
windows10使用cuda11搭建pytorch深度学习框架——运行Dlinknet提取道路(三)——模型精度评估代码完善_dlinknet 代码
赞
踩
重新调试好代码,使用Dinknet34模型对数据集进行训练
数据集大小为1480张图片
运行时间为2022年1月12日16:00
记录下该模型训练时间
但如何评估模型的精度也是一个问题,因此作如下总结
模型精度评估
评价指标:
准确率 (Accuracy),混淆矩阵 (Confusion Matrix),精确率(Precision),召回率(Recall),平均正确率(AP),mean Average Precision(mAP),交除并(IoU),ROC + AUC,非极大值抑制(NMS)。
IoU
IoU这一值,可以理解为系统预测出来的框与原来图片中标记的框的重合程度。 计算方法即检测结果Detection Result与 Ground Truth 的交集比上它们的并集,即为检测的准确率。
是模型结果和标签作比较,但标签不一定是最后的道路真实数据
准确率 (Accuracy)
分对的样本数除以所有的样本数 ,即:准确(分类)率 = 正确预测的正反例数 / 总数。
准确率一般用来评估模型的全局准确程度,不能包含太多信息,无法全面评价一个模型性能。
精确率(Precision)与召回率(Recall)
一些相关的定义。假设现在有这样一个测试集,测试集中的图片只由大雁和飞机两种图片组成,假设你的分类系统最终的目的是:能取出测试集中所有飞机的图片,而不是大雁的图片。
True positives : 正样本被正确识别为正样本,飞机的图片被正确的识别成了飞机。
True negatives: 负样本被正确识别为负样本,大雁的图片没有被识别出来,系统正确地认为它们是大雁。
False positives: 假的正样本,即负样本被错误识别为正样本,大雁的图片被错误地识别成了飞机。 False negatives: 假的负样本,即正样本被错误识别为负样本,飞机的图片没有被识别出来,系统错误地认为它们是大雁。
Precision其实就是在识别出来的图片中,True positives所占的比率。也就是本假设中,所有被识别出来的飞机中,真正的飞机所占的比例。
Recall 是测试集中所有正样本样例中,被正确识别为正样本的比例。也就是本假设中,被正确识别出来的飞机个数与测试集中所有真实飞机的个数的比值。
Precision-recall 曲线:改变识别阈值,使得系统依次能够识别前K张图片,阈值的变化同时会导致Precision与Recall值发生变化,从而得到曲线。
如果一个分类器的性能比较好,那么它应该有如下的表现:在Recall值增长的同时,Precision的值保持在一个很高的水平。而性能比较差的分类器可能会损失很多Precision值才能换来Recall值的提高。通常情况下,文章中都会使用Precision-recall曲线,来显示出分类器在Precision与Recall之间的权衡。
有道路真实数据后就可以把提取结果和道路真值作比较,计算准确率召回率
OSM
获取OpenStreetMap(OSM)
https://zhuanlan.zhihu.com/p/25889246
实在没有真实数据就只能自己下osm之类的自己改
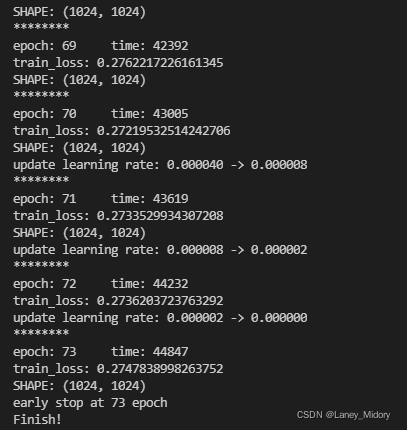
2022年1月13日11:00训练完成
接下来运行测试程序
test.py
输出结果

现在尝试训练3005个样本集
3005个样本集从2022年1月13日16:00开始跑
2022年1月15日16:30跑完
PyTorch绘制训练过程的accuracy和loss曲线
import绘制库
import matplotlib.pyplot as plt
- 1
绘制代码
Loss_list = []
Accuracy_list = []
Loss_list.append(train_loss)
Accuracy_list.append(100 * train_acc / (len(train_dataset)))
x1 = range(0, 200)
x2 = range(0, 200)
y1 = Accuracy_list
y2 = Loss_list
plt.subplot(2, 1, 1)
plt.plot(x1, y1, 'o-')
plt.title('Test accuracy vs. epoches')
plt.ylabel('Test accuracy')
plt.subplot(2, 1, 2)
plt.plot(x2, y2, '.-')
plt.xlabel('Test loss vs. epoches')
plt.ylabel('Test loss')
plt.show()
plt.savefig("accuracy_loss.jpg")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
