
- 1Android用户界面设计
- 2魔百盒cm211-1_ZG-晶晨S905和CH-晶晨S905L3B线刷-刷机固件及教程
- 3IOS面试题object-c 61-70
- 4Eclipse 实用快捷键大全
- 5EventBus3.0报 Subscriber class ...... already registered to......_already registered to event class
- 6TextView实现一行居中显示,多行居左显示_android text不满一行居中,超过一行靠左
- 7新版软考高项试题分析精选(二)
- 8鸿蒙系统源码main函数,鸿蒙系统的启动流程,建议收藏!
- 9[IOS]使用genstrings和NSLocalizedString实现App文本的本地化_移动应用本地化
- 10springboot websocket 实时刷新 添加心跳机制(亲测可用版)_springboot websocket 心跳
目标检测算法(一)R-CNN精细分析和讲解可用于制作ppt并附源码地址和翻译版本_r—cnn目标检测ppt
赞
踩
目录
引言
在计算机视觉领域,目标检测一直是一个热门的研究方向,其中R-CNN是一个非常重要的算法。R-CNN是一种基于深度学习的目标检测算法,由Ross Girshick等人在2014年提出。本文将对R-CNN论文进行深入分析,并结合个人感受进行总结。
正文
一、R-CNN的背景与相关工作
在目标检测领域,传统的算法主要是基于手工设计的特征和机器学习模型。这些算法在一些简单的场景下表现良好,但是对于复杂的场景和多种类别的目标检测效果较差。近年来,深度学习的出现为目标检测领域带来了新的突破。
R-CNN是一种基于深度学习的目标检测算法,其主要思想是将目标检测任务分解为两个子任务:候选区域生成和目标分类。候选区域生成使用选择性搜索(Selective Search)算法,目标分类使用卷积神经网络(Convolutional Neural Network, CNN)。
在R-CNN之前,已经有一些基于深度学习的目标检测算法被提出,例如OverFeat、MultiBox等。这些算法虽然效果较好,但是速度较慢,无法在实际应用中使用。因此,Ross Girshick等人提出了R-CNN算法,该算法在速度和准确率之间取得了良好的平衡。
二、R-CNN的主要思想与流程
R-CNN的主要思想是将目标检测任务分解为两个子任务:候选区域生成和目标分类。首先,选择性搜索算法生成若干个候选区域,然后对每个候选区域进行卷积神经网络(CNN)分类,最后使用支持向量机(SVM)进行目标分类。
具体流程如下所示:
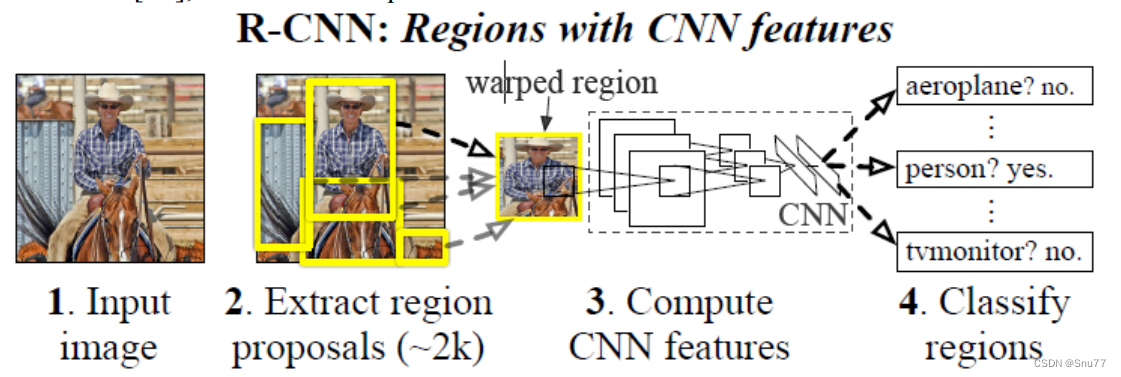
(1)输入一张图像、
(2)提取大约 2000个自下而上的 region proposals、
(3)使用大型卷积神经网络(CNN)计算每个region proposals 的特征向量、
(4)使用特定类别的线性 SVM 对每个 region 进行分类。
R-CNN的流程可以分为三个主要阶段:候选区域生成、特征提取和分类、边界框回归。
