
- 1【Sql Server】通过Sql语句批量处理数据,使用变量且遍历数据进行逻辑处理_sql 遍历
- 2大模型Agent
- 3荣耀10什么时候能更新鸿蒙系统,荣耀手机能升级鸿蒙系统吗?荣耀升级鸿蒙系统机型名单及时间表...
- 4专注于创造,低成本制作电影的好用 AI 工具!#Wonder Studio AI
- 5SpringBoot获取Request的3种方法!
- 6MacOS 安装 VMware Fusion 以及 CentOS7 (ARM 64 版本)_mac m2 vmware fusion 安装 centos 7.9(arm 64 版本)
- 7版本号对比 比较大小 (版本比较)_版本号判断大小
- 8正则表达式对比(Java和JavaScript)_java正则和js正则的区别
- 9杰理之AD14 AD15 AC104定时器中断响应时间不准?【篇】_杰理的怎么设置定时器准
- 10微信小程序:scroll-view自动滚动到最底部,附view标签滚动到底部方法_scroll-view 发送成功消息后滚动到最后一条消息
语义分割中的一些模型的分类汇总_语义分割模型
赞
踩
语义分割是深度学习中的一个重要应用领域。自Unet提出到现在已经过去了8年,期间有很多创新式的语义分割模型。简单的总结了Unet++、Unet3+、HRNet、LinkNet、PSPNet、DeepLabv3、多尺度attention、HarDNet、SegFormer、SegNeXt等10个语义分割模型的基本特性。并对这些模型的创新点进行分类汇总。
1、拓扑结构改进
1.1 UNet++
相比于unet,增加了内部的跳跃连接,使模型具备了更多的Unet集合网络,并提出了深度监督在unet++上的使用(在新增的不做下采样的x0级别的内部跳跃连接添加conv1x1,并连接的输出中)
同时提出了,该结构的unet可以对模型剪枝进行最大适配。
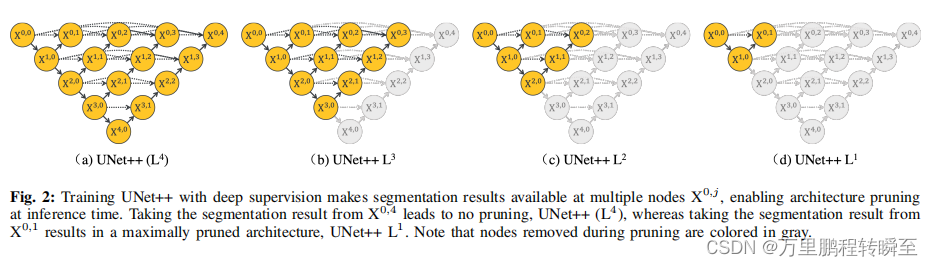
1.2 Unet3+
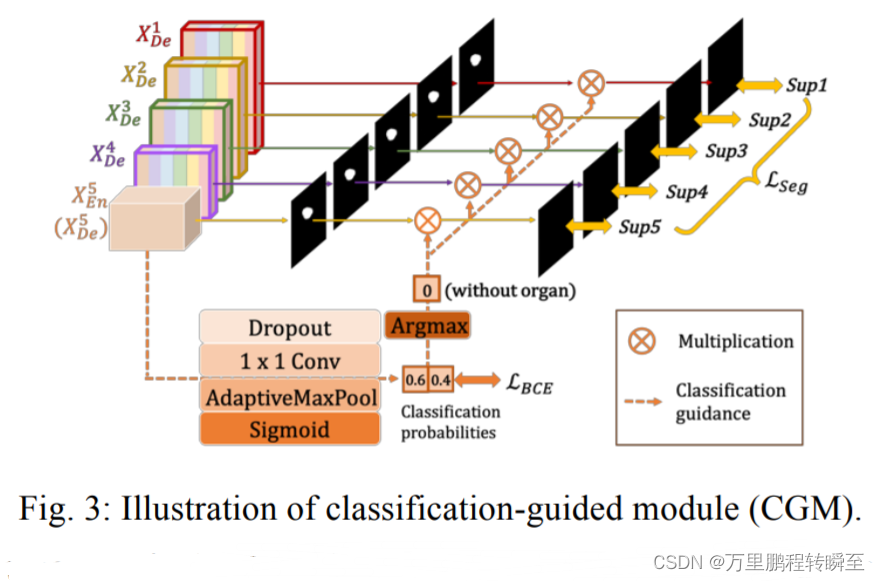
UNet 3+,通过引入全尺度跳跃连接来充分利用多尺度特征,该连接将低层次细节与全尺度特征图中的高层次语义相结合,相比UNet++参数较少; (ii) 使用深度监督以从全尺寸聚合特征图中学习层次表示,从而优化混合损失函数以增强器官边界; (iii) 提出一个分类引导模块,通过与图像级分类联合训练来减少非器官图像<噪声数据>的过度分割。
给出了 UNet、UNet++ 和新提出 UNet 3+ 的简化概述。与 UNet 和 UNet++ 相比,UNet 3+ 通过重新设计跳跃连接(删除了unet++中的短连接)以及利用全尺度深度监督结合了多尺度特征,提供更少的参数但产生更准确的位置感知和边界增强分割图。
内容参考:https://hpg123.blog.csdn.net/article/details/125950195

分类引导模块
因为影像中存在背景噪声,可能存在干扰[对于没有器官的图像,模型可能会把背景识别为器官]。故对每一层次的特征图,都使用Classification-guided Module进行分类引导训练。