我这里修改之后的代码是这样的:
x1 = range(0, len(Loss_list))
y1 = Loss_list
plt.plot(x1, y1, 'o-')
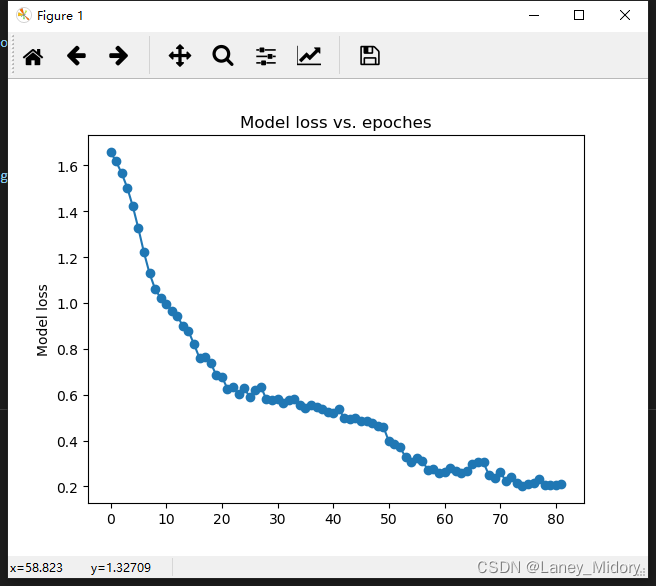
plt.title('Model loss vs. epoches')
plt.ylabel('Model loss')
plt.savefig("model_loss.jpg")
plt.show()
mylog.write('Finish!')
print ('Finish!')
mylog.close()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
这里要注意
一定要在 plt.show() 之前调用 plt.savefig();
如果在 plt.show() 后调用了plt.savefig() ,在 plt.show() 后实际上已经创建了一个新的空白的图片,这时候你再 plt.savefig() 就会保存这个新生成的空白图片
所以保存的图片将会是一片空白!!!!注意这两者的位置!!!
保存的结果:
PyTorch计算mIou(mean intersection over union)和pa(pixel accuracy)
miou计算需要使用到compute_mIoU函数
相关叙述这篇博文解释的很好
如果只输出miou那么可以查看这个代码来实现
这里需要用到头文件utils
import os
from PIL import Imagefrom tqdm import tqdm
from deeplab import DeeplabV3from utils.utils_metrics import compute_mIoU
'''进行指标评估需要注意以下几点:1、该文件生成的图为灰度图,因为值比较小,按照PNG形式的图看是没有显示效果的,所以看到近似全黑的图是正常的。2、该文件计算的是验证集的miou,当前该库将测试集当作验证集使用,不单独划分测试集'''
if __name__ == "__main__":
#---------------------------------------------------------------------------# # miou_mode用于指定该文件运行时计算的内容 # miou_mode为0代表整个miou计算流程,包括获得预测结果、计算miou。 # miou_mode为1代表仅仅获得预测结果。 # miou_mode为2代表仅仅计算miou。 #---------------------------------------------------------------------------#
miou_mode = 2
#------------------------------# # 分类个数+1、如2+1 #------------------------------#
num_classes = 2
# 区分的种类,和json_to_dataset里面的一样
# name_classes = ["background","aeroplane", "bicycle", "bird", "boat", "bottle", "bus", "car", "cat", "chair", "cow", "diningtable", "dog", "horse", "motorbike", "person", "pottedplant", "sheep", "sofa", "train", "tvmonitor"]
name_classes = ["nonroad","road"]
# 指向VOC数据集所在的文件夹 # 默认指向根目录下的VOC数据集
VOCdevkit_path = 'G:/Feng/TMP/Semantic segmentation/daima/VOCdevkit'
image_ids = open(os.path.join(VOCdevkit_path, "VOC2007/ImageSets/Segmentation/val.txt"),'r').read().splitlines()
gt_dir = os.path.join(VOCdevkit_path, "VOC2007/SegmentationClass/")
pred_dir = "G:/Feng/TMP/Semantic segmentation/daima/VOCdevkit/miou_out"
if miou_mode == 0 or miou_mode == 1:
if not os.path.exists(pred_dir):
os.makedirs(pred_dir)
print("Load model.")
