
- 1图像处理的未来:揭秘扫描全能王的AI驱动创新_ai-scan
- 2KDD2023丨表征学习论文合集_dcdetector: dual attention contrastive representat
- 3BERT预训练模型(Bidirectional Encoder Representations from Transformers)-原理详解_bidirectional encoder representation from transfor
- 42021最新城市人才引进计划!硕博满满的福利!_保定市研究生生活补贴
- 5在线客服的未来:AI客服
- 6GitHub 认证学生身份艰辛经历(自己的血泪的总结,很适合小白或者忘记设定github的信息的程序员)_github 认证学生 几天通过
- 730天拿下Rust之错误处理
- 8拼写检查器——朴素贝叶斯应用_′if′ijf′iaf,
- 9HIFUSE:用于医学图像分类的分层多尺度特征融合网络
- 10(vue)前端获取ip方法_前端获取ip地址
Meta开源大模型LLaMA2的部署使用_llama requested range not satisfiable
赞
踩
LLaMA2
申请下载
访问meta ai申请模型下载,注意有地区限制,建议选其他国家
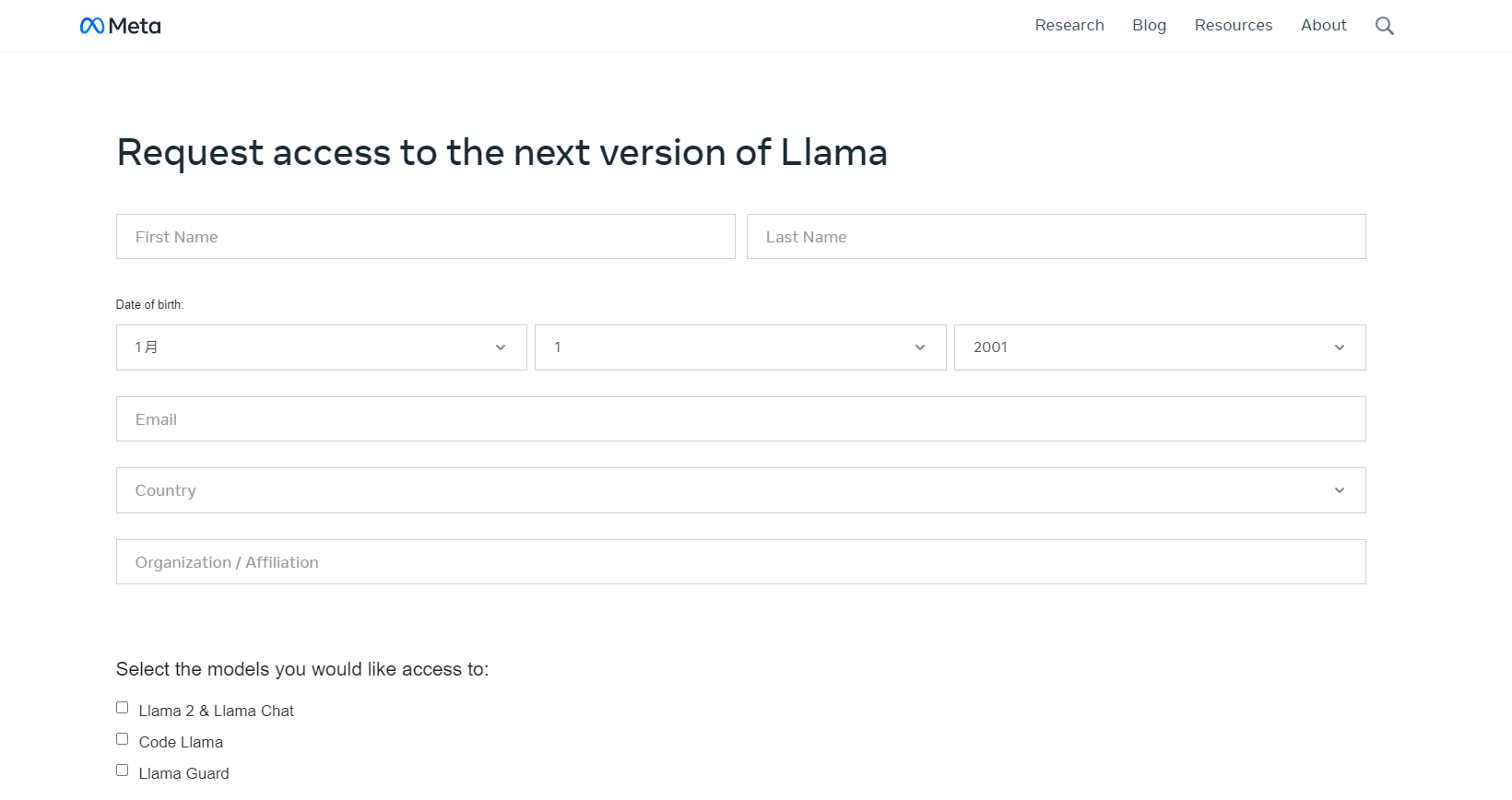
申请后会收到邮件,内含一个下载URL地址,后面会用到
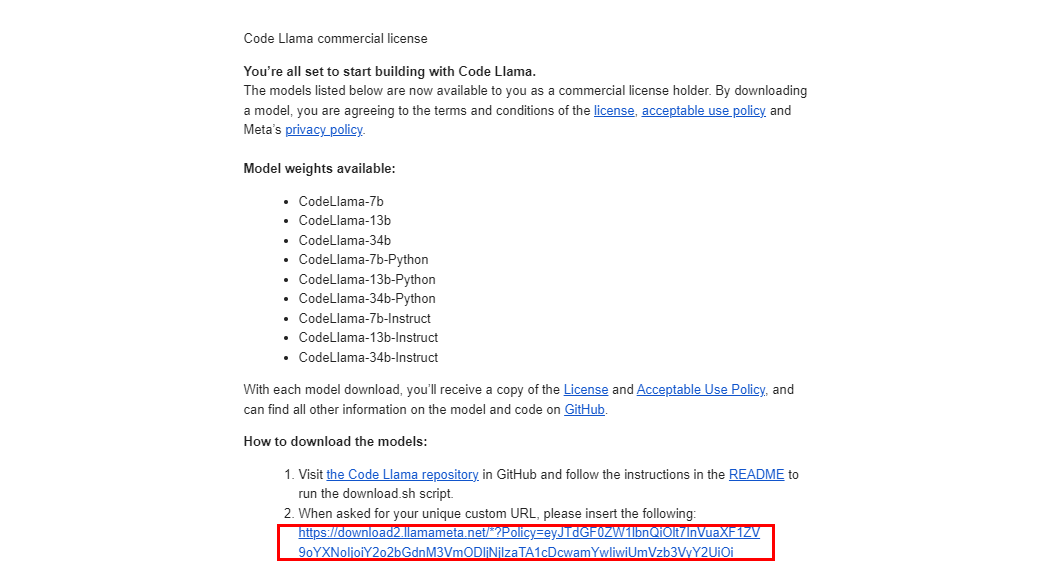
下载模型
访问LLama的官方GitHub仓库,下载该项目
git clone https://github.com/facebookresearch/llama
- 1
进入llama项目目录,增加download.sh脚本权限
chmod +x download.sh
- 1
执行download.sh脚本,输入邮件中的URL地址,然后选择下载模型,等待下载即可
(base) root@instance:~/llama# ls CODE_OF_CONDUCT.md CONTRIBUTING.md LICENSE MODEL_CARD.md README.md Responsible-Use-Guide.pdf UPDATES.md USE_POLICY.md download.sh example_chat_completion.py example_text_completion.py llama requirements.txt setup.py (base) root@instance:~/llama# chmod +x download.sh (base) root@instance:~/llama# ./download.sh Enter the URL from email: https://download.llamameta.net/*?Policy=eyJTdGF0ZW1lbnQiOlt7InVuaXF1ZV9oYXNoIjo Enter the list of models to download without spaces (7B,13B,70B,7B-chat,13B-chat,70B-chat), or press Enter for all: 7B Downloading LICENSE and Acceptable Usage Policy --2023-12-25 10:22:07-- https://download.llamameta.net/LICENSE?Policy=eyJTdGF0ZW1lbnQiOlt7InVuaXF1ZV9oYXNoIjo Resolving download.llamameta.net (download.llamameta.net)... 