
- 1UniApp组件:常见的组件及其用法_uniapp uni组件
- 2鸿蒙会应用到手机上吗,明明鸿蒙系统可随时用在手机上,为何现在还是要用安卓?...
- 3微信小程序自定义头部(无导航背景铺满手机头部)_微信小程序 h5 自定义顶部
- 4Android Studio 华为手机不出Log_android studio 有的手机看不到log
- 5SpringMVC接收参数方式,Controller接收参数,常见不规范的传参和错误传参_controller获取不到参数
- 6【NLP笔记】RNN总结
- 7微信小程序云开发操作全解_微信云开发不为空条件
- 8perl处理excelwenjian_perl处理 excel 事件
- 9安卓系列机型永久去除data分区加密 详细步骤解析_解密data分区的密码
- 10Git回退版本的几种操作_git回滚到指定版本
自然语言处理(NLP)—— 语义关系提取_自然语言处理 词义关联性
赞
踩
语义关系是指名词或名词短语之间的联系。这些关系可以是表面形式(名词性实体)之间的联系,也可以是知识工程中概念之间的联系。在自然语言处理(NLP)和文本挖掘领域,识别和理解这些语义关系对于信息提取、知识图谱的构建以及文本理解都是非常重要的。
1 语义关系的例子
同义词(Synonymy):两个或多个词在某种语境中具有相同或相似的意义。
反义词(Antonymy):词与其对立意义的词之间的关系。
上下位关系(Hyponymy/Hypernymy):一个词是另一个词的下位词(更具体的意义),或上位词(更一般的意义)。
全体-部分关系(Meronymy/Holonymy):一个词表示另一个词的部分,或者整体。
因果关系(Causality):一个事件或状态导致另一个事件或状态。
2 语义关系提取的早期方法:Hearst模式的方法
Martí Hearst在1992年提出了一种基于模式的方法来提取文本中的语义关系。她使用了特定的词汇模式来自动发现文本中的上下位关系,例如:
: 这个模式可以用来识别一组事物中的上位词和下位词,例如,fruits such as apples, bananas, or grapes”。
这个模式与上一个相似,用于识别同一组事物,例如,such tools as hammers, saws, and nails。
这个模式用于识别一组同级事物,以及它们共同的上位概念,例如,dogs, cats, and other pets。
这个模式指出了包含关系,例如,healthy foods, especially fruits and vegetables。
Hearst在Grolier’s American Academic Encyclopedia上应用了这些模式,从中提取了152种关系。通过这种方式,她能够自动从大型文本集合中提取出有用的语义关系,这些关系对于构建词典、本体和知识库非常有价值。随着技术的发展,后来的研究者们提出了更多更为精细的算法和模型来提取和处理语义关系。
3 自助法(Bootstrapping)
自助法(Bootstrapping)是一种迭代方法,常用于信息提取、自然语言处理等领域,特别是在有限或没有标注数据的情况下。它通过从少量的种子信息开始,逐步增加和细化 模式或数据集。
Riloff和Jones在1999年介绍了一种利用自助法来迭代提取语义关系的方法。
3.1 过程
a.初始模式:从Hearst提出的那样的模式开始,这些模式是用来发现文本中特定语义关系的。
b.提取名词性实体:使用这些模式提取出名词或名词短语(nominals)。
c.寻找新关系:在已提取的名词性实体之间寻找新的语义关系。
d.模式扩展:将新发现的关系添加到模式集合中。
e.迭代:使用更新后的模式集合重新开始上述过程。
这个过程会不断循环,每一轮都可能发现新的关系和模式,从而逐渐扩大知识库。
