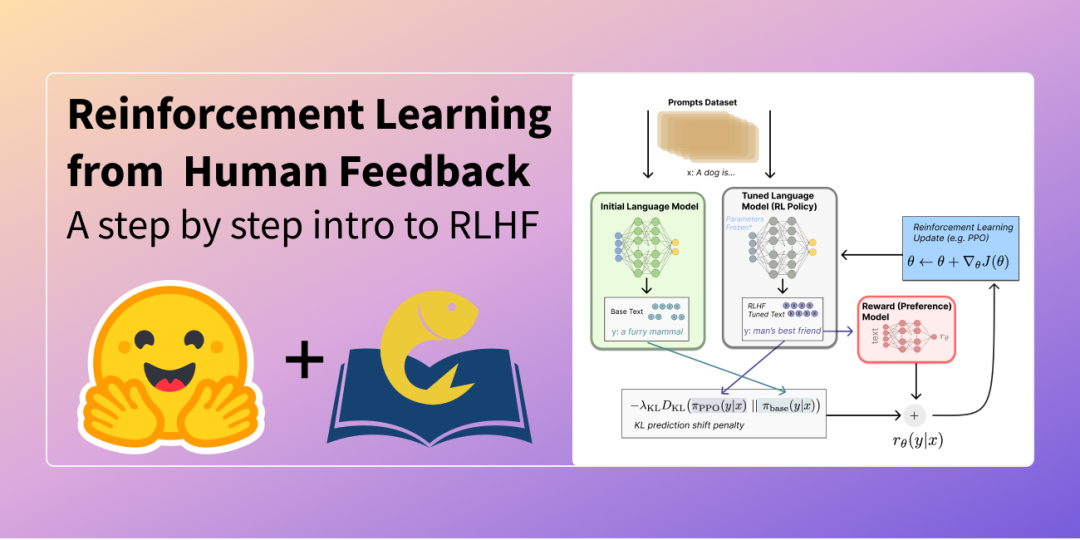
在讨论 LLM 时,我们总是会涉及一个名为「使用人类反馈的强化学习(RLHF)」的过程。RLHF 是现代 LLM 训练流程中不可或缺的一部分,因为它可以将人类偏好整合到优化图景中,从而提升模型的有用性和安全性。
在这篇文章中,机器学习和 AI 研究者 Sebastian Raschka 将逐步解读 RLHF 的工作过程,以帮助读者理解其核心思想和重要性。这篇文章也会比较 ChatGPT 和 Llama 2 执行 RLHF 的方式。
文章最后还将简单介绍一些最近出现的可替代 RLHF 的技术。
本文的目录如下:
使用人类反馈的强化学习(RLHF)
Llama 2 中的 RLHF
RLHF 的替代技术
典型的 LLM 训练流程
ChatGPT 或 Llama 2 等基于 transformer 的现代 LLM 的训练流程一般分为三大步骤:
预训练;
监督式微调;
对齐。
在最初的预训练阶段,模型会从海量的无标签文本数据集中吸收知识。后续的监督式微调阶段会对这些模型进行微调,使之能更好地遵守特定指令。最后的对齐阶段则是对 LLM 进行打磨,使之在响应用户 prompt 时能给出更有用且更安全的结果。
请注意,这个训练流程基于 OpenAI 的 InstructGPT 论文《Training language models to follow instructions with human feedback》,该论文详述了 GPT-3 的训练过程。人们普遍认为 ChatGPT 的训练也使用了此种方法。后面我们还会比较一下该方法与 Meta 最新的 Llama 2 所采用的方法。
首先从最初的预训练步骤开始吧,如下图所示。

LLM 的预训练步骤
预训练通常需要使用一个超大型的文本语料库,其中包含数十亿乃至数万亿 token。预训练阶段的训练任务很简单直接,就是根据前文预测下一个词。
值得强调的一点是,这种类型的预训练让我们可以利用大型的无标注数据集。只要我们能够在不侵犯版权或无视创作者偏好的情况下使用数据,我们就可以使用大型数据集,而无需人来手动标记。事实上,在这个预训练步骤中,其「标签」就是文本中的后一个词,而这本身就已经是数据集的一部分了(因此,这种预训练方法通常被称为自监督学习)。
接下来的步骤是监督式微调,其过程如下图所示。

根据指令数据对预训练后的模型进行微调
监督式微调阶段涉及到另一轮对下一 token 的预测。但是,不同于之前的预训练阶段,模型现在处理的是成对的「指令 - 输出」,如上图所示。在这里,指令是指提供给模型的输入(根据任务的不同,指令中有时候会带有可选的输入文本)。输出则是模型给出的接近我们期望的响应。
这里给出一个具体示例,对于下面这一对「指令 - 输出」:
指令:"Write a limerick about a pelican."
输出:"There once was a pelican so fine..."
