
- 1咸鱼Maya笔记—动画约束_maya约束
- 2Git常用cmd命令_git cmd
- 313472_with the help of the textbook, you鈥檒l possibly spe
- 4双向链表的前插法和后插法创建_在链表中插入一个新的元素有两种方式:后插和前插。后插就是每次在链表的末尾插入
- 5聊天机器人ChatGPT指导下的论文写作
- 6基于某商产品WeblogicT3反序列化告警流量分析_漏洞利用类 weblogic t3协议流量
- 7SystemVerilog Assertions应用指南 第一章(1.28章节 内建的系统函数)_system verilog onehot检查
- 8HDU - 6289 寻宝游戏 详解(DP)_小q最近迷上了一款寻宝游戏,这款游戏中每局都会生成一个n\times m的网格地图,从上
- 9python flask socketio OpenSSL.SSL.Error_flask_socketio ssl_context
- 10html、css、京东移动端静态页面,资源免费分享,可作为参考,提供InsCode在线运行演示
2022届校招前端面试javascript篇1_6ggg
赞
踩
1.javascript中的数据类型?
目前一共有8种数据类型。ES5的时候有Number、String、Boolean、Undefined、Null、Object。ES6中新增了Symbol,这种类型的对象永不相等,即始创建的时候传入相同的值,可以解决属性名冲突的问题,做为标记。谷歌67版本中还出现了一种bigInt。是指安全存储、操作大整数。
衍生问题1:bigint是干嘛的?
BigInt数据类型是为了让JavaScript程序能表示超出Number 类型支持的数值范围( 2的53次方 - 1 )。在对大整数进行数学运算时,以任意精度表示整数的能力尤为重要。有了BigInt,整数溢出将不再是一个问题。
此外,你可以安全地使用高精度时间戳、大整数 ID 等,而不必使用任何变通方法。
要创建bigint,只需要在整数后面加上n即可。或者使用Bigint构造方法。
- console.log(9007199254740995n); // → 9007199254740995n
-
-
- BigInt("9007199254740995"); // → 9007199254740995n
衍生问题2:基本数据类型与引用数据类型有何区别?
- 内存分配不同:基本数据类型的值存储在栈内存中,访问变量直接访问到值。引用数据类型存储在堆内存中,存储在变量处的值是一个指针,该指针指向存储对象的内存地址。
- 访问机制不同:JavaScript不允许直接访问堆内存中的数据,因此在读取一个对象时先得到这个对象在堆内存中的地址,再按照这个地址去获取对象中的值,也就是按引用访问。而原始数据类型的值是可以直接通过读取栈内存得到的。
- 赋值变量时不同:基本数据类型在将一个变量复制给另一个变量时,会在栈内存中开辟新的存储空间来存放这个值。此后这两个变量是完全独立的。而引用数据类型在复制变量时只是将该对象存储在堆内存中的地址赋值给另一个变量,他们中任何一个对对象进行了修改都会改变对象的值。
衍生问题3:为什么typeof null是object?
因为javascript中不同对象在底层都表示为二进制,而javascript 中会把二进制前三位都为0的判断为object类型,而null的二进制表示全都是0,自然前三位也是0,所以执行typeof时会返回'object。 ----引用自《你不知道的javascript(上卷)》
衍衍生问题1:为什么typeof null是object类型,但是却是存储在栈内存中?
因为存储在栈内存中的值是有确定空间大小或者有上限的值,null的大小是确定的,因此存储在栈内存中。
衍生问题4:详细说一下symbol类型?(有什么作用?它的使用场景?ES5如何实现?)