经过 dropout、conv、maxpooling 和 sigmoid 等一系列操作后,从最深层产生一个二维张量,每个张量代表 有/没有 器官的概率。受益于最丰富的语义信息,分类结果可以进一步指导每个分割侧输出分两步。首先,在 argmax 函数的帮助下,二维张量被转换为 {0,1} 的单个输出,表示 有/没有 器官。随后,我们将单个分类输出与侧分割输出相乘。由于二元分类任务的简单性,该模块在二元交叉熵损失函数的优化下毫不费力地达到了准确的分类结果,实现了对弥补无器官图像过分割缺陷的指导。
原文链接:https://blog.csdn.net/a486259/article/details/125950195
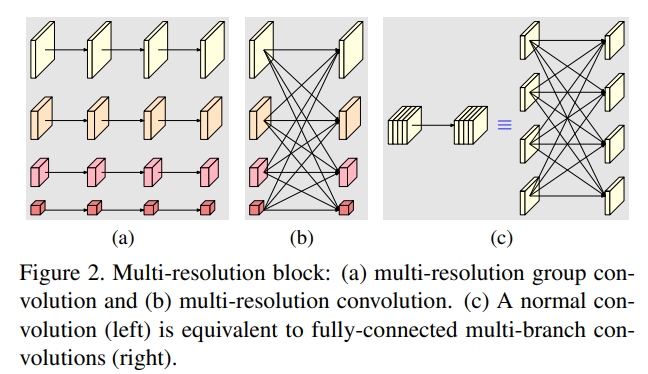
1.3 HRNet
HRNet通过并行多个分辨率的分支,加上不断进行不同分支之间的信息交互,同时达到强语义信息和精准位置信息的目的。在需要精准分割定位的任务中可以取得良好效果

HRNet对尺度间信息通道的看法如下,相比于Nvidia在2020年提出的多尺度attenion 语义分割模型【https://hpg123.blog.csdn.net/article/details/126385231】,在各个支路的forword过程中,持续保证了信息在不同尺度间的流通。
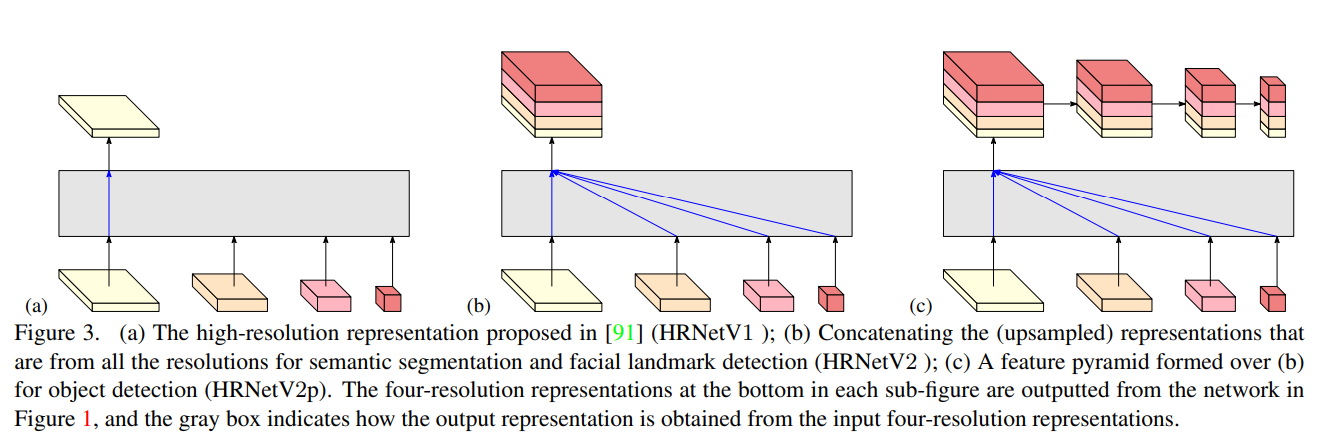
HRNet经历了三个版本的发展,HRNetV1只有顶层支路有输出,HRNetV2的输出concat了4个支路,HRNetV2p为了使用目标检测实现了特征金字塔,将顶层输出由降采样为4个尺度。
Decode相关代码
hardnet作者提出模型时仅用于图像分类训练,paddleseg在使用hardnet做语义分割时,主要是对decode进行了设计,可以看到其实现的解码器,仅是使用HarDBlock实现类似于unet的对称网络。
class Decoder(nn.Layer):
"""The Decoder implementation of FC-HardDNet 70.
Args:
n_blocks (int): The number of blocks in the Encoder module.
in_channels (int): The number of input channels.
skip_connection_channels (tuple|list): The channels of shortcut layers in encoder.
grmul (float): The channel multiplying factor in HarDBlock, which is m in the paper.
gr (tuple|list): The growth rate in each HarDBlock, which is k in the paper.
n_layers (tuple|list): The number of layers in each HarDBlock.