模型将指令文本(Write a limerick about a pelican)作为输入,执行下一 token 预测获得输出文本(There once was a pelican so fine...)。
尽管预测下一 token 这个训练目标是相似的,但监督式微调使用的数据集通常比预训练所用的小得多。这是因为它需要的是指令 - 输出对,而不只是原始文本。为了构建这样一个数据集,必需有一个人类(或另一个高质量 LLM)来根据给定指令写出所需输出 —— 创建这样一个数据集非常费力。
在这个监督式微调阶段之后,还有另一个微调阶段,该阶段通常被称为「对齐」步骤,其主要目标是将 LLM 与人类偏好对齐。这就是 RLHF 的用武之地。
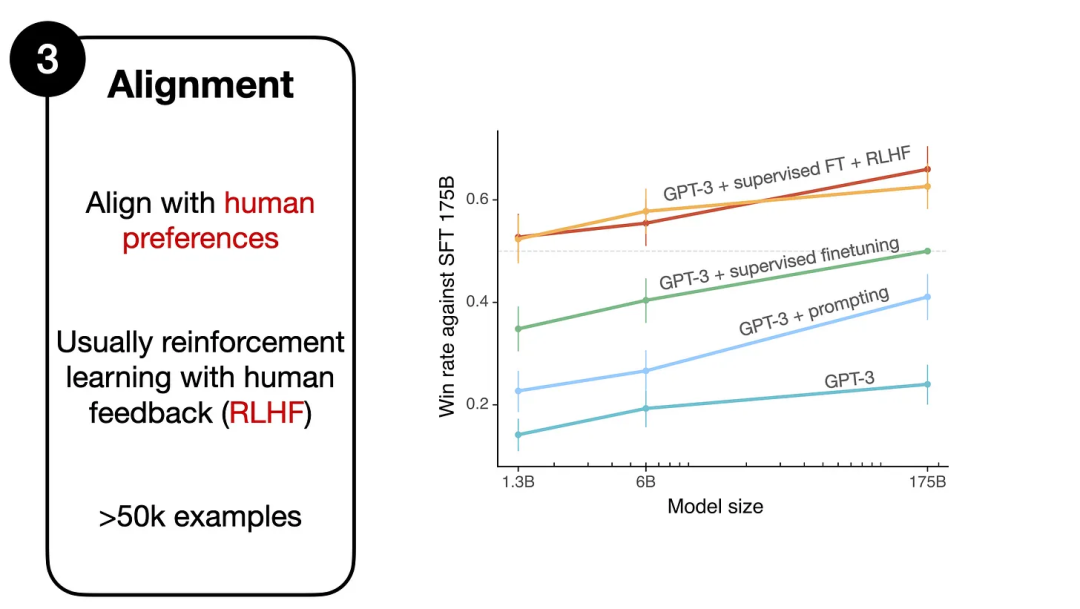
对齐,右侧图表来自 InstructGPT 论文
下一节将深入介绍基于 RLHF 的对齐步骤。但是,如果你想对比一下其与预训练的基础模型和步骤 2 的监督式微调,可以看看来自 InstructGPT 论文的上图。
上图比较了经过监督式微调后的以及使用其它方法的 GPT-3 模型(1750 亿参数)。图中最下方是基础 GPT-3 模型。
可以看到,如果采用 prompt 工程设计方法,即多次查询并选取其中的最佳响应(GPT-3 + prompting),则能获得比基础模型更好的表现,这符合我们的预期。
而如果将监督式微调用于 GPT-3 基础模型,则还能取得甚至更优的表现(GPT-3 + supervised finetuning)。
但是,这里表现最佳的还是使用了监督式微调及 RLHF 的 GPT-3 模型(GPT-3 + supervised finetuning + RLHF)—— 即图中最上面的两条线。(注意,这里之所以有两条线,是因为研究者实验了两种不同的采样方法。)
下面将更详细地介绍 RLHF 步骤。
使用人类反馈的强化学习(RLHF)
前一节讨论了 ChatGPT 和 Llama-2-chat 等现代 LLM 背后的三步式训练流程。这一节将更为详细地描述微调阶段,并重点关注 RLHF 部分。
RLHF 工作流程是通过一种监督式的方式来对预训练模型进行微调(前一节的第 2 步),然后再通过近端策略优化(PPO)来对齐它(前一节的第 3 步)。
为了简单起见,我们可将 RLHF 工作流程再分为三步:
RLHF 第 1 步:对预训练模型进行监督式微调;
RLHF 第 2 步:创建一个奖励模型;
RLHF 第 3 步:通过近端策略优化进行微调。
如下所示,RLHF 第 1 步是监督式微调步骤,目的是创建用于进一步 RLHF 微调的基础模型。
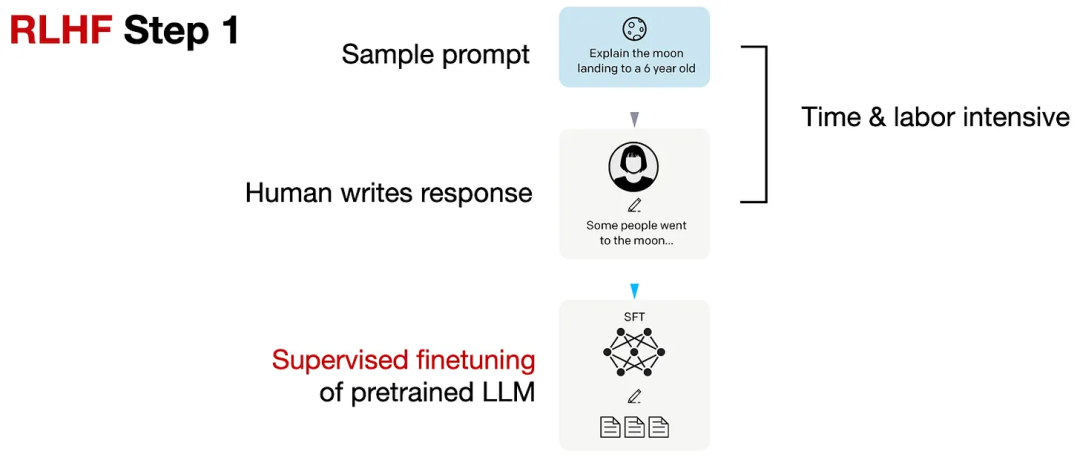
RLHF 第 1 步,图片来自 InstructGPT 论文
在 RLHF 第 1 步,我们创建或采样 prompt(比如从一个数据库中采样),然后让人类编写质量优良的响应。然后使用这个数据集通过一种监督式方式来微调预训练模型。
