
- 1Cloudflare开源了替代NGINX的Pingora_pingora 4000w
- 2javafx-listview 多选复制到剪切板_javafx tableview 多选
- 3iframe嵌入的页面引用jQuery1.10.1,IE9打开时提示拒绝访问_iframe拒绝访问跟浏览器版本有关系吗
- 4如何使用docker pull命令从腾讯云镜像加速源拉取镜像,以提高下载速度?
- 5深度学习之残差网络的原理_深度残差模块的工作原理
- 6关于外网访问本地服务器 (家庭版)_家里部署的服务 能不能访问通过网络访问
- 7评分高的前端书籍推荐(上)—好书知时节_前瞻类书籍
- 8大数据关键技术之数据采集电商数据采集电商API接口接入发展趋势
- 9经典蓝牙连接过程_蓝牙配对流程
- 103秒实现无痛基于Stable Diffusion WebUI安装ComfyUI!无需重复安装环境!无需重复下载模型!安装教程_stable diffusion 绘世安装comfyui
人脸高清算法GFPGAN之TensorRT推理
赞
踩
1. 综述
最近由于做数字人项目,采用的是wav2lip + GFPGAN进行人脸面部高清,但GFPGAN模型本身比较大,所以想着使用TensorRT来代替原始的pth推理看看能否提升运行速度,于是便开始了这趟windows10之下进行GFPGAN的trt推理的折腾之旅。
2. 环境
我会提供一个我写好GFPGAN的trt推理的完整工程包。我的环境是windows10 + cuda11.7 + cudnn 8.9.2 + TensorRT-8.5.1.7 + pycuda_cuda115 + python3.8的虚拟环境。
2.1 TensorRT的环境安装
TensorRT的环境安装参考英伟达官方TensorRT8.x下载地址
2.1.1 pip安装TensorRT文件夹中的.whl文件
进入python文件夹
- conda activate py38_torch # 激活你的python3.8虚拟环境
- pip install tensorrt-8.5.1.7-cp38-none-win_amd64.whl
进入graphsurgeon文件夹
pip install graphsurgeon-0.4.6-py2.py3-none-any进入onnx_graphsurgeon文件夹
pip install onnx_graphsurgeon-0.3.12-py2.py3-none-any.whl -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com进入uff文件夹
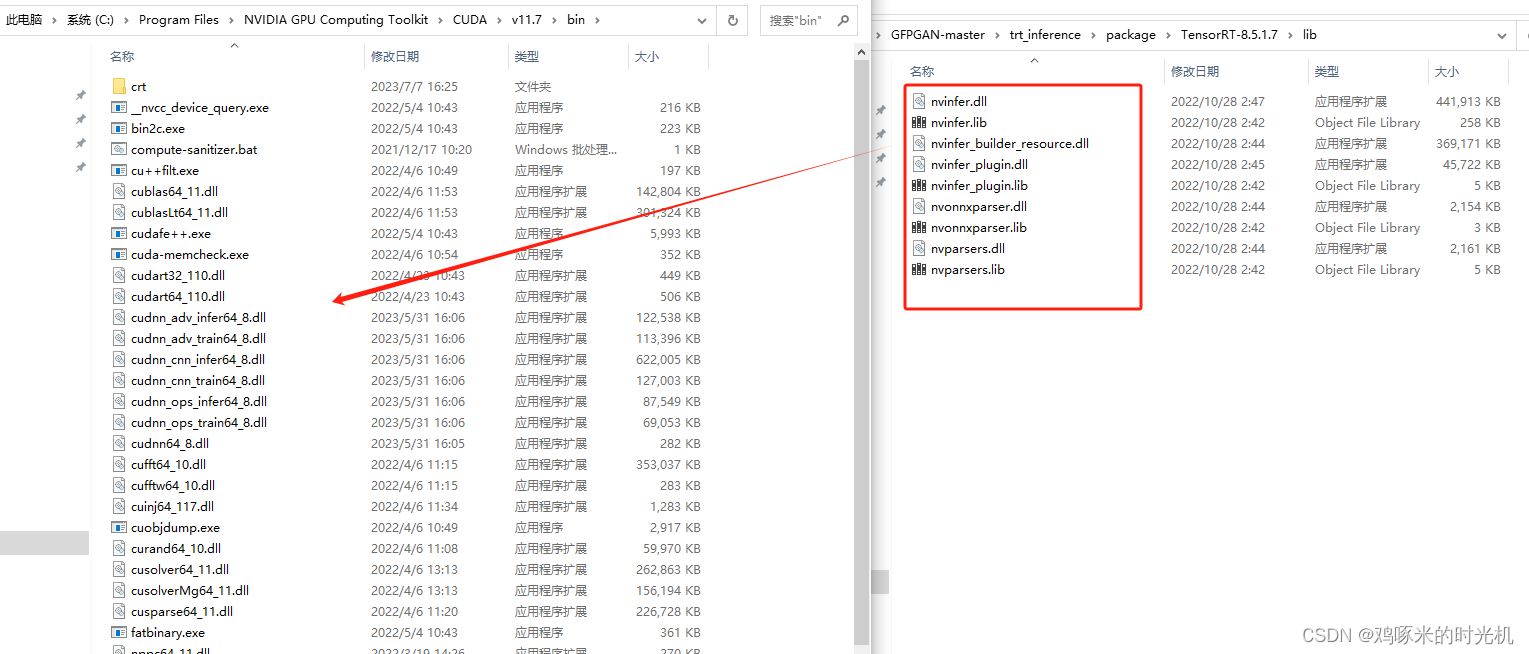
pip install uff-0.6.9-py2.py3-none-any.whl还有很重要的一步就是将TensorRT的lib所有文件复制到cuda的bin下面,如下图所示
验证
- import tensorrt as trt
- print(trt.__version__)
2.2 pycuda安装
