
- 1语言模型在知识图谱与问答系统中的应用
- 2RabbitMQ 和 RocketMQ对比_rabbitm和rockmq对比
- 3Hugging Face让我们人手一个AutoGPT,Hugging Face模型大集合,端到端开发框架transformers-agent,对标LangChain_huggingface 代理
- 4Bug小能手系列(python)_7: BertTokenizer报错 Connection reset by peer_can't load tokenizer for 'bert-base-uncased'. if y
- 5【机器学习】数据探索---python主要的探索函数
- 6ACL 2021 | 北京大学KCL实验室:如何利用双语词典增强机器翻译?
- 7DiT: Self-supervised Pre-training for Document Image Transformer论文阅读笔记
- 8The Era of 1-bit LLMs
- 9MMEngine之介绍、结构、应用示例、常见用法(一)
- 10Transformer原理与代码实现_transformer代码实现
用Python实现《沉默的真相》3万+弹幕情感分析!简单!
赞
踩
以前我写过不少文本数据分析,比如《八佰》影评分析、《三十而已》热评分析等,但基本停留在可视化分析层面。本文将运用文本挖掘技术,对最近热播剧《沉默的真相》弹幕数据进行深入分析,希望对大家有一定的启发。
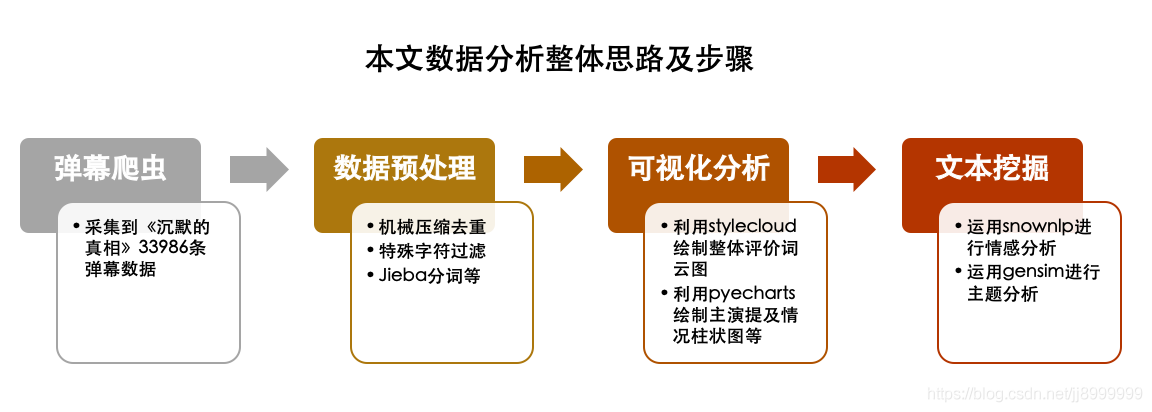
本文数据分析思路及步骤如下图所示,阅读本文需要10min,您可在「菜J学Python」公众号后台回复文本挖掘获取弹幕数据进行测试。
PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取
一、数据获取
如果您对弹幕数据采集感兴趣,可查看J哥往期原创文章「弹幕爬虫,看这一篇就够了!」,本文仅提供核心代码:
from xml.dom.minidom import parse
import xml.dom.minidom
def xml_parse(file_name):
DOMTree = xml.dom.minidom.parse(file_name)
collection = DOMTree.documentElement
# 在集合中获取所有entry数据
entrys = collection.getElementsByTagName("entry")
print(entrys)
result = []
for entry in entrys:
content = entry.getElementsByTagName('content')[0]
print(content.childNodes[0].data)
i = content.childNodes[0].data
name = entry.getElementsByTagName('name')[0]
print(name.childNodes[0].data)
j = name.childNodes[0].data
dd = [j,i]
result.append(dd)
print(result)
return result
二、数据清洗
1.导入数据分析库
#数据处理库 import numpy as np import pandas as pd import glob import re import jieba #可视化库 import stylecloud import matplotlib.pyplot as plt import seaborn as sns %matplotlib inline from pyecharts.charts import * from pyecharts import options as opts from pyecharts.globals import ThemeType from IPython.display import Image #文本挖掘库 from snownlp import SnowNLP from gensim import corpora,models
2.合并弹幕数据
《沉默的真相》共12集,分集爬取,共生成12个csv格式的弹幕数据文件,保存在danmu文件夹中。通过glob方法遍历所有文件,读取数据并追加保存到danmu_all文件中。
csv_list = glob.glob('/菜J学Python/danmu/*.csv')
print('共发现%s个CSV文件'% len(csv_list))
print('正在处理............')
for i in csv_list:
fr = open(i,'r').read()
with open('danmu_all.csv','a') as f:
f.write(fr)
print('合并完毕!')