要注意,RLHF 第 1 步类似于前一节的第 2 步,即「典型的 LLM 训练流程」。这里再次列出它,因为这是 RLHF 不可或缺的一部分。
然后在 RLHF 第 2 步,使用经过监督式微调的模型创建一个奖励模型,如下所示。
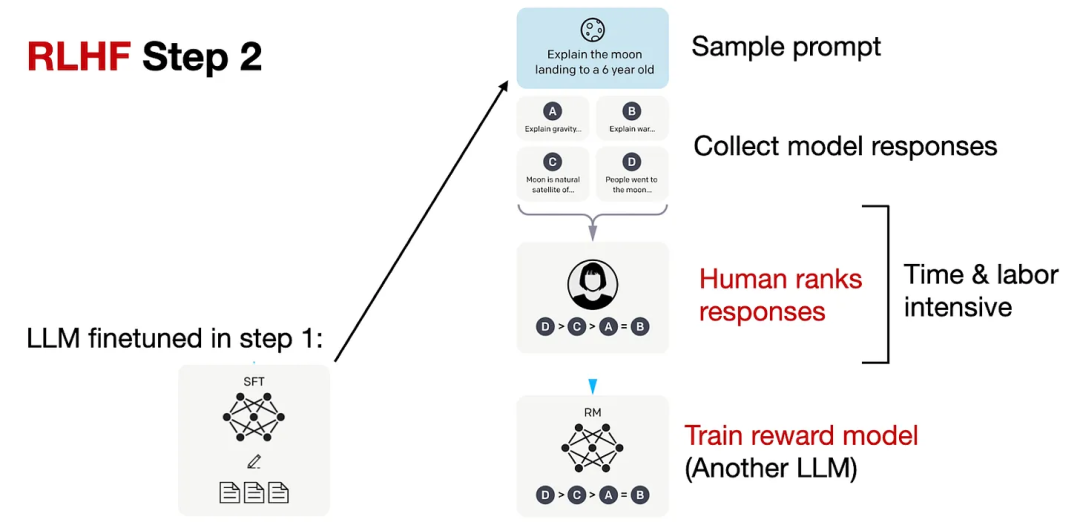
RLHF 第 2 步,图片来自 InstructGPT 论文
如上图所示,用上一步中创建的已微调 LLM 为每个 prompt 生成 4-9 个响应。然后再让人基于自己的偏好对这些响应进行排名。尽管这个排名过程非常耗时,但相比于创建用于监督式微调的数据集,其劳动力密集程度可能要低一些。这是因为对响应进行排名多半比编写响应更简单。
然后基于使用这些排名构建的数据集,我们可以设计一个奖励模型,其输出的是用于 RLHF 第 3 步后续优化阶段的奖励分数。这个奖励模型通常源自之前的监督式微调步骤创建的 LLM。下面将奖励模型简称为 RM,将经过监督式微调后的 LLM 简称为 SFT。为了将 RLHF 第 1 步的模型变成奖励模型,需要将其输出层(下一 token 分类层)替换成一个回归层,其具有单个输出节点。
RLHF 工作流程的第 3 步是使用这个奖励模型(RM)来微调之前监督式微调的模型(SFT),如下图所示。
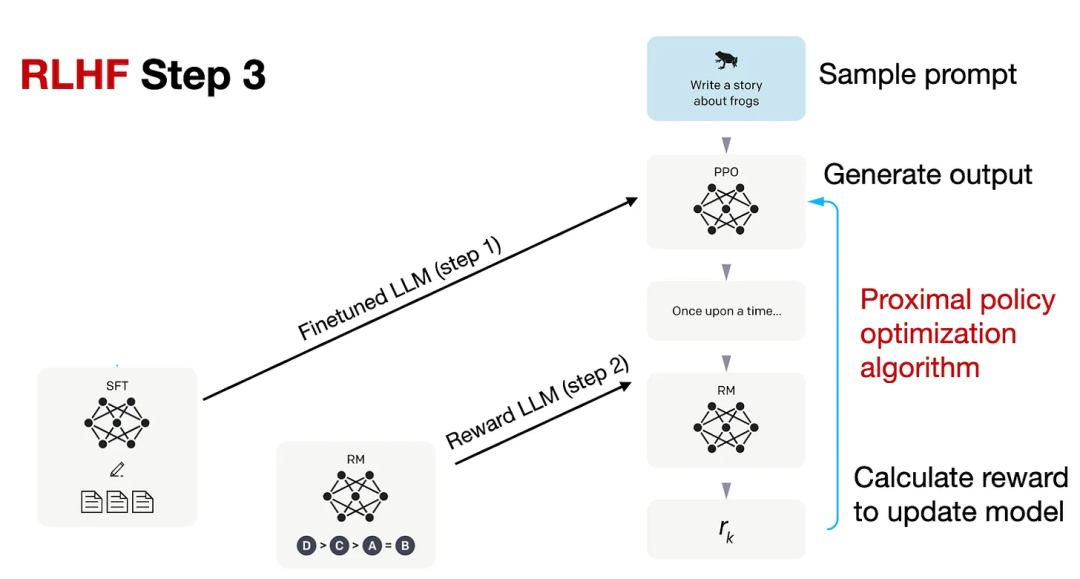
RLHF 第 3 步,图片来自 InstructGPT 论文
在 RLHF 第 3 步,这也是最后一步,需要根据 RLHF 第 2 步创建的 RM 的奖励分数,使用近端策略优化(PPO)来更新 SFT 模型。
有关 PPO 的更多细节超出了本文的范围,但感兴趣的读者可以在 InstructGPT 论文之前的这四篇论文中找到相关数学细节:
(1) 《Asynchronous Methods for Deep Reinforcement Learning》引入了策略梯度方法来替代基于深度学习的强化学习中的 Q 学习。
(2) 《Proximal Policy Optimization Algorithms》提出了一种基于修改版近端策略的强化学习流程,其数据效率和可扩展性均优于上面的基础版策略优化算法。
(3) 《Fine-Tuning Language Models from Human Preferences》阐释了 PPO 的概念以及对预训练语言模型的奖励学习,包括 KL 正则化,以防止策略偏离自然语言太远。
(4) 《Learning to Summarize from Human Feedback》引入了现在常用的 RLHF 三步流程,后来的 InstructGPT 论文也使用了该流程。
Llama 2 中的 RLHF
上一节介绍了 OpenAI 的 InstructGPT 论文中描述的 RLHF 流程。人们也普遍相信 ChatGPT 的开发中也使用了该流程。但它与 Meta AI 最新的 Llama 2 模型相比如何呢?