进入trt_inference/package下面
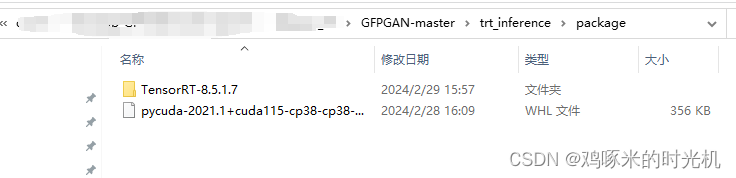
pip install pycuda-2021.1+cuda115-cp38-cp38-win_amd64.whl3. 模型转换
3.1 pth2onnx(将GFPGAN的v1.4的pth模型转换为trt)
进入trt_inference/model_transformer/onnx下面
- python gfpgan2onnx.py --src_model_path GFPGANv1.4.pth --dst_model_path gfpganv1.4.onnx --img_size 512
- pip install onnx-simplifier
- python -m onnxsim gfpganv1.4.onnx gfpganv1.4_sim.onnx
所以就得到了trt_inference/model_transformer/onnx/gfpganv1.4_sim.onnx
3.2 onnx2trt(将GFPGAN的onnx转化为TensorRT的trt)
进入trt_inference/model_transformer/trt下面
python gfpgan2onnx2trt.py --src_model_path ../onnx/gfpganv1.4_sim.onnx --dst_model_path gfpganv1.4.trt所以就得到了trt_inference/model_transformer/trt/gfpganv1.4.trt模型
4 pth和trt模型推理结果比较
进入工程文件GFPGAN-master下面
4.1 使用pytorch的pth模型去跑视频生成
修改gfpgan/utils.py下面的如图两行
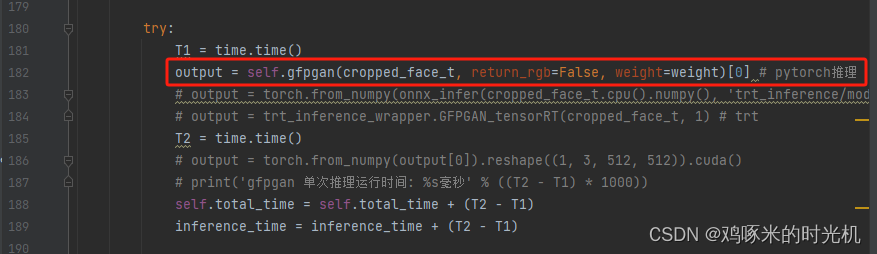
然后直接在GFPGAN-master下面运行 python run.py --face_path inputs/wav2lip.mp4 --audio_path inputs/vyrxlgmx.mp3 --final_path result.mp4 --outputs_path output,则会在output下面生成result.mp4, 生成时间为: 848.8s, 总的推理时间为: 5.8s
4.2 使用TensorRT的trt模型去跑视频生成
修改gfpgan/utils.py下面的如图所示
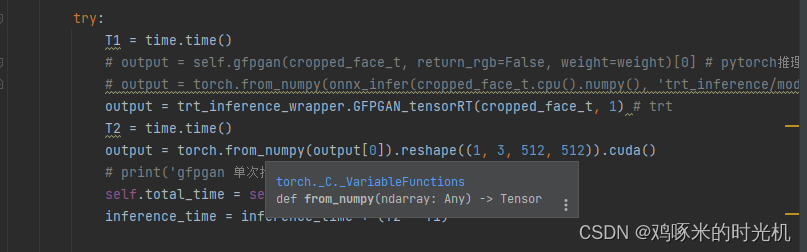
然后直接在GFPGAN-master下面运行 python run.py --face_path inputs/wav2lip.mp4 --audio_path inputs/vyrxlgmx.mp3 --final_path result.mp4 --outputs_path output,则会在output下面生成result.mp4, 生成时间为: 909.6s, 总的推理时间为: 11.8s
完整的工程代码,请看百度网盘链接: 百度网盘,提取码: gfpg

