
- 1Linux 进程间通信(IPC)详解:匿名管道、命名管道与共享内存
- 2【docker系列】Codimd在线Markdown方案_docker codimd
- 3打造智能汽车微服务系统平台:架构的设计与实现
- 4ubuntu20安装xrdp以及解决黑屏问题_ubuntu xrdp 黑屏
- 5【obs-studio开源项目从入门到放弃】obs_graphics_thread 视频采集渲染线程理解_electron libobs
- 6Cpython源码分析01_使用Visual Studio2017来研究Cpython,debug和release两种模式下编译的Python中__sizeof__()不一样的地方
- 7用 React 实现搜索 GitHub 用户功能
- 8Java 18 新特性:简单Web服务器 jwebserver
- 9【时间序列分析】13.ARMA(p,q)模型
- 10论文阅读:2015ResNet深度残差网络(待补充)
【Paddel学习笔记】 计算机视觉基础_paddlepaddle机器视觉
赞
踩
1.1 计算机视觉
1.1.1 计算机视觉概述
计算机视觉(Computer Vision)又称机器视觉(Machine Vision),是一门让机器学会如何去“看”的学科,是深度学习技术的一个重要应用领域,被广泛应用到安防、工业质检和自动驾驶等场景。具体的说,就是让机器去识别摄像机拍摄的图片或视频中的物体,检测出物体所在的位置,并对目标物体进行跟踪,从而理解并描述出图片或视频里的场景和故事,以此来模拟人脑视觉系统。因此,计算机视觉也通常被叫做机器视觉,其目的是建立能够从图像或者视频中“感知”信息的人工系统。
计算机视觉的主要目标是,先理解视频和静止图像的内容,然后从中收集有用的信息,以便解决越来越多的问题。作为人工智能 (AI) 和深度学习的子领域,计算机视觉可训练卷积神经网络 (CNN),以便针对各种应用场合开发仿人类视觉功能。计算机视觉包括对 CNN 进行特定训练,以便利用图像和视频进行数据分割、分类和检测。
1.1.2 计算机视觉应用场景
计算机视觉应用场景非常广泛,包括但不限于以下几个方面:
- 自动驾驶:自动驾驶汽车需要使用计算机视觉技术来感知周围环境,包括识别道路标志、车辆、行人、障碍物等,以便做出正确的决策。
