
- 1mysql in条件值是以逗号分隔的字符串,如何处理_mysql in 字符串 逗号分隔
- 2linux查看防火墙状态及开启关闭命令_linux查看防火墙状态找不到命令
- 3*号的三个用途_代码*作用
- 4鸿蒙HarmonyOS实战-Stage模型(概述和组件配置)_鸿蒙 stage模式
- 5QGIS编译(跨平台编译)056:PDAL编译(Windows、Linux、MacOS环境下编译)
- 6java计算机毕业设计基于springboo+vue的房产出租销售门户网站(房屋租赁系统源代码+数据库+Lw文档)_vue门户网站源码
- 7AndroidAutoLayout--屏幕适配终结者_com.zhy:autolayout下载
- 8【热点资讯】交通银行 RPA+AI 全布局_交通银行rpa数量
- 9Jetson Nano b01安装qt_jetson orin安装qt creactor
- 10aspectj's load-time instrumentation_weaveinfo join point 'method-execution(void com.ly
HBase整合Phoenix_phoenix-5.1.0-hbase-2.0-server.jar
赞
踩
一、简介
1、Phoenix定义
1)官网地址:http://phoenix.apache.org/
Phoenix是HBase的开源SQL皮肤。可以使用标准JDBC API代替HBase客户端API来创建表,插入数据和查询HBase数据。
优点:使用简单,直接能写sql。
缺点:效率没有自己设计rowKey再使用API高,性能较差。
2、Phoenix架构
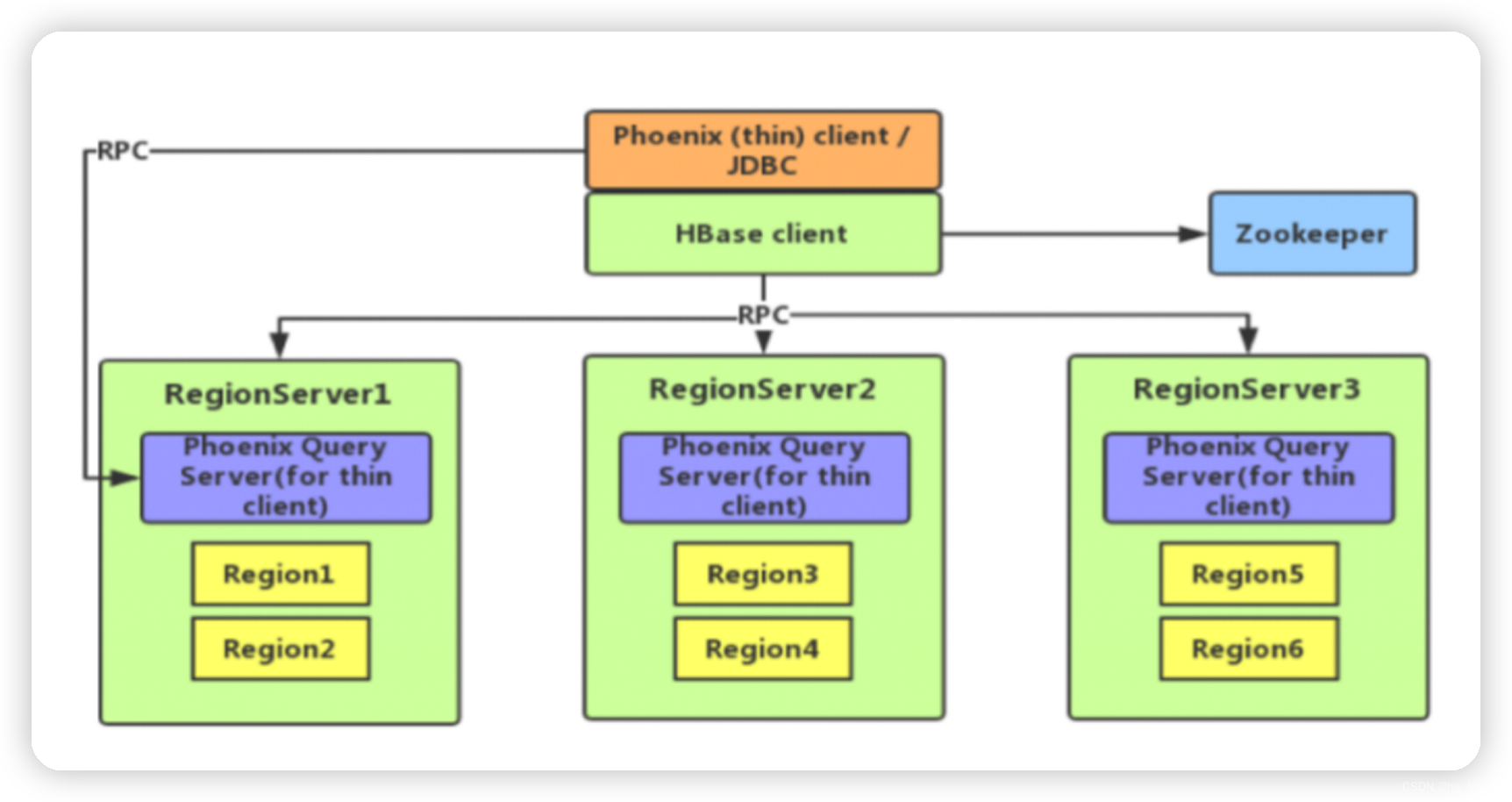
二、安装Phoenix
1、安装
将安装包上传到服务器目录
解压安装包
tar -zxvf apache-phoenix-5.0.0-HBase-2.0-bin.tar.gz -C /opt/module/
mv /opt/module/apache-phoenix-5.0.0-HBase-2.0-bin /opt/module/phoenix
- 1
- 2
复制server包并拷贝到各个节点Hadoop101、Hadoop102、Hadoop103的hbase/lib