然而,自助法在迭代过程中可能会引入噪声,导致所谓的 语义漂移(semantic drift),即随着迭代次数的增加,提取的信息可能会逐渐偏离原始的准确关系。
3.2 模式评分函数 —— 特异性
为了避免语义漂移,可以引入一个模式评分函数,称为特异性(specificity)。这个函数的目的是评估一个模式的准确性。具体公式如下:
这里,是一个模式,
是语料库
中所有匹配该模式的元组集合,
是一个在由模式目标关系确定的元组上均匀分布的随机变量。特异性分数越高,意味着模式与目标关系匹配得越好,因此被视为越可靠。这种方法可以帮助识别和保留高质量的模式,而去除那些可能导致语义漂移的低质量模式。
3.3 改进方法
在2006年,Pantel和Pennacchiotti介绍了一种基于模式和关系可靠性的递归计算方法。这种方法旨在提升自助法(Bootstrapping)在信息提取过程中的准确性,特别是在自动提取语义关系时。通过计算模式(Patterns)和关系实例(Relation Instances)的可靠性,可以有效减少语义漂移(Semantic Drift)的问题。
4 可靠性的计算方法
可靠性的计算基于点互信息(Point-wise Mutual Information, PMI),这是一种衡量两个变量之间关联程度的统计指标。PMI通过比较两个变量共同出现的概率与它们各自独立出现概率的乘积的比值,来量化这种关联。
对于模式的可靠性
,以及关系实例
的可靠性
,计算公式如下:
模式的可靠性:
关系实例的可靠性:
在这里,和
分别是关系实例和模式的数量,
是关系实例
和模式
之间的点互信息。
4.1 递归计算的方法
递归开始时,给定的种子模式和种子关系实例被赋予初值1,作为它们的初始可靠性。
然后,通过反复使用上述公式递归计算,逐渐更新每个模式和关系实例的可靠性。这个过程中,高PMI值的模式和关系实例的可靠性会增加,而低PMI值的则会减少。
这种递归计算方法使得可以从初始种子集合开始,逐步扩展到更广泛的模式和关系实例,同时保持对可靠性的控制。
通过这种方法,可以有效地提高信息提取过程的质量,减少因引入不相关或错误模式和关系实例导致的误差,从而提高最终结果的准确性和可靠性。
5 SPMI
在2018年,Roller等人采用了类似于Hearst模式的一组稍长的模式列表,在一个非常大的语料库上提取所有潜在的上下位(is-a)关系对。他们的工作展示了如何结合传统的模式匹配方法和现代的数学技术(如奇异值分解,SVD)来提高语义关系提取的质量和准确性。
5.1 构建矩阵M
a.基于Hearst模式提取is-a对:首先,他们使用扩展的Hearst模式列表从大型语料库中自动提取潜在的上下位关系对。
b.使用PMI填充矩阵M:接着,构建一个矩阵M,其中包含这些上下位关系对。矩阵M的单元格值是点互信息(PMI),用于表示词对之间的语义相关性。这个矩阵通常是不对称的。
5.2 奇异值分解
a.对M进行奇异值分解:然后,通过奇异值分解将矩阵M分解为,其中
是一个包含按降序排列的奇异值的对角矩阵。
b.截断奇异值:选择截断版本的,即
,以减少维度,同时保留最重要的语义信息。
5.3 计算SPMI
a.定义SPMI:利用截断后的矩阵,定义一种基于奇异值的超上位词(hyperonymy,即上下位关系)预测函数SPMI(Singular Pointwise Mutual Information)。
b.计算方法:对于任意的词对,通过利用
和
对应的
(或
)和
(或
)中的行
和
来计算它们的SPMI值:
。
5.4 SPMI的应用
SPMI值可以被用作预测词对之间是否存在上下位关系的依据。这种方法不仅利用了从文本中直接提取的模式,还通过奇异值分解来捕获和利用词对之间深层的、可能不那么显而易见的语义关系。相比直接使用原始的PMI,SPMI通过聚焦于最重要的语义维度,可以更有效地预测上下位关系,从而提高语义关系提取的准确性和可靠性。