deeplab = DeeplabV3()
print("Load model done.")
print("Get predict result.")
for image_id in tqdm(image_ids):
image_path = os.path.join(VOCdevkit_path, "VOC2007/JPEGImages/"+image_id+".jpg")
image = Image.open(image_path)
image = deeplab.get_miou_png(image)
image.save(os.path.join(pred_dir, image_id + ".png"))
print("Get predict result done.")
if miou_mode == 0 or miou_mode == 2:
print("Get miou.")
compute_mIoU(gt_dir, pred_dir, image_ids, num_classes, name_classes) # 执行计算mIoU的函数
print("Get miou done.")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
这里对于compute_mIoU函数的参数进行一些解释
gt_dir:VOCdevkit/VOC2007/SegmentationClass/ 是分割的png标签图片目录
pred_dir:miou_out是输出miou结果的目录,没有时会创建
png_name_list:是读取的验证集的png图片的名称序列
这里得获取png_name_list
相关方法如下
Python 利用os 获取文件夹中每一张图片的名字 并保存至 txt
查看这篇博文
带图片整个路径:
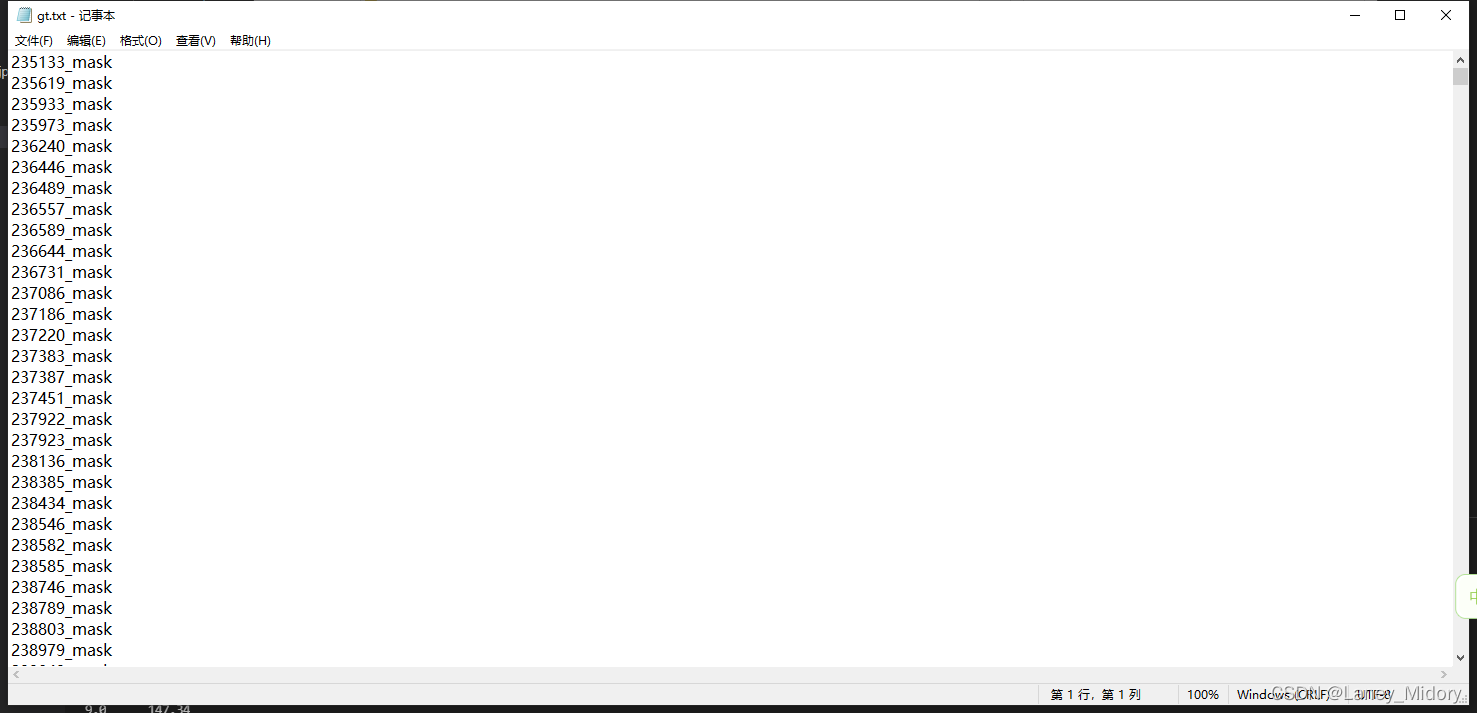
data_path = 'C:/Users/Administrator/Desktop/DeepGlobe-Road-Extraction-link34-py3/dataset/'
image_ids = open(os.path.join(data_path, "real/gt.txt"),'r').read().splitlines()
gt_dir = os.path.join(data_path, "real/")
pred_dir = "C:/Users/Administrator/Desktop/DeepGlobe-Road-Extraction-link34-py3/submits/log01_dink34"
for files in os.listdir(gt_dir):
print(files)
img_path = gt_dir+ files
with open("gt.txt", "a") as f:
f.write(str(img_path) + '\n')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
这样写的结果是图片的路径

不带后缀:
data_path = 'C:/Users/Administrator/Desktop/DeepGlobe-Road-Extraction-link34-py3/dataset/'
image_ids = open(os.path.join(data_path, "real/gt.txt"),'r').read().splitlines()
gt_dir = os.path.join(data_path, "real/")