cp /opt/module/phoenix/phoenix-5.0.0-HBase-2.0-server.jar /opt/module/hbase/lib/
xsync /opt/module/hbase/lib/phoenix-5.0.0-HBase-2.0-server.jar
- 1
- 2
配置环境变量
vim /etc/profile.d/my_env.sh
- 1
添加内容
#phoenix
export PHOENIX_HOME=/opt/module/phoenix
export PHOENIX_CLASSPATH=$PHOENIX_HOME
export PATH=$PATH:$PHOENIX_HOME/bin
- 1
- 2
- 3
- 4
在hbase-site.xml中添加支持二级索引的参数(如果不需要创建二级索引,不用不加)。之后分发到所有regionserver的节点上。
vim /opt/module/hbase/conf/hbase-site.xml
xsync /opt/module/hbase/conf/hbase-site.xml
- 1
- 2
配置内容
<property> <name>hbase.regionserver.wal.codec</name> <value>org.apache.hadoop.hbase.regionserver.wal.IndexedWALEditCodec</value> </property> <property> <name>hbase.region.server.rpc.scheduler.factory.class</name> <value>org.apache.hadoop.hbase.ipc.PhoenixRpcSchedulerFactory</value> <description>Factory to create the Phoenix RPC Scheduler that uses separate queues for index and metadata updates</description> </property> <property> <name>hbase.rpc.controllerfactory.class</name> <value>org.apache.hadoop.hbase.ipc.controller.ServerRpcControllerFactory</value> <description>Factory