
- 1GoLang之再谈Gvim/Vim配置——使用Vundle安装vim-go_gvim 配置vim-go
- 2全网最详细中英文ChatGPT-GPT-4示例文档-自然语言智能转换SQL请求语句从0到1快速入门——官网推荐的48种最佳应用场景(附python/node.js/curl命令源代码,小白也能学)_chatgtp 自然语言转sql
- 3Redis 过期删除策略和内存淘汰策略
- 4『关键词挖掘』结合 LDA + Word2Vec + TextRank 实现关键词的挖掘_lda+word2vec
- 5priority_queue 的常见用法详解_priority_queue用法
- 6电话机器人核心技术之NLP_freeswitch 对话机器人
- 7基于英特尔OpenAI实现神经网络图像分类算法_openai 图像识别
- 8分布式软总线——服务发布
- 9HanLP使用教程——NLP初体验_hanlp小白教程
- 10[Python] RuntimeError: Invalid DISPLAY variable
【目标检测经典模型比较】--YOLOv1、v2、v3、v4、v5、x、v7、v8_yolo系列哪个最好
赞
踩
YOLOv1、v3、v5、v7、v8
1.YOLO(2015)

结构
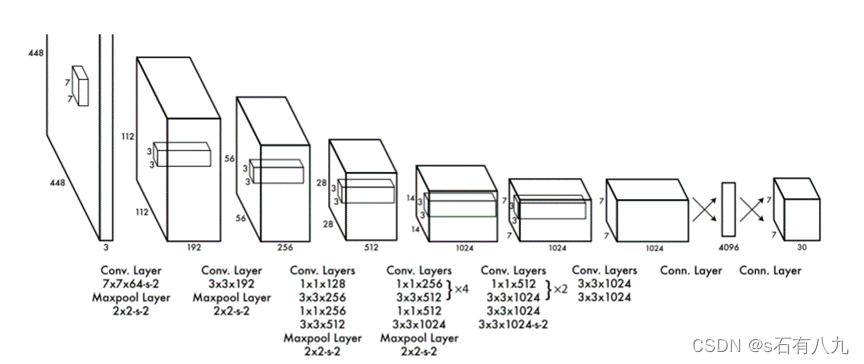
YOLO检测网络包括24个卷积层和2个全连接层
其中,卷积层用来提取图像特征,全连接层用来预测图像位置和类别概率值。
- YOLO网络借鉴了GoogLeNet分类网络结构。不过使用1x1卷积层(此处1x1卷积层的存在是为了跨通道信息整合)+3x3卷积层简单替代。
- YOLO论文中,作者还给出一个更轻快的检测网络fast YOLO,它只有9个卷积层和2个全连接层。
- Loss函数使用均方和误差,即网络输出的SxSx(Bx5 + C)维向量与真实图像的对应SxSx(Bx5 + C)维向量的均方和误差。