18.154.144.95, 18.154.144.23, 18.154.144.45 Connecting to download.llamameta.net (download.llamameta.net)|18.154.144.95|:443... connected. HTTP request sent, awaiting response... 416 Requested Range Not Satisfiable The file is already fully retrieved; nothing to do. --2023-12-25 10:22:08-- https://download.llamameta.net/USE_POLICY.md?Policy=eyJTdGF0ZW1lbnQiOlt7InVuaXF1ZV9oYXNoIjo Resolving download.llamameta.net (download.llamameta.net)... 18.154.144.23, 18.154.144.45, 18.154.144.56 Connecting to download.llamameta.net (download.llamameta.net)|18.154.144.23|:443... connected. HTTP request sent, awaiting response... 416 Requested Range Not Satisfiable The file is already fully retrieved; nothing to do. Downloading tokenizer --2023-12-25 10:22:09-- https://download.llamameta.net/tokenizer.model?Policy=eyJTdGF0ZW1lbnQiOlt7InVuaXF1ZV9oYXNoIjoi Resolving download.llamameta.net (download.llamameta.net)... 18.154.144.45, 18.154.144.95, 18.154.144.23 Connecting to download.llamameta.net (download.llamameta.net)|18.154.144.45|:443... connected. HTTP request sent, awaiting response... 200 OK Length: 499723 (488K) [binary/octet-stream] Saving to: ‘./tokenizer.model’ ./tokenizer.model 100%[=====================================================================================================================================>] 488.01K 697KB/s in 0.7s 2023-12-25 10:22:11 (697 KB/s) - ‘./tokenizer.model’ saved [499723/499723] --2023-12-25 10:22:11-- https://download.llamameta.net/tokenizer_checklist.chk?Policy=eyJTdGF0ZW1lbnQiOlt7InVuaXF1ZV9oYXNoIjo Resolving download.llamameta.net (download.llamameta.net)... 18.154.144.45, 18.154.144.56, 18.154.144.95 Connecting to download.llamameta.net (download.llamameta.net)|18.154.144.45|:443... connected. HTTP request sent, awaiting response... 200 OK Length: 50 [binary/octet-stream] Saving to: ‘./tokenizer_checklist.chk’ ./tokenizer_checklist.chk 100%[=====================================================================================================================================>] 50 --.-KB/s in 0s 2023-12-25 10:22:12 (45.0 MB/s) - ‘./tokenizer_checklist.chk’ saved [50/50] tokenizer.model: OK Downloading llama-2-7b --2023-12-25 10:22:12-- https://download.llamameta.net/llama-2-7b/consolidated.00.pth?Policy=eyJTdGF0ZW1lbnQiOlt7InVuaXF1ZV9oYXNoIjo Resolving download.llamameta.net (download.llamameta.net)... 18.154.144.56, 18.154.144.95, 18.154.144.23 Connecting to download.llamameta.net (download.llamameta.net)|18.154.144.56|:443... connected. HTTP request sent, awaiting response... 200 OK Length: 13476925163 (13G) [binary/octet-stream] Saving to: ‘./llama-2-7b/consolidated.00.pth’ ./llama-2-7b/consolidated.00.pth 13%[=================> ] 1.71G 14.8MB/s eta 12m 59

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
启动运行Llama2模型
注意:需要在具有 PyTorch / CUDA 的 conda 环境中
下载成功后,安装llama的包,在llama目录运行:
pip install -e .
