
- 1基于yolov5的电瓶车和自行车检测系统,可进行图像目标检测,也可进行视屏和摄像检测(pytorch框架)【python源码+UI界面+功能源码详解】_yolov5 电动车识别
- 2基于Python的旅游景点推荐系统_python旅游景点推荐系统
- 3【Andriod】Appium的不同版本(Appium GUI、Appium Desktop、Appium Server )的安装教程
- 4OpenStack(1)--创建实例_openstack创建实例
- 5机器学习之支持向量机(SVM)原理详解、公式推导(手推)、面试问题、简单实例(sklearn调包)_svm原理
- 6【视频】海康威视摄像头RTSP协议格式_rtsp协议的摄像头
- 7nginx执行文件替换掉之后重启提示permission denied
- 8【数据结构】栈和队列(概念选择题)
- 9c++字符串匹配之kmp_c++字符串 匹配 kmp
- 10express mysql 做rbac_spring boot:spring security用mysql数据库实现RBAC权限管理(spring boot 2.3.1)...
揭秘|一探腾讯基于Kubeflow建立的多租户训练平台背后的技术架构_kube-studio sam
赞
踩
腾讯业务及组织架构现状
先简单和大家介绍一下腾讯内部的业务及相关组织架构的现状,有助于帮助大家理解为什么我们会基于后面的架构来设计整套方案。
下图的应用大多数人经常会用到,比如微信、腾讯视频、游戏等等APP,其背后承载的技术也不尽相同,涉及了NLP、计算机视觉、强化学习、语音等不同的AI技术。
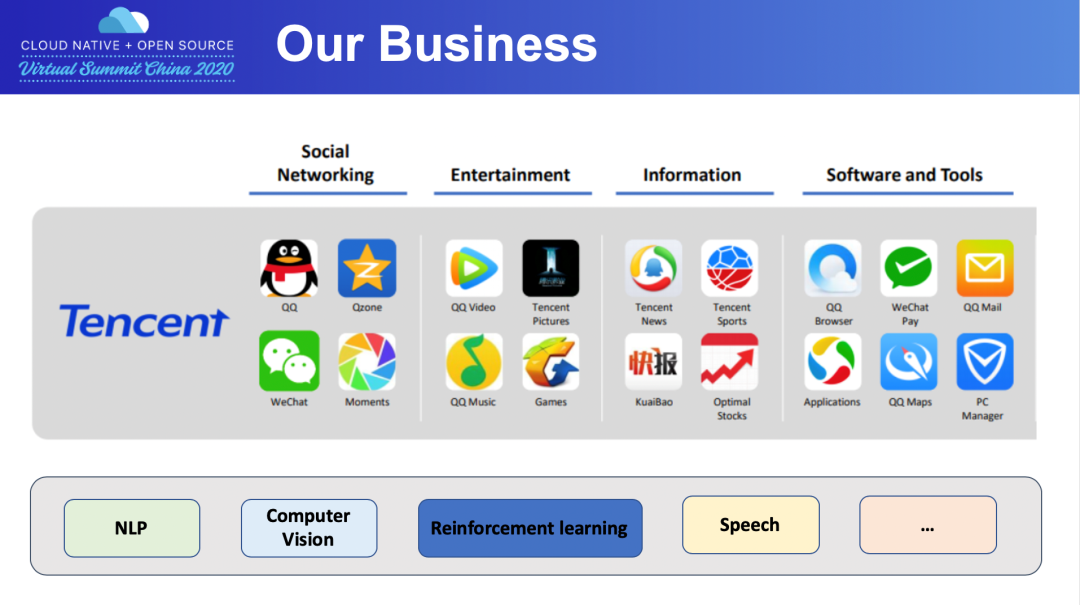
比如我们玩的《王者荣耀》或者下围棋,背后所对应的就是用强化学习训练出来的一个机器人,玩游戏没有队友陪同时,机器人可以满足我们对战合作等游戏需求。
不同的业务部门,APP对外需求也不同,均会针对自己的业务场景做一些AI平台的定制。我们做的是底层算力,给业务部门提供服务时,在考虑整体资源利用率的情况下,也要为各业务便捷地去做些定制服务,这就是腾讯内部的一个多租户的现状。
业务特点与规模
接下来,介绍一下腾讯内部业务的一些特点以及大概规模。
目前的环境是基于开源项目TKEStack,TKEStack是腾讯公有云TKE的开源版本,是一个开源的容器云平台解决方案,用的KubernetesV1.14版本,操作系统是腾讯自研的Linux操作系统,已经为GPU或者腾讯内部业务做了一层性能的调优和bugfix。
GPU节点是NVIDIA的V100、P100,个别会有一些M40的机器。网络联通使用100G的RoCE,既能够提供以太网的支持,又能够提供RDMA的网络协议支持,对于用户去做一些多机通信的优化有事半功倍的效果,也从硬件层面保证了整体的使用效率。
完整流程设计思路
接下来介绍一下我们是怎么完善、开发以及设计这一整套流程的。
Kubeflow 是什么
这里先介绍一下关于Kubeflow以及Kubeflow里面一些主要的组件,帮助大家理解其中的一些具体业务,或者设计。

Kubeflow是什么呢?
Kubeflow自从2017年底发布,目前逐渐成为主流的在Kubernetes上面跑机器学习、深度学习等训练或者推理任务的主要工具。
Kubeflow包含非常多的组件,比较多的像Operator ,或者像自动调参的工具。
Operator
先介绍一下Operator,它是Kubernetes中的一种概念,主要是用来打包、部署以及管理用户的任务。但在Kubeflow里面,Operator主要用来管理机器学习或者深度学习里面的任务。
那么它能帮用户做什么呢?
比如在多机的任务下面,如何去管理和维护一个任务的多个节点,以及之前通信是怎么做的,怎么能够帮助用户管理整个Pod以及任务的生命周期,比如某一个Pod失败了,整个任务是终止还是有一些其他的容错办法,这个都是由Operator来完成。
目前主流的Operator有几种,会对应每一种框架。比如用的最多的TF-Operator,主要对应的是tensorflow,MPI-Operator主要对应Horovod,Pytorch和Caffe2的Operator,它们针对各自的框架都有一些定制的场景。
这里着