coordError、iouError和classError分别代表预测数据与标定数据之间的坐标误差、IOU误差和分类误差。
训练:
batchsize=64 momentum=0.9 decay=0.0005 前期:learning rate= 10−3 to 10−2.后期10−2训练75个epoch,然后用10−3训练30个epoch,最后用10−4训练30个epoch。dropout layer with rate =0.5 数据增强:20%的随机缩放和平移,随机调整曝光和饱和度的图像在HSV颜色空间的一个因子1.5
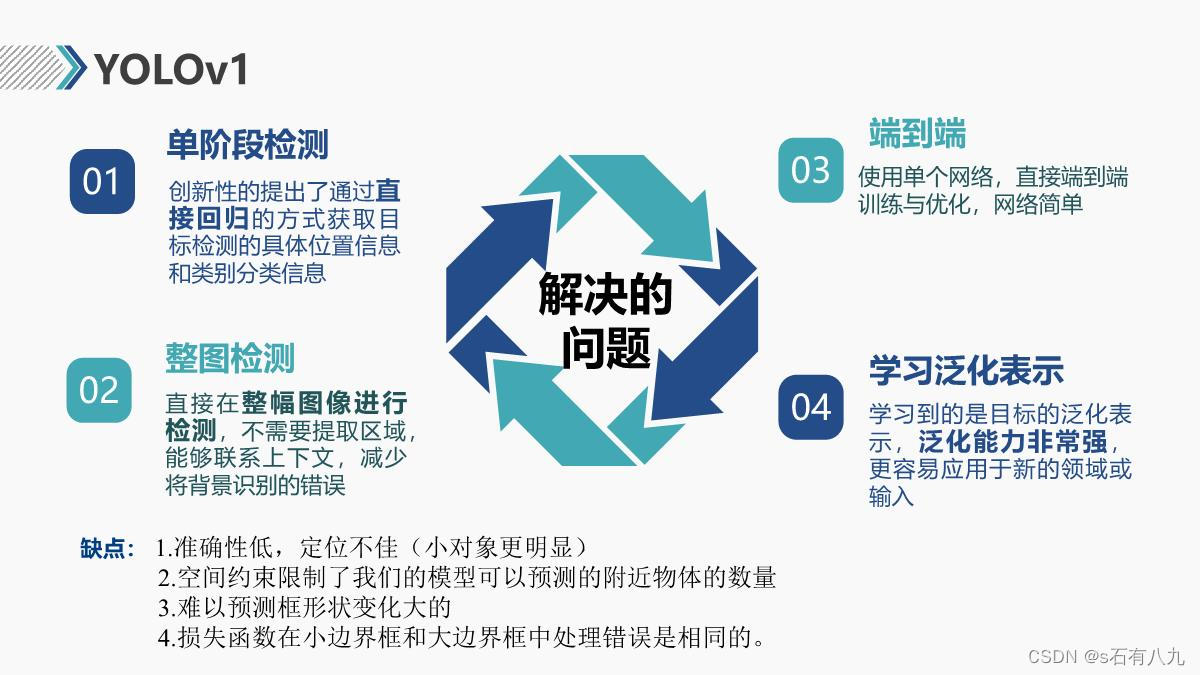
优点:
- 速度快,将检测视为回归问题(平均精度也高)
- 对图像进行全局推理,关联背景上下文(背景错误少)
- 学习对象的通用模式(相当于模板),推广性强
缺点:
- 准确性低,定位不佳(小对象更明显)
- 空间约束限制了我们的模型可以预测的附近物体的数量
- 难以预测框形状变化大的
- 损失函数在小边界框和大边界框中处理错误是相同的。
2.YOLOv2(2016) YOLO9000: Better, Faster, Stronger
1. 结构
数据集:ImageNet的9000多个类
yolov2主要集中在提高召回率和定位,同时保持分类准确性。
Yolov2训练策略:
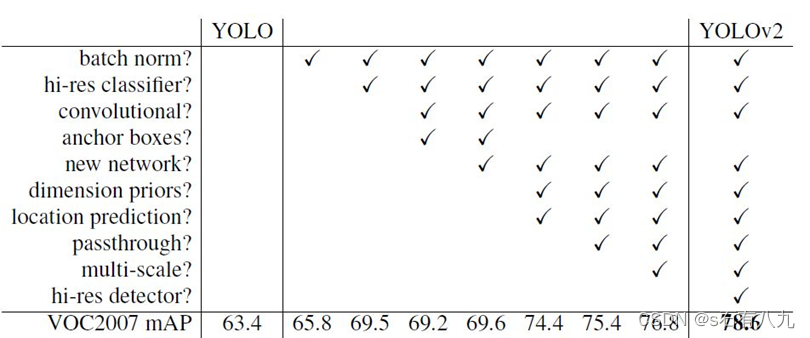
在YOLO中的所有卷积层上添加批量归一化。删去全连接层,并使用锚框来预测边界框。k-means生成边界框,使用维度聚类直接预测边界框中心位置。添加一个passthrough层,使26×26×512的特征图得到1×26×512。采用多尺度输入训练策略,输入图片大小选择一系列为32倍数的值: 320,352,…608