"""
def __init__(self,
n_blocks,
in_channels,
skip_connection_channels,
gr,
grmul,
n_layers,
align_corners=False):
super().__init__()
prev_block_channels = in_channels
self.n_blocks = n_blocks
self.dense_blocks_up = nn.LayerList()
self.conv1x1_up = nn.LayerList()
for i in range(n_blocks - 1, -1, -1):
cur_channels_count = prev_block_channels + skip_connection_channels[
i]
conv1x1 = layers.ConvBNReLU(
cur_channels_count,
cur_channels_count // 2,
kernel_size=1,
bias_attr=False)
blk = HarDBlock(
base_channels=cur_channels_count // 2,
growth_rate=gr[i],
grmul=grmul,
n_layers=n_layers[i])
self.conv1x1_up.append(conv1x1)
self.dense_blocks_up.append(blk)
prev_block_channels = blk.get_out_ch()
self.out_channels = prev_block_channels
self.align_corners = align_corners
def forward(self, x, skip_connections):
for i in range(self.n_blocks):
skip = skip_connections.pop()
x = F.interpolate(
x,
size=paddle.shape(skip)[2:],
mode="bilinear",
align_corners=self.align_corners)
x = paddle.concat([x, skip], axis=1)
x = self.conv1x1_up[i](x)
x = self.dense_blocks_up[i](x)
return x
def get_out_channels(self):
return self.out_channels
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
网络构建代码
通过仔细观察HarDNet中forword流程,可以发现第一步是stem的预处理(包含了一次下采样),关于编码器与解码器的特征连接方式,可以看到是朴素的unet结构,若拓扑结构跟换为unet3+的的形式,HarDNet获取会迎来下一次的飞跃。
class HarDNet(nn.Layer):
"""
[Real Time] The FC-HardDNet 70 implementation based on PaddlePaddle.
The original article refers to
Chao, Ping, et al. "HarDNet: A Low Memory Traffic Network"
(https://arxiv.org/pdf/1909.00948.pdf)
Args:
num_classes (int): The unique number of target classes.
stem_channels (tuple|list, optional): The number of channels before the encoder. Default: (16, 24, 32, 48).
ch_list (tuple|list, optional): The number of channels at each block in the encoder. Default: (64, 96, 160, 224, 320).
grmul (float, optional): The channel multiplying factor in HarDBlock, which is m in the paper. Default: 1.7.
gr (tuple|list, optional): The growth rate in each HarDBlock, which is k in the paper. Default: (10, 16, 18, 24, 32).
n_layers (tuple|list, optional): The number of layers in each HarDBlock. Default: (4, 4, 8, 8, 8).
align_corners (bool): An argument of F.interpolate. It should be set to False when the output size of feature
is even, e.g. 1024x512, otherwise it is True, e.g. 769x769. Default: False.
pretrained (str, optional): The path or url of pretrained model. Default: None.
"""
def __init__(self,
num_classes,
stem_channels=(16, 24, 32, 48),
ch_list=(64, 96, 160, 224, 320),
grmul=1.7,
gr=(10, 16, 18, 24, 32),
n_layers=(4, 4, 8, 8, 8),
align_corners=False,
pretrained=None):
super().__init__()
self.align_corners = align_corners
self.pretrained = pretrained
encoder_blks_num = len(n_layers)
decoder_blks_num = encoder_blks_num - 1
encoder_in_channels = stem_channels[3]
self.stem = nn.Sequential(
layers.ConvBNReLU(
3, stem_channels[0], kernel_size=3, bias_attr=False),
layers.ConvBNReLU(
stem_channels[0],
stem_channels[1],
kernel_size=3,
bias_attr=False),
layers.ConvBNReLU(
stem_channels[1],
stem_channels[2],
kernel_size=3,
stride=2,
bias_attr=False),
layers.ConvBNReLU(
stem_channels[2],
stem_channels[3],
kernel_size=3,
bias_attr=False))
self.encoder = Encoder(encoder_blks_num, encoder_in_channels, ch_list,
gr, grmul, n_layers)
skip_connection_channels = self.encoder.get_skip_channels()
decoder_in_channels = self.encoder.get_out_channels()
self.decoder = Decoder(decoder_blks_num, decoder_in_channels,
skip_connection_channels, gr, grmul, n_layers,
align_corners)
self.cls_head = nn.Conv2D(
in_channels=self.decoder.get_out_channels(),
out_channels=num_classes,
kernel_size=1)
self.init_weight()
def forward(self, x):