6 分布式包含假设与分布式信息量假设
这两个假设,分布式包含假设(Distributional Inclusion Hypothesis)和分布式信息量假设(Distributional Informativeness Hypothesis),都是在探索词汇语义泛化(generality)和它们在大型文本语料库中的使用模式之间的联系。这些假设为自然语言处理(NLP)中的语义分析提供了理论基础,尤其是在词义的自动识别和分类上。
6.1 分布式信息量假设
根据Santus于2017年提出的 分布式信息量假设,一个术语的泛化程度可以通过其最典型上下文的信息量来推断。这意味着,如果一个术语在其上下文中提供了丰富的、独特的信息,那么这个术语就更具体;反之,如果一个术语的上下文信息量较低,那么这个术语就更加泛化。这个假设的核心在于,通过分析一个词在文本中出现的上下文,我们可以对这个词的语义泛化程度进行量化。
6.2 分布式包含假设
分布式包含假设,由Santus等人在2014年提出,声称如果是
的上位词(hyperonym),那么
的上下文集合是
的上下文集合的子集。简而言之,这意味着一个词的所有上下文也应适用于其上位词。这个假设基于观察,即更泛化的术语倾向于在更广泛的上下文中出现,而更具体的术语则在更狭窄的上下文中出现。
6.3 语义泛化指数
为了量化一个术语的语义泛化程度,Santus等人定义了 语义泛化指数,该指数基于术语的特征列表计算得出。对于术语,其语义泛化指数
是通过计算最频繁出现的
个上下文的熵的中位数来得到的,其中熵
是给定上下文
中术语特征的熵:
这个公式计算了给定上下文中特征出现概率的熵,高熵值表示在该上下文中出现的术语特征分布较为均匀,反映了较高的语义泛化程度;低熵值则意味着某些特征出现的概率远高于其他特征,反映了较低的语义泛化程度。
这两个假设和语义泛化指数在自然语言处理中尤其是在自动词义识别、词义消歧和知识图谱构建等领域提供了重要的理论支持和实用工具。
6.4 SLQS
根据分布式包含/信息量假设,可以通过术语的上下文来评估其语义泛化程度和潜在的上下位关系。Santus, Lenci, Qin, Schulte (SLQS) 提出的方法进一步精细化了这一理论,特别是在自然语言处理和语义分析领域。
6.4.1 语义泛化指数
术语的语义泛化指数
通过计算该术语最重要的
个上下文的熵的中位数来得到。这里的
表示
的第
个上下文,
是该上下文的熵。公式如下:
熵反映了在给定上下文中词汇特征分布的多样性。高熵值表示该词在不同上下文中具有较广泛的语义应用,从而指示了较高的语义泛化程度;而低熵值则表明该词在较为特定的上下文中使用,指示了较低的语义泛化程度。
6.4.2 SLQS 计算上下位关系
两个术语和
之间的潜在上下位关系可以通过 SLQS 公式来计算:
这里,如果的泛化程度小于
(即
),则
的值接近于 1,表明
可能是
的下位词。反之,如果
的泛化程度大于或等于
,
的值会小于或等于 0,表明
不太可能是
的下位词。
6.4.3 应用
SLQS 方法为自动识别文本中的上下位关系提供了一种有效的工具,这对于构建知识图谱、提高信息检索的准确性以及改善语义搜索等应用都非常重要。通过分析词汇在大量文本中的分布情况,SLQS 有助于揭示词汇之间复杂的语义关系,为理解和处理自然语言提供了有力的支持。
7 双锚点模式
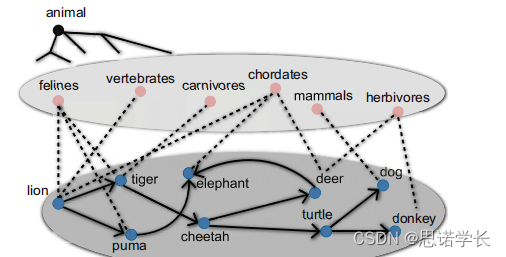
图中展示的可能是一种知识图谱或语义网络,描绘了不同动物类别之间的上下位关系(即语义关系)。这个网络通过节点(动物或动物类别)和边(表示这些类别之间的关系)来说明动物界的分类体系。
在提取这类关系时,使用单一锚点的模式(如“such as jaguar”)可能会带来噪声,因为“jaguar”(捷豹)这个词具有多义性——它既可以指代一种动物,也可以指代汽车品牌等。