模型称为Darknet-19,有19个卷积层和5个maxpooling层。
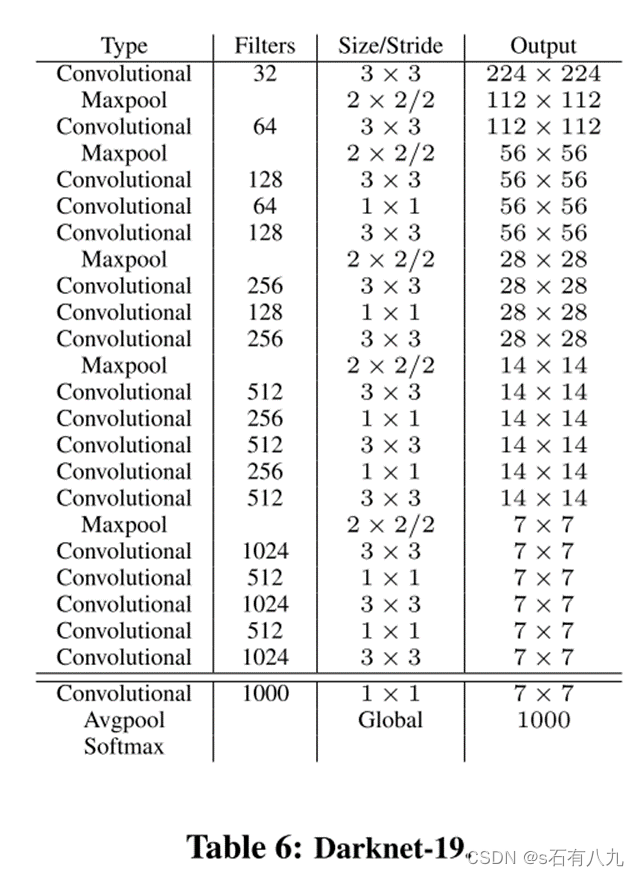
使用WordTree层次结构组合数据集。
损失函数包含两部分: 分类损失Softmax和回归损失Smooth L1
优点:
1.精度提高,检测准确率比YOLOv1高。
2.速度更快,可达到更高的实时性能。
3.使用了batch normalization技术,可以减轻过拟合问题。
缺点:
1.一个分类器只能检测固定数量的物体,无法处理可变数量的物体。
2.训练和调整模型需要更多的计算资源和时间
3.学习检测设备和服饰表现差
3.YOLOv3(2018)

YOLOv3是一种基于深度学习的目标检测算法,它是在YOLOv2的基础上进行了改进和优化,提高了检测的准确度和速度。YOLOv3解决的问题主要有以下几个方面:
• 提高小目标的检测能力。 YOLOv3采用了多尺度预测的方式,使用了三种不同大小的特征图,分别负责检测大、中、小的目标。这样可以增加小目标的感受野,提高小目标的定位和分类效果
• 增加网络的深度和宽度。 YOLOv3使用了Darknet-53作为骨干网络,它是一个由残差模块组成的深层网络,具有较强的特征提取能力。同时,YOLOv3也增加了每个网格单元预测的边框数量,从YOLOv2的5个增加到了3个,这样可以增加网络的表达能力和泛化能力
• 改进边框预测和类别预测。 YOLOv3对边框预测和类别预测进行了一些改进,例如使用logistic回归代替softmax进行多标签分类,使用二值交叉熵代替平方误差进行置信度损失计算,使用k-means聚类代替手动设置进行锚框设计等。这些改进可以提高网络的稳定性和鲁棒性
特征提取器是一个残差模型,因为包含53个卷积层,所以称为Darknet-53。采用类FPN架构来实现多尺度检测。YOLOv3采用了3个尺度的特征图(当输入为416*416时):(13*13),(26*26), (52*52)。使用binary cross-entropy loss分类器。