input_shape = paddle.shape(x)[2:]
x = self.stem(x)
x, skip_connections = self.encoder(x)
x = self.decoder(x, skip_connections)
logit = self.cls_head(x)
logit = F.interpolate(
logit,
size=input_shape,
mode="bilinear",
align_corners=self.align_corners)
return [logit]
def init_weight(self):
if self.pretrained is not None:
utils.load_entire_model(self, self.pretrained)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
1.4 LinkNet
网络结构如下所示,是一个简单的u型网络。与unet相比就是只是将通道concat更改为add操作,该操作可以一定程度上减少解码过程中的计算量和参数量。网络的编码器从一个stem开始,stem对输入图像进行卷积,其核大小为7×7,步幅为2,该块还在3×3的区域中执行空间最大池化,步幅为2。论文解读:https://hpg123.blog.csdn.net/article/details/125849870
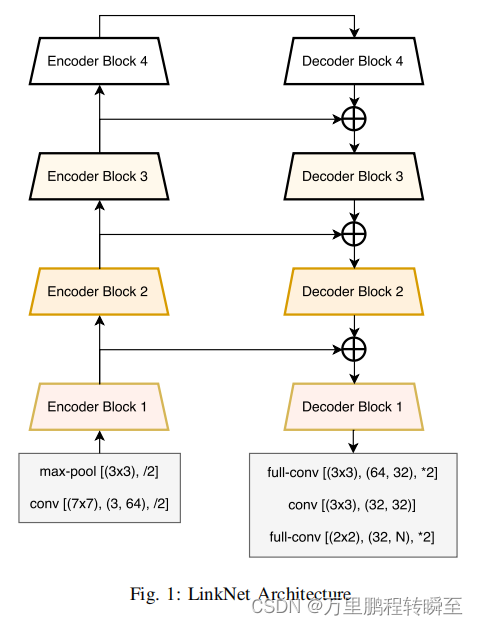
特点
将unet中concat更改为add操作,节省了解码时的计算量和参数量
单个block内跳跃连接,充分利用了resnet的结构
在第一个block前进行4x的下采样,减少了map的size,提升运算速度。
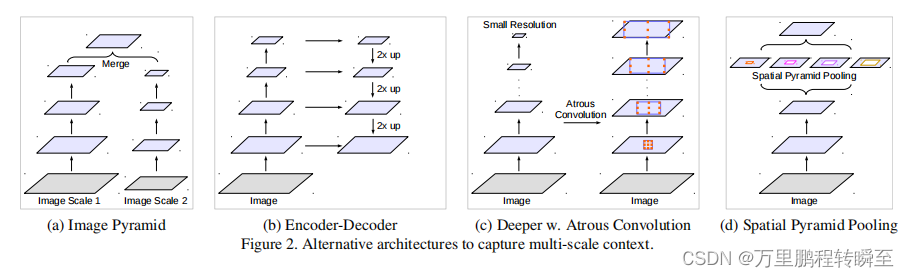
2、特征上下文改进
对于多尺度特征的融合方式,图像金字塔、解码器u网络(使用编码器特征进行跳跃连接)、孔洞卷积、SPP(空间金字塔池化)
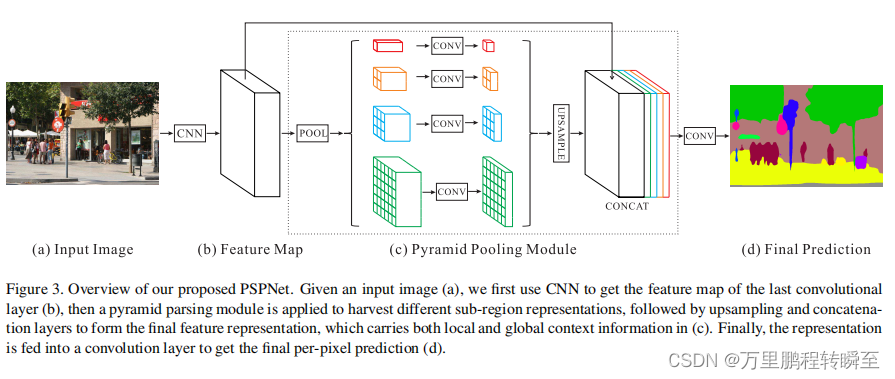
2.1 PSPNet
金字塔场景解析 在四个不同的金字塔尺度下融合特征。用红色突出显示的最粗级别是单个输出的全局池化。下面的金字塔层将特征图划分为不同的子区域,并形成不同位置的集合表示。金字塔池模块中不同级别的输出包含不同大小的特征图。为了保持全局特征的权重,如果金字塔的水平大小为N,在每个金字塔水平后使用1层×1卷积层,将上下文表示的维数降低为原始表示的1/N。然后,直接采样低维特征地图得到相同大小的特征作为原始特征地图通过双线性插值。最后,将不同层次的特征连接为最终的金字塔池全局特征。 内容参考自:https://hpg123.blog.csdn.net/article/details/125810356
金字塔场景解析模块实现代码,模块包含多个pool_scales[预设的pool_scales=(1, 2, 3, 6)],每个pool_scale的信息流程为AdaptiveAvgPool2d[自适应池化,将数据池化到特定size]->ConvModule[conv1x1进行通道间信息融合]->resize[进行上采样]
class PPM(nn.ModuleList):
"""Pooling Pyramid Module used in PSPNet.
Args:
pool_scales (tuple[int]): Pooling scales used in Pooling Pyramid
Module.
in_channels (int): Input channels.
channels (int): Channels after modules, before conv_seg.
conv_cfg (dict|None): Config of conv layers.
norm_cfg (dict|None): Config of norm layers.
act_cfg (dict): Config of activation layers.
align_corners (bool): align_corners argument of F.interpolate.
"""
def __init__(self, pool_scales, in_channels, channels, conv_cfg, norm_cfg,
act_cfg, align_corners, **kwargs):
super(PPM, self).__init__()
self.pool_scales = pool_scales
self.align_corners = align_corners
self.in_channels = in_channels
self.channels = channels
self.conv_cfg = conv_cfg
self.norm_cfg = norm_cfg
self.act_cfg = act_cfg
for pool_scale in pool_scales:
self.append(
nn.Sequential(
nn.AdaptiveAvgPool2d(pool_scale),
ConvModule(
self.in_channels,
self.channels,
1,
conv_cfg=self.conv_cfg,
norm_cfg=self.norm_cfg,
act_cfg=self.act_cfg,
**kwargs)))
def forward(self, x):
"""Forward function."""
ppm_outs = []
for ppm in self:
ppm_out = ppm(x)
upsampled_ppm_out = resize(
ppm_out,
size=x.size()[2:],
mode='bilinear',
align_corners=self.align_corners)
ppm_outs.append(upsampled_ppm_out)
return ppm_outs
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
PSPHead实现代码
@HEADS.register_module()
class PSPHead(BaseDecodeHead):
"""Pyramid Scene Parsing Network.
This head is the implementation of
`PSPNet <https://arxiv.org/abs/1612.01105>`_.
Args:
pool_scales (tuple[int]): Pooling scales used in Pooling Pyramid
Module. Default: (1, 2, 3, 6).
"""
def __init__(self, pool_scales=(1, 2, 3, 6), **kwargs):
super(PSPHead, self).__init__(**kwargs)
assert isinstance(pool_scales, (list, tuple))
self.pool_scales = pool_scales
self.psp_modules = PPM(
self.pool_scales,
self.in_channels,
self.channels,
conv_cfg=self.conv_cfg,
norm_cfg=self.norm_cfg,
act_cfg=self.act_cfg,
align_corners=self.align_corners)
self.bottleneck = ConvModule(
self.in_channels + len(pool_scales) * self.channels,
self.channels,
3,
padding=1,
conv_cfg=self.conv_cfg,
norm_cfg=self.norm_cfg,
act_cfg=self.act_cfg)
def _forward_feature(self, inputs):
"""Forward function for feature maps before classifying each pixel with
``self.cls_seg`` fc.
