
- 1大专计算机考证基础_专科计算机基础考什么
- 2Window11一键安装APK应用详细教程,及错误解决_win11安装apk
- 3脑科学开放日举行,张钹等专家:下一代AI创新要结合脑科学研究_中科院 人工智能
- 4Python存取图片至服务器数据库中_python 网络图片存入数据库
- 5JAVA编写有图形化界面的计算器_java四则运算计算器图形
- 6GNN手绘草图识别新架构:Multi-Graph Transformer 网络
- 7java计数_滑动窗口计数java实现
- 8abtest-显著性差异(significance test)
- 9python画图代码大全简单,python画图代码简单
- 10【GitHub项目推荐--自动生成视频】【转载】_githubtext转视频项目
[AIGC] Stable Diffusion - 什么是 LoRA 模型以及如何在 AUTOMATIC1111 中使用它们_shukezouma
赞
踩
英文原文:https://stable-diffusion-art.com/lora/
LoRA 模型是小型稳定扩散模型,对标准检查点模型进行微小的更改。它们通常比检查点模型小 10 到 100 倍。这使得它们对于拥有大量模型的人来说非常有吸引力。
这是针对之前没有使用过 LoRA 模型的初学者的教程。您将了解 LoRA 模型是什么、在哪里可以找到它们以及如何在 AUTOMATIC1111 GUI 中使用它们。然后你会在最后找到一些 LoRA 模型的演示。
LoRA 模型是什么?
LoRA(低阶适应)是一种用于微调稳定扩散模型的训练技术。
但我们已经有了 Dreambooth 和文本反转等训练技术。 LoRA 有什么大不了的? LoRA 在文件大小和训练能力之间提供了良好的权衡。 Dreambooth 功能强大,但会产生较大的模型文件(2-7 GB)。文本反转很小(大约 100 KB),但你不能做那么多。
LoRA 位于两者之间。它的文件大小更易于管理(2 – 200 MB),并且训练能力也不错。
喜欢尝试不同模型的 Stable Diffusion 用户可以告诉您他们的本地存储填满的速度有多快。由于体积较大,很难用个人计算机来维护收藏。 LoRA 是解决存储问题的绝佳解决方案。
与文本反转一样,您不能单独使用 LoRA 模型。它必须与模型检查点文件一起使用。 LoRA 通过对附带的模型文件进行小的更改来修改样式。
LoRA 是一种在不填满本地存储的情况下定制 AI 艺术模型的好方法。
LoRA 是如何工作的?
LoRA 对稳定扩散模型最关键的部分进行了微小的改变:交叉注意力层。它是模型中图像和提示词交汇的部分。研究人员发现,微调模型的这一部分就足以实现良好的训练。交叉注意力层是下面稳定扩散模型架构中的黄色部分。
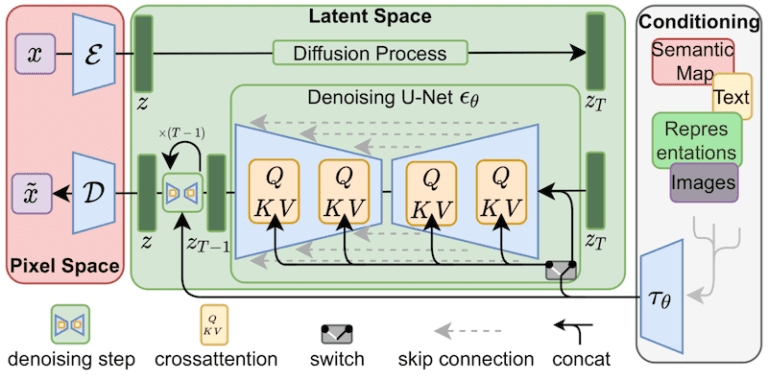
LORA 微调交叉注意力层(U-Net 噪声预测器的 QKV 部分)。 (图来自稳定扩散论文。)