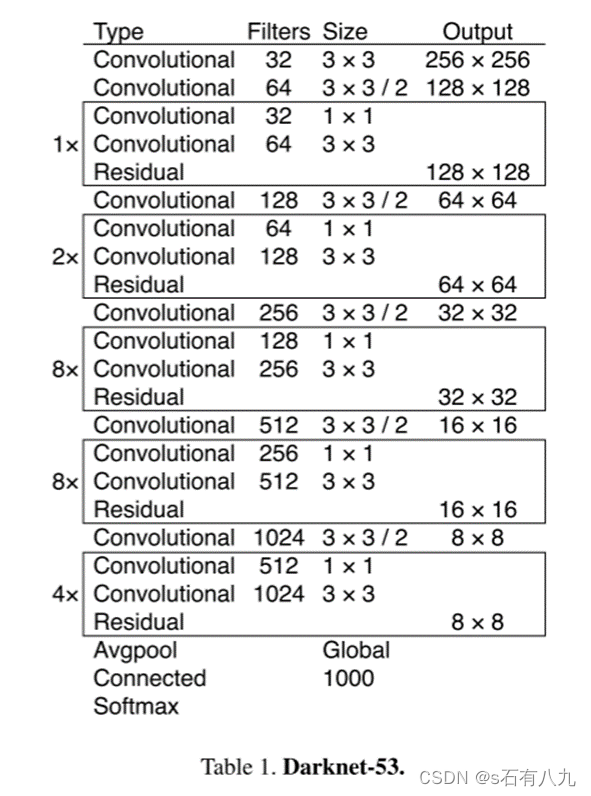
YOLOv3 的 neck 输出 3 个分支,即输出 3 个特征图, head 模块只有一个分支,由卷积层组成,该卷积层完成目标分类和位置回归的功能。总的来说,YOLOv3 网络的 3 个特征图有 3 个预测分支,分别预测 3 个框,也就是分别预测大、中、小目标。
优点:
1.快速
2.背景误检率低
3.通用性强
缺点:
1.识别物体位置精准性差,小物体检测能力弱
2.召回率低
创新点:
- 使用Darknet-53作为特征提取网络,利用残差连接和卷积降采样来构建一个深层而高效的网络结构。
- 使用FPN(特征金字塔网络)来实现多尺度检测,利用不同大小的特征图来预测不同大小的物体,同时使用上采样和拼接来融合不同层次的特征。
- 使用逻辑回归替代softmax作为分类器,避免了类别之间的竞争,支持多标签的预测。
4.YOLOv4(2020)
贡献:
-
我们开发了一个高效、强大的目标检测模型。它使得每个人都可以使用1080 Ti或2080 Ti GPU来训练超级快速准确的目标检测器。
-
在检测器训练过程中,我们验证了最先进的bag - offrebies和Bag-of-Specials方法对目标检测的影响。
-
我们修改了最先进的方法,使其更有效,更适合单GPU训练,包括CBN , PAN , SAM等。
讲了通用的改进方法:数据增强,loss函数,增强感受野,注意力机制,特征集成,激活函数,后处理方法(后续开发无锚方法时不再需要进行后处理)
网络结构: CSPDarknet53骨干、SPP附加模块、PANet路径聚合颈和YOLOv3(基于锚点的)头作为YOLOv4的架构。DropBlock作为我们的正则化方法。增强马赛克和自对抗训练(SAT)方法
YOLOv4 consists of :