Args:
inputs (list[Tensor]): List of multi-level img features.
Returns:
feats (Tensor): A tensor of shape (batch_size, self.channels,
H, W) which is feature map for last layer of decoder head.
"""
x = self._transform_inputs(inputs)
psp_outs = [x]
psp_outs.extend(self.psp_modules(x))
psp_outs = torch.cat(psp_outs, dim=1)
feats = self.bottleneck(psp_outs)
return feats
def forward(self, inputs):
"""Forward function."""
output = self._forward_feature(inputs)
output = self.cls_seg(output)
return output
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
2.3 DeepLabv3
标准孔洞卷积
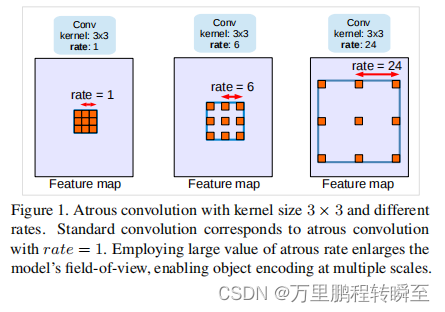
孔洞卷积在模型深处的应用 block5,block6,block7是block4的副本
multi-grid方法:即对block5,block6,block7使用不同的孔洞率。
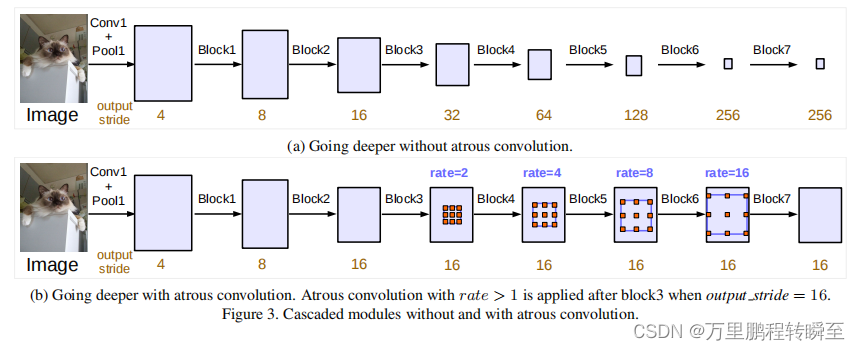
使用孔洞卷积做特征金字塔池化
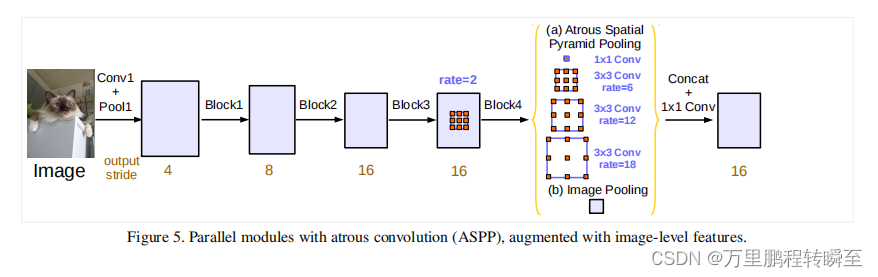
内容参考自:https://hpg123.blog.csdn.net/article/details/125853032
模型评估方法
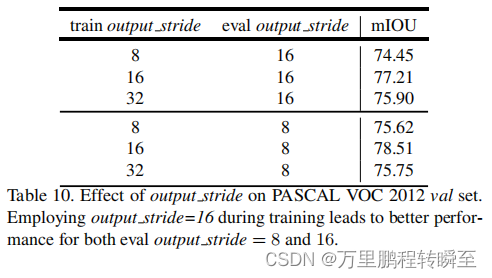
一旦模型被训练好,我们就会在推理过程中应用输出步幅=8。如表6所示,采用输出步幅=8比使用输出步幅=16提高了1.3%,采用多尺度输入和添加左右翻转图像,性能分别进一步提高了0.94%和0.32%。ASPP的最佳模型达到79.77%的性能,优于级联孔洞卷积模块的最佳模型(79.35%),因此选择我们作为最终的模型进行测试集评估。

此外还该文章实验了输出步幅度对miou的影响(resize images评估iou)、batchsize的影响、crop size的影响等实验。
2.3 多尺度attention
多尺度推理是提高语义分割结果的常用方法。多个图像尺度通过网络,然后将结果与平均或最大池化相结合。在这项工作中,NVIDIA提出了一种基于注意力的方法来结合多尺度预测。其所注意力机制是分层的,这使得它的训练效率比其他最近的方法高4倍。在训练过程中,给定的输入图像按因子r进行缩放,其中r=0.5表示2因子的降采样,r=2.0表示2倍的上采样,r=1表示不操作。在训练中,选择了r=0.5和r=1.0。然后将r=1和r=0.5的两幅图像通过共享网络主干通道,产生语义逻辑值L和每个尺度的一个注意掩码(α),用于融合两个尺度之间的语义逻辑值L。在测试阶段,将尺度设为了0.5、1.0、2.0。相比于单尺度训练,多尺度attention的方式节省了大量的训练成本。内容参考自:https://hpg123.blog.csdn.net/article/details/126385231
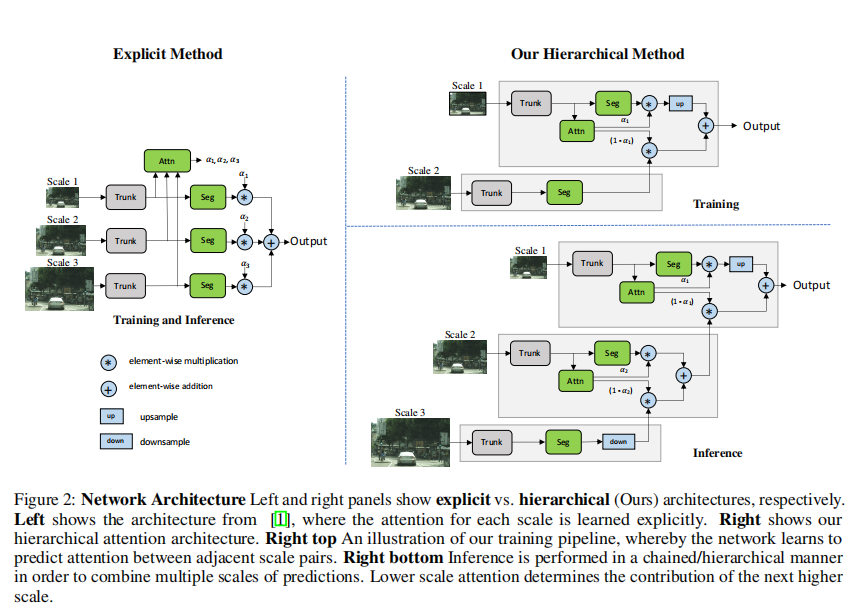
不同尺度的目标,在进行语义分割时,可能需要不同size的输入。其实质在于,在模型的forword流程中,不同尺度输入中,相同位置的conv的感受野不一样。对于大目标,需要缩小尺寸来扩大conv的相对全局感受野(固定深度的conv的感受野是不变的,但是相对于全局的的感受野比例是会变化的);而对于小目标,则需要放大图像size,缩小conv的相对全局感受野,让conv能聚焦到物体内部的信息,忽略掉外部干扰。
