
- 1Air724UG 核心板学习记录-开发板介绍
- 2看大神如何用python爬虫爬取京东商品评论_python爬虫爬取京东电商平台商品评论,要求根据商品关键字爬取
- 3探索【Stable-Diffusion WEBUI】的附加功能:图片缩放&抠图_4x-ultrasharp
- 4AI程序员的出现与程序员的未来:饭碗之争的真相
- 548位一作相聚CVPR 2024预讲会/附全部议程
- 6Flask之ajax操作示例_flask 处理 ajex
- 7LLaMA模型指令微调 字节跳动多模态视频大模型 Valley 论文详解_valley: video assistant with large language model
- 8(五)比赛中的CV算法(下)目标检测终章:Vision Transformer_为什么不用vision transformer 做bacbone 进行目标检测
- 9包含密钥的OMP压缩感知模拟(MATLAB)
- 10备战蓝桥杯,用JAVA刷洛谷算法题单:【算法2-1】前缀和、差分与离散化
17、InternVL: Scaling up Vision Foundation Models and Aligning for Generic Visual-Linguistic Tasks
赞
踩
简介
github
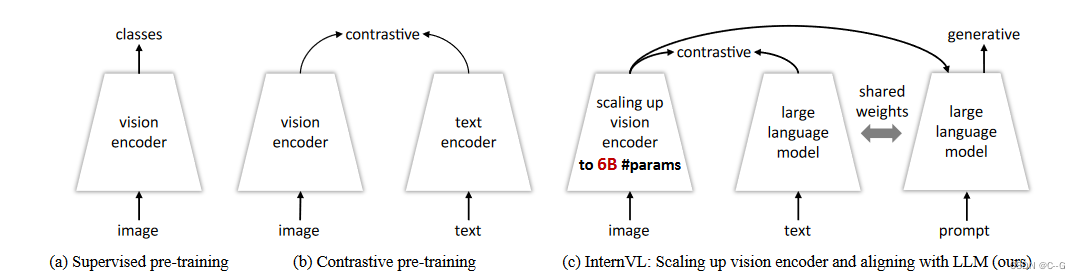
(a)表示传统的视觉基础模型,如对分类任务进行预训练的ResNet。
(b)表示视觉语言基础模型,例如CLIP,对图像-文本对进行预训练。
(c)InternVL,它提供了一种将大规模视觉基础模型(即InternViT-6B)与大型语言模型对齐的可行方法,并且对于对比和生成任务都是通用的。
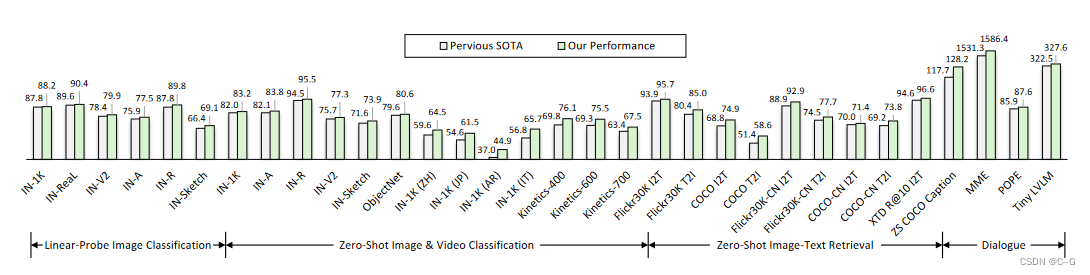
比较各种通用视觉语言任务的结果,包括图像分类、视频分类、图像文本检索、图像字幕和多模态对话。InternVL在所有这些任务上都达到了最佳性能。
预备知识
ViT-22B是Google Research的一项研究,将 Vision Transformer 参数量扩展到了 22B,其主要是扩展了模型的宽度,使得参数量更大,深度和 ViT-G 一样。paper
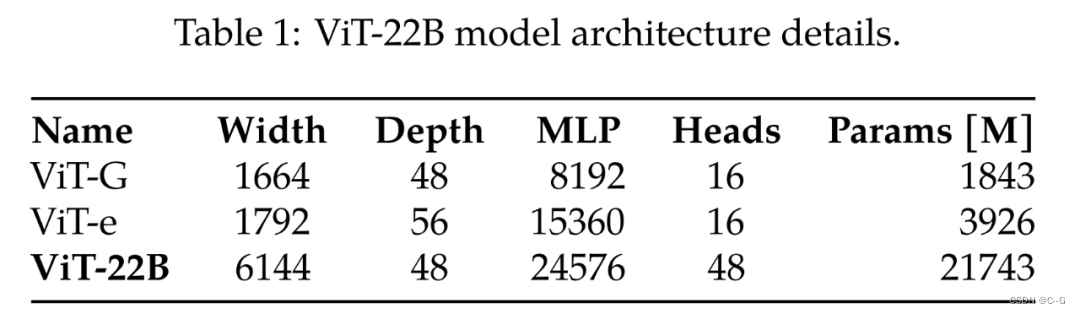
与自然语言处理类似,对预训练视觉主干的迁移提高了模型在各种视觉任务上的性能。更大的数据集、可扩展的架构和新的训练方法都推动了模型性能的提升。然而,视觉模型仍然远远落后于语言模型。具体来说,迄今为止最大的视觉模型 ViT 只有 4B 参数,而入门级语言模型通常超过 10B 参数,更别说具有 540B 参数的大型语言模型。
