
热门标签
热门文章
- 1【机器学习基础】无监督学习(5)——生成模型_数据生成模型
- 2微信小程序_微信开发者工具开启多个页面
- 3毕业设计超市进销存管理系统源码
- 4Mac OS下JDK1.7安装_mac os jdk1.7
- 5Android Studio ——在不root手机的情况下读取Data目录下的文件_adb查看文件目录
- 6构造c语言的上下文无关文法,正则文法和上下文无关文法
- 72022华为软件精英挑战赛比赛经历
- 8yolov5 过拟合 欠拟合_yolo 欠拟合
- 9鸿蒙开发 - 状态管理之@Observed和@ObjectLink
- 10Linux 十四 修改文件操作权限 用户文件权限详解_14.修改linux权限每个数字代表的含义
当前位置: article > 正文
【人工智能概论】 自编码器(Auto-Encoder , AE)
作者:Monodyee | 2024-04-04 21:38:18
赞
踩
自编码器
【人工智能概论】 自编码器(Auto-Encoder , AE)
一.自编码器简介
- 自编码器结构图
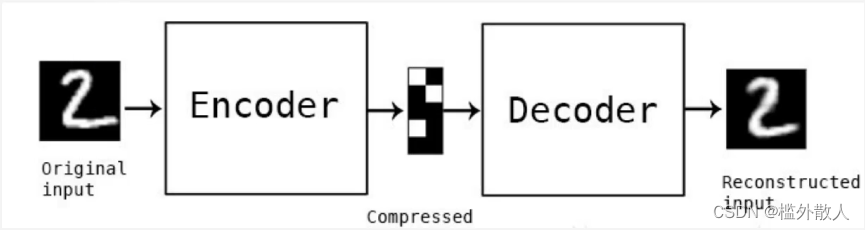
- 自编码器是自监督学习的一种,其可以理解为一个试图还原其原始输入的系统。
- 其主要由编码器(Encoder)和解码器(Decoder)组成,其工作流程是将输入的数据
x经编码器压缩成y,y再由解码器转化成x*,其目的是让x*和x尽可能相近。
注意:尽管自编码器是自监督模型,但是输入的数据总归是有规律的,以猫狗识别数据集为例,模型不知道它们是什么,但做开发的我们却是知道的,我们不能揣着明白装糊涂,要利用我们上帝视角的优势更好的把握全局,优化算法。
二.自编码器的特点
- 自编码器是自监督模型,其训练数据相对容易获取。
- 编码器的输出(此后称之为code)维度相较于输入要低很多,但其中却隐含着大量的特征信息。因此编码器有做数据压缩的潜质。
- code中蕴含着输入数据的信息,维度又很低。因此其具有为数据进一步处理节约运算成本的潜质。
- 从结果上看,解码器是通过一个低维数据生成一个高维数据的模型。因此解码器有做生成模型的潜质。
三.自编码器的应用潜质探索
1. 降噪——De-noising Auto-Encoder
- 将原始数据加上噪声作为输入,但输出的数据仍尽可能接近原始数据,通过这样一个小调整既能实现降噪,也能提高模型的鲁棒性,也有助于模型学到更深层次的特征。
- 实际上Bert的训练似乎与它有异曲同工之妙,Bert训练采用的Mask方法何尝不是一种加噪声,Bert就好似Encoder,它的产出就是code,后面加的网络就是Decoder。
2. 特征分离——Feature Disentanglement
- Disentanglement的意思是把原本纠缠在一起的东西解开。
- 自编码器的code中纠缠了许多信息,如果能把这些信息分拣出来,可以做很多有趣的事,这种想法就是Feature Disentanglement。
- 举例子来说,可以做语者转换,利用大量语音信号训练自编码器,同时再做个Feature Disentanglement的技术(比如控制code大部分维度不便,每次只调整一两个维度变化摸索规律,进而了解每个维度的作用),通过它来知道code中哪些维度代表语音内容,哪些维度代表语者特征,接下来把不同人的语音特征进行交换,然后解码还原。这就做到了语者转换。
- 不止如此这种技术还可以应用到影像,NLP等领域,这就是风格迁移。
3. 潜在离散表示——Discrete Latent Representation
- 自编码器的code不一定都是实数向量,也可以是二值向量,它的每个分量代表某种特征的存在与否。
比如,因为输入的是一个女生的图片,所以导致code的第一个维度就是1,她戴眼镜了,所以code的第二个维度也是1,她有一头乌黑的长发,因此code的第三个维度还是1,她的身高是超过170cm,code的第四个维度仍是1,但很可惜她不喜欢你所以code的第五个维度是0。
- 甚至可以强迫code是独热编码,这样就实现了自监督分类器。
- 能不能更离谱点,code一定是数字组成的向量吗? 当然不一定,code完全可以是一串文字,这段文字对应的正是输入文章的摘要或总结,这可能要求自编码器的编码器和解码器都是seq2seq结构。此外实际操作中不难发现code往往都是“加密”的,笑死人类根本看不懂,这时候可以再引入一个Discriminator,让它来监督Encoder输出的必须是人看的懂的东西,这样编码器不仅要能生成文字code,还要骗过Discriminator,大概率不好训练,怎么办?用RL硬train一发。这其实就是cycleGAN的想法。