Meta AI 在创造 Llama-2-chat 模型时也使用了 RLHF。尽管如此,这两种方法之间还是有些差异,如下图所示。
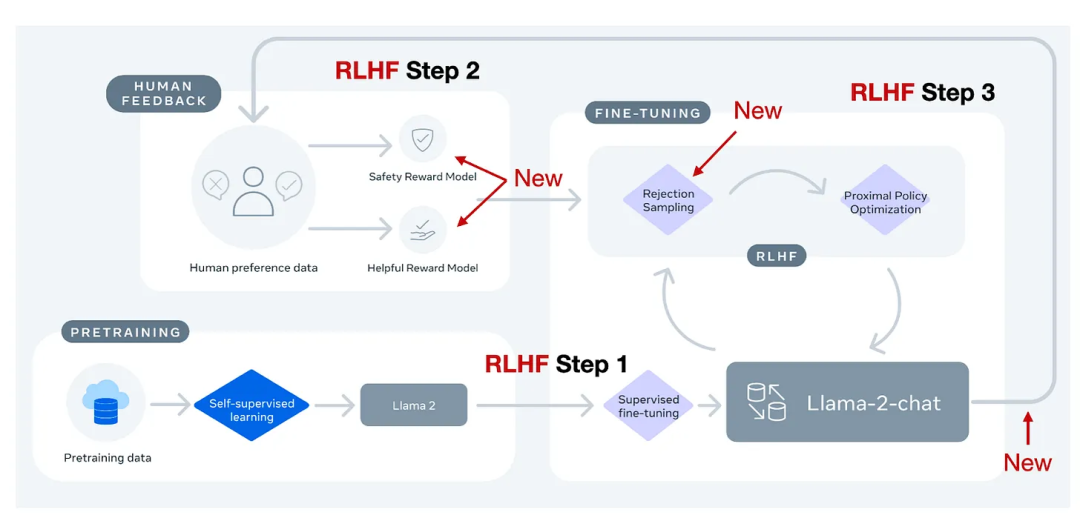
两种 RLHF 的差异,图片改编自 Llama-2 论文
总结起来,Llama-2-chat 遵循与 InstructGPT 的 RLHF 第 1 步相同的基于指令数据的监督式微调步骤。然而,在 RLHF 第 2 步,Llama-2-chat 是创建两个奖励模型,而不是一个。此外,Llama-2-chat 模型会经历多个演进阶段,奖励模型也会根据 Llama-2-chat 中涌现的错误而获得更新。它还有一个额外的拒绝采样步骤。
边际损失
还有另一个区别未在上图中给出,其涉及到生成奖励模型时对模型响应排序的方式。在之前讨论的 InstructGPT 所用的标准 RLHF PPO 中,研究者会根据自己创建的「k 选 2」比较方法来收集排名 4-9 的输出响应。
举个例子,如果一位人类标注者要对 4 个响应(A-D)进行排名,比如 A < C < D < B,这会有「4 选 2」=6 次比较。
A < C
A < D
A < B
C < D
C < B
D < B
类似地,Llama 2 的数据集基于对响应的二元比较,例如 A < B。然而,每位人类标记者在每轮标记时仅会比较 2 个响应(而不是 4-9 个响应)。
此外,Llama 2 方法的另一个不同之处是在每次二元排名时会收集一个「边际」标签(范围从「优势显著」到「优势可忽略」),这可以通过一个附加的边际参数被用于二元排名损失(可选)以计算两个响应之间的差距。
在训练奖励模型方面,InstructGPT 使用的是以下基于交叉熵的排名损失:
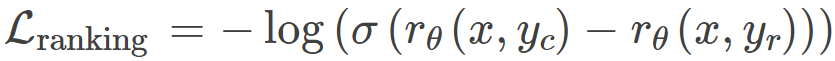
Llama 2 则添加了一个边际量 m (r) 作为偏好评级的离散函数,如下所示:
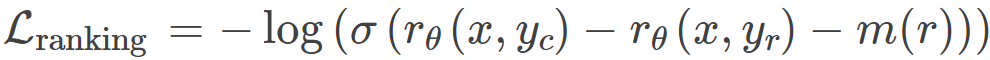
其中:
r_θ(x,y) 是对于 prompt x 和生成的响应 y 的标量分数输出;
θ 是模型权重;
σ 是 logistic sigmoid 函数,作用是把层输出转换为 0 到 1 之间的分数;
y_c 是人类标注者选择的偏好响应;
y_r 是人类标注者选择的被拒响应。
举个例子,通过 m (r) 返回一个更高的边际量会让偏好响应和被拒响应的奖励之差更小,这会让损失更大,又进一步导致梯度更大,最终导致模型在策略梯度更新过程中发生变化。
两个奖励模型
如前所述,Llama 2 中有两个奖励模型,而不是一个。一个奖励模型基于有用性,另一个则是基于安全性。而用于模型优化的最终奖励函数是这两个分数的一种线性组合。
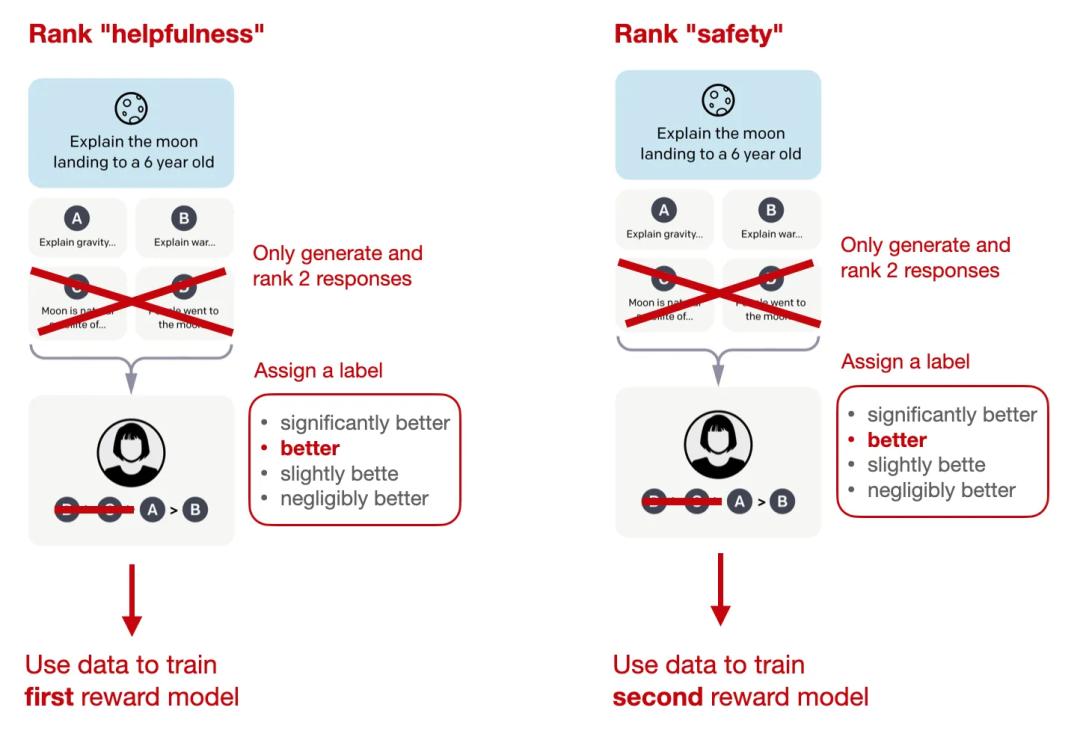
Llama 2 的排名方法和奖励模型创建,改编自 InstructGPT 论文的图片
拒绝采样
此外,Llama 2 的作者还采用了一种可以迭代式产生多个 RLHF 模型(从 RLHF-V1 到 RLHF-V5)的训练流程。他们没有仅仅依赖于之前讨论的使用 PPO 方法的 RLHF,而是使用了两种用于 RLHF 微调的算法:PPO 和拒绝采样(rejection sampling。
在拒绝采样中,会先抽取 K 个输出,然后在优化步骤选取其中奖励最高那个用于梯度更新,如下图所示。
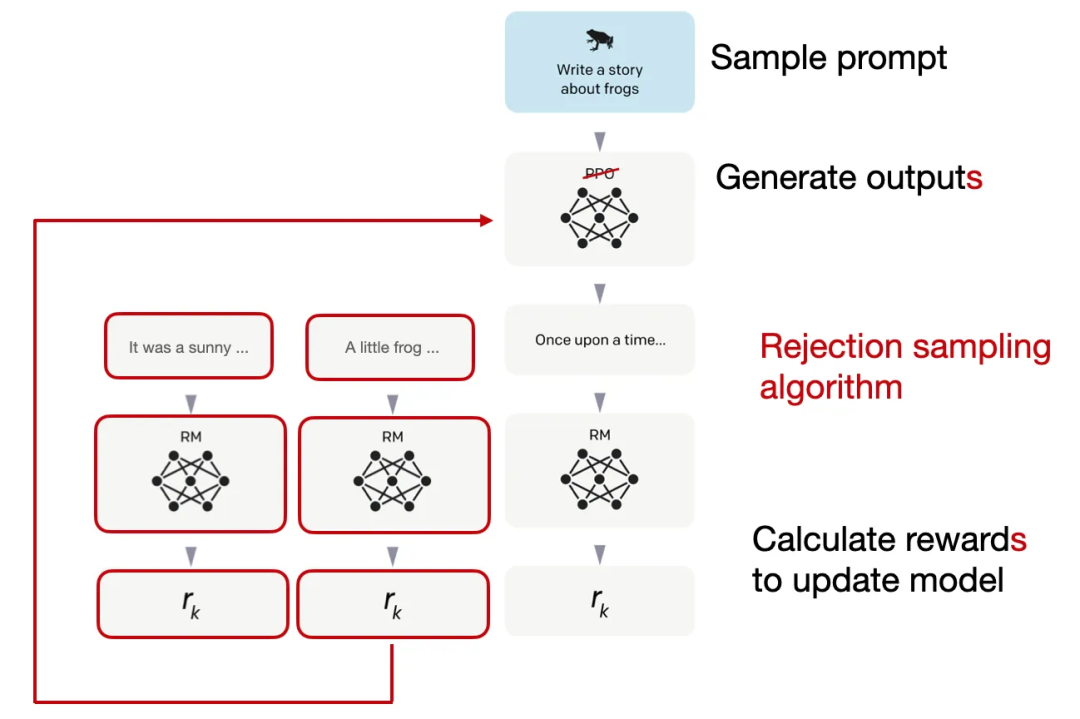
Llama 2 的拒绝采样步骤,即创建多个响应然后选取其中奖励最高的那个,改编自 InstructGPT 论文的图片
拒绝采样的作用是在每次迭代中选取奖励分数高的样本。由此造成的结果是,模型可以使用奖励更高的样本进行微调,相比之下,PPO 每次只能基于一个样本进行更新。
在经过监督式微调的最初阶段后,再专门使用拒绝采样训练模型,之后再将拒绝采样和 PPO 组合起来。
研究者绘出了随 RLHF 各阶段的模型性能变化情况,可以看到经过 RLHF 微调的模型在安全性和有用性方面都有提升。