LLaMA——Large Language Model Meta AI,Meta开源的大模型,参数量从 70 亿到 650 亿不等。paper
Vicuna-13B。以 Meta 开源 LLaMA(直译为「大羊驼」)系列模型为起点,研究人员逐渐研发出基于LLaMA的Alpaca(羊驼)、Alpaca-Lora、Luotuo(骆驼)等轻量级类 ChatGPT 模型并开源。而**Vicuna(小羊驼)**是基于LLaMA,参数量13B。Vicuna-13B 就是通过微调 LLaMA 实现了高性能的对话生成。github
实现流程
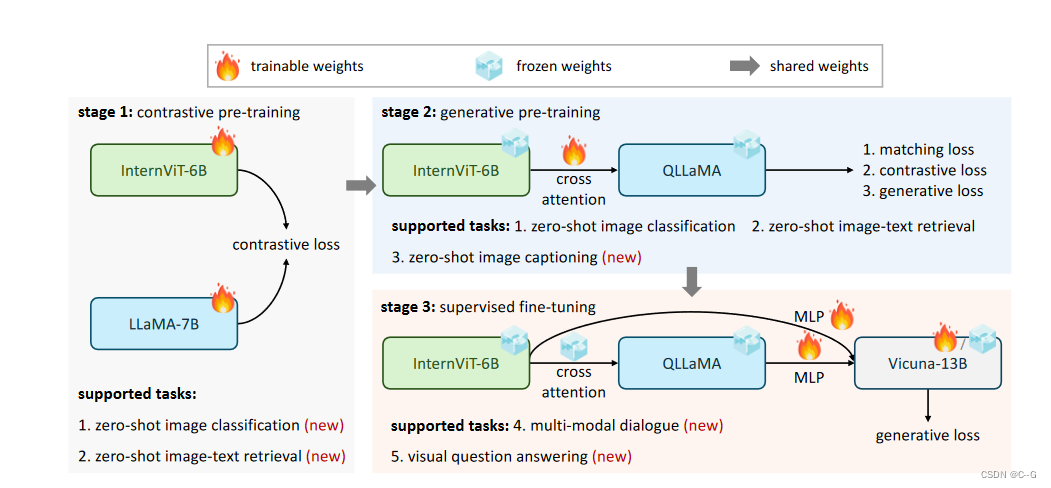
新增两个大模型:
- internet - 6b是一个有60亿个参数的视觉Transformer,为了匹配LLMs的规模,基于vanilla vision transformer (ViT)实现。
- QLLaMA是一个拥有80亿个参数的语言中间件,基于LLaMA实现。
InternViT-6B
在LAION-en数据集的100M子集上使用对比学习来测量不同配置的Internet - 6b变体的准确性、速度和稳定性。模型深度可选值为{32,48,65,80},头尺寸在{64,128},MLP比率在{4,8}。最终确定超参数如下表:
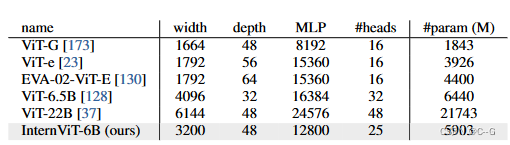
- 速度。对于不同的模型设置,当计算不饱和时,深度较小的模型显示出更快的图像速度。然而,随着GPU计算的充分利用,速度差异变得可以忽略不计;
- 准确性。在参数数量相同的情况下,深度、头尺寸和MLP比对性能的影响较小
QLLaMA
QLLaMA是在预先训练好的多语言LLaMA基础上开发的,新增96个可学习的 queries 和随机初始化的 cross-attention (10亿个参数)(参考BLIP-2)
- 通过使用预训练的权值进行初始化,QLLaMA可以将Interviti - 6b生成的图像标记转换为与LLMs对齐的表示
- QLLaMA具有80亿个视觉语言对齐参数,是QFormer的42倍。因此,即使使用冻结的LLM解码器,InternVL也可以在多模态对话任务上取得令人满意的性能。
- 它还可以应用于对比学习,为图像-文本对齐任务提供强大的文本表示,如零快照图像分类和图像-文本检索。
BLIP-2网络架构
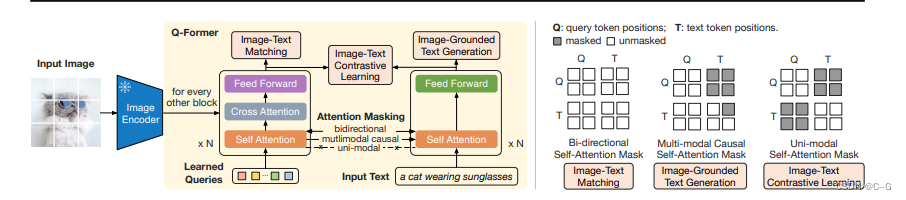
Training
视觉语言对比训练