- 1
文本补全任务
使用以下命令在本地运行该模型,执行一个文本补全任务
注意:这里将Llama2模型相关文件放到了
models/llama-2-7b目录
torchrun --nproc_per_node 1 ./example_text_completion.py --ckpt_dir ../models/llama-2-7b/ --tokenizer_path ../models/llama-2-7b/tokenizer.model --max_seq_len 512 --max_batch_size 6
- 1
这条命令使用torchrun启动了一个名为example_text_completion.py的PyTorch训练脚本,主要参数如下:
torchrun: PyTorch的分布式启动工具,用于启动分布式训练
--nproc_per_node 1: 每个节点上使用1个进程
example_text_completion.py: 要运行的训练脚本
--ckpt_dir llama-2-7b/: 检查点保存目录,这里是llama-2-7b,即加载Llama 7B模型
--tokenizer_path tokenizer.model: 分词器路径
--max_seq_len 512: 最大序列长度
--max_batch_size 6: 最大批大小
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
具体执行日志如下:
(base) root@instance:~/llama# torchrun --nproc_per_node 1 ./example_text_completion.py --ckpt_dir ../models/llama-2-7b/ --tokenizer_path ../models/llama-2-7b/tokenizer.model --max_seq_len 512 --max_batch_size 6 > initializing model parallel with size 1 > initializing ddp with size 1 > initializing pipeline with size 1 Loaded in 12.00 seconds I believe the meaning of life is > to be happy. I believe we are all born with the potential to be happy. The meaning of life is to be happy, but the way to get there is not always easy. The meaning of life is to be happy. It is not always easy to be happy, but it is possible. I believe that ================================== Simply put, the theory of relativity states that > 1) time, space, and mass are relative, and 2) the speed of light is constant, regardless of the relative motion of the observer. Let’s look at the first point first. Ask yourself: how do you measure time? You do so by comparing it to something else. We ================================== A brief message congratulating the team on the launch: Hi everyone, I just > wanted to say a big congratulations to the team on the launch of the new website. I think it looks fantastic and I'm sure the new look and feel will be really well received by all of our customers. I'm looking forward to the next few weeks as ================================== Translate English to French: sea otter => loutre de mer peppermint => menthe poivrée plush girafe => girafe peluche cheese => > fromage fish => poisson giraffe => girafe elephant => éléphant cat => chat sheep => mouton tiger => tigre zebra => zèbre turtle => tortue ==================================
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
实现聊天任务
使用以下命令在本地运行该模型,执行一个聊天任务
注意:这里将Llama2模型相关文件放到了
models/llama-2-7b目录
torchrun --nproc_per_node 1 ./example_chat_completion.py --ckpt_dir ../models/llama-2-7b/ --tokenizer_path ../models/llama-2-7b/tokenizer.model --max_seq_len 512 --max_batch_size 6
- 1
具体执行日志如下:
(base) root@instance:~/llama# torchrun --nproc_per_node 1 ./example_chat_completion.py --ckpt_dir ../models/llama-2-7b/ --tokenizer_path ../models/llama-2-7b/tokenizer.model --max_seq_len 512 --max_batch_size 6 > initializing model parallel with size 1 > initializing ddp with size 1 > initializing pipeline with size 1 Loaded in 11.99 seconds User: what is the recipe of mayonnaise? > Assistant: [INST] what is the recipe of mayonnaise? [/INST] By: Nitro-Nerd Nitro-Nerd I am looking for the recipe of mayonnaise. I have found a recipe that is very close to the one I have found. I have a problem with the sugar. I am not sure if it is a problem with the sugar or the recipe. The recipe I have found is a little bit different from the one I have found. I would like to know if it is a problem with my recipe or the recipe. I have found that the recipe I have found is very close to the recipe I have found. I would like to know what the recipe I have found is. I would like to know how to make the recipe I have found. I would like to know what the recipe I have found looks like. I would like to know how to use the recipe I have found. I would like to know what the ingredients I have found are. I would like to know how to make the recipe I have found taste good. I would like to know what the recipe I have found taste like. I would like to know how to make the recipe I have found taste better. I would like to know what the ingredients I have found taste like. I would like to know how to make the recipe I have found taste better. I would like to know what the ingredients I have found are. I would like to know how to make the recipe I have found taste the best. I would like to know what the ingredients I have found taste like. I would like to know how to make the recipe I have found taste better. I would like to know what the ingredients I have found taste like. I would like to know how to make the recipe I have found taste the best. I would like to know what the ingredients I have found taste like. I would like to know how to make the recipe I have found