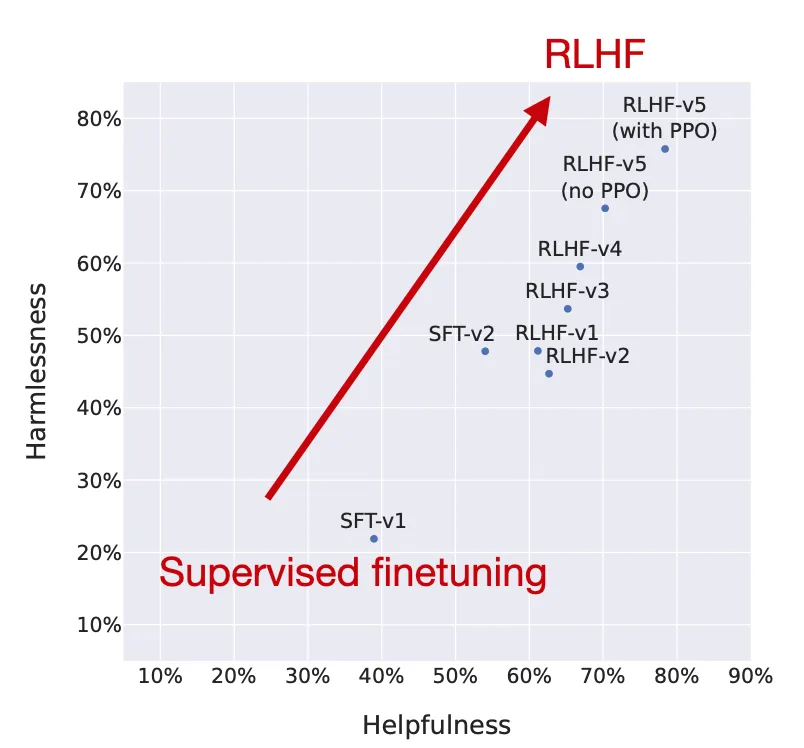
RLHF 确实有效,改编自 Llama 2 论文的图片
请注意,研究者在最后一步中使用了 PPO,之前则是用拒绝采样更新过的模型。对比图中 RLHF-v5 (with PPO) 和 RLHF-v5 (no PPO) 的位置可以看到,如果在拒绝采样之后的最后阶段使用 PPO,模型的表现会更好一些。
RLHF 的替代技术
现在我们已经讨论并定义了 RLHF 过程,这个过程相当复杂,人们可能会问这么麻烦是否值得。前文中来自 InstructGPT 和 Llama 2 论文的图表(下面再次给出)证明 RLHF 值得这样麻烦。
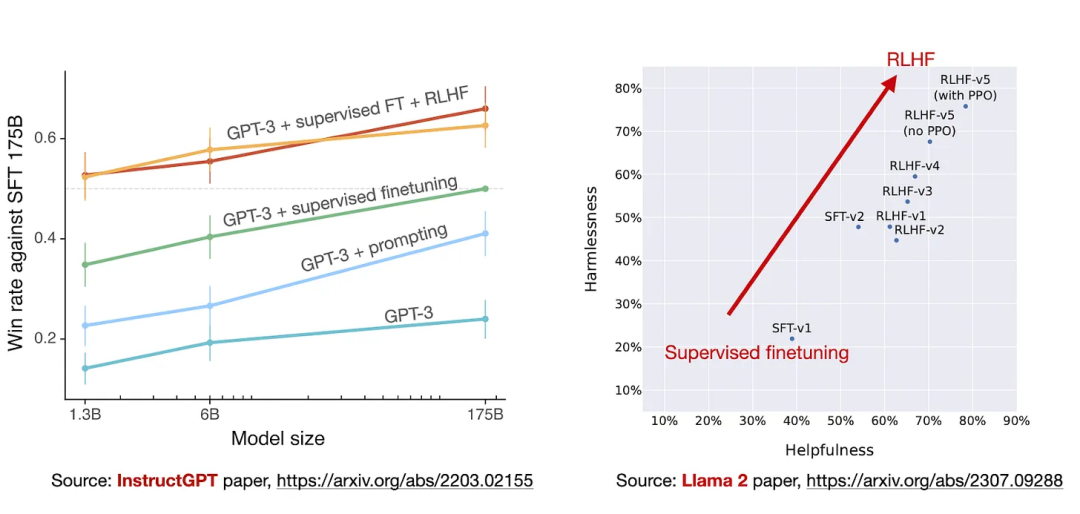
但是,有很多研究关注的重点是开发更高效的替代技术。其中最有趣的方法总结如下。
论文 1:《Constitutional AI: Harmlessness from AI Feedback》

论文地址:https://arxiv.org/abs/2212.08073
在这篇 Constitutional AI 论文中,作者提出了一种自训练机制,其基于人类提供的规则列表。类似于之前提到的 InstructGPT 论文,这里提出的方法也使用了一种强化学习。
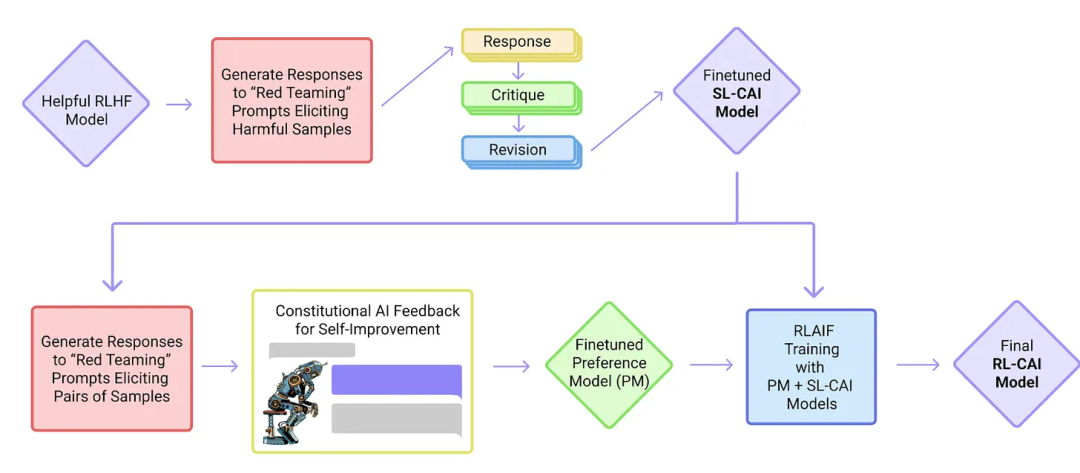
来自 Constitutional AI 论文
上图中的「red teaming(红队)」这一术语指的是一种源于冷战军事演习的测试方法,原本是指扮演苏联角色的演习队伍,用于测试美国的战略和防御能力。
在 AI 研究的网络安全语境中,红队现在描述的是这样一个过程:外部或内部的专家模仿潜在的对手,通过模仿真实世界攻击者的战术、技术和工作流程来挑战、测试并最终提升给定的相关系统。
论文 2:《The Wisdom of Hindsight Makes Language Models Better Instruction Followers》