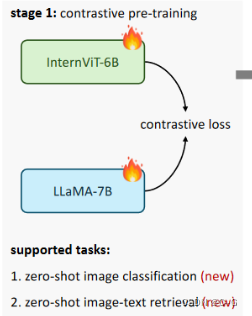
进行对比学习,将Internet - 6b与多语言LLaMA-7B对齐。
使用的数据集包括:
- LAION-en
- LAION-multi
- LAION-COCO
- COYO
- Wukong
原始数据集包含60.3亿对图像-文本对,清理后剩下49.8亿对。
使用LLaMA-7B将文本编码为 T f T_f Tf,使用Intern ViT-6B将图片编码为 I f I_f If,类似CLIP,最小化批处理中图像-文本对相似分数的对称交叉熵损失,这使得InternVL在对比任务上表现出色,如零拍摄图像分类和图像文本检索,这一阶段的视觉编码器在语义分割等视觉感知任务上也能表现出色。
在这一阶段,对图像编码器Internit - 6b进行随机初始化,对文本编码器LLaMA-7B使用预训练好的权值进行初始化。所有参数都是完全可训练的。
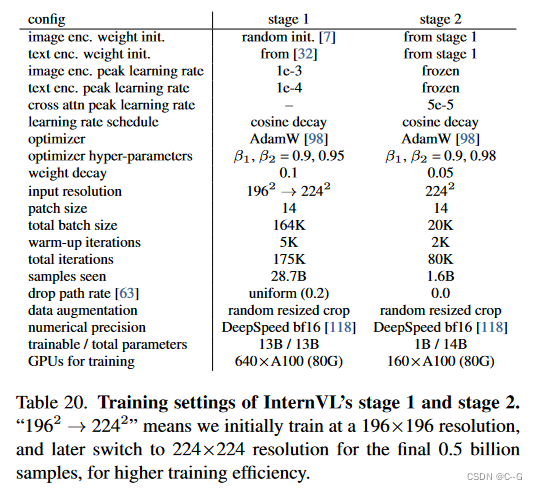
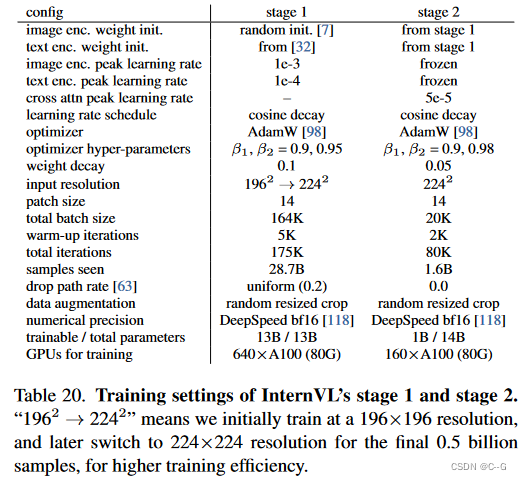
如下表所示,本阶段使用BEiT的初始化方法对图像编码器Internit - 6b进行随机初始化,对文本编码器LLaMA-7B使用多语种LLaMA-7B预训练的权值进行初始化。所有参数都是完全可训练的。使用了AdamW优化器,其中 β 1 β_1 β1 = 0.9, β 2 β_2 β2 = 0.95,权重衰减为0.1,余弦学习率分别从1e-3和1e-4开始。采用0.2的均匀掉落路径速率。该训练涉及640个A100 gpu的164K总批处理规模,扩展超过175K次迭代,处理约287亿个样本。为了提高效率,最初以196×196分辨率训练,屏蔽50%的图像标记,然后切换到224×224分辨率,不屏蔽最终的5亿个样本。
视觉语言生成训练

QLLaMA继承第一阶段的LLaMA-7B的权重。将Internit - 6b和QLLaMA保持冻结状态,只训练新添加的可学习queries和具有过滤的高质量数据的 cross attention。进一步过滤掉了标题质量较低的数据,从第一阶段的49.8亿减少到10.3亿,训练数据如下:

使用BLIP-2的损失函数,使得queries能够提取强大的视觉表示,并进一步将特征空间与LLMs对齐。
- image-text contrastive (ITC) loss