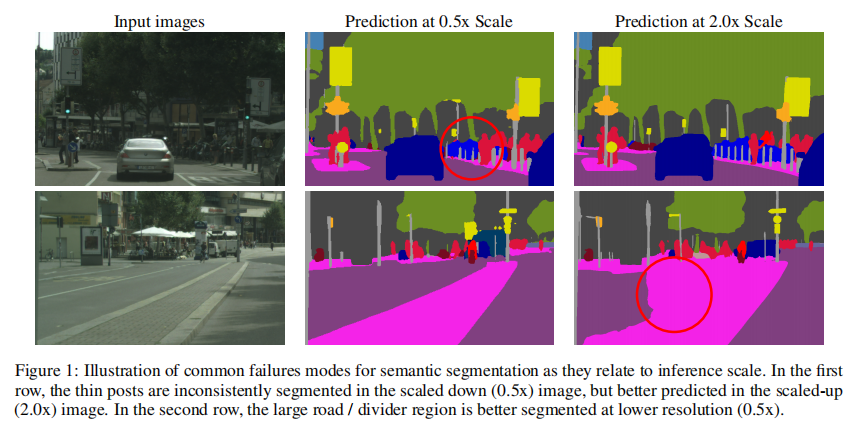
实现过程中潜在的问题
该方法主要是通过将普通语义分割模型转换为孪生网络模型,并在原先的模型上添加spatial attention分支(预测当前尺度下对应位置结果融合的概率)
spatial attention分支所生成的attention map为b,1,w,h即可,作者并未指定spatial attention的实现方式,所以不一定需要安装传统attention中的QVK格式实现(传统格式需要生成b,wxh,wxh的attn_map,会带来巨大的显存需求)。或许,可以使用普通的卷积头来实现这个attention map;也可以使用Criss-Cross Attention或Interlaced Sparse Self-Attention的方式实现attention。关于attention具体可以参考 https://hpg123.blog.csdn.net/article/details/126538242。
3、网络结构上改进
3.1 HarDNet
属于通用性的网络拓扑结构改进,对resnet、densenet中的跳跃连接进行研究,提出低MACs(内存访问成本)和低内存流量的指标需求;并定义了输入/输出(CIO),这是一个简单的关于每个卷积层中输入tensor大小和输出tensor总和,用于近似实际DRAM流量值。使用大量的大型卷积内核可以很容易地实现最小化的CIO。然而,它也降低了计算效率,并最终导致超过增益的显著延迟开销。因此,HarDNet认为保持较高的计算效率仍然是必要的,只有当一个层,MACs超过CIO (MoC),且低于计算平台的某个性能指标下,CIO才能主导推理时间。
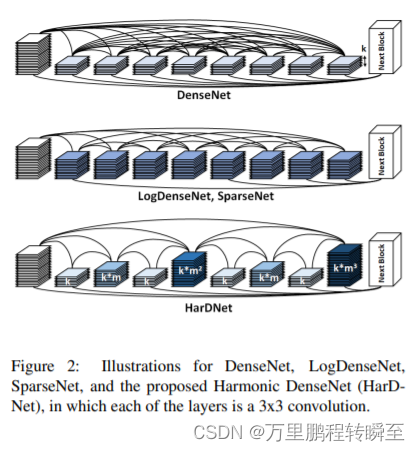
HarDNet是一种通用型的网络拓扑改进,可以用于各种模型。在paddleseg中的轻量化模型中,HarDNet取得了优异的成绩。在paddleseg中给出的精度 vs 速度性能表中,一度超越了SegFormerb1,更多的实验对比细节可以参考https://gitee.com/paddlepaddle/PaddleSeg/blob/release/2.5/docs/model_zoo_overview_cn.md

完整实现代码在https://gitee.com/paddlepaddle/PaddleSeg/blob/release/2.5/paddleseg/models/hardnet.py
3.2 SegFormer
SegFormer将Transformers与轻量级多层感知器(MLP)解码器统一起来。SegFormer有两个吸引人的特点:1)SegFormer包括一个新的层次结构Transformers编码器,输出多尺度特征。它不需要位置编码,从而避免了位置码的插值,当测试分辨率与训练不同时,会导致性能下降。2)SegFormer避免了复杂的解码器。所提出的MLP解码器聚合了来自不同层的信息,从而结合了局部注意和全局注意,呈现出强大的表示。SegFormer论文翻译可以查看:https://hpg123.blog.csdn.net/article/details/126040514
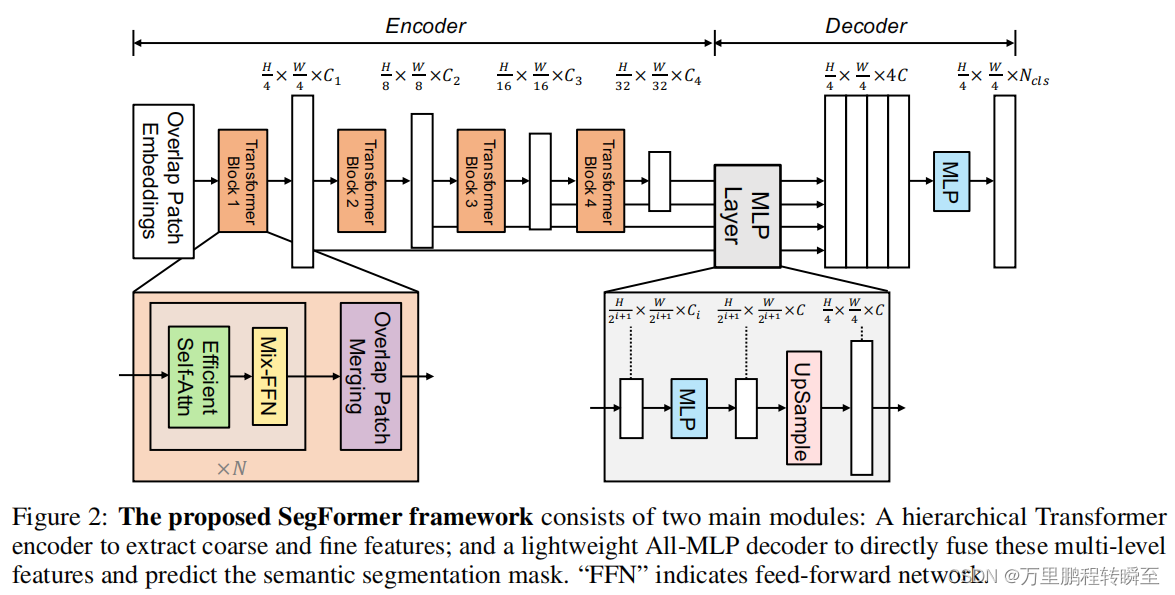
SegFormer使用Overlapped Patch Merging实现图像分辨率的下采样,其具体实现代码如下。其实质就是在进行patch编码时采用stride控制下采样的效果。同时从网络结构图中可以看到,SegFormer中的第一个OverlapPatchEmbed是进行的1/4下采样。
class OverlapPatchEmbed(nn.Layer):
""" Image to Patch Embedding
