
- 1VSCode文件跳转_文件放到vscode里变不成文件夹怎么办
- 2什么是CAS?CAS有什么问题?_cas的问题
- 3Java界面编程实战(三)——时钟小程序_java 时钟
- 4AVPlayer的基本使用_avplayer 重定向
- 5HarmonyOS ArkTS HTTP 请求简单封装(二十二)_arkts封装http请求
- 6关于“Python”的核心知识点整理大全49
- 7android开发中遇到的问题汇总【九】_cannot import 'getapplication', functions and prop
- 8逻辑回归原理_逻辑回归模型原理
- 9文本主题模型之潜在语义分析(LDA:Latent Dirichlet Allocation)_lda语义分析
- 10如何用python进行文字校对,python调整对齐的快捷键_python文本对齐
机器学习----PCA_机器学习pca
赞
踩
一、PCA思想
PCA是Principal Component Analysis(主成分分析)的缩写。它是一种常用的数据降维技术,可以将高维数据降维到低维空间中,同时保留尽可能多的原始数据的信息。
PCA的基本思想是:通过线性变换,将原始数据从高维空间投影到低维空间中,并使投影后的数据方差最大。这样可以把数据中的冗余信息去除,得到更紧凑、更容易处理的表示形式。
在具体应用中,PCA常常用于数据压缩、特征提取和可视化等领域。PCA还可以用于去噪、异常检测和聚类等任务。
二、PCA概念