ITC的优化目标是对齐图像嵌入和文本嵌入,将来自Image Transformer输出的Query嵌入与来自Text Transformer输出的文本嵌入对齐,为了避免信息泄漏,ITC采用了单模态自注意掩码,不允许Query和Text相互注意。具体来说,Text Transformer的文本嵌入是 [CLS] 标记的输出嵌入,而Query嵌入则包含多个输出嵌入,因此首先计算每个Query输 嵌入与文本嵌入之间的相似度,然后选择最高的一个作为图像-文本相似度。
- image-text matching (ITM) loss
ITM是一个二元分类任务,通过预测图像-文本对是正匹配还是负匹配,学习图像和文本表示之间的细粒度对齐。这里将Image Transformer输出的每个Query嵌入输入到一个二类线性分类器中以获得对应的logit,然后将所有的logit平均,再计算匹配分数。ITM使用双向自注意掩码,所有Query和Text都可以相互关注。
- image-grounded text generation (ITG) loss
ITG 是在给定输入图像作为条件的情况下,训练 Q-Former 生成文本,迫使Query提取包含文本信息的视觉特征。由于 Q-Former 的架构不允许冻结的图像编码器和文本标记之间的直接交互,因此生成文本所需的信息必须首先由Query提取,然后通过自注意力层传递给文本标记。ITG采用多模态Causal Attention掩码来控制Query和Text的交互,Query可以相互关注,但不能关注Text标记,每个Text标记都可以处理所有Query及其前面的Text标记。这里将 [CLS] 标记替换为新的 [DEC] 标记,作为第一个文本标记来指示解码任务。
在这个阶段,Interviti - 6b和QLLaMA从第一阶段继承了它们的权值,而QLLaMA中的可学习queries和cross-attention是随机初始化的。得益于第一阶段学习到的强大编码能力,将internit - 6b和QLLaMA都保持冻结状态,只训练新增的参数。输入图像的处理分辨率为224×224。优化时,采用AdamW优化器,
β
1
β_1
β1 = 0.9,
β
2
β_2
β2 = 0.98,权值衰减设置为0.05,总批大小为20K。训练在160个A100 gpu上扩展超过80K步,包括2K热身步,并由余弦学习率计划控制,峰值学习率为5e-5。下表列出了更详细的培训设置。
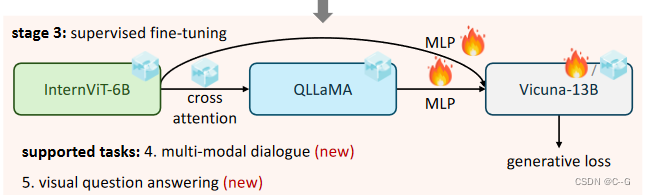
监督微调三个递进阶段
InternVL创建多模态对话系统中的优势,通过MLP层将其与现有的LLM解码器(例如Vicuna或InternLM)连接起来,并进行监督微调(SFT)。训练数据如下:
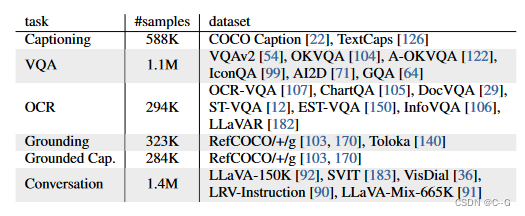