交叉注意力层的权重排列在矩阵中。矩阵只是按列和行排列的一堆数字,就像 Excel 电子表格一样。 LoRA 模型通过将权重添加到这些矩阵来微调模型。
如果需要存储相同数量的权重,LoRA模型文件如何才能更小? LoRA 的技巧是将矩阵分解为两个较小的(低秩)矩阵。通过这样做,它可以存储更少的数字。让我们用下面的例子来说明这一点。
假设该模型有一个包含 1,000 行和 2,000 列的矩阵。模型文件中需要存储 2,000,000 个数字 (1,000 x 2,000)。 LoRA 将矩阵分解为 1,000×2 矩阵和 2×2,000 矩阵。这只有 6,000 个数字 (1,000 x 2 + 2 x 2,000),少了 333 倍。这就是 LoRA 文件小得多的原因。
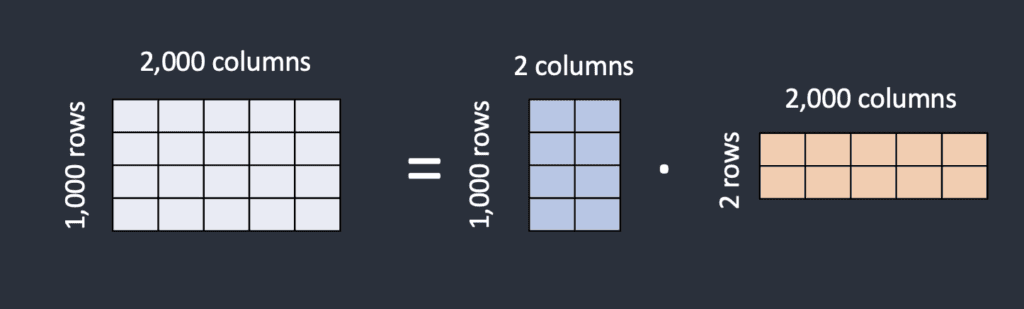
LoRA 将一个大矩阵分解为两个小的低秩矩阵。
在这个例子中,矩阵的秩为2。它比原始维度低得多,因此称为低秩矩阵。秩可以低至 1。
但这样的伎俩有什么害处吗?研究人员发现,在交叉注意力层中这样做并不会影响微调的能力。所以我们很好。
哪里可以找到 LoRA 模型?
Civitai
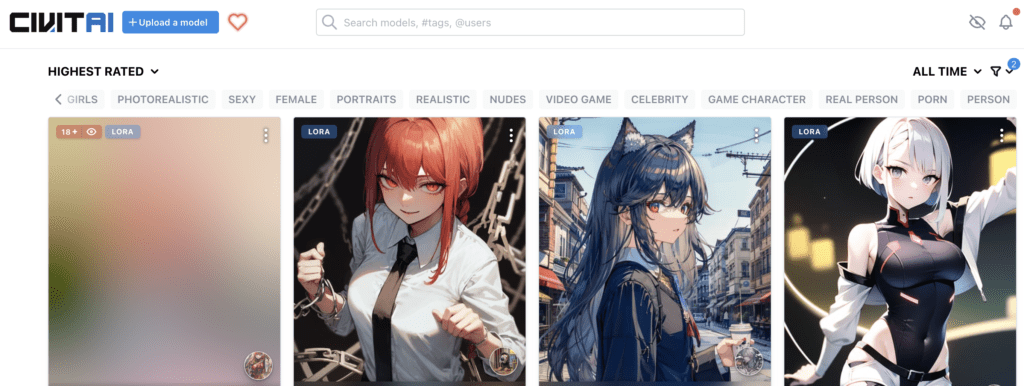
寻找LoRA的首选地点是Civitai。该网站拥有大量 LoRA 模型。应用 LORA 过滤器仅查看 LoRA 模型。你可能会发现它们都趋于相似:女性肖像、动漫、写实插画风格等。
(请注意,Civitai 上有很多 NSFW 内容。如果您不想看到无法看不到的内容,请务必使用 NSFW 过滤器……)
Hugging Face
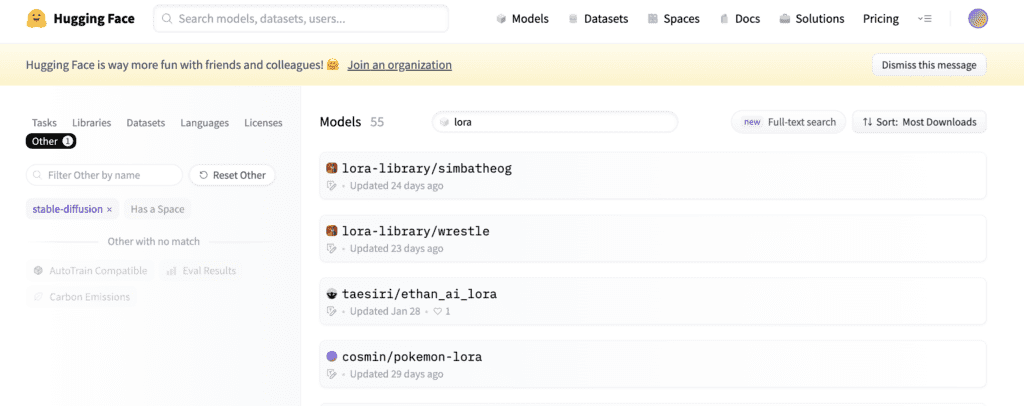
Hugging Face 是 LoRA 库的另一个很好的来源。您会发现更多种类的 LoRA 模型。但那里的 LoRA 模型并不多。他们的收藏要小得多。
如何使用LoRA?
在本节中,您将找到在 AUTOMATIC1111 稳定扩散 GUI 中使用 LoRA 模型的说明。您可以在 Windows、Mac 或 Google Colab 上使用此 GUI。
AUTOMATIC1111 本身支持 LoRA。您不需要安装任何扩展。
第1步:安装LoRA模型
要在 AUTOMATIC1111 webui 中安装 LoRA 模型,请将模型文件放在以下文件夹中。
stable-diffusion-webui/models/Lora
第2步:在提示符中使用LoRA
要在 AUTOMATIC1111 Stable Diffusion WebUI 中添加具有权重的 LoRA,请在提示或否定提示中使用以下语法:
<lora: name: weight>
name 是 LoRA 模型的名称。它可以与文件名不同。
weight 是 LoRA 模型的重点。它类似于关键字权重。默认值为 1。将其设置为 0 将禁用该模型。
