
- 1Android resource linking failed -AAPT:error resource xml/... not found——萌新BUG_error: resource xml/white (aka com.example.small_c
- 2root后怎么刷回官方,recovery刷入root_root的手机怎么刷回去
- 3MATLAB编写m函数理解 y=f(g(x))*h(x)_x(k)在matlab中代表什么
- 4TensorFlow2.1.0 报错解决:failed call to cuInit: CUDA_ERROR_NO_DEVICE: no CUDA-capable device is detected
- 5MYSQL之事务
- 6ADC学习系列(一):ADC基础概念_adc基础知识
- 7鸿蒙HarmonyOS实战-工具安装和Helloworld案例_鸿蒙windows模拟器
- 8linux升级ssh到6.6版本,CentOS6.5 openssh升级到openssh-7.6版本
- 9cp文书_hifjzoc9
- 10mathtype2023专门打数学符号的软件_mathtype7产品密钥2023
Bert系列:BERT(Bidirectional Encoder Representations from Transformers)原理以及hugging face介绍
赞
踩
1. 预训练语言模型的发展史
2018年,BERT被正式提出。下图1回顾了近年来预训练语言模型的发展史以及最新的进展。预训练语言模型的成功,证明了我们可以从海量的无标注文本中学到潜在的语义信息,而无需为每一项下游NLP任务单独标注大量训练数据。此外,预训练语言模型的成功也开创了NLP研究的新范式[6],即首先使用大量无监督语料进行语言模型预训练(Pre-training),再使用少量标注语料进行微调(Fine-tuning)来完成具体NLP任务(分类、序列标注、匹配关系判断和机器阅读理解等)。