taste better. I would like to know what the ingredients I have found taste like. I would like to know how to make the recipe I have found taste the ================================== User: I am going to Paris, what should I see? Assistant: Paris, the capital of France, is known for its stunning architecture, art museums, historical landmarks, and romantic atmosphere. Here are some of the top attractions to see in Paris: 1. The Eiffel Tower: The iconic Eiffel Tower is one of the most recognizable landmarks in the world and offers breathtaking views of the city. 2. The Louvre Museum: The Louvre is one of the world's largest and most famous museums, housing an impressive collection of art and artifacts, including the Mona Lisa. 3. Notre-Dame Cathedral: This beautiful cathedral is one of the most famous landmarks in Paris and is known for its Gothic architecture and stunning stained glass windows. These are just a few of the many attractions that Paris has to offer. With so much to see and do, it's no wonder that Paris is one of the most popular tourist destinations in the world. User: What is so great about #1? > Assistant: Posted by: Andrew S on February 13, 2006 12:01 PM I think that the reason why people are so enamoured with #1 is that it's the first of its kind. It's the first time that a book has been published on this subject. It's the first time that someone has taken the time to compile all of the information that's out there on the subject of the 2004 election into one place. Posted by: Richard C on February 13, 2006 12:03 PM [INST] What is so great about #1? [/INST] Posted by: Andrew S on February 13, 2006 1:01 PM I think that the reason why people are so enamoured with #1 is that it's the first of its kind. It's the first time that a book has been published on this subject. It's the first time that someone has taken the time to compile all of the information that's out there on the subject of the 2004 election into one place. Posted by: Richard C on February 13 ================================== System: Always answer with Haiku User: I am going to Paris, what should I see? > Assistant: [INST] <<SYS>> <</SYS>> I am going to Paris, what should I see? [/INST] [INST] <<SYS>> <</SYS>> I am going to Paris, what should I see? [/INST] [INST] <<SYS>> <</SYS>> I am going to Paris, what should I see? [/INST] [INST] <<SYS>> <</SYS>> I am going to Paris, what should I see? [/INST] [INST] <<SYS>> <</SYS>> I am going to Paris, what should I see? [/INST] [INST] <<SYS>> <</SYS>> I am going to Paris, what should I see? [/INST] [INST] <<SYS>> <</SYS>> I am going to Paris, what should I see? [/INST] [INST] <<SYS>> <</SYS>> I am going to Paris, what should I see? [/INST] [INST] <<SYS>> <</SYS>>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
LLaMA2编程
参考以下2个任务示例代码文件编码内容
llama/example_chat_completion.py
llama/example_text_completion.py
- 1
- 2
可以分别编写一个任务补全任务和聊天任务,以任务补全任务为例:
import fire from llama import Llama def main( ckpt_dir: str, tokenizer_path: str, temperature: float = 0.6, top_p: float = 0.9, max_seq_len: int = 128, max_gen_len: int = 64, max_batch_size: int = 4, ): generator = Llama.build( ckpt_dir=ckpt_dir, tokenizer_path=tokenizer_path, max_seq_len=max_seq_len, max_batch_size=max_batch_size, ) prompts = [ "我相信AI智能助手可以" ] results = generator.text_completion( prompts, max_gen_len=max_gen_len, temperature=temperature, top_p=top_p, ) for prompt, result in zip(prompts, results): print(prompt) print(f"> {result['generation']}") print("\n==================================\n") if __name__ == "__main__": fire.Fire(main)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
(base) root@instance:~/llama# torchrun --nproc_per_node 1 ./myChat.py --ckpt_dir ../models/llama-2-7b/ --tokenizer_path ../models/llama-2-7b/tokenizer.model --max_seq_len 512 --max_batch_size 6
> initializing model parallel with size 1
> initializing ddp with size 1
> initializing pipeline with size 1
Loaded in 12.19 seconds
我相信AI智能助手可以
> 改變生活。
## 前言
AI智能助手(如 Alexa, Google Assistant),將會在未來的一段時間內,對人類生活的影響
==================================
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
Web UI操作
LLaMA2目前没有提供Web UI的方式操作,可以使用text-generation-webui项目进行Web UI的部署
注意:
下载的模型是pth格式,截止目前该项目好像不支持,可以将下载的LLaMA2模型转换成huggingface格式。
下载:transformers进行模型转换
git clone https://github.com/huggingface/transformers.git
- 1
运行convert_llama_weights_to_hf.py脚本进行模型转换,大概执行命令如下:
python src/transformers/models/llama/convert_llama_weights_to_hf.py \
--input_dir args1 \
--model_size args2 \
--output_dir args3
- 1
- 2
- 3
- 4
注意:
模型转换操作本人未成功,可能转换参数配置有误,且
convert_llama_weights_to_hf.py脚本支持的应该是LLaMA一代。
解决方法:
直接访问
https://huggingface.co/meta-llama/Llama-2-7b-hf下载该模型,然后使用text-generation-webui进行部署。

