
热门标签
热门文章
- 1怎样用python进行机器学习
- 2uni-app网络请求封装跨域_前端面试准备---浏览器和网络篇(一)
- 3玩转贝启科技BQ3588C开源鸿蒙系统开发板 —— 编译构建及此过程中的踩坑填坑(5)_鸿蒙 build.sh product-name dayu210
- 4余承东回应高通对华为恢复 5G 芯片供应;ChatGPT 发布重要更新;微软推出免费 AI 入门课|极客头条...
- 5利用nginx在树莓派上搭建文件服务器_192.168.18.14:8888
- 6iOS微信/支付宝/苹果内付支付流程图1_苹果支付流程图
- 7MFCC特征提取
- 8自练题目c++
- 9解密高并发系统的瓶颈:五大解决方案_微服务 高并发的瓶颈
- 10Python是什么?Python基础教程400集大型视频,全套完整视频赠送给大家_python人马大战csdn
当前位置: article > 正文
最新多模态模型MiniGPT-4 开源 | 提前感受GPT-4的识图能力 | 基于Vicuna构建的LLM | 能够生成图片描述 | 根据手写文本指令构建网站_多模态大模型 vicuna
作者:Monodyee | 2024-04-04 23:03:44
赞
踩
多模态大模型 vicuna
概述
最新多模态模型MiniGPT-4 开源:它使用先进的大型语言模型 (LLM)--Vicuna(其中 Vicuna 是基于 LLaMA 构建的)进行调优,在文本语言方面可以达到 ChatGPT 能力的90%。在视觉感知方面,作者采用了与BLIP-2相同的预训练视觉组件,其中该组件由EVA-CLIP的ViT-G/14和Q-Former组成。MiniGPT-4 只添加了一个映射层,将编码的视觉特征与Vicuna语言模型对齐,冻结了所有视觉和语言组件参数。
MiniGPT-4介绍
距离GPT-4 已经发布一个多月了,但识图功能还是体验不了。来自阿卜杜拉国王科技大学的研究者推出了类似产品 ——MiniGPT-4,大家可以上手体验了。
对人类来说,理解一张图的信息,不过是一件微不足道的小事,人类几乎不用思考,就能随口说出图片的含义。就像下图,手机插入的充电器多少有点不合适。人类一眼就能看出问题所在,但对 AI 来说,难度还是非常大的。
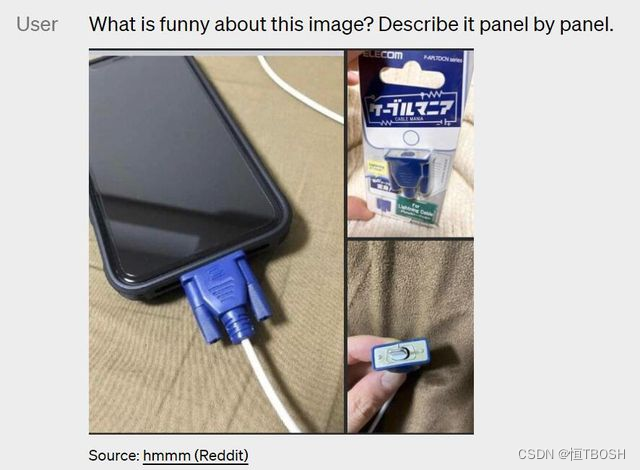
GPT-4 则能很快的指出图中问题所在:VGA 线充 iPhone是不合适的。
其实 GPT-4 的魅力远不及此,更炸场的是利用手绘草图直接生成网站,在草稿纸上画一个潦草的示意图,拍张照片,然后发给 GPT-4,让它按照示意图写网站代码,GPT-4 就能很快把网页代码写出来了。
但遗憾的是,GPT-4 这一功能至今仍未向公众开放,想要上手体验也无从谈起。不过,已经有人等不及了,来自阿卜杜拉国王
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/Monodyee/article/detail/361745
推荐阅读
相关标签