- 安防监控:计算机视觉技术可以用于视频监控系统,包括人脸识别、车牌识别、行为识别等,从而提高安防监控系统的效率和准确性。
- 医疗影像:计算机视觉可以用于医疗影像分析,包括诊断和治疗。例如,计算机视觉可以帮助医生识别肿瘤、病变、骨折等。
- 智能家居:计算机视觉可以用于智能家居系统,例如通过摄像头检测人的位置和活动,从而控制灯光、温度、安防等。
- 虚拟现实:计算机视觉可以用于虚拟现实系统,例如通过跟踪头部和手部的运动来控制虚拟现实环境中的角色或物体。
1.1.3 计算机视觉任务的挑战
对人类来说,识别猫和狗是件非常容易的事。但对计算机来说,即使是一个精通编程的高手,也很难轻松写出具有通用性的程序(比如:假设程序认为体型大的是狗,体型小的是猫,但由于拍摄角度不同,可能一张图片上猫占据的像素比狗还多)。计算机视觉任务在许多方面都具有挑战性,物体外观和所处环境往往变化很大,目标被遮挡、目标尺寸变化、目标变形、背景嘈杂、环境光照变化,如 图5 所示
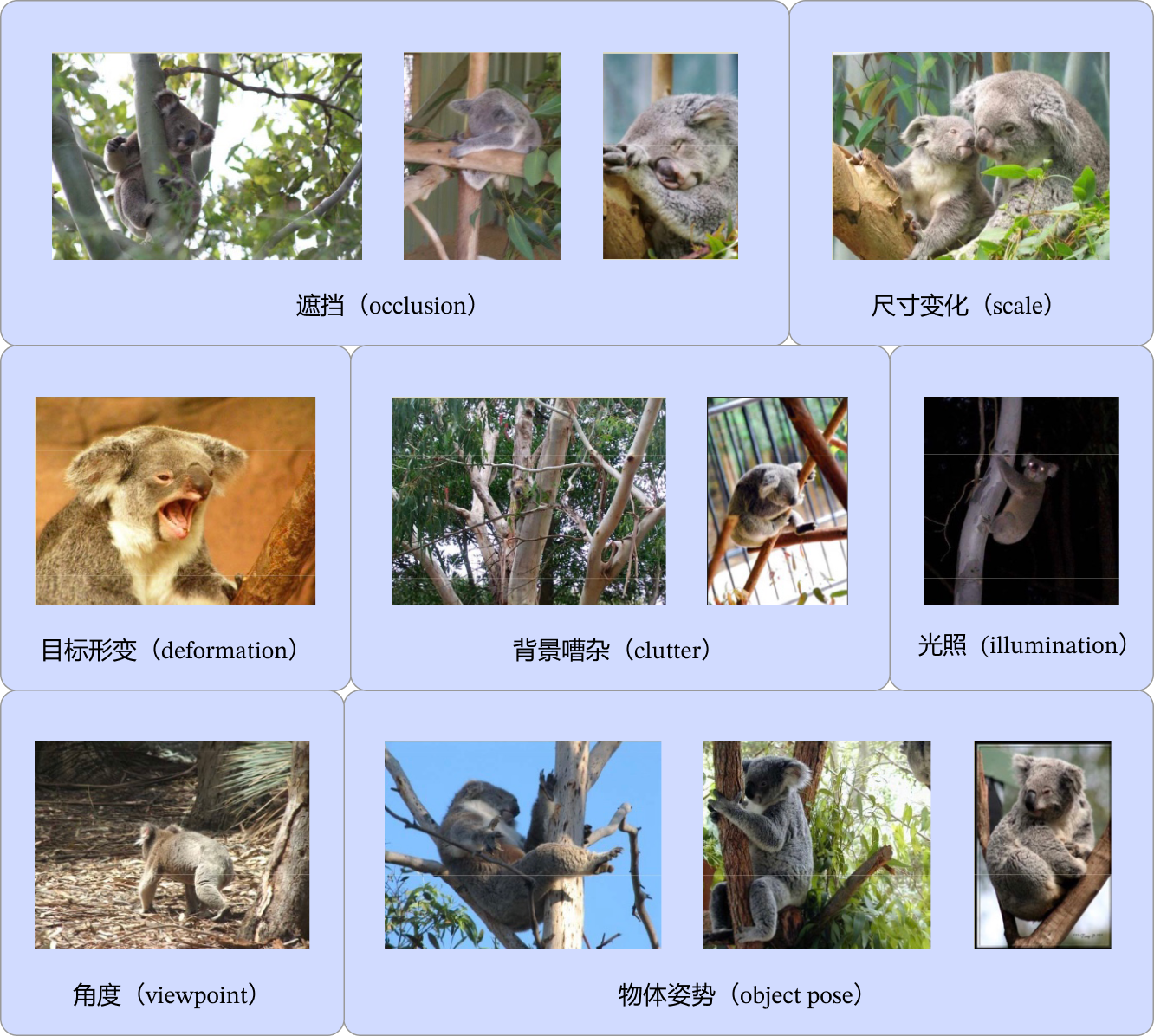
图3:计算机视觉技术在各领域的应用
除此之外,计算机视觉任务还面临数据量有限、数据类别不均衡、速度实时需求等挑战。
图片来源:KristenGrauman, BastianLeibe, Visual Object Recognition
1.3 常见的计算机视觉任务快速实践
下面开始通过PaddleHub工具进行计算机视觉任务的实战。
首先安装PaddleHub:
!pip install paddlehub --upgrade -i https://mirror.baidu.com/pypi/simple
- 1
通过以下指令导入依赖包。
import paddlehub as hub
import cv2
from PIL import Image
import matplotlib.pyplot as plt
%matplotlib inline
- 1
- 2
- 3
- 4
- 5
1.3.1 图像分类
图像分类利用计算机对图像进行定量分析,把图像或图像中的像元或区域划分为若干个类别中的某一种,如 图6 所示:

图6:图像分类示意图
图像分类是计算机视觉中重要的基本问题,也是图像检测、图像分割、物体跟踪、行为分析等其他高层视觉任务的基础,在很多领域有广泛应用,包括安防领域的人脸识别和智能视频分析等,交通领域的交通场景识别,互联网领域基于内容的图像检索和相册自动归类,医学领域的图像识别等。
我们通过第一章讲解的PaddleHub快速实现图像分类,使用resnet50_vd_dishes模型识别如下美食图片,更多模型及实现请参考PaddleHub模型库
先使用课程提供的白灼虾图片进行分类测试:

图7:待分类图片
classifier = hub.Module(name="resnet50_vd_dishes")
result = classifier.classification(images=[cv2.imread('imgs/test1.jpg')])
print('result:{}'.format(result))
- 1
- 2
- 3
[2022-06-28 17:21:55,454] [ WARNING] - The _initialize method in HubModule will soon be deprecated, you can use the __init__() to handle the initialization of the object
result:[{'白灼虾': 0.4448080360889435}]
- 1
- 2
- 3
- 4
可以看到成功识别出来了,再从网络上找到鸳鸯火锅的图片进行识别:

鸳鸯火锅
result = classifier.classification(images=[cv2.imread('imgs/yyhg.jpg')])
print('result:{}'.format(result))
- 1
- 2

可以看到鸳鸯火锅也成功进行了识别。
上面介绍了ResNet模型实现了美食分类,除此之外,图像分类还包含丰富的模型,主要分为CNN骨干网络模型和Transformer骨干网络模型,每一类又分为部署到服务器端的高精度模型和部署到手机等移动端平台的轻量级系列模型,具有更快的预测速度,如 图8 所示:

图8:图像分类算法
1.3.2 目标检测
对计算机而言,能够“看到”的是图像被编码之后的数字,但它很难理解高层语义概念,比如图像或者视频帧中出现的目标是人还是物体,更无法定位目标出现在图像中哪个区域。目标检测的主要目的是让计算机可以自动识别图片或者视频帧中所有目标的类别,并在该目标周围绘制边界框,标示出每个目标的位置。目标检测应用场景覆盖广泛,如安全帽检测、火灾烟雾检测、人员摔倒检测、电瓶车进电梯检测等等。

图9:目标检测示意图
我们使用PaddleHub检测模型yolov3_darknet53_vehicles进行车辆检测。
vehicles_detector = hub.Module(name="yolov3_darknet53_vehicles")
result = vehicles_detector.object_detection(images=[cv2.imread('imgs/test2.jpg')], visualization=True)
# 结果保存在'yolov3_vehicles_detect_output/'目录,可以观察可视化结果
img = Image.open(result[0]['save_path'])
plt.figure(figsize=(15,8))
plt.imshow(img)
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8

上面使用单阶段目标检测模型YOLOv3实现了车辆检测,目前目标检测主要分为Anchor based(两阶段和单阶段)、Anchor free模型、Transformer系列如 图10 所示:

图10:目标检测算法
其中Anchor是预先设定好比例的一组候选框集合,Anchor based方法就是使用Anchor提取候选目标框,在特征图上的每一个点对Anchor进行分类和回归。两阶段模型表示模型分为两个阶段,第一个阶段使用anchor回归候选目标框,第二阶段使用候选目标框进一步回归和分类,输出最终目标框和对应的类别。单阶段模型无候选框提取过程,直接在输出层回归bbox的位置和类别,速度比两阶段模型块,但是可能造成精度损失。由于需要手工设计Anchor,并且Anchor匹配对不同尺寸大小的物体不友好,因此发展出Anchor free模型,不再使用预先设定的anchor,通常通过预测目标的中心或者角点,对目标进行检测。
1.3.3 图像分割
图像分割指的是将数字图像细分为多个图像子区域的过程,即对图像中的每个像素加标签,这一过程使得具有相同标签的像素具有某种共同视觉特性。图像分割的目的是简化或改变图像的表示形式,使得图像更容易理解和分析。图像分割通常用于定位图像中的物体和边界(线,曲线等)。图像分割的领域非常多,人像分割、车道线分割、无人车、地块检测、表计识别等等。

