
- 1IPA包企业证书签名手动替换_ipa包烧签名好能不能更换文件
- 2反距离权重插值(IDW)
- 3探秘 widget 之 launcher 添加 widget 的流程分析_自定义launcher加载安卓wiget
- 4Commons IO -- IOUtils_commons-io ioutils
- 5Android4.0中AppWidget的一些新玩意体验_android:previewimage
- 6javax.servlet.http包
- 7v07.08 鸿蒙内核源码分析(调度机制) | 任务是如何被调度执行的 | 百篇博客分析HarmonyOS源码_鸿蒙内核shell程序是什么
- 8maven copy 依赖jar包
- 9人工智能之机器学习常见算法_人工智能、机器学习的算法不同
- 10详解小程序配置服务器域名_小程序 配置服务器域名
浅谈机器学习算法-决策树
赞
踩
数新网络-让每个人享受数据的价值
官网现已全新升级 欢迎访问!
决策树方法在分类、预测、规则提取等领域有着广泛应用。20世纪70年代后期和80年代初期,机器学习研究者J.Ross Quinlan提出了ID3算法以后,决策树在机器学习、数据挖掘领域得到极大的发展。Quinlan后来又提出了C4.5,成为新的监督学习算法。1984年,几位统计学家提出了CART分类算法。ID3和CART算法几乎同时被提出,但都是采用类似的方法从训练样本中学习决策树。
——《Python数据分析与挖掘实战》
01 介绍
决策树(Decision Tree)是一种常用的机器学习算法,用于解决分类和回归问题。它是一种基于树状结构进行决策的模型,通过一系列的判定来对数据进行分类或预测。
决策树的构建过程就是根据数据特征逐步进行划分,直到达到预定的终止条件。它是一种树形结构,其中每个内部节点代表一个属性上的判断,每个分支代表一个判断结果的输出,每个叶节点代表一种分类结果。决策树是一种十分常用的分类方法,属于有监管学习。
监管学习就是给出一堆样本,每个样本都有一组属性和一个分类结果,也就是分类结果已知,那么通过学习这些样本得到一个决策树,这个决策树能够对新的数据给出正确的分类。
02 案例分析
当谈到机器学习中的决策树时,我们可以考虑一个简单的二分类问题,例如预测一个人是否会购买某个产品,基于他们的年龄和收入水平。以下是一个示例:假设我们有一个数据集,其中包含了一些人的信息,以及他们是否购买了某个产品。数据集可能如下所示:
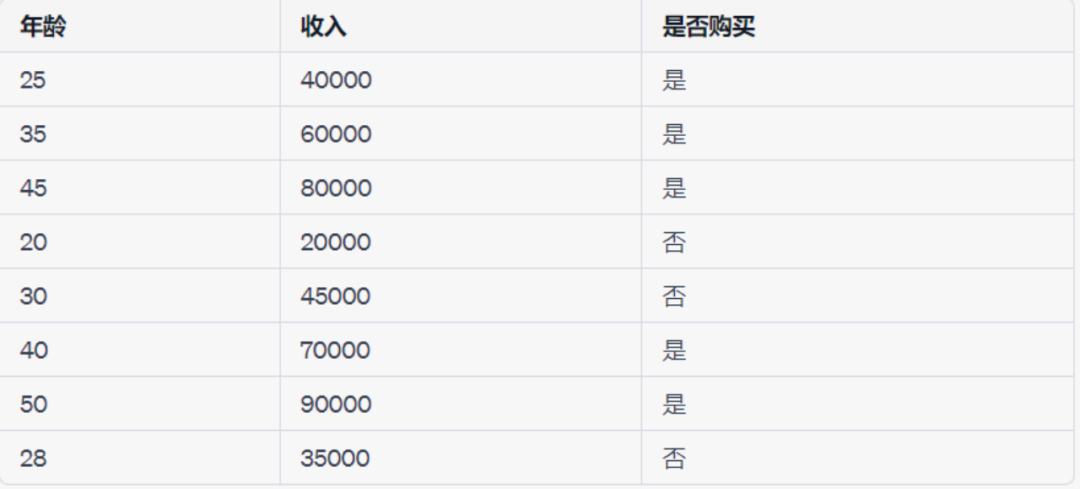
我们可以使用决策树来预测一个新的个体是否会购买产品。决策树的构建过程如下:
选择一个特征来分割数据。我们可以选择年龄或收入作为第一个分割特征。根据选定的特征将数据集分成不同的子集。
对于每个子集,重复步骤1和2,选择一个最佳的特征来进一步分割数据。
重复这个过程,直到达到某个停止条件,例如树的深度达到一定的限制或节点中的样本数不足以再次分割。
最终构建的决策树可能如下所示:
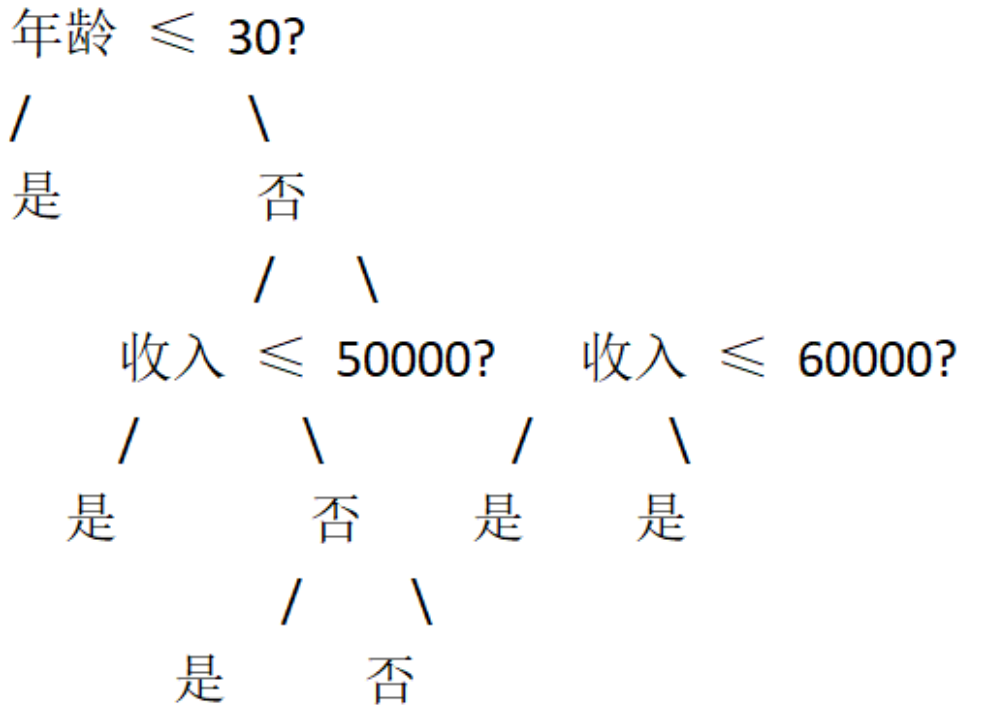
在这个决策树中,每个节点都代表一个特征及其阈值,每个分支代表一个决策。例如,根节点的“年龄 ≤ 30?”是一个决策,如果满足这个条件,就沿着左分支走,否则沿着右分支走。最终,我们可以根据这个决策树来预测一个新个体是否会购买产品。
03 分类
比较常用的决策树有ID3,C4.5和CART。下面介绍具体原理思想。
3-1 ID3算法
是一种经典的决策树算法,用于解决分类问题。它由Ross Quinlan于1986年提出,是决策树算法的先驱之一。ID3的主要思想是通过递归地选择最佳的特征进行划分,以构建一个树状结构,将数据集划分成不同的子集,最终达到分类的目标。
以下是ID3算法的主要原理步骤:
(1)特征选择: 在每个节点上,选择一个最佳的特征来进行数据集的划分。ID3使用信息增益(Information Gain)作为特征选择的依据。信息增益是衡量某个特征划分对于数据集纯度提升的程度,选择能够带来最大信息增益的特征。
(2)划分数据: 使用选定的特征和其取值将数据集划分成多个子集,每个子集对应一个分支。这些子集将作为树的下一层节点。
(3)递归构建: 对于每个子集,如果子集内的样本不属于同一类别,则继续递归地进行特征选择和划分,直到满足某个终止条件(例如,子集内的样本都属于同一类别,或者特征已经用完)。
(4)生成决策树: 最终,ID3通过递归地进行特征选择、划分和构建,生成一棵完整的决策树,其中每个叶节点表示一个类别标签。
ID3的主要优点是简单易懂、容易实现,并且能够处理离散特征。然而,它也存在一些问题,如容易过拟合(过度学习训练数据)。
3-2 C4.5算法
ID3算法在决策树构建过程中存在一个问题,即它倾向于将数据集划分得非常细致,以达到训练数据零错误率的目标。然而,这种细致的分割可能在训练数据上表现得很好,但对新的未见过的数据却无法泛化,导致分错率上升,这就是过度学习的现象。
这种过度学习现象可以用一个例子来说明:假设我们以某个特定属性的阈值为标准,将数据集分成两组,但在其中一组中有1个样本分类错误。然后,我们进一步微调阈值,将其中的一个样本划分到另一组,这样训练数据的分类错误率变为0。然而,这样的微调可能只是对当前数据集有效,对于新数据却无法产生相同的效果,因为新数据可能与训练数据不同。这导致了决策树在训练数据上表现良好,但在新数据上表现糟糕。