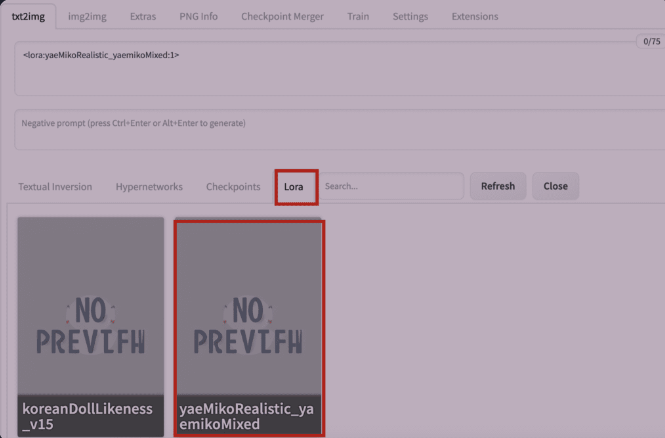
您如何确定名称正确?不要输入此短语,而是单击 LoRA 选项卡。
您应该会看到已安装的 LoRA 模型的列表。单击您要使用的那个。
LoRA 短语将插入到提示中。
LoRA使用注意事项
您可以调整乘数来调高或调低效果。将乘数设置为 0 会禁用 LoRA 模型。您可以在 0 和 1 之间调整样式效果。
一些 LoRA 模型是使用 Dreambooth 进行训练的。您需要包含一个触发关键字才能使用 LoRA 模型。您可以在模型页面上找到触发关键字。
与嵌入类似,您可以同时使用多个 LoRA 模型。您还可以将它们与嵌入一起使用。
在 AUTOMATIC1111 中,LoRA 短语不是提示的一部分。 LoRA模型应用后将被移除。这意味着您不能将 [keyword1:keyword2: 0.8] 之类的提示语法与它们一起使用。
有用的 LoRA 模型
Detail Tweaker(细节调整器)

细节调整器 LoRA 可以增加或减少细节(图片来源:CyberAIchemist)
谁不想要人工智能图像中的更多细节?细节调整器可让您增加或减少图像中的精细细节。现在,您可以输入所需的详细信息。
使用正 LoRA 权重来增加细节,使用负权重来减少细节。
Epi Noise Offset(Epi 噪声偏移)

Epi Noise OffSet LoRA 生成较暗的图像。 (图片来源:epikion)
众所周知,许多 Stable Diffusion v1.5 模型无法生成暗图像。 Epi Noise Offset LoRA 可让您使用任何 v1.5 模型生成暗图像。使用关键词黑暗工作室、边缘照明、双色调照明、昏暗灯光、低调等来诱发变暗效果。
Better Portrait lighting(更好的人像照明)

更好的人像照明 LoRA 为图像添加良好的照明。如果您正在处理肖像风格的真实感图像,那么值得一试。
有趣的 LoRA 模型
以下是我对有趣的 LoRA 模型的偏颇选择。
Shukezouma
Shukezouma LoRA模型带出时尚的中国水墨主题。Shukezouma是指画作中的留白空间(常见于中国画中)足够大,足以让马穿过它。
与中国风模特郭峰一起使用这款LoRA。
触发关键词:Shukezouma
提示词:
(shukezouma:0.5) ,<lora:Moxin_Shukezouma:1> , chinese painting, half body, female, perfect symmetric face, detailed chinese dress, mountains, flowers, 1girl, tiger
负面提示词:
disfigured, ugly, bad, immature

Akemi Takada (1980s)风格
高田明美(Akemi Takada)是一位日本漫画插画家。如果您喜欢 20 世纪 80 年代和 90 年代的日本动漫,这就是为您准备的。