使用大量高质量的指令数据,总计约400万个样本,对于非对话数据集,遵循[Improved baselines with visual instruction tuning]中描述的方法进行转换,由于QLLaMA和LLMs的特征空间相似,即使冻结LLM解码器,也可以选择只训练MLP层或同时训练MLP层和QLLaMA,从而获得鲁棒性能。这种方法不仅加快了SFT过程,而且保持了llm的原始语言能力
在这个阶段,有两种不同的构型。一种是单独使用InternViT-6B,如下图(c) 所示。另一种是同时使用整个InternVL模型,如下图 (d)所示
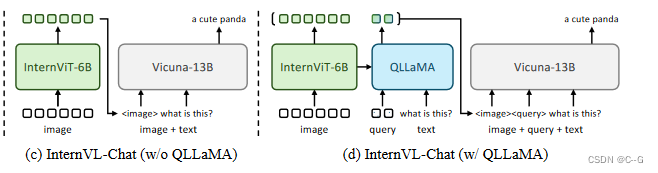
- Internv1 -chat(无QLLaMA):对于这个设置,遵循LLaVA-1.5的训练策略。使用相同的超参数和数据集进行监督调优,即首先使用LGS- 558k数据集训练MLP层,然后使用LLaVA-Mix-665k数据集训练LLM,两者都是一个epoch。
- InternVL-Chat (w/ QLLaMA):对于这个更高级的设置,也分两个步骤进行了培训。首先用自定义的SFT数据集训练MLP层,然后用它对LLM进行微调。由于数据集的扩展,将批处理大小增加到512。
Settings of Retrieval Fine-tuning
在实验中,将InternVL的所有参数设置为可训练的。分别对Flickr30K和Flickr30KCN进行了微调。按照惯例,采用364×364分辨率进行微调。为了避免过度拟合,对internit - 6b和QLLaMA都采用了0.9的分层学习率衰减,同时对Internit - 6b采用了0.3的下降路径率。使用总批大小为1024的AdamW优化器对10个epoch的InternVL模型进行微调。更详细的培训设置请参见下表。
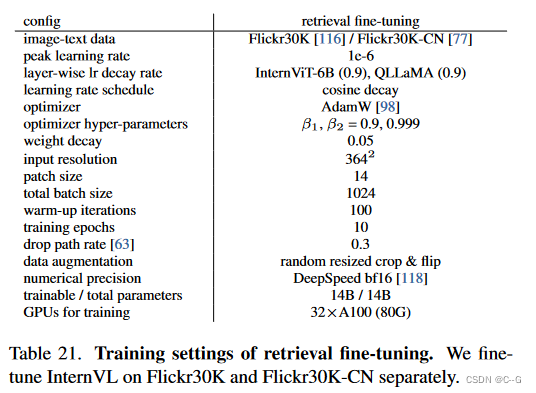
Settings of ImageNet Linear Probing
在之前的方法中遵循Linear Probing的常见做法。具体来说,在训练过程中使用了额外的BatchNorm来规范化预训练的骨干特征。此外,将平均池补丁令牌特征与类令牌连接起来。线性头部在ImageNet-1K上使用SGD优化器训练了10个epoch,总批大小为1024,峰值学习率为0.2,1 epoch预热,没有权重衰减。数据增强包括随机大小裁剪和翻转。更多培训细节见下表。
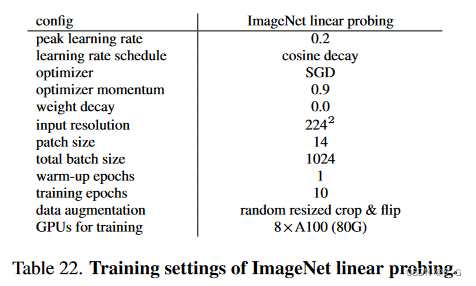
Settings of ADE20K Semantic Segmentation.
