
- 1深度学习进阶篇-国内预训练模型[5]:ERINE、ERNIE 3.0、ERNIE-的设计思路、模型结构、应用场景等详解_ernie-gram比ernie的优势
- 2CNN-GRU-SAM-Attention分类|基于卷积神经网络结合门控循环单元-空间注意力机制多特征分类预测附matlab代码_门控图卷积神经网络
- 3如何使用Vite打包和部署项目到服务器二级路由_vite配置打包路径
- 4【rpm】源码包制作rpm包|修改rpm、重新制作rpm包_linux rpm封装的时候图标路径怎么修改
- 5JavaScript面试题总结(全面)
- 6估算 ASM 重新平衡操作成本_oracle asm均衡阶段
- 7Android 上百实例源码分析以及开源分析_安卓游戏源代码
- 8自学历程-AutoDL服务器训练YOLOv8_yologaijin
- 9微信小程序实现客服默认自动回复功能_小程序客服 玩家点击后自动发送客服消息
- 10Android studio关于External Libraries中重复包的删除和恢复_android studio external libraries
自然语言处理(期末考点)_自然语言处理期末考试
赞
踩
IDLE的两种使用方式:交互式和文件式
缩进是Python语法的一部分
注释有两种:单行注释和多行注释
逻辑运算符:and, or, not
赋值运算符:=
算术运算符:+, -, *, /, //, **, %
关系运算符:>, >=, <, <=, ==, !=
位运算符:<< 左移, >> 右移, & 按位与, | 按位或, ^ 按位异或, ^ 按位取反
数值型:整数、浮点数、复数
序列类型:字符串str, 列表list, 元组tuple
布尔型:True和False
集合set
映射型:字典dict
顺序结构的三种用法:
1)单分支 if ...
2)双分支 if ... else ...
3)多分支 if ... elif ... elif ... else ...
循环结构:for和while
for:适用于循环次数已知的情况
while:适用于循环次数未知的情况
range(start, stop, step)
break:结束当前循环
continue:跳过当前循环中的剩余语句,继续下一轮循环
使用def定义函数
变量分为全局变量和局部变量
函数的返回值return
匿名函数lambda
递归函数:自己调用自己
数据分析与可视化常用的四个库:NumPy, SciPy, Pandas和Matplotlib
创建NumPy数组的四种方法:
np.array()
np.arange()
np.linspace()等差数列
np.logspace()等比数列
Pandas两个重要的数据结构:
Series序列
DataFrame数据框架
数据集分为:
小数据集
大数据集
生成数据集
7个小数据集:
波士顿房屋价格load_boston
糖尿病load_diabetes
手写数字load_digits
乳腺癌load_breast_cancer
鸢尾花load_iris
葡萄酒load_wine
体能训练load_linnerud
数据集的划分:
数据集 = 训练集 + 测试集
训练集用于训练并生成机器学习模型
测试集用于验证模型的效果
特征预处理的方法:
归一化preprocessing.MinMaxScaler
标准化preprocessing.StandardScaler
鲁棒化preprocessing.RobustScaler
正则化preprocessing.Normalize
独热编码OneHotEncoder
TF-IDF词频-逆文档频率
NLTK = natural language toolkit自然语言处理工具包
NLTK被称为“用自然语言进行游戏的神奇图书馆”
中文情感分析的类库SnowNLP和Gensim
英文情感分析的类库textblob
中文分词使用jieba库
jieba.cut()得到生成器
jieba.cut(txt, cut_all=True)全模式
jieba.cut(txt, cut_all=False)精确模式