pred_dir = "C:/Users/Administrator/Desktop/DeepGlobe-Road-Extraction-link34-py3/submits/log01_dink34"
path_list = os.listdir(gt_dir)
path_name = []
def saveList(pathName):
for file_name in pathName:
with open("C:/Users/Administrator/Desktop/DeepGlobe-Road-Extraction-link34-py3/dataset/real/gt.txt", "a") as f:
f.write(file_name.split(".")[0] + "\n")
def dirList(path_list):
for i in range(0, len(path_list)):
path = os.path.join(gt_dir, path_list[i])
if os.path.isdir(path):
saveList(os.listdir(path))
dirList(path_list)
saveList(path_list)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
这样写的结果是图片的前缀
open(“gt.txt”, “a”)
刚才打开文件过程中用到了‘r’这个参数,在文件打开过程中还会用到很多操作方法,都有不同的参数来表示。'r’读模式、'w’写模式、'a’追加模式、‘b’二进制模式、’+'读/写模式。
这里有个问题就是‘a’模式如果没有txt文件存在就会报错,他不会自己创建,因此这里最好换成w
with open("C:/Users/Administrator/Desktop/DeepGlobe-Road-Extraction-link34-py3/dataset/real/gt.txt", "w") as f:
- 1
很奇怪这样改了还是出现问题
No such file or directory: ‘C:/Users/Administrator/Desktop/DeepGlobe-Road-Extraction-link34-py3/dataset/gt.txt’
f=open(“C:/Users/Administrator/Desktop/DeepGlobe-Road-Extraction-link34-py3/dataset/gt.txt”, ‘w’)
一直报错,但是我的代码确实是创建txt文档呀
不知道为什么没法创建
之后才发现我先写了这个语句
image_ids = open(os.path.join(data_path, "gt.txt"),'r').read().splitlines()
- 1
然后才是创建txt文档
f=open("C:/Users/Administrator/Desktop/DeepGlobe-Road-Extraction-link34-py3/dataset/gt.txt", 'w')
- 1
这肯定会报错的,没有这个文件怎么访问
所以我调了一下代码的顺序
不应该太早就访问gt.txt而是应该等写入数据之后再访问
所以把它放到了最后面
dirList(path_list)
saveList(path_list)
image_ids = open(os.path.join(data_path, "gt.txt"),'r').read().splitlines()
- 1
- 2
- 3
问题解决!