下表列出了ADE20K语义分割中三种不同配置的超参数,包括线性探测、头部调优和全参数调优。
InternVL
通过灵活地结合视觉编码器和语言中间件,InternVL可以支持各种视觉或视觉语言任务。

- 对于视觉感知任务,可以使用InternVL的视觉编码器Internviti - 6b作为视觉任务的主干。给定输入图像 I ∈ R H × W × 3 I∈R^{H×W ×3} I∈RH×W×3,模型可以生成特征映射 F ∈ R H / 14 × W / 14 × D F∈R^{H/14×W/14×D} F∈RH/14×W/14×D用于密集预测任务,或者使用全局平均池化和线性投影进行图像分类。
- 对于对比任务,如上图 (a) (b)所示,引入了InternVL-C和InternVLG两种推理模式,使用视觉编码器或结合使用InternViT和QLLaMA对视觉特征进行编码。具体来说,将注意力池应用于Intervit的视觉特征或QLLaMA的查询特征,计算全局视觉特征 I f I_f If。此外,通过从QLLaMA的[EOS]令牌中提取特征,将文本编码为 T f T_f Tf。通过计算 I f I_f If和 T f T_f Tf之间的相似度得分,支持各种对比任务,如图像-文本检索。
- 对于生成任务,与QFormer不同,QLLaMA由于其按比例放大的参数,固有地具有很好的 image captioning 能力。QLLaMA的 queries 对来自Internet - 6b的可视化表示进行重组,并作为QLLaMA的前缀文本。随后的文本令牌依次生成。
- 对于多模态对话,引入了InternVLChat,利用InternVL作为与LLMs连接的可视化组件。为此,有两种不同的配置。一种选择是独立使用InternViT-6B,如上图 (c)所示。另一种选择是同时使用完整的InternVL模型,如上图 (d)所示。
datasets used in stage 1 and stage 2
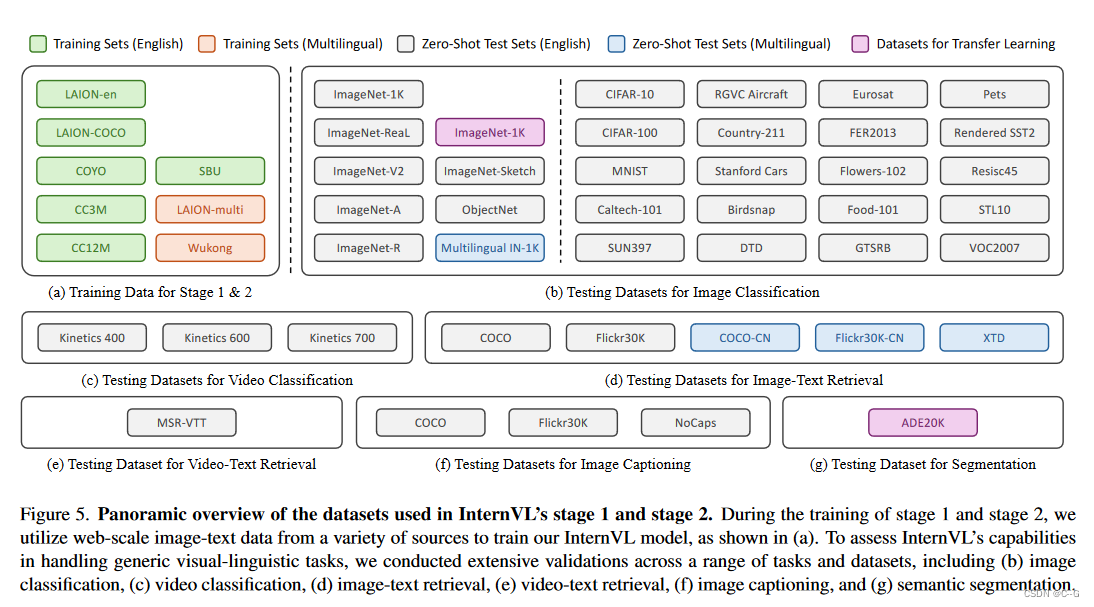
在第1阶段和第2阶段的训练中,我用来自各种来源的网络规模的图像文本数据来训练InternVL模型,如(a)所示。为了评估InternVL处理通用视觉语言任务的能力,在一系列任务和数据集上进行了广泛的验证,包括(b)图像分类,(c)视频分类,(d)图像文本检索,(e)视频文本检索,(f)图像字幕和(g)语义分割。