主成分分析(Principal Component Analysis,PCA)是一种常用的数据预处理和降维方法。它的主要思想是将n维特征映射到k维上,这k维是全新的正交特征也被称为主成分,是在原有n维特征的基础上重新构造出来的k维特征23。
PCA的工作就是从原始的空间中顺序地找一组相互正交的坐标轴,新的坐标轴的选择与数据本身是密切相关的。其中,第一个新坐标轴选择是原始数据中方差最大的方向,第二个新坐标轴选取是与第一个坐标轴正交的平面中使得方差最大的,第三个轴是与第1,2个轴正交的平面中方差最大的。依次类推,可以得到n个这样的坐标轴2。
通过这种方式获得的新的坐标轴,我们发现,大部分方差都包含在前面k个坐标轴中,后面的坐标轴所含的方差几乎为0。于是,我们可以忽略余下的坐标轴,只保留前面k个含有绝大部分方差的坐标轴。事实上,这相当于只保留包含绝大部分方差的维度特征,而忽略包含方差几乎为0的特征维度,实现对数据特征的降维处理2。
PCA的数学定义是:一个正交化线性变换,把数据变换到一个新的坐标系统中,使得这一数据的任何投影的第一大方差在第一个坐标(称为第一主成分)上,第二大方差在第二个坐标(第二主成分)上,依次类推4。 PCA是最简单的以特征量分析多元统计分布的方法。
三、PCA内容
1、特征维度约减的概念
![]()
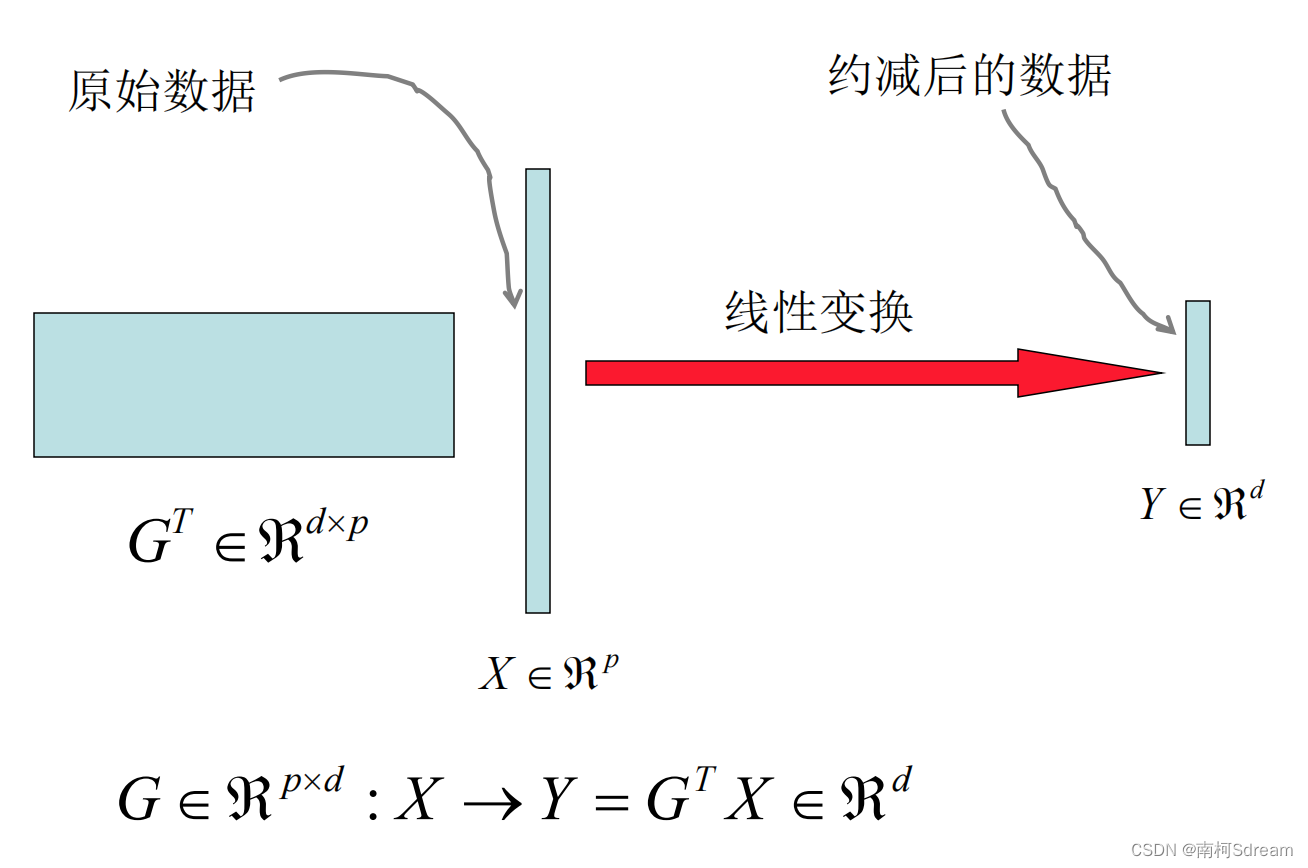
2、为何要维度约减?
3、常规维度约减方法
4、Principal Component Analysis (PCA)