"""
def __init__(self,
img_size=224,
patch_size=7,
stride=4,
in_chans=3,
embed_dim=768):
super().__init__()
img_size = to_2tuple(img_size)
patch_size = to_2tuple(patch_size)
self.img_size = img_size
self.patch_size = patch_size
self.H, self.W = img_size[0] // patch_size[0], img_size[
1] // patch_size[1]
self.num_patches = self.H * self.W
self.proj = nn.Conv2D(
in_chans,
embed_dim,
kernel_size=patch_size,
stride=stride,
padding=(patch_size[0] // 2, patch_size[1] // 2))
self.norm = nn.LayerNorm(embed_dim)
self.apply(self._init_weights)
def forward(self, x):
x = self.proj(x)
x_shape = paddle.shape(x)
H, W = x_shape[2], x_shape[3]
x = x.flatten(2).transpose([0, 2, 1])
x = self.norm(x)
return x, H, W
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
SegFormer中使用的Efficient Self-Attention与PVT中的spatial-reduction attention是一模一样的[具体参考https://hpg123.blog.csdn.net/article/details/126538242],其通过将K在WH上的的信息移动到channel维度上(通过除以R来实现),减少了K*V进行矩阵乘法时的空间复杂度。第一阶段到第四阶段将R设置为[64,16,4,1]
mmseg中对于SegFormer中Efficient Self-Attention的实现如下,可以看到是通过控制sr_conv的步长来对数据进行压缩,通过该操作可以大幅降低输入KV中数据的大小。
self.sr_ratio = sr_ratio
if sr_ratio > 1:
self.sr = Conv2d(
in_channels=embed_dims,
out_channels=embed_dims,
kernel_size=sr_ratio,
stride=sr_ratio)
#将W*H的数据通过卷积变为(W/sr_ratio)*(H/sr_ratio)
# The ret[0] of build_norm_layer is norm name.
self.norm = build_norm_layer(norm_cfg, embed_dims)[1]
# handle the BC-breaking from https://github.com/open-mmlab/mmcv/pull/1418 # noqa
from mmseg import digit_version, mmcv_version
if mmcv_version < digit_version('1.3.17'):
warnings.warn('The legacy version of forward function in'
'EfficientMultiheadAttention is deprecated in'
'mmcv>=1.3.17 and will no longer support in the'
'future. Please upgrade your mmcv.')