jieba.cut_for_search(txt)搜索引擎模式
jieba.lcut()得到列表,用法与jieba.cut()相同
降维技术PCA
PCA = Principal Component Analysis主成分分析
pca = PCA(n_components=n)
n可以是整数,代表保留的主分量个数
n也可以是0到1之间的浮点数,代表保留的方差比
中文分词可以使用的库jieba和HanLP
文档向量化使用CountVectorizer和DictVectorizer
评价分类器性能的指标:
混淆矩阵
准确率Accuracy
精确率Precision
召回率Recall
F1值
ROC曲线(受试者工作特征Receiver Operating Characteristic)
AUC面积(Area Under Curver,ROC曲线下的面积)
衡量聚类性能的评价指标:
调整兰德系数ARI(Adjusted Rand Index),[-1, 1],值越大意味着聚类结果与真实情况越吻合
轮廓系数(Silhouette Coefficient),[-1, 1],数值越大,聚类效果越好
提供以下三个数据集,大家随意发挥,得到一个有趣的结果即可
刘慈欣《三体》,“santi.txt”
1999年全国31个省份城镇居民家庭平均每人全年消费性支出,“1999年全国31个省份城镇居民家庭平均每人全年消费性支出.csv”
加州住房数据集,“housing.csv”
下面简单介绍加州住房数据集(California Housing):
加州住房数据集包含的所有属性,如下表所示
| 属性名 | 属性值的类型 | 说明 |
| longitude | 浮点数 | 街区的经度 |
| latitude | 浮点数 | 街区的纬度 |
| housing_median_age | 浮点数 | 房龄中位数 |
| total_rooms | 浮点数 | 房间总数 |
| total_bedrooms | 浮点数 | 卧室总数 |
| population | 浮点数 | 人口数量 |
| households | 浮点数 | 家庭数量 |
| median_income | 浮点数 | 收入中位数 |
| median_house_value | 浮点数 | 房价中位数 |
| ocean_proximity | object | 是否靠海 |
读取数据集:
>>> import pandas as pd 别名
>>> housing = pd.read_csv('housing.csv')
查看数据集:head()方法在默认情况下读取数据集的前五行。
每一行代表一个街区,总共有10个属性。数据集包含20 640个街区,即20 640个实例。
info()方法可以快速给出数据集的简单描述,具体包括:总行数、所有的属性名及其对应的值类型、非空值的数量等。
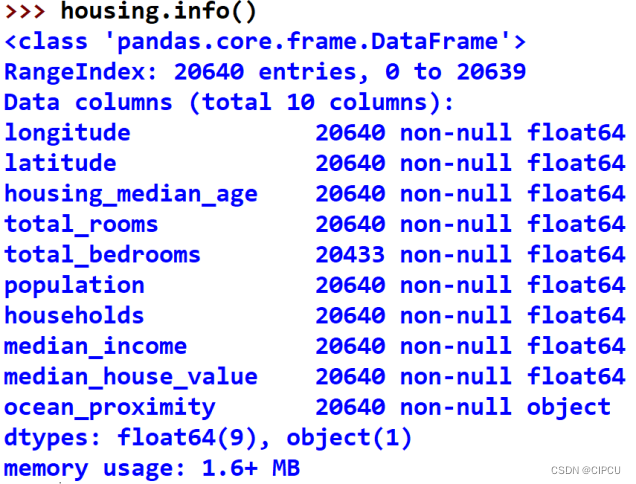
由上述信息可知,属性total_bedrooms的非空值有20433个,即空值有20640-20433=207个。
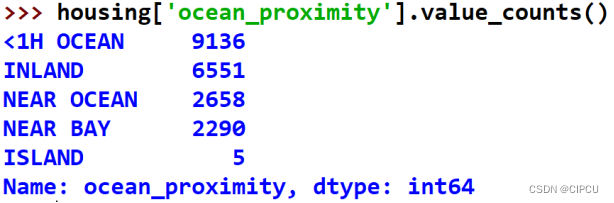
value_counts()方法:统计一个属性取各个属性值的次数。通常是在一个具体的属性上使用该方法,特别是离散值属性,比如下面的文本属性ocean_proximity。
describe()方法给出数值属性的摘要信息。下面以属性total_rooms为例。

上述计算过程忽略空值。在total_rooms属性上,describe()方法给出了下列信息:
- 属性值为非空的个数count;
- 属性值的平均数mean;
- 属性值的标准差std;
- 属性值的最小值min;
- 属性值的最大值max;
- 25%-百分之二十五分位数(第一四分位数);
- 50%-中位数;
- 75%-百分之七十五分位数(第三四分位数)。
第一四分位数表示有25%的街区,其房间总数total_rooms少于1447.75,以此类推其它分位数代表的含义。另外,也可以在整个数据集上使用describe()方法。