论文地址:https://arxiv.org/abs/2302.05206
这篇论文用于 LLM 微调的监督式方法实际上可以发挥出很好的效果。这里,研究者提出了一种基于重新标注的监督式微调方法,其在 12 个 BigBench 任务上的表现优于 RLHF。
这种新提出的 HIR(Hindsight Instruction Labeling)是如何工作的?简单来说,HIR 方法包含两个步骤:采样和训练。在采样步骤,prompt 和指令被输入到 LLM 中以收集响应。然后基于对齐分数,在训练阶段适当的地方对指令进行重新标注。然后,使用经过重新标注的指令和原始 prompt 对 LLM 进行微调。使用这种重新标注方法,研究者可以有效地将失败案例(LLM 的输出与原始指令不匹配的情况)转变成对监督学习有用的训练数据。
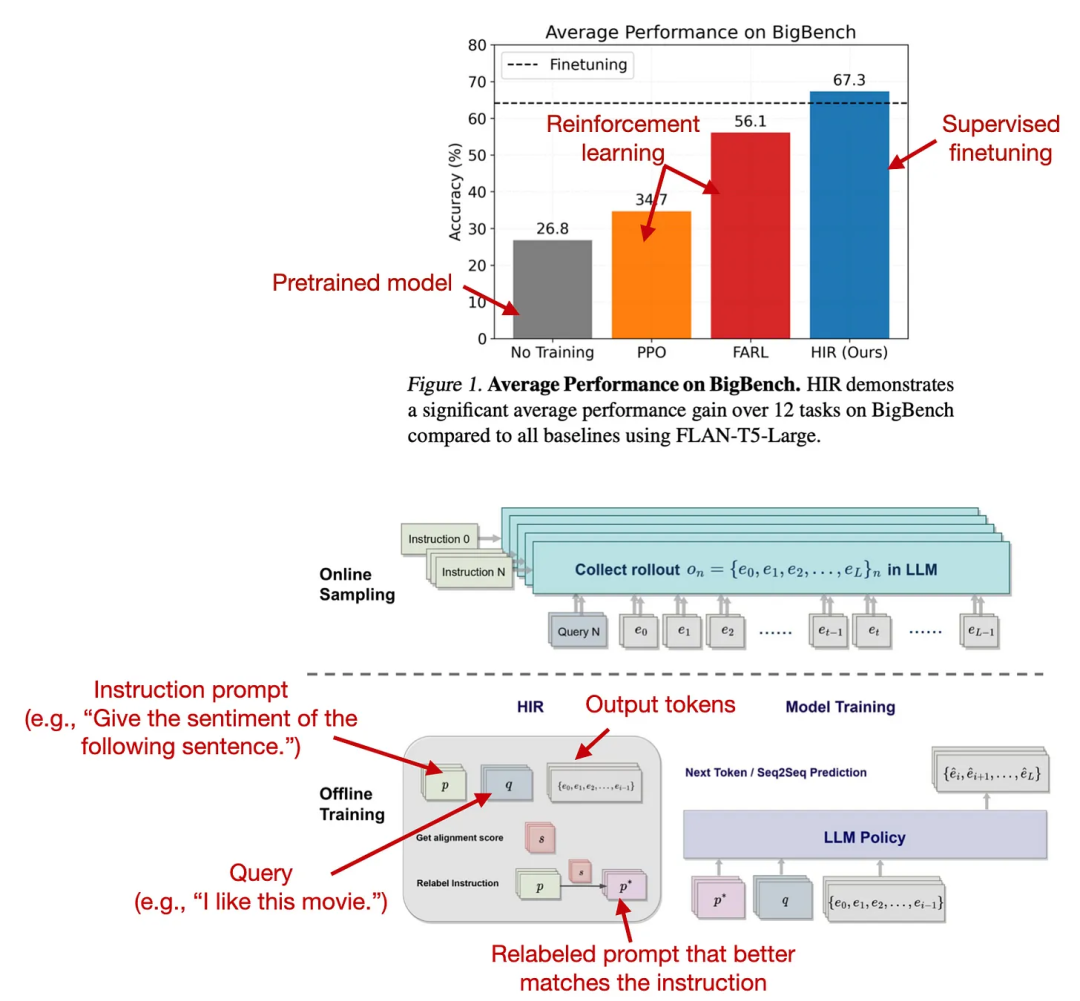
来自上述论文的方法及实验结果比较
注意这项研究不能直接与 InstructGPT 中的 RLHF 工作进行比较,因为它似乎使用启发式方法(「但是,由于大多数人类反馈数据都难以收集,所以我们采用了一个脚本化的反馈函数……」)不过 HIR 的事后高见方法的结果依然非常引人注目。
论文 3:《Direct Preference Optimization:Your Language Model is Secretly a Reward Model》

论文地址:https://arxiv.org/abs/2305.18290
直接偏好优化(DPO)是一种「使用 PPO 的 RLHF」的替代技术,作者在论文中表明在 RLHF 用于拟合奖励模型的交叉熵损失也可用于直接微调 LLM。根据他们的基准测试,使用 DPO 的效率更高,而且在响应质量方面也通常优于 RLHF/PPO。
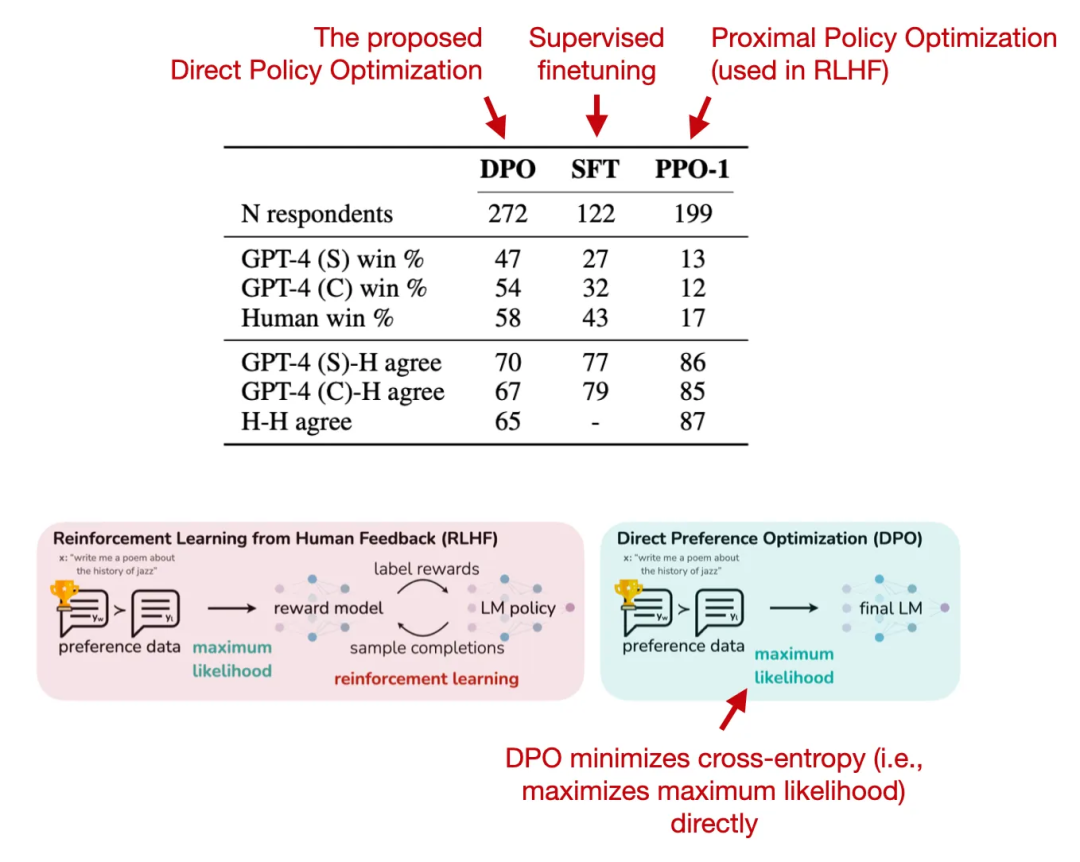
来自对应论文的 DPO 及其效果展示
论文 4:《Reinforced Self-Training (ReST) for Language Modeling》