1.候选区域生成
在这个阶段,R-CNN使用选择性搜索来生成一组候选框。选择性搜索是一种快速的区域提取算法,它通过合并不同大小和形状的区域来生成候选框。选择性搜索根据相邻像素的相似性将图像分割成多个区域,并为每个区域提取一组特征。然后,这些特征被组合成候选框。
2.特征提取和分类
在这个阶段,R-CNN对每个候选框进行特征提取和分类。首先,每个候选框都被重新缩放到相同的大小,并传递给一个卷积神经网络,以提取与目标相关的特征。这些特征向量然后被输入到一组全连接层中,以进行目标分类。
3.边界框回归
在这个阶段,R-CNN使用线性回归器来进一步精调每个候选框的位置和大小。这是通过将卷积神经网络的输出作为输入,并在全连接层之前插入一个额外的回归层来实现的。这个回归层被训练来预测候选框的精确位置和大小,从而提高检测的准确性。
总体而言,R-CNN算法的主要思想是利用深度卷积神经网络对图像进行特征提取和分类,然后通过线性回归来进一步精调检测框的位置和大小。R-CNN算法在物体检测领域取得了很好的成果,并且是现代目标检测算法的基础。
三、R-CNN的训练过程
R-CNN的训练过程为"有监督训练"并且分为两个阶段:第一阶段是对CNN模型的预训练,第二阶段是对SVM分类器的训练。
在第一阶段中,采用预训练的AlexNet作为特征提取器,对训练集中的每个图像进行前向传播,提取出每个候选框所对应的特征向量。这些特征向量被用来训练SVM分类器,并且也用于后续的回归任务。由于AlexNet在ImageNet数据集上进行了大规模的预训练,因此它的特征提取能力比较强,可以提取出具有一定语义信息的特征向量。
在第二阶段中,首先对每个候选框进行判别,判断它是否包含一个物体。如果包含,则对该候选框进行回归,修正其坐标,使其更加准确地框住物体。这些判别和回归任务同样也是通过SVM分类器实现的。在训练SVM分类器时,需要使用一些负样本来进行负样本挖掘。具体而言,首先从每张训练图像中随机选取一些候选框,然后计算它们与真实边界框的重叠程度(IoU),若重叠程度小于0.3,则将其视为负样本。这样就能够使得训练数据更加均衡,提高分类器的性能。
需要注意的是,在训练过程中,每个物体只被用来训练一次,即使在同一张图像中,也只会选择最高得分的候选框进行训练。这样做是为了避免同一物体被重复训练,浪费计算资源。
综上所述,R-CNN的训练过程主要是将预训练的CNN模型作为特征提取器,提取候选框的特征向量,并使用SVM分类器进行判别和回归。
四、R-CNN的实验过程
在R-CNN的论文中,作者进行了一系列的实验来验证其方法的有效性。下面将对其中几个实验进行详细介绍。
1.PASCAL VOC 2010数据集实验
作者在PASCAL VOC 2010数据集上进行了实验,该数据集包含20个类别的物体,共计约5,000张训练图片和5,000张测试图片。作者利用该数据集中的训练图片训练模型,并在测试图片上进行测试。