- 还能不能再离谱点? 能,输入文章,把Encoder的输出变成Tree structure,再用它还原文字。
- 潜在离散表示相关技术中较为知名有VQ-VAE,其算法流程大概如下
- step1:首先设置 K 个向量作为可查询的 Codebook备用,一般这k个向量也是经过学习获得的。
- step2:输入的数据经过encoder编码转换成code,这个code通过最近邻算法与Coebook中的k个向量作对比,找出最接近的它的一个向量。
- step3:将筛选出来的向量作为解码器的输入进行解码重构。
- VQ-VAE 最核心的部分就是 Codebook 查询操作,通过使用具有高度一致性的 Codebook 来代替混乱的中间表征,可以有效的提高数据生成的可控性和丰富度。把它用在语音上codebook可能学到最基本的发声部位(phonetic音标),codebook里的每个向量对应着某个发音,就像对应某个音标符号。
4. 生成——Generate Network
- 前面提到过自编码器的解码器是有作为生成模型的潜质的。
- 实际上常见的三种生成模型除了GAN以外,剩下的两种其中一个就是VAE(Variational Auto-Encoder)
5. 降维,可视化,编码
- 前面提到过自编码器的编码器有做压缩器的潜质,且相较于传统的线性压缩,它的非线性压缩更有优势。
- 将输入数据降到二维,三维可以实现数据分布的可视化。
- 编码code也有为减少计算成本贡献的潜力。
6. 异常检测——Anomaly Detection
- 这是个重头戏
- 什么是异常检测?假设现在已有一堆训练资料『Xi』,现在来一笔新资料,它到底和之前的资料是否相似,是不是有什么隐疾,靠人为检查可能很难检查出来,这就需要一个能够检测出异常的检测系统。这个系统做得工作就是异常检测。
- 具体来说,通过大量已有的正确的样本训练出来的模型,如果给它新输入的资料与原本的资料类似,那么它就会认定这就是个nomaly的资料,否则就是一个anomaly的资料。
- 异常检测有什么用?安全工程,欺诈检测,异常访问,异常细胞检测等
- 怎么做到异常检测,把它看成一个二分类问题行不行?理论上似乎可行,实际上是行不通的,因为收集到的资料大部分都是正常的,异常数据是非常少的,数据非常不平衡,根本没法有效训练。况且在一大堆正常数据中甄别出几个异常数据也是相当困难的。最极端的当属根本没有异常数据,这根本无法训练二分类问题。
- 那该如何是好,Auto-Encoder为你解忧愁。举个例子甄别一张人脸图片是不是算法合成的,可以用大量的真实人脸训练一个自编码器,然后给它新的数据,它将通过计算还原出的图像与原始图像间的相似度来断定是不是真人脸,算法合成的人脸可能能骗过人类,但是自编码器却不能完美的重构它,算出来的相似度势必会比输入真人脸得到的相似度要明显低,这就实现了异常检测。
- 当然也要明确这也只是异常检测的一种思路。
四.传统自编码器的缺点(编码器映射空间的缺点)
- 听起来自编码器很完美,但事实并非如此,它的缺陷也是致命的。
编码器的映射空间不连续,且呈现不规则的,无界的分布
- 想要理解这一现象不妨借助一个极端的例子——自编码器解码器过拟合。
- 一个强大到可以轻易的记住所有训练数据的解码器乱杀一切,而编码器只需要给所有数据无脑的分配一个毫无意义的一对一的编号,每个样本经过编码器得到的code相互混杂,彼此孤立,毫无关系,整个code里没有任何有价值的信息,学号跟它比起来都是信息量巨大。
- 实际上这时候的解码器就是个大型的switch…case…结构,不在code范围的一切编码都用“default语句“生成一个“四不像”。
1. 编码器的映射空间不连续
- 传统自编码器的编码器映射空间不连续,即不同训练样本在该空间中对应的点与点之间
没有平滑的过渡。这就导致了自编码器的生成几乎是一对一的,只有靠近训练数据对应code的点生成的数据才可能有意义,即使是一个小的扰动也有可能导致输出的数据非常离谱。 - 因此想做生成模型传统自编码器是不合格的。
2.编码器的映射分布无规律
- code的表示自由自在,在映射空间中呈随意弥散状,
聚类的效果差,可解释性差,预期中希望code里包含语义信息往往实现不了,code往往扮演一个编号的角色。 - 因此想用自编码器做数据压缩、聚类往往不可行。
3.编码器映射呈无界分布
- 这将导致在映射空间不连续的基础上,进一步加大随机取点生成的数据无意义的几率。
- 在不能做生成模型的基础上反复鞭尸。
五.引出VAE
- AE有诸多不足,这就引出VAE。
实际上前面谈及的自编码器的应用潜质,多数都是由VAE实现的
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/Monodyee/article/detail/361272
推荐阅读
相关标签