论文地址:https://arxiv.org/abs/2308.08998
ReST 也是 RLHF 的一种替代方法,其能用于对齐 LLM 与人类偏好。ReST 使用一种采样方法来创建一个改进版数据集,然后在质量越来越高的子集上不断迭代训练,从而实现对奖励函数的微调。据作者描述,ReST 的效率高于标准的在线 RLHF 方法(比如使用 PPO 的 RLHF),因为其能以离线方式生成训练数据集,但他们并未全面地比较这种方法与 InstructGPT 和 Llama 2 等中使用的标准 RLHF PPO 方法。
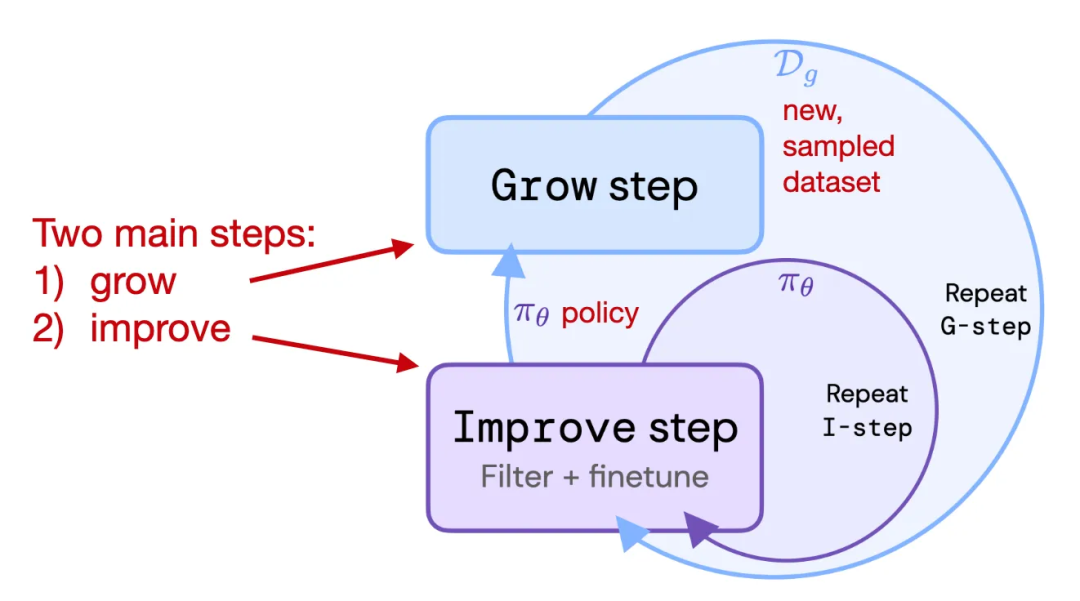
ReST 方法图示
论文 5:《RLAIF:Scaling Reinforcement Learning from Human Feedback with AI Feedback》

论文地址:https://arxiv.org/abs/2309.00267
近期的根据人工智能反馈的强化学习(RLAIF)研究表明,在 RLHF 中用于训练奖励模型的评分并不一定非要由人类提供,也可以使用 LLM(这里是 PaLM 2)生成。在人类评估者看来,用传统 RLHF 方法和 RLAIF 方法训练的模型得到的结果都差不多。
另一个有趣的发现是:RLHF 和 RLAIF 模型都显著优于单纯使用监督式指令微调训练的模型。
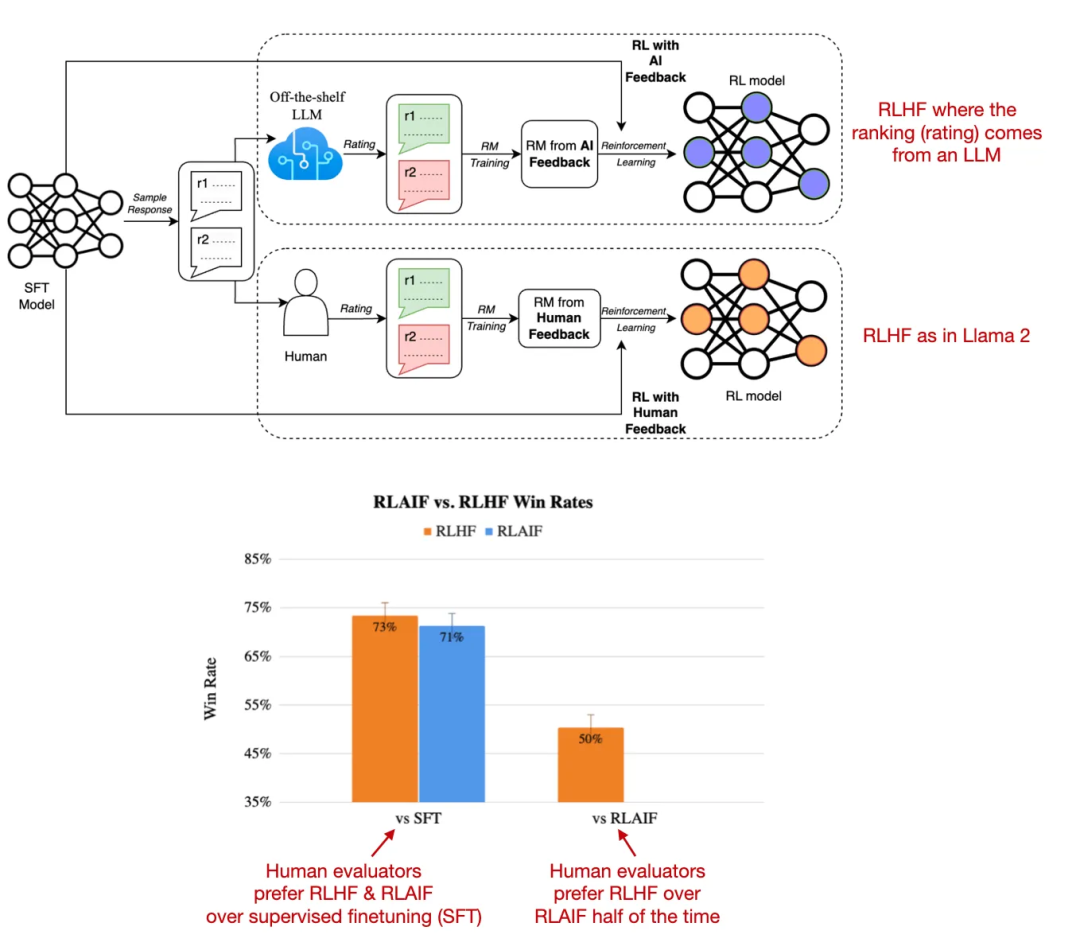
RLHF 和 RLAIF 方法以及它们的胜率比较
这项研究的结果非常有用而且很有意思,因为这基本上意味着我们可以让 RLHF 训练更加高效并且成本更低。但是,在有关信息内容的安全性和可信性(人类偏好研究只能部分地体现)的定性研究中,这些 RLAIF 模型究竟表现如何还有待观察。
结语
这些替代技术是否值得投入应用实践?这个问题还有待解答,因为目前 Llama 2 和未使用 RLHF 训练的 Code Llama 系列模型都还没有真正的竞争者。
整理不易,点赞三连↓