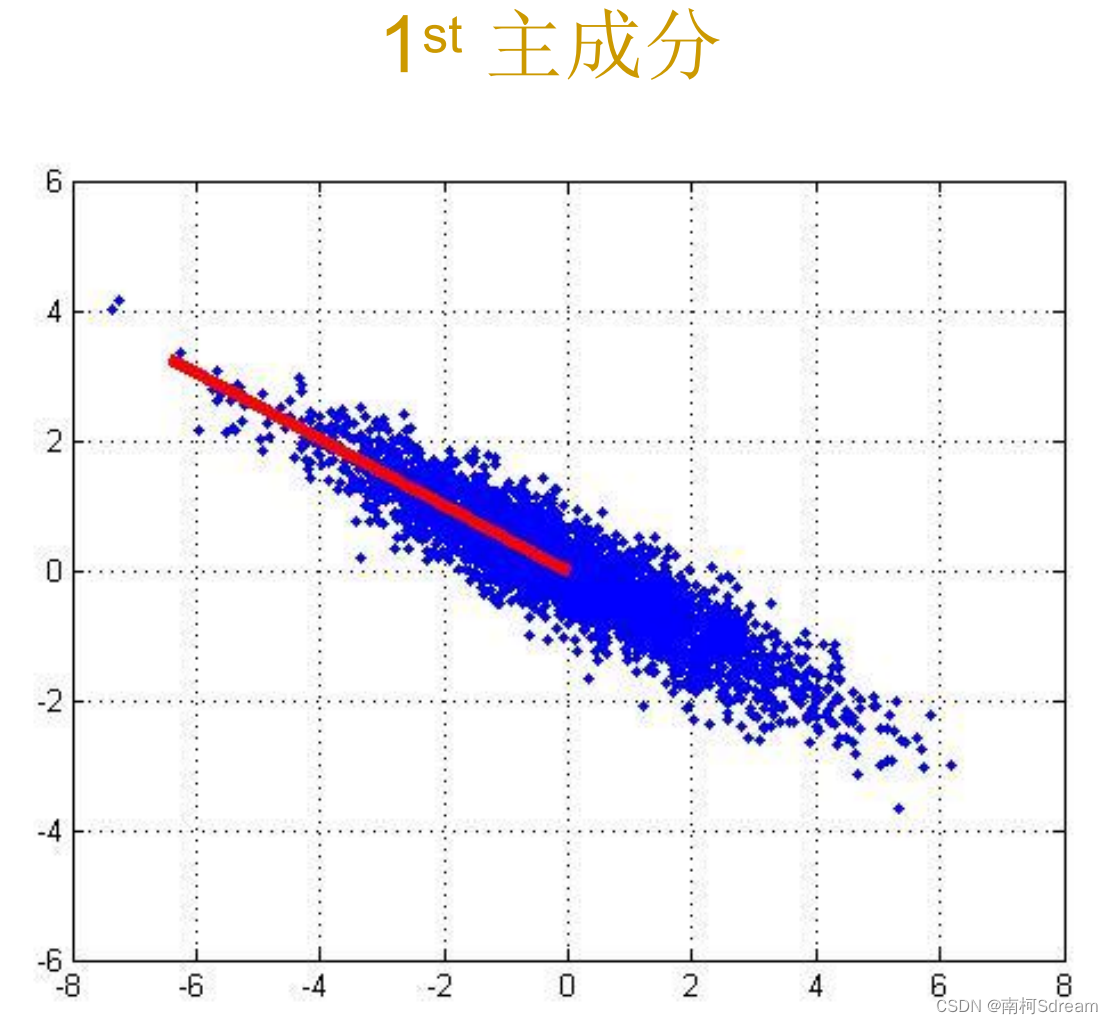
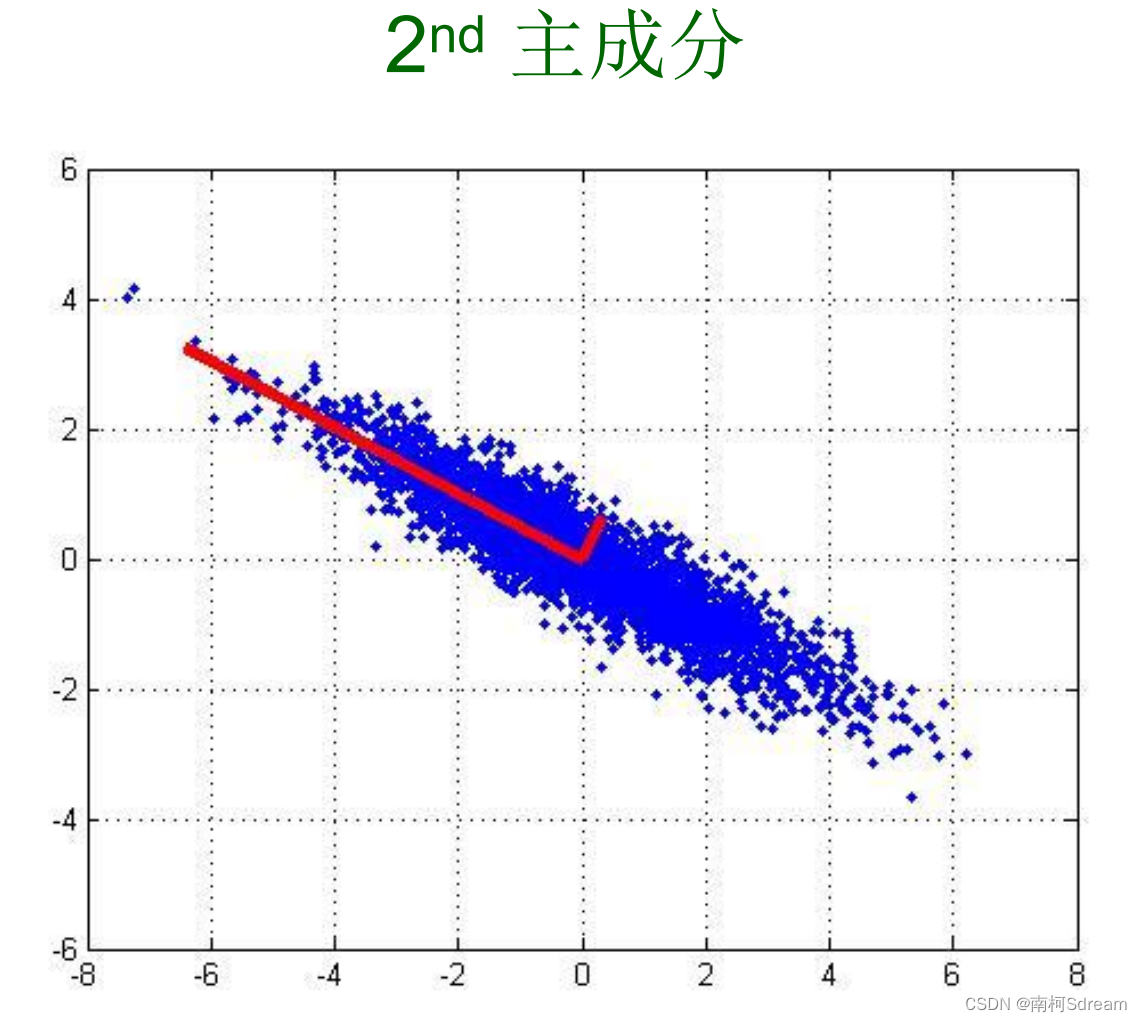
四、PCA算法步骤
-
1 数据预处理:将原始数据进行标准化,使得每个特征的均值为0,方差为1。这样可以确保各个特征具有相同的重要性。
-
2 计算协方差矩阵:根据预处理后的数据计算特征之间的协方差矩阵。协方差描述了两个变量之间的线性关系程度,可以衡量它们的相关性。
-
3 特征值分解:对协方差矩阵进行特征值分解,得到特征值和对应的特征向量。特征值表示每个特征向量上的信息量大小,特征向量则表示每个主成分的方向。
-
4 主成分选择:根据特征值的大小,选择较大的K个特征值对应的特征向量作为主成分。通常,选择特征值较大的前K个主成分可以保留大部分数据的信息。
-
5 数据投影:将原始数据投影到选取的K个主成分上,得到降维后的数据。投影的计算可以通过矩阵运算来实现。
五、代码实现
- import numpy as np
- from sklearn.datasets import fetch_lfw_people
- from sklearn.decomposition import PCA
- from sklearn.model_selection import train_test_split
- from sklearn.neural_network import MLPClassifier