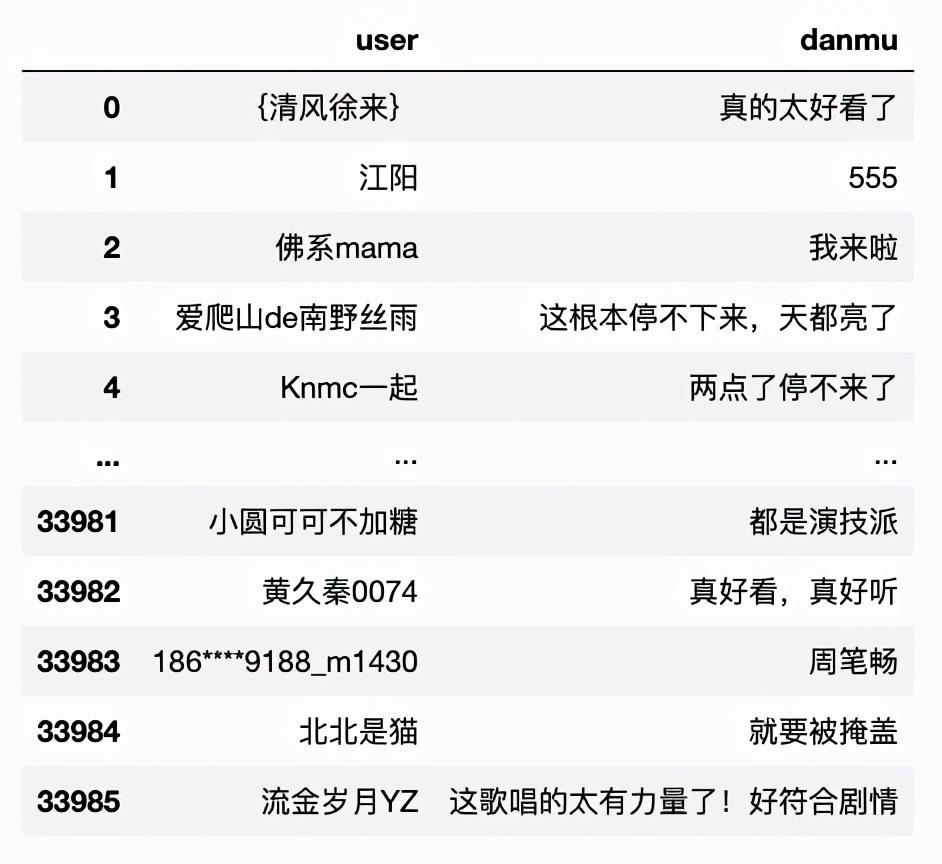
3.重复值、缺失值等处理
#error_bad_lines参数可忽略异常行
df = pd.read_csv("./danmu_all.csv",header=None,error_bad_lines=False)
df = df.iloc[:,[1,2]] #选择用户名和弹幕内容列
df = df.drop_duplicates() #删除重复行
df = df.dropna() #删除存在缺失值的行
df.columns = ["user","danmu"] #对字段进行命名
df
清洗后数据如下所示:
4.机械压缩去重
机械压缩去重即数据句内的去重,我们发现弹幕内容存在例如"啊啊啊啊啊"这种数据,而实际做情感分析时,只需要一个“啊”即可。

#定义机械压缩去重函数
def yasuo(st):
for i in range(1,int(len(st)/2)+1):
for j in range(len(st)):
if st[j:j+i] == st[j+i:j+2*i]:
k = j + i
while st[k:k+i] == st[k+i:k+2*i] and k<len(st):
k = k + i
st = st[:j] + st[k:]
return st
yasuo(st="啊啊啊啊啊啊啊")
应用以上函数,对弹幕内容进行句内去重。
df["danmu"] = df["danmu"].apply(yasuo) 1
5.特殊字符过滤
另外,我们还发现有些弹幕内容包含表情包、特殊符号等,这些脏数据也会对情感分析产生一定影响。

特殊字符直接通过正则表达式过滤,匹配出中文内容即可。
df['danmu'] = df['danmu'].str.extract(r"([\u4e00-\u9fa5]+)") df = df.dropna() #纯表情直接删除 12
另外,过短的弹幕内容一般很难看出情感倾向,可以将其一并过滤。
df = df[df["danmu"].apply(len)>=4] df = df.dropna()
三、数据可视化
数据可视化分析部分代码本公众号往期原创文章已多次提及,本文不做赘述。从可视化图表来看,网友对《沉默的真相》还是相当认可的,尤其对白宇塑造的正义形象江阳,提及频率远高于其他角色。
1.整体弹幕词云

2.主演提及

四、文本挖掘(NLP)
1.情感分析
情感分析是对带有感情色彩的主观性文本进行分析、处理、归纳和推理的过程。按照处理文本的类别不同,可分为基于新闻评论的情感分析和基于产品评论的情感分析。其中,前者多用于舆情监控和信息预测,后者可帮助用户了解某一产品在大众心目中的口碑。目前常见的情感极性分析方法主要是两种:基于情感词典的方法和基于机器学习的方法。
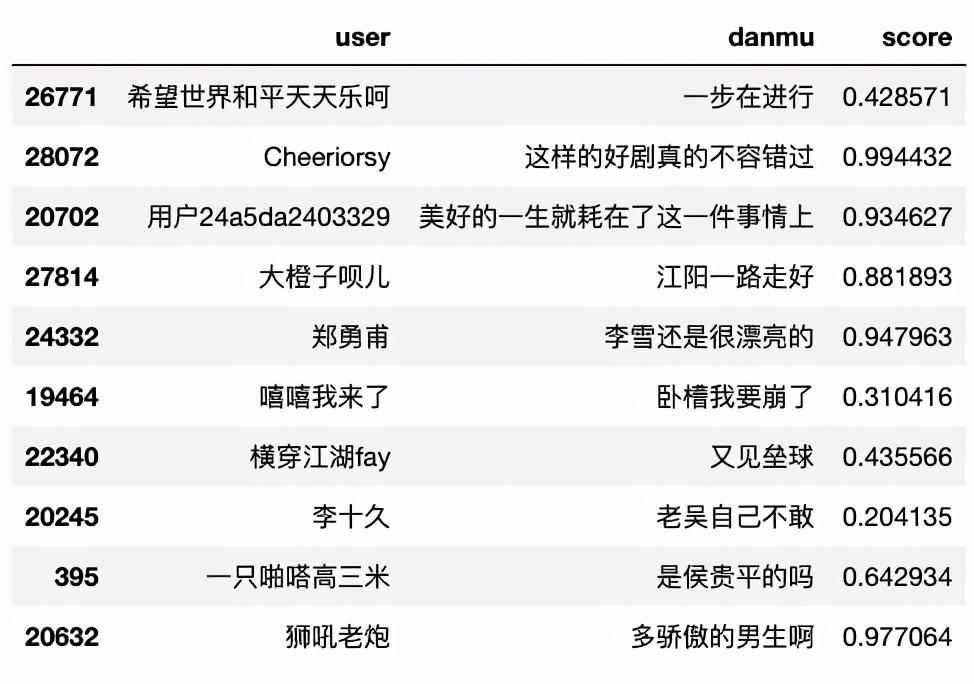
本文主要运用Python的第三方库SnowNLP对弹幕内容进行情感分析,使用方法很简单,计算出的情感score表示语义积极的概率,越接近0情感表现越消极,越接近1情感表现越积极。