to create the Phoenix RPC Scheduler that uses separate queues for index and metadata updates</description> </property>

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
重启HBase
stop-hbase.sh
start-hbase.sh
- 1
- 2
连接 phoenix
/opt/module/phoenix/bin/sqlline.py hadoop101,hadoop102,hadoop103:2181
- 1
三、Phoenix操作
1、Phoenix 数据映射
Phoenix 将 HBase 的数据模型映射到关系型模型中。
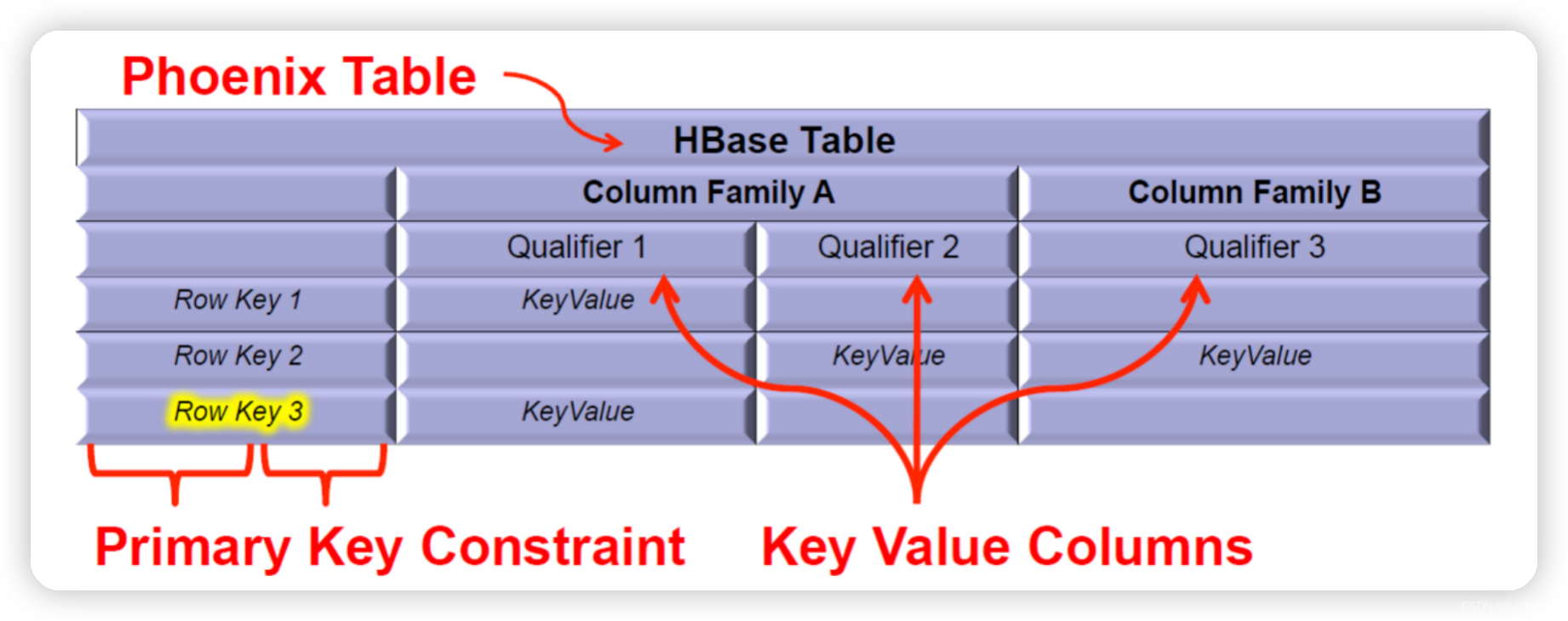
Phoenix中的主键会作为rowkey,非主键列作为普通字段。默认使用0作为列族,也可以在建表时使用 列族.列名 作为字段名,显式指定列族。
如果主键是联合主键,则会将主键字段拼接作为rowkey。
2、Phoenix Shell操作
- 登录Phoenix
/opt/module/phoenix/bin/sqlline.py hadoop101,hadoop102,hadoop103:2181
- 1
- 创建表
CREATE TABLE IF NOT EXISTS student(
id VARCHAR primary key,
name VARCHAR,
addr VARCHAR);
- 1
- 2
- 3
- 4
在phoenix中,表名等会自动转换为大写,若要小写,使用双引号,如"us_population"。
CREATE TABLE IF NOT EXISTS "un_student"(
id VARCHAR primary key,
name VARCHAR,
addr VARCHAR);
- 1
- 2
- 3
- 4
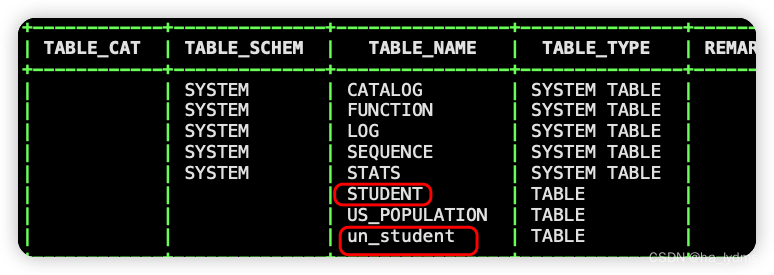
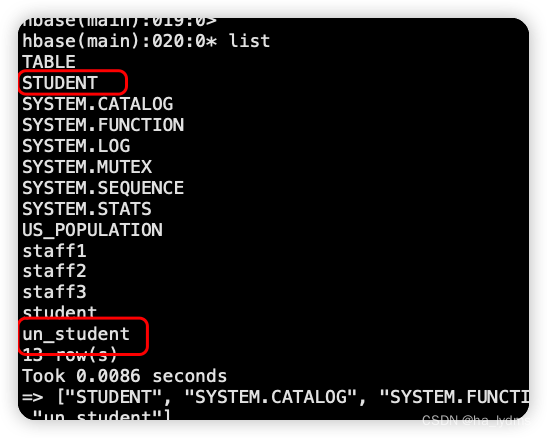