为了避免这种多义性问题,Kozareva等人在2008年引入了双锚点模式(doubly-anchored patterns),例如“* such as jaguar and *”。这样的模式通过在句子中提供两个锚点(通常是同一类别中的两个实例),减少了错误抽取的风险,因为提取算法需要同时找到匹配两个锚点的上下文。
在2010年,Kozareva等人采用自助法(bootstrapping)的方式应用双锚点模式,迭代地提取和细化上位词(hyperonyms)。在每一轮迭代中,他们会保留最相关的上位词,这些上位词被用作后续迭代中新模式的种子。这样,随着迭代的进行,系统能够自动识别和增强相关的上下位关系,从而提高提取这些关系的准确性。
图中所示的网络中的点和线代表了动物和它们之间的分类关系。例如,felines(猫科动物)是“lion”(狮子)、“tiger”(老虎)和“puma”(美洲狮)的上位词。这种关系可以用双锚点模式来精确提取,例如“* such as lion and tiger”,来确定“felines”是这两种动物的一个共同的上位类别。
8 相似度模型
关系的“形状”或表现可以通过不同的语言模式来观察。例如,“shot against the flu,” “shot to prevent the flu” 和 “flu shot” 这三个短语都表达了某种关于预防流感的接种活动,但它们的结构和表述方式各不相同。问题是,我们如何知道两个短语是否表示相同的关系?
8.1 字符串相似度模型
在字符串相似度模型中,两个短语s1和s2表示相同关系R的概率可以用一个基于相似度函数的概率模型来估计:
这里的sim函数可以是任何度量字符串之间相似性的函数,如莱文斯坦编辑距离(Levenshtein string edit distance),这是衡量两个字符串之间通过插入、删除或替换操作转换成对方所需的最少操作数。
8.2 分布式相似度模型
在分布式相似度模型中,Lin & Pantel (2001) 提出的DIRT(发现推理规则)算法使用上下文信息来推断关系。DIRT算法通过以下步骤实现关系发现:
8.2.1 提取关系三元组
他们从文本中提取形如(r, w1, w2)的关系,其中w1和w2是名词或名词短语,r是包含动词的依存关系路径。
8.2.2 比较依存路径
通过比较不同实例中的依存路径(r*, w1, w2),DIRT算法可以推断不同的依存关系路径ri之间的相似性。
这种方法依赖于观察,不同的词或短语如果在相似的上下文中以相似的方式使用,它们可能表示相同的或类似的语义关系。DIRT算法通过分析这种上下文共现信息来发现可能的推理规则,从而揭示隐含的语义关系。
总的来说,这两种模型都试图通过不同的方式理解和识别语言中的隐含关系,无论是通过直接比较字符串的形式,还是通过考虑它们的分布式上下文特征。这些模型对于信息提取、知识图谱的构建、问答系统和机器翻译等NLP应用都有重要的意义。
9 无限关系模型
无限关系模型(Infinite Relational Model, IRM)是一种非参数贝叶斯模型,用于发现数据中的潜在结构,尤其是用于识别术语对和关系之间的聚类模式。在IRM中,数据被视为术语对和关系之间的相互作用,通过这种方法,可以识别出表示相同关系的术语聚类,以及连接相同术语对的关系聚类。
IRM的核心思想是在给定的数据中发现一个无限数量的潜在聚类,它允许模型根据数据的复杂性动态调整聚类的数量。这个特性来自于其使用了Dirichlet过程,这是一种非参数贝叶斯方法,可以根据数据集的大小和多样性来自适应地确定聚类的数量。
9.1 Kemp等人(2006年)的IRM