self.forward = self.legacy_forward
def forward(self, x, hw_shape, identity=None):
x_q = x
if self.sr_ratio > 1:
x_kv = nlc_to_nchw(x, hw_shape)
x_kv = self.sr(x_kv)
x_kv = nchw_to_nlc(x_kv)
x_kv = self.norm(x_kv)
else:
x_kv = x
if identity is None:
identity = x_q
# Because the dataflow('key', 'query', 'value') of
# ``torch.nn.MultiheadAttention`` is (num_query, batch,
# embed_dims), We should adjust the shape of dataflow from
# batch_first (batch, num_query, embed_dims) to num_query_first
# (num_query ,batch, embed_dims), and recover ``attn_output``
# from num_query_first to batch_first.
if self.batch_first:
x_q = x_q.transpose(0, 1)
x_kv = x_kv.transpose(0, 1)
out = self.attn(query=x_q, key=x_kv, value=x_kv)[0]
if self.batch_first:
out = out.transpose(0, 1)
return identity + self.dropout_layer(self.proj_drop(out))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
3.3 SegNeXt
SegNeXt是一个简单的用于语义分割的卷积网络架构,通过对传统卷积结构的改进,在一定的参数规模下超越了transformer模型的性能,同等参数规模下在 ADE20K, Cityscapes,COCO-Stuff, Pascal VOC, Pascal Context, 和 iSAID数据集上的miou比transformer模型高2个点以上。其优越之处在对编码器(backbone)的的改进,将transformer中模型的一些特殊结构(将PatchEmbed引入传统卷积、将MLP引入传统卷积)引入了传统卷积中,并提出了MSCAAttention结构,在语义分割中的空间attenion中占据一定优势。参考地址 https://blog.csdn.net/a486259/article/details/129402562
其模型实现代码如下,对语义分割中特征提取未做过多研究,仅是堆叠OverlapPatchEmbed与MSCAN模块所实现。在特征融合时,也就是类似SegFormer一样,级联了3个尺度的特征图。使用了轻量级的Hamburger来进一步建模全局上下文。
@ BACKBONES.register_module()
class MSCAN(BaseModule):
def __init__(self,
in_chans=3,
embed_dims=[64, 128, 256, 512],
mlp_ratios=[4, 4, 4, 4],
drop_rate=0.,
drop_path_rate=0.,
depths=[3, 4, 6, 3],
num_stages=4,
norm_cfg=dict(type='SyncBN', requires_grad=True),
pretrained=None,
init_cfg=None):
super(MSCAN, self).__init__(init_cfg=init_cfg)
assert not (init_cfg and pretrained), \
'init_cfg and pretrained cannot be set at the same time'
if isinstance(pretrained, str):
warnings.warn('DeprecationWarning: pretrained is deprecated, '
'please use "init_cfg" instead')
self.init_cfg = dict(type='Pretrained', checkpoint=pretrained)
elif pretrained is not None:
raise TypeError('pretrained must be a str or None')
self.depths = depths
self.num_stages = num_stages
dpr = [x.item() for x in torch.linspace(0, drop_path_rate,
sum(depths))] # stochastic depth decay rule
cur = 0
for i in range(num_stages):
if i == 0:
patch_embed = StemConv(3, embed_dims[0], norm_cfg=norm_cfg)
else:
patch_embed = OverlapPatchEmbed(patch_size=7 if i == 0 else 3,
stride=4 if i == 0 else 2,
in_chans=in_chans if i == 0 else embed_dims[i - 1],
embed_dim=embed_dims[i],
norm_cfg=norm_cfg)
block = nn.ModuleList([Block(dim=embed_dims[i], mlp_ratio=mlp_ratios[i],
drop=drop_rate, drop_path=dpr[cur + j],
norm_cfg=norm_cfg)
for j in range(depths[i])])
norm = nn.LayerNorm(embed_dims[i])
cur += depths[i]
setattr(self, f"patch_embed{i + 1}", patch_embed)
setattr(self, f"block{i + 1}", block)
setattr(self, f"norm{i + 1}", norm)
def forward(self, x):
B = x.shape[0]
outs = []
for i in range(self.num_stages):
patch_embed = getattr(self, f"patch_embed{i + 1}")
block = getattr(self, f"block{i + 1}")
norm = getattr(self, f"norm{i + 1}")
x, H, W = patch_embed(x)
for blk in block:
x = blk(x, H, W)
x = norm(x)
x = x.reshape(B, H, W, -1).permute(0, 3, 1, 2).contiguous()
outs.append(x)
return outs
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
SegNeXT在内存上的消耗是巨大的,虽然其在flop上占据优势,但在训练与部署上并不占据优势。博主使用MSCAN-S简单进行训练测试,发现加载模型后显存消耗650MiB,对单个512x512 的图像进行forword后显存消耗为2315MiB,对512x512的图像进行训练,batchsize为8时显存为1200MiB。这种规模的内存消耗对于工程实践而言简直是灾难性的,从内存消耗与网络结构上看,应该是全连接所导致的。随后通过分析代码,发现就是MLP层中dwconv所导致的,其所包含的全连接有[64, 128, 256, 512]x4 ,其中最大的全连接层为2048*2048,参数量极为庞大。
(mlp): Mlp(
(fc1): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1))
(dwconv): Conv2d(2048, 2048, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=2048)
(act): GELU()
(fc2): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1))
(drop): Dropout(p=0.0, inplace=False)
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8