# 指定多个列的联合作为RowKey
CREATE TABLE IF NOT EXISTS us_population (
State CHAR(2) NOT NULL,
City VARCHAR NOT NULL,
Population BIGINT
CONSTRAINT my_pk PRIMARY KEY (state, city));
- 1
- 2
- 3
- 4
- 5
- 6
注意:Phoenix中建表,会在HBase中创建一张对应的表。为了减少数据对磁盘空间的占用,Phoenix默认会对HBase中的列名做编码处理。具体规则可参考官网链接:https://phoenix.apache.org/columnencoding.html,若不想对列名编码,可在建表语句末尾加上COLUMN_ENCODED_BYTES = 0;
CREATE TABLE IF NOT EXISTS student(
id VARCHAR primary key,
name VARCHAR,
addr VARCHAR)
COLUMN_ENCODED_BYTES = 0
;
- 1
- 2
- 3
- 4
- 5
- 6
- 插入或更新数据
upsert执行时,判断如果主键存在就更新,不存在则执行插入。
- 1
- 插入或更新数据
upsert执行时,判断如果主键存在就更新,不存在则执行插入。
upsert into student values('1001','zhangsan','beijing');
- 1
- 查询记录
select * from student;
select * from student where id='1001';
- 1
- 2
- 删除记录
delete from student where id='1001';
- 1
- 删除表
drop table student;
- 1
- 退出命令行
!quit
- 1
3、Phoenix JDBC操作
3.1 胖客户端
- 胖客户端指将Phoenix的所有功能都集成在客户端,导致客户端代码打包后体积过大。
pom依赖