表格展示了(本方法)在VOC2010的结果,我们将自己的方法同四种先进基准方法作对比,其中包括SegDPM,这种方法将DPM检测子与语义分割系统相结合并且使用附加的内核的环境和图片检测器打分。更加恰当的比较是同Uijling的UVA系统比较,因为我们的方法同样基于候选框算法。对于候选区域的分类,他们通过构建一个四层的金字塔,并且将之与SIFT模板结合,SIFT为扩展的OpponentSIFT和RGB-SIFT描述子,每一个向量被量化为4000词的codebook。分类任务由一个交叉核的支持向量机承担,对比这种方法的多特征方法,非线性内核的SVM方法,我们在mAP达到一个更大的提升,从35.1%提升至53.7%,而且速度更快。我们的方法在VOC2011/2012数据达到了相似的检测效果mAP53.3%。
实验结果表明,R-CNN在该数据集上的平均精度为53.7%,相较于之前的最优方法提高了30%以上。此外,作者还分析了各个类别的准确率,发现R-CNN在物体较小的类别上表现更好。
2.ILSVRC2013数据集实验
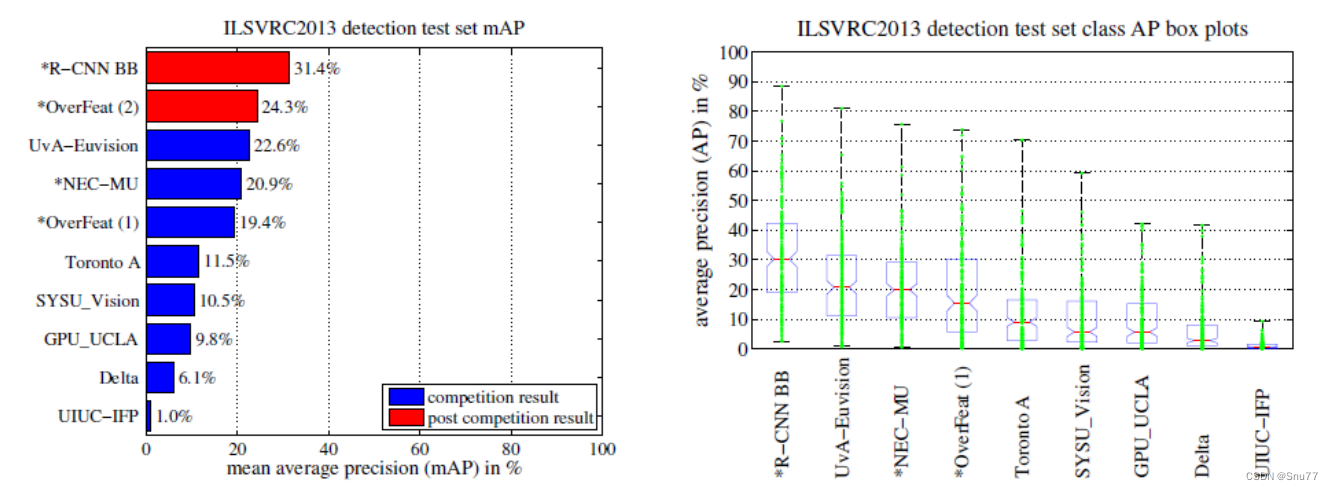 (左图)ILSVRC2013 检测测试集的 mAP。*开头的方法使用外部训练数据(所有方法都使用 ILSVRC 分类数据集中的图像和标签) 将R-CNN与ILSVRC 2013竞赛中的参赛作品以及竞赛后的 OverFeat结果进行了比较。 R-CNN的mAP达到31.4%,大大超过 了OverFeat的第二佳结果24.3%.为了让您了解AP在各个类别中的分布情况,还提供了箱形图及指(右图)每种方法的 200 个平均精度值的箱形图。竞赛后的 OverFeat 结果的箱形图未显示,并在下面表格中的末尾列出了每个类别的AP。大多数竞争者(OverFeat,NEC-MU,UvAEuvision,Toronto A, 和 UIUC-IFP)使用了卷积神经网络,这表明CNN如何应用于目标检测有很大的细微差别,导致结果差异很大。
(左图)ILSVRC2013 检测测试集的 mAP。*开头的方法使用外部训练数据(所有方法都使用 ILSVRC 分类数据集中的图像和标签) 将R-CNN与ILSVRC 2013竞赛中的参赛作品以及竞赛后的 OverFeat结果进行了比较。 R-CNN的mAP达到31.4%,大大超过 了OverFeat的第二佳结果24.3%.为了让您了解AP在各个类别中的分布情况,还提供了箱形图及指(右图)每种方法的 200 个平均精度值的箱形图。竞赛后的 OverFeat 结果的箱形图未显示,并在下面表格中的末尾列出了每个类别的AP。大多数竞争者(OverFeat,NEC-MU,UvAEuvision,Toronto A, 和 UIUC-IFP)使用了卷积神经网络,这表明CNN如何应用于目标检测有很大的细微差别,导致结果差异很大。

3.物体定位实验
作者在PASCAL VOC 2010数据集上进行了物体定位实验,即在检测到物体的情况下,准确地标注出物体的位置。实验结果表明,R-CNN的物体定位精度相较于之前的最优方法提高了约30%。
综上所述,R-CNN在多个数据集上进行了实验,均取得了较好的效果。该方法不仅能够检测物体,还能够准确地标注物体的位置,具有较高的应用价值。