Kemp等人在2006年提出的IRM是这样一个迭代模型,其中一种类型的聚类(例如术语聚类)是由另一种类型的聚类(例如关系聚类)构建出来的。该模型交替地考虑术语对和关系之间的关联,通过这种迭代过程,逐渐改进对数据中关系结构的估计。
9.2 Davidov和Rappoport(2008年)的方法
Davidov和Rappoport在2008年提出了一种使用模式来挖掘数据中的术语和关系的方法。他们使用的模式包含内容词(CW)和高频词(*fix,如前缀、中缀、后缀),来识别文本中的相关信息。例如:
prefix CW1 infix CW2 postfix
这里的CW1和CW2是内容词,而prefix、infix和postfix则是连接这些内容词的高频词。通过这些模式,他们能够自动地从文本中提取可能表示特定关系的术语对。
这种方法特别有助于从大规模文本数据中发现那些可能没有明确表述的推理规则和关系,从而增强机器对自然语言中隐含关系的理解和推理能力。这种模式和IRM的结合使用,可以有效地揭示文本数据中的复杂关系结构,这在知识发现和自然语言理解领域是非常有价值的。
10 远程监督(Distant Supervision)
远程监督(Distant Supervision)是自然语言处理领域的一个技术,它使用从一个任务中获取的数据来训练另一个相关任务。这种方法的核心思想是,如果我们知道两个实体之间存在某种关系,那么任何提及这两个实体的文本都可能是这种关系的一个实例。
10.1 远程监督的应用
远程监督通常用于那些难以获取大量手工标注数据的场景,特别是在实体关系提取任务中。例如,我们可以使用以下资源进行远程监督:
WordNet:用于获取同义词、反义词、上下位关系等语义关系。
Wikipedia:作为丰富的知识源,用于抽取事实性信息,如人物关系、历史事件等。
Wikidata:提供结构化的知识库,包含各种实体和它们之间的关系。
通过这些语料库,我们可以自动构建训练数据集。例如,如果Wikidata告诉我们“Obama”是“美国总统”的一个实例,那么任何包含“Obama”和“美国总统”的句子都可能被用作提取“总统”关系的训练实例。
10.2 远程监督的挑战
远程监督的挑战包括:
噪声:不是所有提及两个实体的文本都确实表达了我们感兴趣的关系。有时文本可能在谈论其他事情。
偏差:远程监督假设所有提及特定实体的句子都与已知的关系有关,这可能导致训练数据偏差。此外,多义性(polysemy)问题也会增加噪声,因为同一个词或短语在不同上下文中可能有不同的意义。
尽管存在这些挑战,远程监督是提高大规模数据集上监督学习性能的一种有效方法。通过合适的清洗和处理步骤,我们可以缓解噪声和偏差的问题,从而利用这些方法来提高模型的性能和泛化能力。
10 项目NELL
项目NELL(Never-Ending Language Learning)是由卡内基梅隆大学开展的一项研究项目,旨在创建一个持续学习和读取网络信息的计算系统。从2010年开始,NELL系统已经不断地从网络上提取信息,并试图从找到的文本中读取并理解事实。
10.1 NELL项目的关键特点
持续学习:NELL旨在模拟一个永不停歇的学习过程,它每天尝试从互联网上读取和提取新的信息。
任务:它主要执行两项任务:一是提取文本中的事实;二是改进其阅读能力,以便在未来能更准确地从网络上提取更多事实。
开始规模:项目启动时,NELL识别了大约600种关系,每种关系有10到20个示例。
增长:截至Tom Mitchell于2015年的报道,NELL已经提取了大约5000万个关系,其中280万个是高置信度的关系。
这个项目的成果不仅展示了机器学习和人工智能在文本理解方面的进步,还为如何构建和维护大型知识库提供了见解。NELL系统不断利用新的数据来增强其模型,通过这种方式,它可以不断地优化自己的学习算法,以更好地识别和理解新的概念和事实。这个系统也体现了远程监督等技术的实际应用,通过从现有的数据资源中学习,不断提升自身的阅读和理解能力。