图11:图像分割示意图
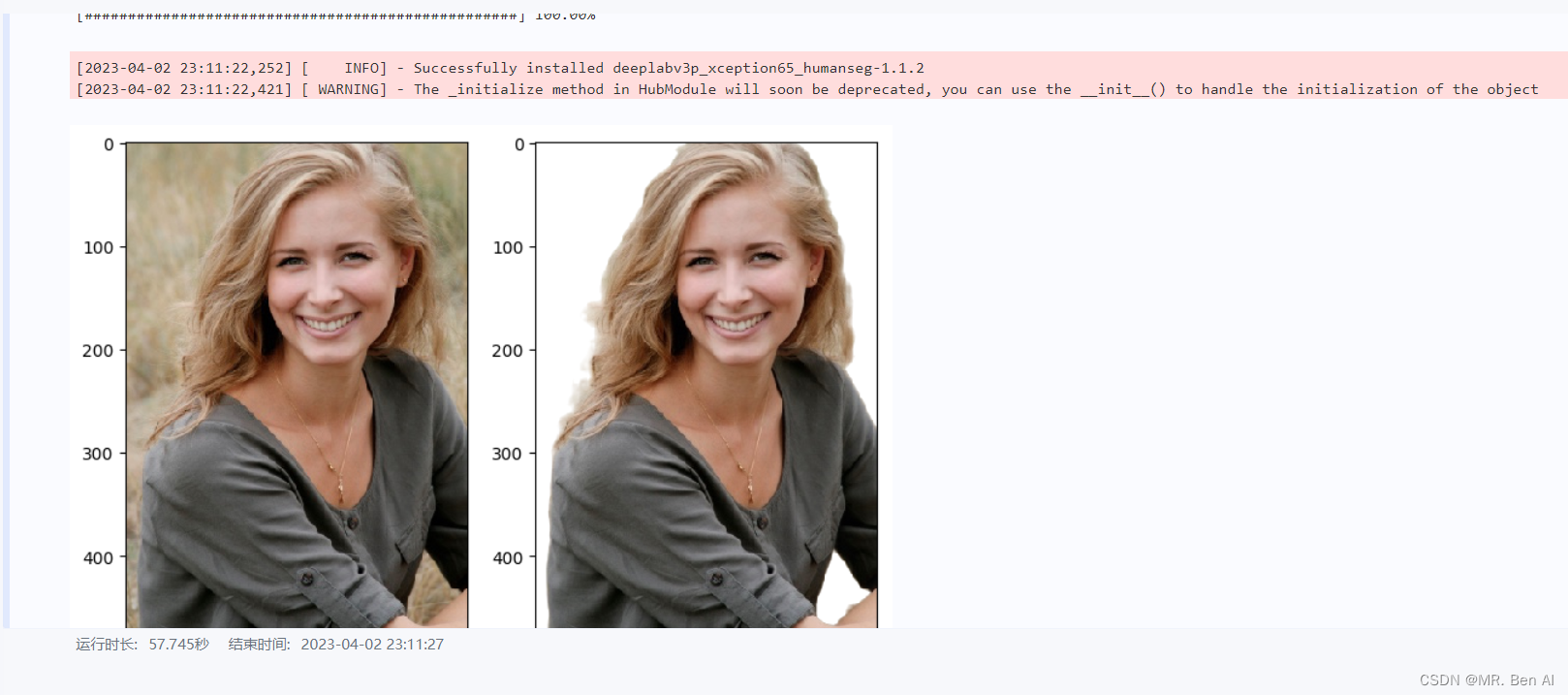
我们通过PaddleHub快速实现图像分割,使用deeplabv3p_xception65_humanseg预训练模型进行人像分割。
human_seg = hub.Module(name="deeplabv3p_xception65_humanseg")
result = human_seg.segmentation(images=[cv2.imread('./imgs/test3.jpg')], visualization=True)
# 结果保存在'humanseg_output/'目录,可以观察可视化结果
img_ori = Image.open('./imgs/test3.jpg')
img = Image.open(result[0]['save_path'])
fig = plt.figure(figsize=(8,8))
# 显示原图
ax = fig.add_subplot(1,2,1)
ax.imshow(img_ori)
# 显示人像分割图
ax = fig.add_subplot(1,2,2)
ax.imshow(img)
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
上面使用deeplabv3p识别实现了人像分割,除此之外,图像分割还包含如 图12 所示算法:

1.3.4 OCR
OCR(Optical Character Recognition,光学字符识别)是计算机视觉重要方向之一。传统定义的OCR一般面向扫描文档类对象,即文档场景文字识别(Document Analysis & Recognition,DAR),现在我们常说的OCR一般指场景文字识别(Scene Text Recognition,STR),主要面向自然场景。OCR技术有着丰富的应用场景,如卡证票据信息抽取录入审核、工厂自动化、政府工作医院等文档电子化、在线教育等。
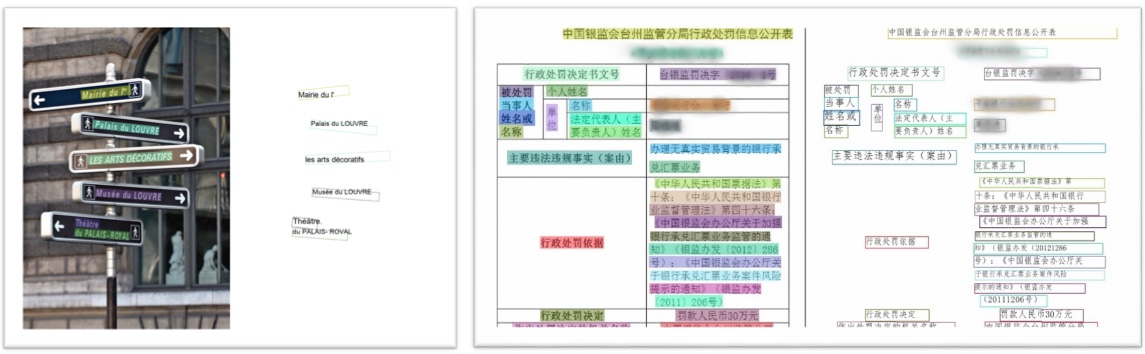
图13:文字识别示意图
我们通过PaddleHub快速实现OCR任务,使用chinese_ocr_db_crnn_mobile模型进行文字识别。
ocr = hub.Module(name="chinese_ocr_db_crnn_mobile")
result = ocr.recognize_text(images=[cv2.imread('./imgs/test4.jpg')], visualization=True)
# 结果保存在'ocr_result/'目录,可以观察可视化结果
img = Image.open(result[0]['save_path'])
plt.figure(figsize=(20,20))
plt.imshow(img)
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8

再从网上找个最近新上线的P60 PRO的产品图进行验证:
result = ocr.recognize_text(images=[cv2.imread('./imgs/P60.jpg')], visualization=True)
# 结果保存在'ocr_result/'目录,可以观察可视化结果
img = Image.open(result[0]['save_path'])
plt.figure(figsize=(20,20))
plt.imshow(img)
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7

可以看到基本文字信息都获取到了。
上面使用DBNet检测模型和CRNN识别实现了文字识别,可以看到上述OCR实现过程分为检测和识别2个模型,我们称之为两阶段算法,除此之外还有端到端算法,使用一个模型同时完成文字检测和文字识别。文档分析能够帮助开发者更好地完成文档理解相关任务,通常OCR算法和文档分析算法结合使用。

图14:OCR算法
其中,版面分析识别文档中的图像、文本、标题和表格等区域,然后对文本、标题等区域进行OCR的检测识别,如 图15(a) 所示。表格识别对文档中表格区域进行结构化分析,最终结果输出Excel文件,如 图15(b) 所示。关键信息提取算法,将每个检测到的文本区域分类为预定义的类别,如订单ID、发票号码,金额等,如 图15© 所示。文档视觉问答DocVQA包括语义实体识别SER 和关系抽取RE任务。基于SER任务,可以完成对图像中的文本识别与分类;基于RE任务,可以完成对图象中的文本内容的关系提取,如判断问题对(pair),如 图15(d) 所示。PP-Structure包含了版面分析、表格识别、视觉问答等功能,支持模型训练、测试等,如 图15(e) 所示。

图15:文档分析算法
学习感悟
PaddleHub所实现的模型已经满足了简单的场景需求,在一些简单的场景下已经实现了开箱即用,大大降低的计算机视觉应用的成本。但是在一些更复杂的场景中还是需要更有针对性的进行优化和改进,除了简单的应用,我们还是得对机器视觉的原来和实现有更深入的了解。

