
- 1NLP-文本蕴含(文本匹配):概述【单塔模型、双塔模型】_文本蕴含任务
- 2java 字符串分词_Java实现的双向匹配分词算法示例
- 3代码编译安全之classfinal-maven-plugin插件
- 4手把手教程 | 使用无服务器模板部署机器学习模型_离线服务器上部署机器学
- 5chatgpt 谷歌开源免费语言模型、本地部署、离线使用
- 6装饰工程管理系统|基于Springboot的装饰工程管理系统设计与实现(源码+数据库+文档)
- 7SQL server数据库端口访问法_sql server连接字符串带端口
- 8蓝桥杯练习——基础篇(10)_蓝桥杯编程竞赛指南第一章第十节
- 9操作系统面试题总结(2022最新版)_面试后端岗位,操作系统问什么
- 10批量打印,支持灵活按需筛选
学习大数据Hadoop——心得体会_hadoop实训报告总结及体会
赞
踩
1.项目总结
-- 1. HBase是什么?
1. 分布式
2. 可扩展
3. 支持海量数据的存储
4. NoSQL的数据库。
-- 2. 说明:
a、NoSQL: Not only SQL,不仅仅是一个数据库
b、是基于谷歌的三篇论文之bigtable生成的。
c、HBase:理解为Hadoop base
-- 3. 大数据框架:
a、数据的存储:hdfs / hive / hbase
b、数据的传输:flume / sqoop
c、数据的计算:tez / mr / spark / flink
-- 4. 和传统数据库的差别:
传统数据库的结构:数据库 --> 表 --> 行和列
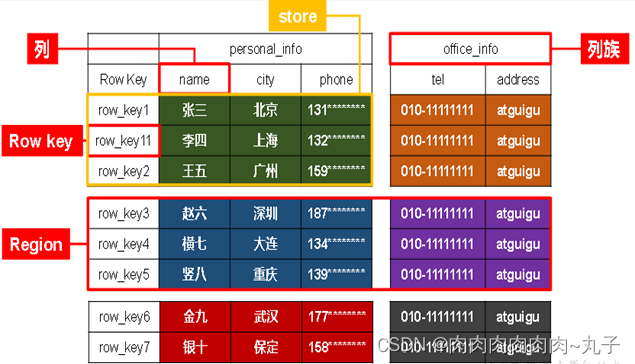
HBase的结构 : namespace(命名空间) --> table --> 列族 --> 行和列 --> orgion --> store
HBase可以理解为多维的map,嵌套的map结构。
HBase逻辑结构
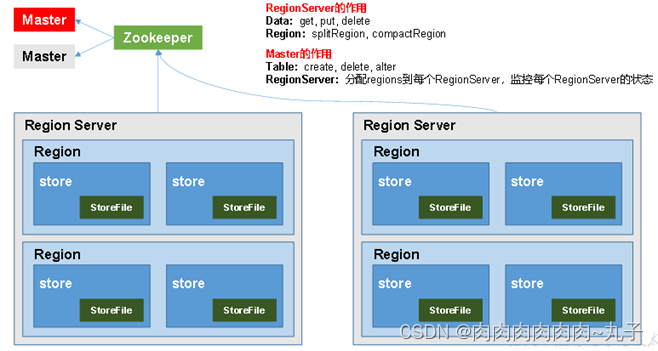
Hbase物理结构

数据模型
2.心得体会
互联网的快速发展带来了数据快速增加,海量数据的存储已经不是一台机器所能处理的问题了。Hadoop的技术就应运而生。在看了超人学院吴超老师的讲解之后,对这个概念有了一个比较系统的了解。可以讲Hadoop的核心内容看作是两个部分,一个是分布式存储,一个是分布式计算。
对于分布式存储,Hadoop有自己的一套系统来处理叫Hadoop distribution file system。为什么分布式存储需要一个额外的系统来处理呢,而不是就把1TB以上的文件分开存放就好了呢。如果不采用新的系统,我们存放的东西没办进行一个统一的管理。存放在A电脑的东西只能在连接到A去找,存在B的又得单独去B找。繁琐且不便于管理。而这个分布式存储文件系统能把这些文件分开存储的过程透明化,用户看不到文件是怎么存储在不同电脑上,看到的只是一个统一的管理界面。现在的云盘就是很好的给用户这种体验。
对于分布式计算。在对海量数据进行处理的时候,一台机器肯定也是不够用的。所以也需要考虑将将数据分在不同的机器上并行的进行计算,这样不经可以节省大量的硬件的I/O开销。也能够将加快计算的速度。Hadoop对分布式计算的系统为MapReduce。
Map即将数据分开存放进行计算,Reduce将分布计算的得到的结果进行整合,最后汇总得到一个最终的结果。这样对Hadoop的技术有一个清晰框架思路。