<!-- 胖客户端--> <dependency> <groupId>org.apache.phoenix</groupId> <artifactId>phoenix-core</artifactId> <version>5.0.0-HBase-2.0</version> <exclusions> <exclusion> <groupId>org.glassfish</groupId> <artifactId>javax.el</artifactId> </exclusion> </exclusions> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>2.7.2</version> </dependency>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
测试代码:
import java.sql.*; public class TestThickClient { public static void main(String[] args) throws SQLException { // 1.添加链接 String url = "jdbc:phoenix:hadoop101,hadoop102,hadoop103:2181"; // 2.获取连接 Connection connection = DriverManager.getConnection(url); // 3.编译SQL语句 PreparedStatement preparedStatement = connection.prepareStatement("select * from student"); // 4.执行语句 ResultSet resultSet = preparedStatement.executeQuery(); System.out.println("==="); // 5.输出结果 while (resultSet.next()) { System.out.println(resultSet.getString(1) + ":" + resultSet.getString(2) + ":" + resultSet.getString(3)); } // 6.关闭资源 connection.close(); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27

3.2 瘦客户端
- 瘦客户端指将Phoenix的功能进行拆解,主要功能由服务端提供,只使用轻量级的客户端向服务端发送请求。
服务上启动hadoop101
queryserver.py start