df['score'] = df["danmu"].apply(lambda x:SnowNLP(x).sentiments) df.sample(10) #随机筛选10个弹幕样本数据 12
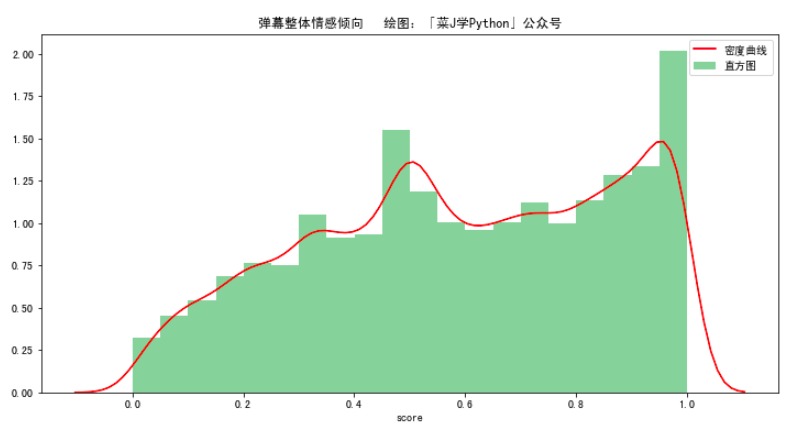
(1)整体情感倾向
plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置加载的字体名
plt.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
plt.figure(figsize=(12, 6)) #设置画布大小
rate = df['score']
ax = sns.distplot(rate,
hist_kws={'color':'green','label':'直方图'},
kde_kws={'color':'red','label':'密度曲线'},
bins=20) #参数color样式为salmon,bins参数设定数据片段的数量
ax.set_title("弹幕整体情感倾向 绘图:「菜J学Python」公众号")
plt.show
12345678910
(2)观众对主演的情感倾向
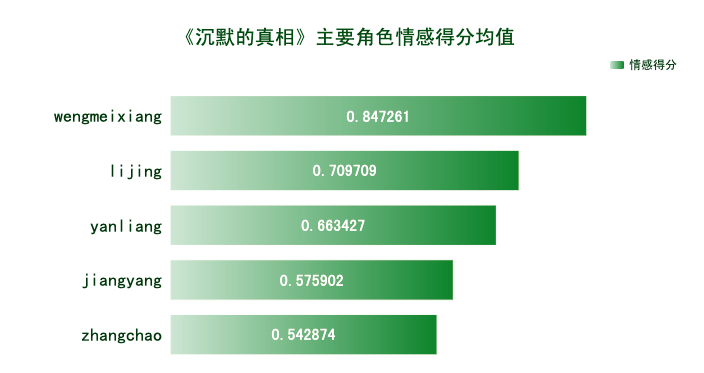
mapping = {'jiangyang':'白宇|江阳', 'yanliang':'廖凡|严良', 'zhangchao':'宁理|张超','lijing':'谭卓|李静', 'wengmeixiang':'李嘉欣|翁美香'}
for key, value in mapping.items():
df[key] = df['danmu'].str.contains(value)
average_value = pd.Series({key: df.loc[df[key], 'score'].mean() for key in mapping.keys()})
print(average_value.sort_values())
12345
由各主要角色情感得分均值可知,观众对他们都表现出积极的情感。翁美香和李静的情感得分均值相对高一些,难道是男性观众偏多?江阳的情感倾向相对较低,可能是观众对作为正义化身的他惨遭各种不公而鸣不平吧。
2.主题分析
这里的主题分析主要是将弹幕情感得分划分为两类,分别为积极类(得分在0.8以上)和消极类(得分在0.3以下),然后再在各类里分别细分出5个主题,有助于挖掘出观众情感产生的原因。
首先,筛选出两大类分别进行分词。
#分词
data1 = df['danmu'][df["score"]>=0.8]
data2 = df['danmu'][df["score"]<0.3]
word_cut = lambda x:' '.join(jieba.cut(x)) #以空格隔开
data1 = data1.apply(word_cut)
data2 = data2.apply(word_cut)
print(data1)
print('----------------------')
print(data2)
123456789
首先,筛选出两大类分别进行分词。
#去除停用词