• Backbone: CSPDarknet53 主要在残差块进行了改进,引入了大残差块;
• Neck: SPP ,PAN
• Head: YOLOv3
创新:
- 输入端:Mosaic、Self-Adversarial Training–SAT自对抗训练、cmBN、Label Smoothing类标签平滑(缩小差距,减小过拟合)
- backbone:CSPDarknet53、Mish激活函数(无边界避免饱和)、Dropblock(随即丢弃区域)
- neck:SPP模块(何恺明提出,解决不同尺寸的特征图如何进入全连接层)、FPN+PAN(自底向上的特征金字塔,特征反复提取)
- 使用Mish激活函数
5.YOLOv5(2020)

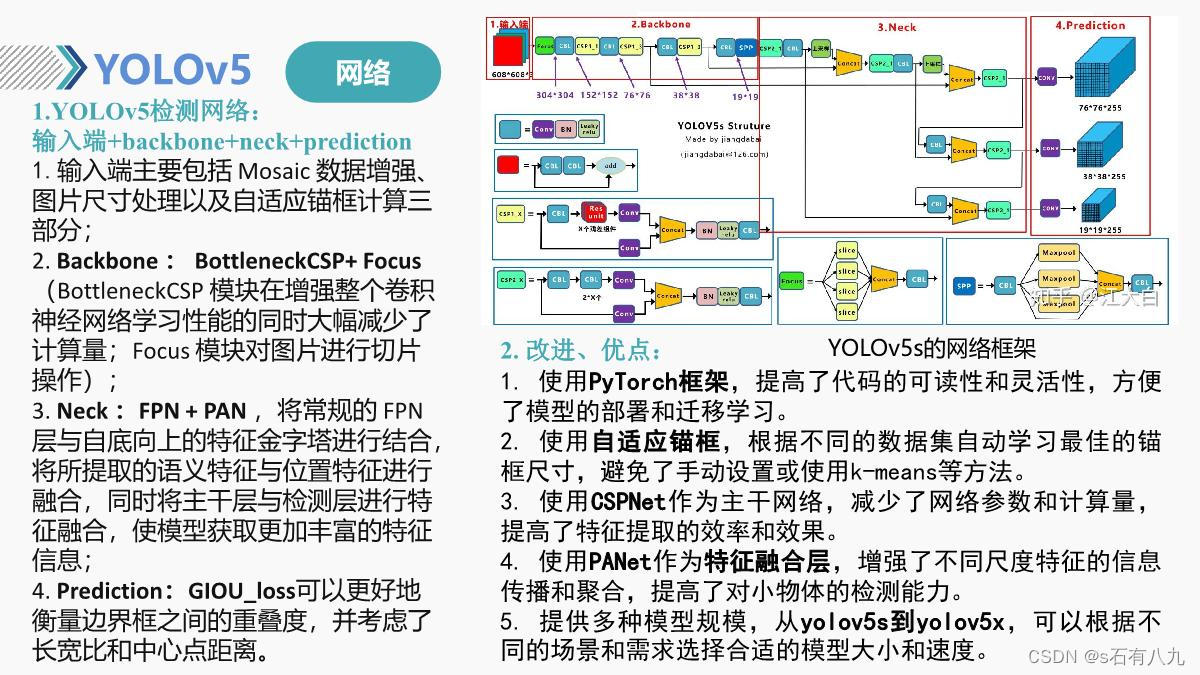
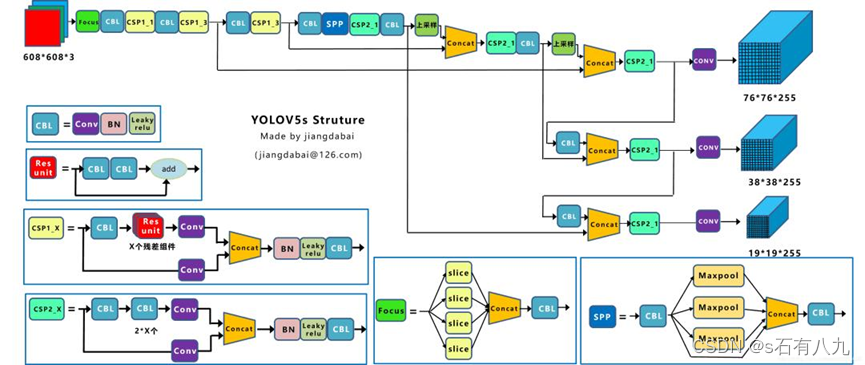
YOLOv5给出了四种版本的目标检测网络,分别是Yolov5s、Yolov5m、Yolov5l、Yolov5x四个模型。
创新点: YOLOv5各部分改进
- 输入端:Mosaic数据增强、自适应锚框计算(自动计算该数据集最合适的Anchor尺寸融入代码,保证准确率,减少模型参数和FLOPS)
- Backbone:Focus结构(切片操作为一片片特征图),CSP结构(Cross Stage Partial Network,跨阶段局部网络)两种CSP,一个在backbone,一个在neck
- Neck:FPN+PAN结构(加强网络特征融合的能力)
- Prediction:GIOU_Los
- 非极大值抑制采用DIOU_nms,对于遮挡问题,检出效果有所提升。
解决问题:
1.马赛克数据增强使小目标检测效果变好
2. Focus结构减少FLOPs,提高速度
优点:
1.使用pytorch框架,易于训练,投入生产,易于部署