不过,R-CNN也存在一些缺点。首先,R-CNN在测试时需要对每张图像提取约2,000个区域,并对每个区域进行卷积操作,计算量较大,导致检测速度较慢。其次,R-CNN需要对每个区域进行独立的卷积操作,使得模型的参数较多,难以训练。为了解决这些问题,后续的研究者提出了Fast R-CNN和Faster R-CNN等改进方法,使得检测速度和准确率都得到了提升,这些我门之后讲解的文章会提到。
五、数据集
ILSVRC2013检测数据集
数据集概述:
六、R-CNN的优缺点
1.优点
-
R-CNN在检测过程中能够产生高准确度的检测结果。相比传统的滑动窗口检测方法,它可以避免大量的计算和重复操作,从而节省了时间和空间开销。
-
R-CNN能够适用于各种类型的对象检测任务。它使用深度神经网络进行特征提取和分类,能够处理各种尺度、形状、姿态和遮挡的物体,并且在不同场景下都有着较好的表现。
-
R-CNN的训练方式比较灵活。其采用了两阶段的训练方法,可以先进行特征提取和预训练,再进行后续的微调,从而使得训练更加高效和准确。
-
R-CNN的检测结果比较可解释。由于其采用了区域提议和物体分类两个步骤,可以清晰地了解每个区域是如何被分类为目标的,并且可以可视化地展示每个区域的贡献度。
2.缺点
-
R-CNN的训练和测试速度较慢。其需要先进行区域提议,然后对每个提议进行特征提取和分类,整个过程比较繁琐,需要较长的时间和计算资源。
-
R-CNN的内存占用较大。由于其需要保存大量的区域提议和特征向量,因此需要较大的内存空间来存储数据,这会导致训练和测试时的内存瓶颈。
-
R-CNN的区域提议算法比较简单。其采用了基于选择性搜索的方法来生成区域提议,这种方法在生成大量提议时比较耗时,并且容易出现重叠区域和冗余区域的问题。
-
R-CNN对小目标的检测效果较差。由于其使用了全卷积网络进行特征提取,因此对于小目标的检测效果较差,容易出现漏检和误检的情况。
总的来说,R-CNN作为一种经典的目标检测方法,具有很多优点和缺点。在实际应用中,需要根据具体的场景和任务需求来选择合适的检测方法,并进行相应的调优和改进。
总结
综上所述,R-CNN作为目标检测领的一个重要里程碑,提出了一种基于区域建议的目标检测方法。通过使用深度学习技术,R-CNN在多个数据集上取得了显著的检测结果,具有高度的可靠性和准确性。
然而,R-CNN也存在一些不足之处。首先,其检测速度相对较慢,因为它需要进行两个阶段的训练和测试,并且在生成区域建议时需要使用较慢的选择性搜索算法。其次,由于每个目标都需要进行单独的前向传递,因此需要大量的计算资源。此外,由于区域选择的方法不够优秀,可能会出现漏检和误检的问题。
尽管存在一些缺点,但R-CNN为后续目标检测方法的研究提供了重要的启示和参考,其基本思想在很大程度上影响了目标检测领域的发展。随着技术的不断进步,各种改进的方法也应运而生,例如Fast R-CNN、Faster R-CNN和Mask R-CNN等方法。这些方法都基于R-CNN的基本思想,但在模型结构和算法优化方面有所不同,并在实验中取得了更好的结果。
在未来的研究中,我们可以尝试进一步优化R-CNN的模型和算法,使其具有更高的检测速度和更好的准确性。同时,我们也可以探索更加复杂和高级的模型,例如目前流行的一些深度学习模型,例如YOLO、SSD和RetinaNet等。