图1 NLP Pre-training and Fine-tuning新范式及相关扩展工作
Google AI团队提出的预训练语言模型BERT(Bidirectional Encoder Representations from Transformers),在11项自然语言理解任务上刷新了最好指标,可以说是近年来NLP领域取得的最重大的进展之一。
1.1 BERT简介
简: BERT是深度双向语言表征模型。首先,百万量级训练语料无监督pre-training语言模型,然后特定任务语料有监督进行fine-tuning模型。
繁:
| BERT是基于Transformer的深度双向语言表征模型,基本结构如图2所示,本质上是利用Transformer结构构造了一个多层双向的Encoder网络。Transformer是Google在2017年提出的基于自注意力机制(Self-attention)的深层模型,在包括机器翻译在内的多项NLP任务上效果显著,超过RNN且训练速度更快。不到一年时间内,Transformer已经取代RNN成为神经网络机器翻译的State-Of-The-Art(SOTA)模型,包括谷歌、微软、百度、阿里、腾讯等公司的线上机器翻译模型都已替换为Transformer模型。关于Transformer的详细介绍可以参考Google论文《Attention is all you need》[3]。
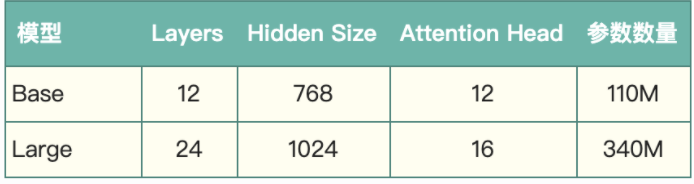
图2 BERT及Transformer网络结构示意图 模型结构如表1所示,根据参数设置的不同,Google 论文中提出了Base和Large两种BERT模型。
表1 BERT Base和Large模型参数对比 |
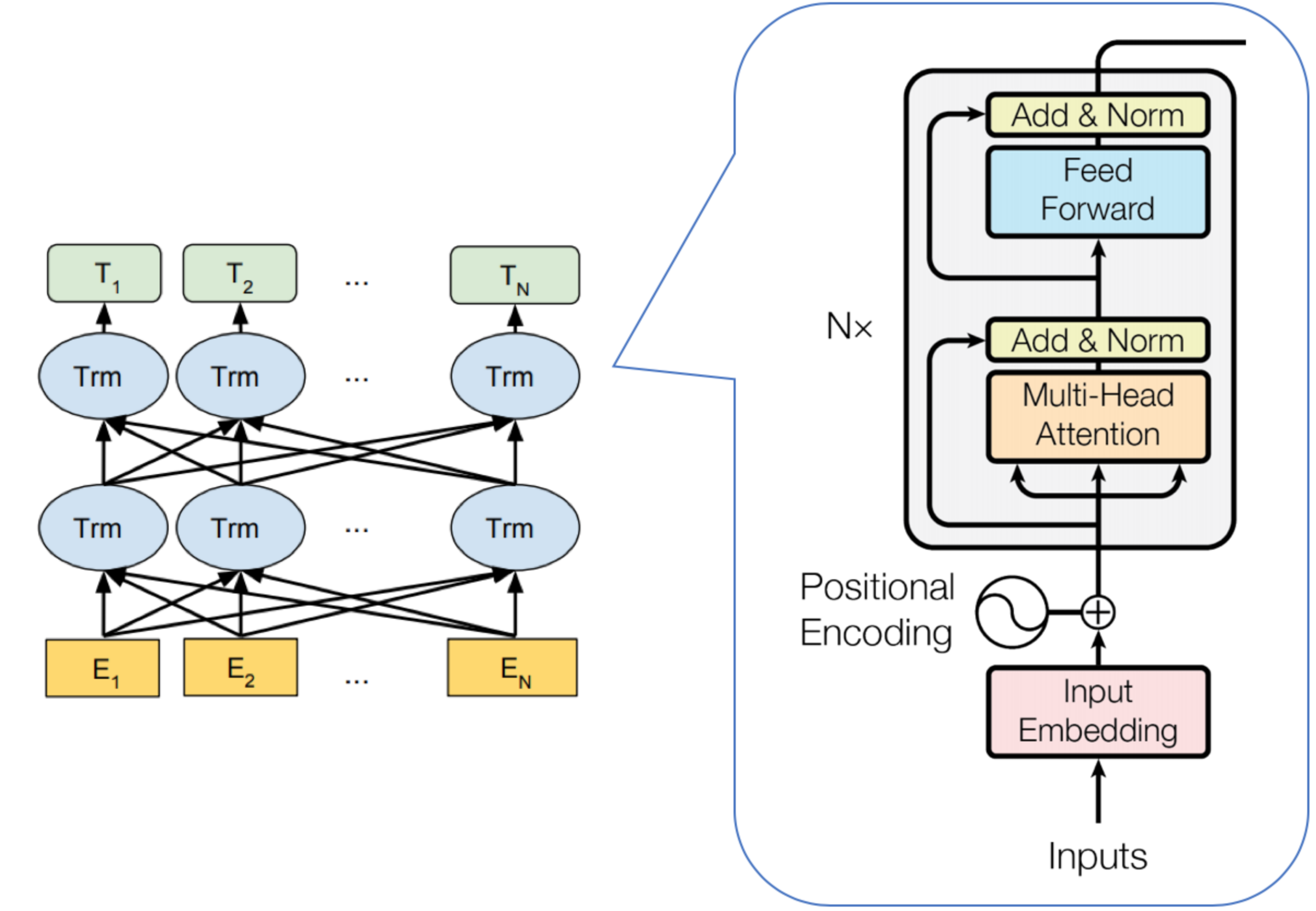
BERT模型框架
BERTpre-training和fine-tuning。除了输出层,pre-training和fine-tuning的结构是一样的。使用相同的pre-training的模型参数进行初始化,针对不同下游作业,使用不同的业务数据对模型进行fine-tuning。在fine-tuning期间,所有参数都被微调。
Pre-training
由于BERT需要通过上下文信息,来预测中心词的信息,同时又不希望模型提前看见中心词的信息,因此提出了一种 Masked Language Model 的预训练方式,即随机从输入预料上 mask 掉一些单词,然后通过的上下文预测该单词,类似于一个完形填空任务。
在预训练任务中,15%的 Word Piece 会被mask,这15%的 Word Piece 中,80%的时候会直接替换为 [Mask] ,10%的时候将其替换为其它任意单词,10%的时候会保留原始Token.
Fine-tunninng
对于不同的下游任务,我们仅需要对BERT不同位置的输出进行处理即可,或者直接将BERT不同位置的输出直接输入到下游模型当中。