2.提供四种版本,依据实际情况选择
3.模型训练、检测速度快
4.直接对单个图像,批处理图像,视频,摄像头端口输入进行有效推理
缺点: 没有发论文
6.YOLOX(2021)

7.YOLOv7

论文摘要:
本文提出的方法的发展方向不同于目前主流的实时目标检测器。除了架构优化之外,我们提出的方法将侧重于训练过程的优化。我们将重点研究一些优化模块和优化方法,这些模块和优化方法可以在不增加推理成本的情况下,增强训练成本以提高目标检测的准确性。
我们将提出的模块和优化方法称为可训练的免费包。
在本文中,我们将介绍一些我们发现的新问题,并设计有效的方法来解决它们。对于模型的再参数化,采用梯度传播路径的概念,分析了适用于不同网络层的模型再参数化策略,提出了规划的再参数化模型。此外,当我们发现使用动态标签分配技术时,具有多个输出层的模型的训练将产生新的问题。
即 : “如何为不同分支的输出分配动态目标?” 针对这一问题,我们提出了一种新的标签分配方法,即粗到细的导联标签分配方法。
本文的贡献总结如下:
- 设计了几种可训练的免费袋方法,使得实时目标检测在不增加推理成本的情况下大大提高了检测精度;
- 对于目标检测方法的改进,我们发现了两个新问题,即重参数化模块如何替换原始模块,以及动态标签分配策略如何处理对不同输出层的分配。此外,我们还提出了解决这些问题所带来的困难的方法;
- 提出了实时目标检测器的**“扩展”和“复合缩放”**方法,可以有效地利用参数和计算量;
- 该方法可有效减少当前实时目标检测器约40%的参数和50%的计算量,具有更快的推理速度和更高的检测精度
8.YOLOv8
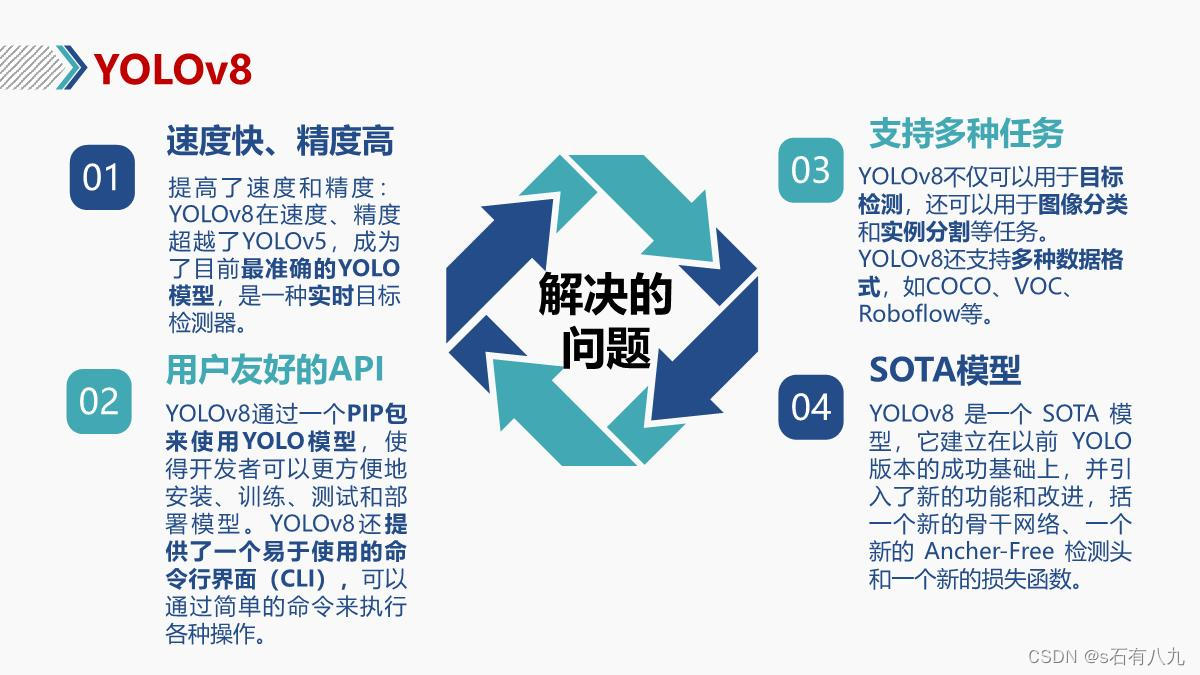
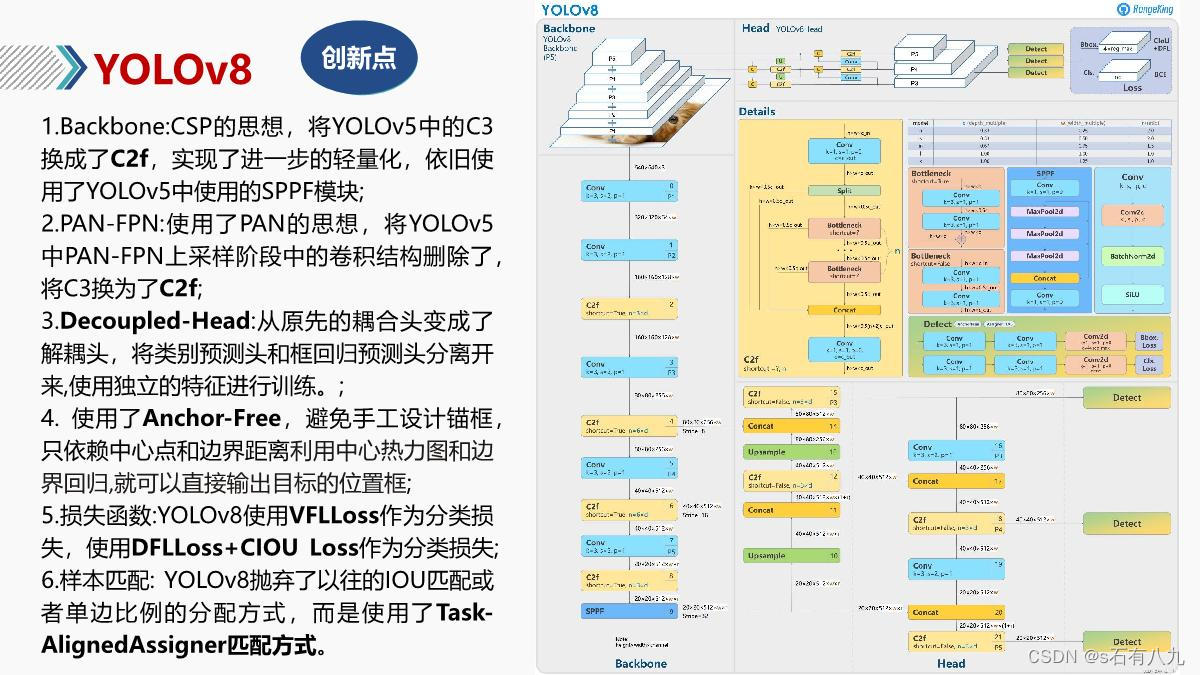
解决的问题、贡献、优点