与 AbyssOrangeMix2 模型一起使用。
提示词:
takada akemi, Tifa lockhart as magician, Final Fantasy VII, 1girl, small breast, beautiful eyes, brown hair, smiling, red eyes, highres, diamond earring, long hair, side parted hair, hair behind ear, upper body, stylish dress, indoors, bar 1980s (style), painting (medium), retro artstyle, watercolor (medium) <lora:akemiTakada1980sStyle_1:0.6>
负面提示词:
(worst quality, low quality:1.4), (painting by bad-artist-anime:0.9), (painting by bad-artist:0.9), watermark, text, error, blurry, jpeg artifacts, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, artist name, bad anatomy

Cyberpunk 2077 Tarot card
这个 LoRA 模型生成了具有未来赛博朋克风格的机器人和城市。
与 Anything v5 一起使用
提示词:
cyberpunk, tarot card, close up, portrait, bionic body, cat, young man, perfect human symmetric face, leather metallic jacket, circuit, city street in background, natural lighting, masterpiece <lora:cyberpunk2077Tarot_tarotCard512x1024:0.6>
负面提示词:
(worst quality, low quality:1.4), (painting by bad-artist-anime:0.9), (painting by bad-artist:0.9), watermark, text, error, blurry, jpeg artifacts, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, artist name, bad anatomy, big breast

总结
LoRA 模型是检查点模型的小修改。您可以通过在提示中包含短语来轻松地在 AUTOMATIC1111 中使用它们。
今天就这样!我将在以后的文章中告诉您如何训练 LoRA 模型。