输入表示
BERT的输入的编码向量(长度是512)是3个嵌入特征的单位和,如图4,这三个词嵌入特征是:
- WordPiece 嵌入[6]:WordPiece是指将单词划分成一组有限的公共子词单元,能在单词的有效性和字符的灵活性之间取得一个折中的平衡。例如图4的示例中‘playing’被拆分成了‘play’和‘ing’;
- 位置嵌入(Position Embedding):位置嵌入是指将单词的位置信息编码成特征向量,位置嵌入是向模型中引入单词位置关系的至关重要的一环。
- 分割嵌入(Segment Embedding):用于区分两个句子,例如B是否是A的下文(对话场景,问答场景等)。对于句子对,第一个句子的特征值是0,第二个句子的特征值是1。
最后,说明一下图4中的两个特殊符号[CLS]和[SEP],其中[CLS]表示该特征用于分类模型,对非分类模型,该符合可以省去。[SEP]表示分句符号,用于断开输入语料中的两个句子。

1.2 BERT精度高的原因
大量的预训练语料
Google发布的英文BERT模型使用了BooksCorpus(800M词汇量)和英文Wikipedia(2500M词汇量)进行预训练,所需的计算量非常庞大。BERT论文中指出,Google AI团队使用了算力强大的Cloud TPU进行BERT的训练,BERT Base和Large模型分别使用4台Cloud TPU(16张TPU)和16台Cloud TPU(64张TPU)训练了4天(100万步迭代,40个Epoch)。
1.3 应用举例
- 匹配任务(句子关系判断任务)
对两个短语或者句子之间的关系进行分类,常见句间关系任务如自然语言推理(Natural Language Inference, NLI)、语义相似度判断(Semantic Textual Similarity,STS)等 - 分类任务,输入是一个文本,输出是其类别
- 问答类任务,输入是一个问题和一段很长的包含答案的文字(Paragraph),输出在这段文字里找到问题的答案
- 序列标注,比如命名实体识别,输入是一个句子,每个时刻都会有输出的Tag,比如B-PER表示人名的开始。然后用输出的Tag来进行Fine-Tuning
BERT系列模型
对BERT原生模型在一些方向的改进:

2.hugging face
2.1 简介
Hugging face是一家总部位于纽约的聊天机器人初创服务商,开发的应用在青少年中颇受欢迎,相比于其他公司,Hugging Face更加注重产品带来的情感以及环境因素。官网链接 https://huggingface.co/ 。
但更令它广为人知的是Hugging Face专注于NLP技术,拥有大型的开源社区。尤其是在github上开源的自然语言处理,预训练模型库 Transformers https://huggingface.co/models,已被下载超过一百万次,github上超过24000个star。Transformers 提供了NLP领域大量state-of-art的预训练语言模型结构的模型和调用框架。用于自然语言理解(NLU)任务(如分析文本的情感)和自然语言生成(NLG)任务(如语言翻译)的预先训练的模型。
![]()
图4 2019.10-2020.3,每日平均的预训练模型下载数量
优势:
- 兼容TensorFlow2.0和pytorch(模型之间的深层互操作、框架之间迁移模型)
- 模型接口简洁
- 社区有很多预训练的BERT类模型,可快捷引用(30多种预训练模型的10种架构,其中一些采用了100多种语言)
- 可扩展性
huggingface提升了BERT类模型在工程上的可扩展性。

基于以上优势,通过huggingface工具,可以快速使用前述各BERT类模型。
参考:
[1] Peters, Matthew E., et al. “Deep contextualized word representations.” arXiv preprint arXiv:1802.05365 (2018).
[2] Howard, Jeremy, and Sebastian Ruder. “Universal language model fine-tuning for text classification.” arXiv preprint arXiv:1801.06146 (2018).
[3] Vaswani, Ashish, et al. “Attention is all you need.” Advances in neural information processing systems. 2017.
[4] Alec Radford, Karthik Narasimhan, Tim Salimans, and Ilya Sutskever. 2018. Improving Language Understanding by Generative Pre-Training. Technical report, OpenAI.
[5] Devlin, Jacob, et al. “Bert: Pre-training of deep bidirectional transformers for language understanding.” arXiv preprint arXiv:1810.04805 (2018).
[6] Ming Zhou. “The Bright Future of ACL/NLP.” Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. (2019).
[7] Deng, Jia, et al. “Imagenet: A large-scale hierarchical image database.” 2009 IEEE conference on computer vision and pattern recognition. Ieee, (2009).
[8] Girshick, Ross, et al. “Rich feature hierarchies for accurate object detection and semantic segmentation.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2014.
[9] bert系列模型:https://www.jiqizhixin.com/articles/2019-08-26-16