- 提高了速度和精度: YOLOv8在MS COCO数据集上达到了58.9%的AP,超越了YOLOv5的48.4%的AP,成为了目前最准确的YOLO模型。YOLOv8还在GPU V100上保持了40 FPS以上的速度,比YOLOv5快了10 FPS,是一种实时目标检测器。
- 提供了一个友好的接口: YOLOv8通过一个PIP包来使用YOLO模型,使得开发者可以更方便地安装、训练、测试和部署模型。YOLOv8还提供了一个易于使用的命令行界面(CLI),可以通过简单的命令来执行各种操作。
- 支持多种任务: YOLOv8不仅可以用于目标检测,还可以用于图像分类和实例分割等任务。YOLOv8还支持多种数据格式,如COCO、VOC、Roboflow等。
- 拥有一个活跃的社区:YOLOv8由Ultralytics开发和维护,他们也是YOLOv5的创造者。Ultralytics不断地改进模型的架构和性能,并且积极地与社区交流和反馈。YOLOv8也继承了YOLO系列模型的优势,如小巧、灵活、可训练等,受到了计算机视觉领域的广泛关注和使用。
小结
作为单阶段大名鼎鼎的YOLO系列,速度确实快,精度可能会差一点。
现在最常用的就是yolov5、yolov7、yolov8了。
工业界便于部署使用的大部分是yolov5,不过yolov8现在也使用起来不错,不过使用起来,会出一些bug,修改代码需要修改环境里的Ultralytics代码。现在yolov8也是许多人改进模型的基础模型了(比较好水bushi)。
yolov8改进,我尝试过很多,总体来说效果其实也就那样,许多注意力机制更是几乎没什么用(甚至都不如CBAM)。
不过还是有可以改进的:提高速度和提高精度
- 提高速度:加一些DWconv、ghostconv等等
- 提高精度:一般都得上模型复杂度,会变慢,但是速度会提高
如果有需要我可以详细讲一下,我有一些yolov8的改进方法:
可以看我的GitHub yolov8改进
具体策略在 STF-YOLO/cfg/models/v8/ 里

