
- 1反反爬虫之--爬取大众点评--店铺名称、详址、经纬度、评价人数、平均消费等信息_怎么爬大众点评的店铺信息
- 2初学构建小项目之仓库管理系统数据库及表的创建及登录页面的实现(一)_addcomponent(passwordtxt, grouplayout.preferred_si
- 3python-提取特征 & 特征选择_python 脑电信号特征提取
- 4Python请求示例获取抖音视频详情数据,抖音商品详情数据_抖音获取视频信息
- 57大最常用ChatGPT Excel最佳使用示例(最后附微软官方Excel-ChatGPT插件使用方法)——手把手从0开始教您如何在Excel中使用ChatGPT,附详细指南及教程_chatgpt for excel
- 6基于Python爬虫广西柳州餐厅餐馆数据可视化系统设计与实现(Django框架) 研究背景与意义、国内外研究现状
- 7语音交互的三驾马车:ASR、NLP、TTS_asrnlp全称英文
- 8使用LSTM进行情感分析_lstm 情感分析 影响准确率的因素
- 9[AIDV] 芯片验证:AI 机器学习在 DV 中的应用及进展_dv验证芯片
- 10spring cloud config server端接收到远程仓库端消息之后,无法将消息传递到config client端的问题_discoveryclient - registration status: 204
马斯克发布Grok 1.5! 编码和数学能力大幅提升
赞
踩
就在刚刚,马斯克Grok大模型宣布重大升级。
难怪之前突然开源了Grok-1,因为他有更强的Grok-1.5了,主打推理能力。
GPT-3.5研究测试站:
https://hujiaoai.cn
GPT-4/Claude-3研究测试站:
https://higpt4.cn/
推荐一个自动刷arXiv的AI Agent,推荐每日最热AI论文,并转为论文解读:
https://www.saibomaliang.com/generate?agent_id=68248fd1-32f9-4869-a35d-b6086ac0ebcf
(已被清华、北航、复旦、百度等多家高校和大厂AI团队引进使用)
来自xAI的官方推送啥也没说,直接甩链接。主打一个“字少事大”图片
▲image
新版本Grok有啥突破?
一是上下文长度飙升,从8192增长到128k,和GPT-4齐平。
二是推理性能大幅提升,数学能力直接涨点50%之多、HumanEval数据集上得分超过GPT-4。
消息一出,评论区立刻就躁起来了。

具体跑分结果如何,咱们立马来看。
Grok-1.5来了
首先,对于上下文窗口。
这次是一把直接提升到之前的16倍,来到128k量级。
这也就意味着Grok可以处理更长和更复杂的提示,同时保持其遵循指令的能力。
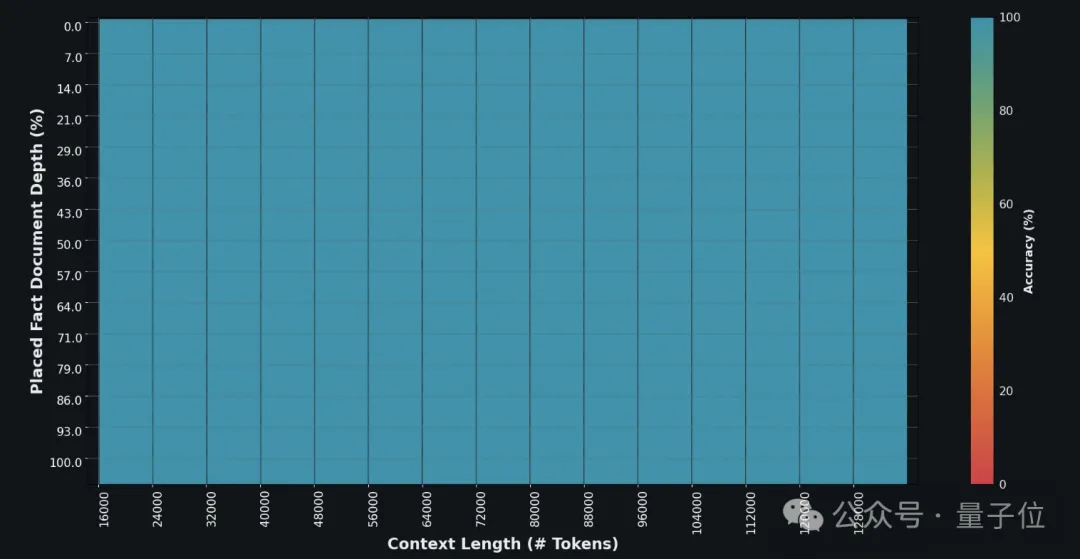
在“大海捞针”(NIAH)测试中,Grok-1.5在128K token的上下文中完美检索嵌入的文本。
整个图一水儿的蓝色(100%的检索深度):
其次,推理方面。
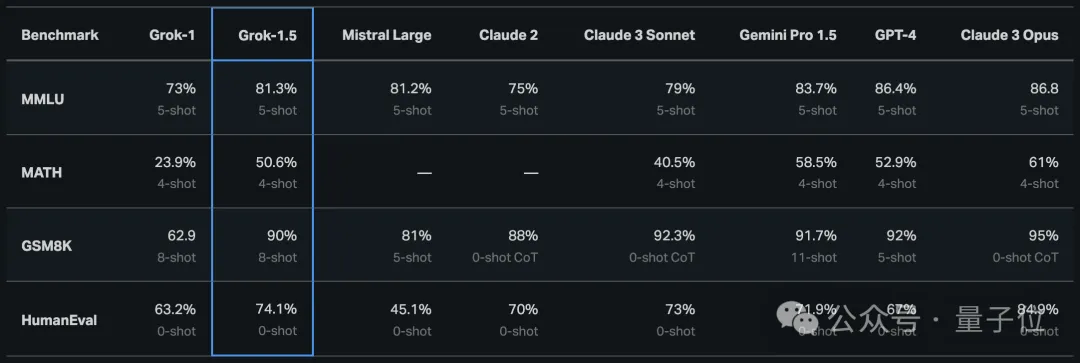
Grok-1.5处理编程和数学相关任务的能力大幅提升,全面超越Grok-1、Mistral Large、Claude 2。
数学方面,Grok-1.5在MATH基准测试上得分50.6%,超越中杯Claude 3 Sonnet;GSM8K上得分90%。
编程方面,Grok-1.5在HumanEval基准测试上得分74.1%,超越中杯Claude 3 Sonnet、Gemini Pro1.5、GPT-4,仅次于大杯Claude 3 Opus。
看起来,Grok这次的实力也是不可小觑。
Grok系列与其他大模型相比还有一个特色,不使用通用的Python语言+Pytorch框架。
据官方介绍,Grok 1.5采用分布式训练架构,使用Rust、JAX+Kubernetes构建。
为了提高训练可靠性和维持正常运行时间,团队提出了自定义训练协调器,可自动检测到有问题的节点,然后剔除。
除此之外,他们还优化了checkpointing、数据加载和训练重启等流程,最大限度地减少故障停机时间。
这,才速速有了现在的Grok 1.5~
更多信息官方也暂时还没有披露。
可以确定的是,新版本未来几天会先推送给早期测试者。并按照“老规矩”,很快将在声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/Monodyee/article/detail/337551
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