stop = pd.read_csv("/菜J学Python/stop_words.txt",encoding='utf-8',header=None,sep='tipdm')
stop = [' ',''] + list(stop[0])
#print(stop)
pos = pd.DataFrame(data1)
neg = pd.DataFrame(data2)
pos["danmu_1"] = pos["danmu"].apply(lambda s:s.split(' '))
pos["danmu_pos"] = pos["danmu_1"].apply(lambda x:[i for i in x if i.encode('utf-8') not in stop])
#print(pos["danmu_pos"])
neg["danmu_1"] = neg["danmu"].apply(lambda s:s.split(' '))
neg["danmu_neg"] = neg["danmu_1"].apply(lambda x:[i for i in x if i.encode('utf-8') not in stop])
1234567891011121314
其次,对积极类弹幕进行主题分析。
#正面主题分析
pos_dict = corpora.Dictionary(pos["danmu_pos"]) #建立词典
#print(pos_dict)
pos_corpus = [pos_dict.doc2bow(i) for i in pos["danmu_pos"]] #建立语料库
pos_lda = models.LdaModel(pos_corpus,num_topics=5,id2word=pos_dict) #LDA模型训练
print("正面主题分析:")
for i in range(5):
print('topic',i+1)
print(pos_lda.print_topic(i)) #输出每个主题
print('-'*50)
12345678910
结果如下:

最后,对消极类弹幕进行主题分析。
#负面主题分析
neg_dict = corpora.Dictionary(neg["danmu_neg"]) #建立词典
#print(neg_dict)
neg_corpus = [neg_dict.doc2bow(i) for i in neg["danmu_neg"]] #建立语料库
neg_lda = models.LdaModel(neg_corpus,num_topics=5,id2word=neg_dict) #LDA模型训练
print("负面面主题分析:")
for j in range(5):
print('topic',j+1)
print(neg_lda.print_topic(j)) #输出每个主题
print('-'*50)
12345678910
结果如下:

四、总结
本文较为系统的分析了《沉默的的真相》3万+弹幕数据,但由于snownlp对商品评论做文本挖掘更有效,您也可以尝试用百度AI和腾讯AI进行情感分析,分析的结构可能更有效一些。