- 1
pom文件
<!-- 瘦客户端-->
<dependency>
<groupId>org.apache.phoenix</groupId>
<artifactId>phoenix-queryserver-client</artifactId>
<version>5.0.0-HBase-2.0</version>
</dependency>
<dependency>
<groupId>com.google.protobuf</groupId>
<artifactId>protobuf-java</artifactId>
<version>3.21.4</version>
</dependency>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
测试代码
import org.apache.phoenix.queryserver.client.ThinClientUtil; import java.sql.*; public class TestThinClient { public static void main(String[] args) throws SQLException { // 1. 直接从瘦客户端获取链接 String hadoop102 = ThinClientUtil.getConnectionUrl("hadoop101", 8765); System.out.println(hadoop102); // 2. 获取连接 Connection connection = DriverManager.getConnection(hadoop102); // 3.编译SQL语句 PreparedStatement preparedStatement = connection.prepareStatement("select * from student"); // 4.执行语句 ResultSet resultSet = preparedStatement.executeQuery(); // 5.输出结果 while (resultSet.next()) { System.out.println(resultSet.getString(1) + ":" + resultSet.getString(2) + ":" + resultSet.getString(3)); } // 6.关闭资源 connection.close(); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
四、Phoenix二级索引
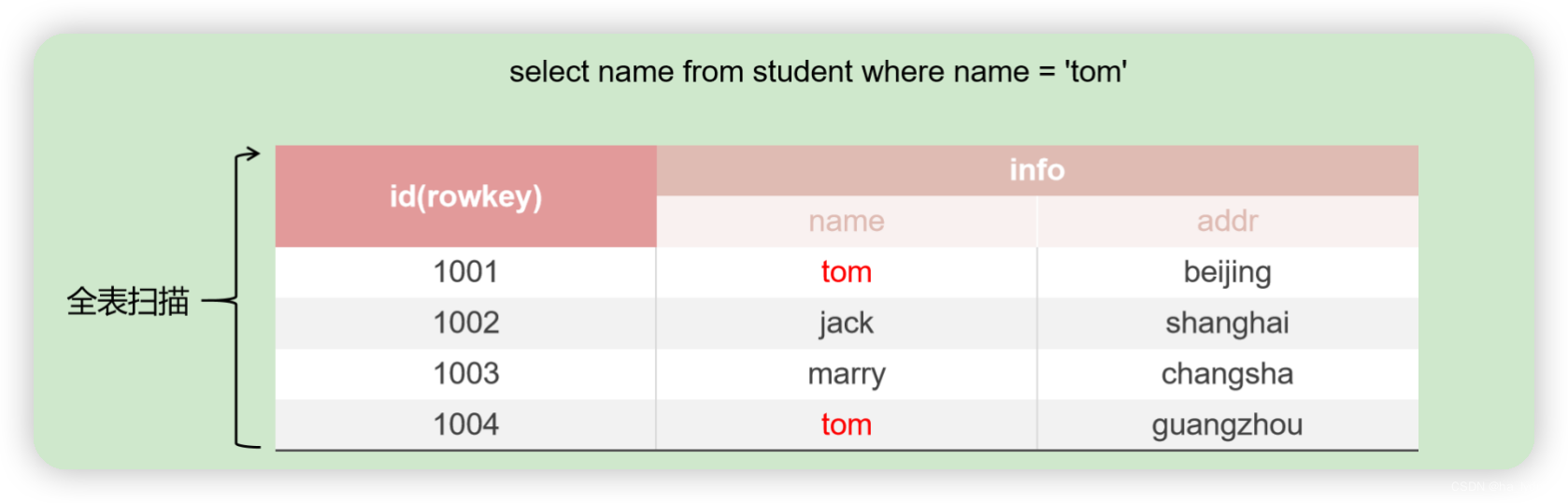
1、为什么需要二级索引
- 在HBase中查询时,必须指定rowkey。但是在Phoenix中,可以通过sql语句进行查询,在编写sql语句时,有事我们可能在不使用主键的情况下,进行过滤查询。此时好比是不使用rowkey,直接查询某一列。这样必须对某个表进行全表扫描,才能查询到指定的数据,效率低。
- 二级索引是针对列的索引,通过建立二级索引,可以在不使用主键进行查询的场景中提升查询效率。
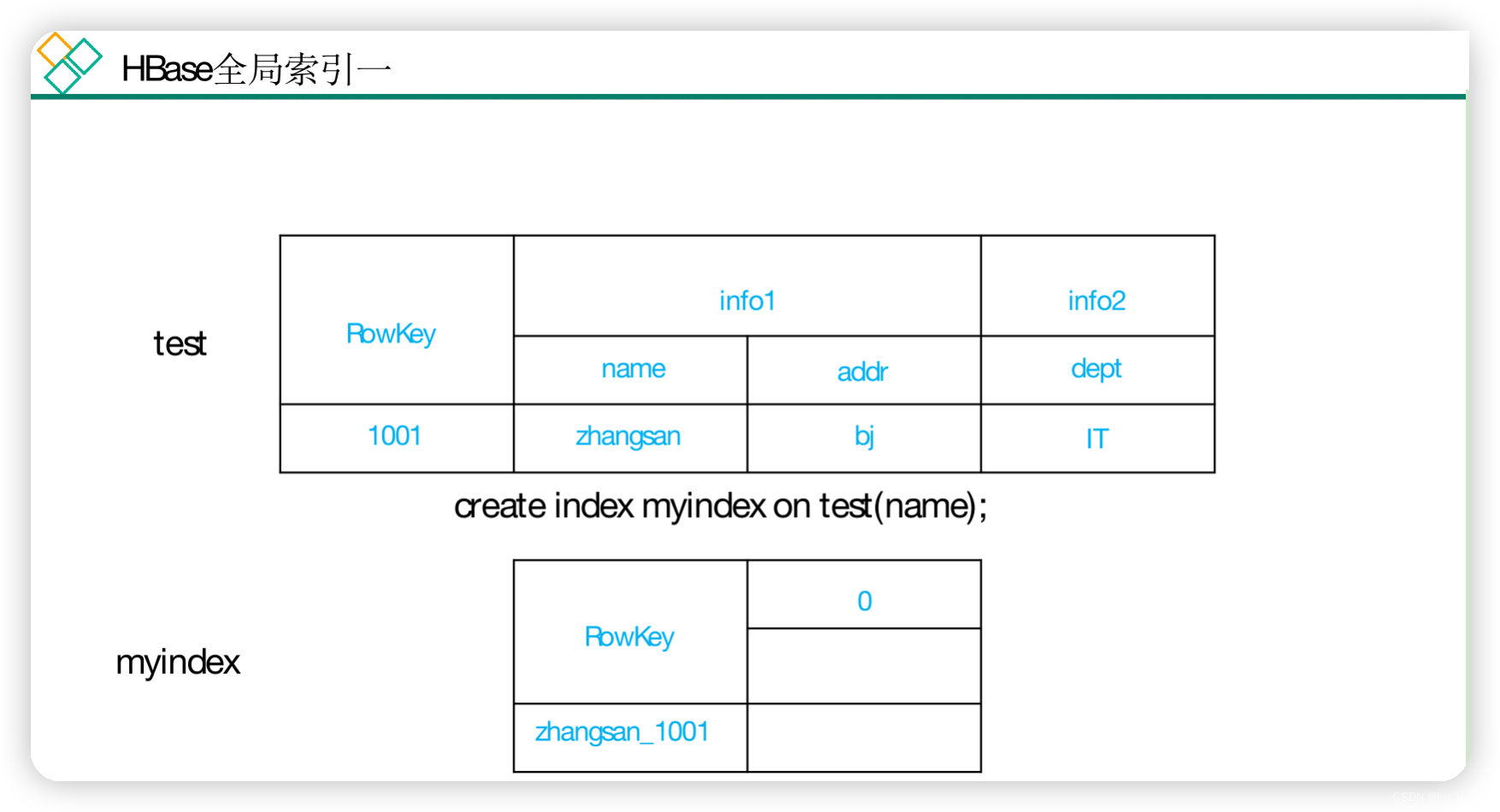
2、全局索引(global index)
- Global Index是默认的索引格式,创建全局索引时,会在HBase中建立一张新表。也就是说索引数据和数据表是存放在不同的表中的,因此全局索引适用于多读少写的业务场景。
- 写数据的时候会消耗大量开销,因为索引表也要更新,而索引表是分布在不同的数据节点上的,跨节点的数据传输带来了较大的性能消耗。
- 在读数据的时候Phoenix会选择索引表来降低查询消耗的时间。
创建单个字段的全局索引
CREATE INDEX my_index ON my_table (my_col);
- 1
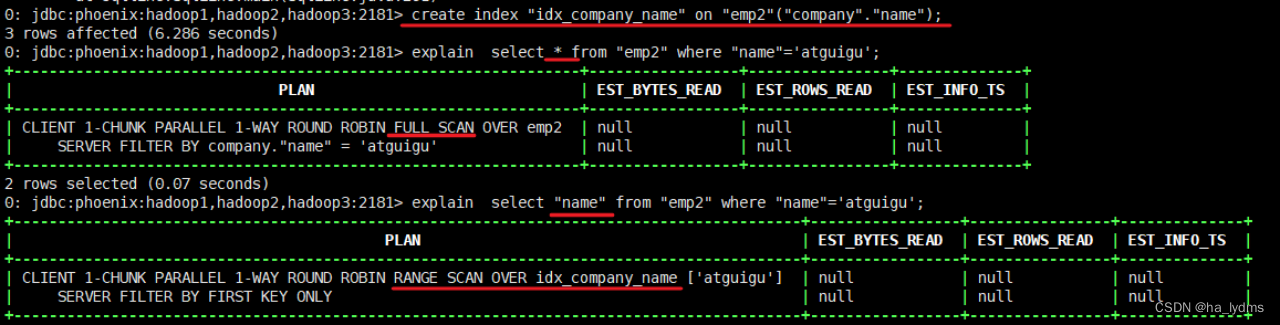
如果想查询的字段不是索引字段的话索引表不会被使用,也就是说不会带来查询速度的提升。
3、包含索引(covered index)
- 包含索引会将指定的列作为rowkey,包含的列作为普通列建立索引。
创建携带其他字段的全局索引
CREATE INDEX my_index ON my_table (v1) INCLUDE (v2);
- 1

4、本地索引(local index)
- Local Index适用于写操作频繁的场景。
- 在数据表中新建一个列族来存储索引数据。避免了在写操作的时候往不同服务器的索引表中写索引带来的额外开销。
CREATE LOCAL INDEX my_index ON my_table (my_column);
- 1