- from sklearn.metrics import classification_report, accuracy_score
-
- # 加载人脸数据集
- lfw_dataset = fetch_lfw_people(min_faces_per_person=70, resize=0.4)
- X = lfw_dataset.data
- y = lfw_dataset.target
- target_names = lfw_dataset.target_names
-
- # 划分训练集和测试集
- X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
-
- # 执行PCA降维
- pca = PCA(n_components=150, whiten=True)
- pca.fit(X_train)
- X_train_pca = pca.transform(X_train)
- X_test_pca = pca.transform(X_test)
-
- # 训练分类器
- clf = MLPClassifier(hidden_layer_sizes=(1024,), batch_size=256, verbose=True, early_stopping=True)
- clf.fit(X_train_pca, y_train)
-
- # 预测测试集
- y_pred = clf.predict(X_test_pca)
-
- # 输出分类结果
- print(classification_report(y_test, y_pred, target_names=target_names))
- print("Accuracy:", accuracy_score(y_test, y_pred))

实验结果:
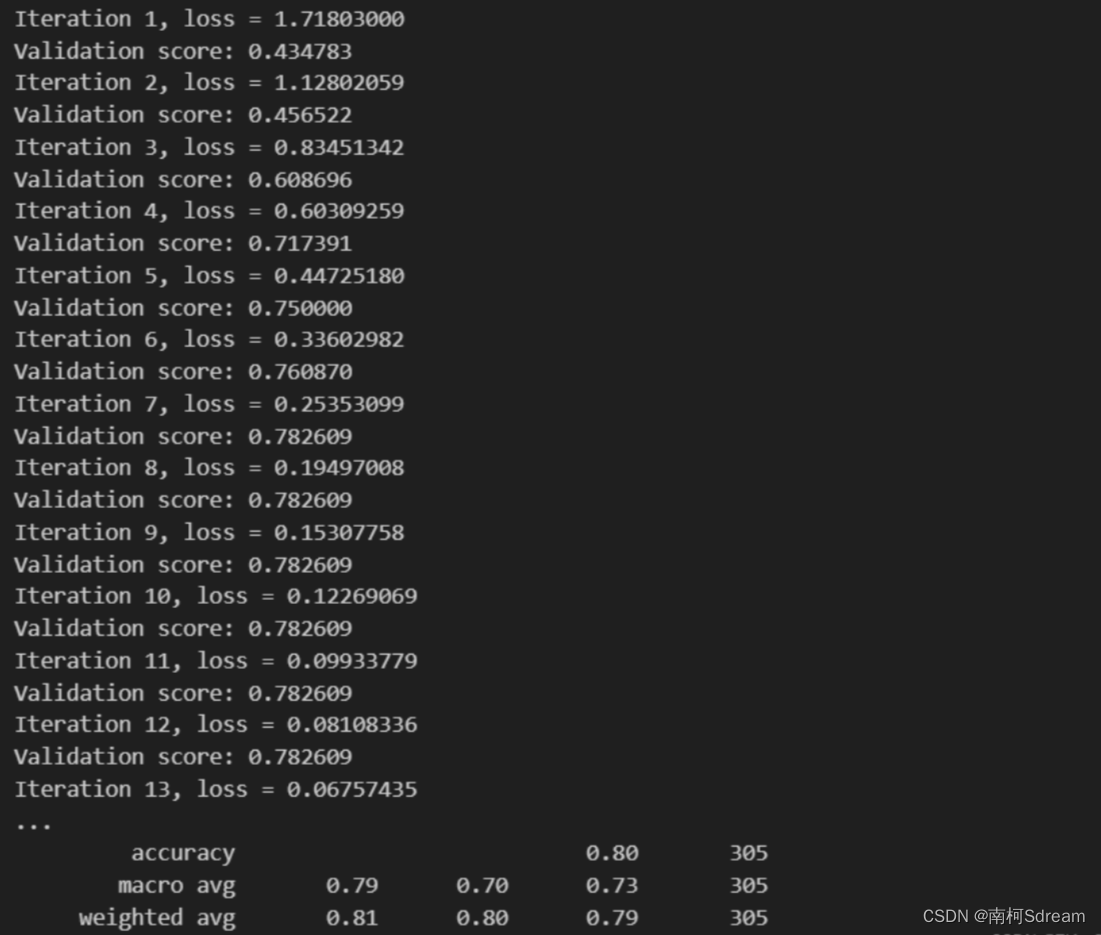
六、实验小结
本实验使用了Python和Scikit-learn库实现了基于PCA的人脸识别。首先,我们使用fetch_lfw_people函数加载人脸数据集,该数据集包含多个人的人脸图像。然后,我们将数据集分为训练集和测试集,并使用PCA降维技术将高维的人脸图像数据转换为低维的特征向量。接着,我们使用多层感知机(MLP)分类器对降维后的数据进行训练和预测。最后,我们评估了分类器的性能并输出了分类结果和准确率。
通过实验,我们可以得出以下结论:
-
PCA在人脸识别中起到了重要作用:PCA可以帮助我们降低数据维度,减少冗余信息,从而提取出更有代表性的特征向量。这对于人脸识别任务来说尤为重要,因为人脸图像通常具有较高的维度。
-
选择合适的PCA维度是关键:在实验中,我们选择了150作为PCA的维度,但实际应用中需要根据具体情况进行调优。选择过大的维度可能导致过拟合,而选择过小的维度可能导致信息丢失。
-
MLP分类器在人脸识别中表现良好:我们使用了MLP分类器对降维后的数据进行训练和预测,取得了较高的准确率。然而,对于更大规模的数据集和更复杂的任务,可能需要考虑其他更高级的分类器或深度学习模型。