为了解决这个问题,C4.5算法对ID3进行了改进。C4.5引入了信息增益率的概念,这是一个优化项,它将信息增益除以分割的代价,以降低分割过于细致的情况。信息增益率考虑了分割的效果与分割代价之间的平衡,从而避免了过度学习的问题。因此,C4.5在进行特征选择时不仅考虑了信息增益,还考虑了分割的代价,以确保决策树能够更好地泛化到新的数据。
3-3 CART算法
CART(Classification and Regression Trees,分类与回归树)是一种常用的决策树算法,它可以用于解决分类和回归问题。CART 算法的主要思想是通过递归地将数据集划分为更小的子集,然后在每个子集上构建一个简单的决策树,从而达到分类或回归的目标。
当使用CART(分类与回归树)进行回归任务时,每个节点都代表数据的一个子集,而每次分裂都旨在找到一个特征和阈值,将数据分成更具相似性的子集。理想情况下,如果每个叶节点内的数据都属于同一个类别,那么树的构建就可以停止,达到最佳的分类。然而,在实际应用中,数据可能不够清晰地分割成不同的类别,或者要达到纯净的分割需要多次分裂,导致构建树的时间变得很长。
为了解决这个问题,CART算法引入了回归解析的概念。这意味着在树的构建过程中,不仅仅考虑了数据的纯度,还考虑了叶节点内数据的分布情况。具体而言,CART会计算每个叶节点内数据的均值和方差。如果一个叶节点内数据的方差小于某个阈值,意味着这个叶节点内的数据相对来说比较相似,树的分割可能已经足够好了。
因此,CART可以决定停止在这个节点继续分割,从而达到降低计算成本的目的。CART和ID3一样,也存在过度拟合问题。可以对特别长的树进行剪枝处理来解决该问题。
04 交叉验证法(Cross- Validation)
在决策树训练的时候,一般会采取交叉验证(Cross-Validation)法。它是一种常用于评估和选择机器学习模型性能的技术。它的主要目的是在有限的数据上尽可能准确地估计模型在未见数据上的性能,从而避免过拟合或选择不适合的模型。其执行步骤如下:
a. 将数据分成k个相等的子集(折叠)。
b. 在第 i 个折叠上,将第 i 个折叠作为测试集,其他 k-1 个折叠作为训练集。
c. 训练模型:使用训练集的数据来训练机器学习模型。
d. 测试模型:使用测试集的数据来评估模型的性能,计算性能指标(如准确率、精确率、召回率等)。
e. 重复步骤 b-d,直到每个折叠都作为测试集一次。
交叉验证可以帮助准确地估计模型的性能,从而支持更好的模型选择和超参数调整,以获得更好的泛化性能。