symbol用来表示独一无二的值,它的作用时防止对象的属性名称冲突,也可以用来模拟在对象上创建私有属性。当请求某个接口返回一个对象时,你想往该对象添加属性或者方法,但是不知道之前该名称是否已经被设置过,就可以使用symbol。
- //用symbol实现
- var Person = (function() {
- let _name = Symbol(); //注意不是new Symbol() symbol没有构造函数,因此不能new
- class Person {
- constructor(name) {
- this[_name] = name;
- }
-
- get name() {
- return this[_name];
- }
- }
- return Person;
- })();
-
- let person = new Person('4ggg')
-
- console.log(person); //Person {Symbol(): "4ggg"}
- console.log(person.name); //4ggg
-
- //若此时执行
- person.name = '5ggg' //w报错 [system] TypeError: Cannot set property name of #<Person> which has only a getter
-
-
-

其实质在于匿名函数中的 Symbol 实例 _name 是局部变量,在外部不可访问。而 Symbol 由于自身的唯一性特点,也没法再造一个相同的出来,所以就模拟出来一个私有成员了。
按照此思路,在 ES5 中其实也很容易模拟私有成员。局部变量是很容易做到的,在函数范围内 let 和 var 是一样的效果。问题在于模拟 Symbol 的唯一性。
ES5 没有 Sybmol,属性名称只可能是一个字符串,如果我们能做到这个字符串不可预料,那么就基本达到目标。要达到不可预期,一个随机数基本上就解决了。
- //ES5实现
-
- var Person = (function() {
- var _name = "00" + Math.random();
- function Person(name) {
- this[_name] = name;
- }
-
- Object.defineProperty(Person.prototype, "name", {
- get: function() {
- return this[_name];
- }
- });
-
- return Person;
- })();
-
- let person = new Person('4ggg')
-
- console.log(person); //Person {000.17976586667226235: "4ggg"}
- console.log(person.name); //4ggg
-
-
- person.name = '5ggg' //同样报错
小问题1:为什么Object.defineProperty要将属性设置在原型上(Person.prototype)而不设置在构造函数(Person)中?
1、把方法写在原型中比写在构造函数中消耗的内存更小,因为在内存中一个构造函数的原型只有一个,写在原型中的行为可以被所有实例共享,实例化的时候并不会在实例的内存中再复制一份而写在构造函数中的方法,实例化的时候会在每个实例中再复制一份,所以消耗的内存更高。
所以没有特殊原因,我们一般把属性写到构造函数中,而行为写到原型中。
2、构造函数中定义的属性和方法要比原型中定义的属性和方法的优先级高,如果定义了同名称的属性和方法,构造函数中的将会覆盖原型中的

小问题2:通过原型链封装库属性,写在构造函数里好还是原型链上好?
要看这个属性的用途。如果这个属性需要被实例共享,那么就写在原型内。如果不想被共享,就写在构造函数内。《JavaScript高级程序(第三版)》 p158
2.JavaScript中的this指向?谈谈call apply bind的不同?
先说答案:call apply bind都是用于改变函数运行时this的指向。call和apply几乎相同,不同的在于call函数第二个参数开始需要传入的是参数列表,而apply需要传入的是参数数组。而bind方法从第二个参数开始是接收的参数列表,与call区别在于bind方法返回值是函数。懂的可以直接跳过下面。
- var name = '4ggg',age=18;
- var obj1 = {
- name:'5ggg',
- myFun:function(){
- console.log(`姓名:${this.name},年龄:${this.age}`);
- }
- }
-
- obj1.myFun() //姓名:5ggg,年龄:undefined 此时myFun里面的this指向obj1的内部
-
-
-
-
- var obj2 = {
- name:'6ggg',
- age:20
- }
-
- obj1.myFun.call(obj2); //姓名:6ggg,年龄:20
- obj1.myFun.apply(obj2); //姓名:6ggg,年龄:20
- obj1.myFun.bind(obj2)(); //姓名:6ggg,年龄:20
-
-
call、apply、bind的作用是改变函数运行时this的指向。
- obj1.myFun()
- //相当于
- obj1.myFun.call(obj1); //指向当前对象
-
-
-
- var fn1 = obj1.myFun
- fn1() //相当于fn1.call(null) 也就是指向window对象
-
-
call 方法第一个参数是要绑定给this的值,后面传入的是一个参数列表。当第一个参数为null、undefined的时候,默认指向window。obj1.(method).call(obj2,argument1,argument2) ,call的作用就是把obj1的方法放到obj2上使用,后面的argument1..这些做为参数传入。
语法:call([thisObject[,arg1 [,arg2 [,...,argn]]]]);,应用某一对象的一个方法,用另一个对象替换当前对象。
说明: call方法可以用来代替另一个对象调用一个方法,call方法可以将一个函数的对象上下文从初始的上下文改变为thisObj指定的新对象,如果没有提供thisObj参数,那么Global对象被用于thisObj。
- var obj = {
- message: 'My name is: '
- }
-
- function getName(firstName, lastName) {
- console.log(this.message + firstName + ' ' + lastName)
- }
-
- getName.call(obj, '4', 'ggg') //My name is: 4 ggg
apply接受两个参数,第一个参数是要绑定给this的值,第二个参数是一个参数数组。当第一个参数为null、undefined的时候,默认指向window。
- var obj = {
- message: 'My name is: '
- }
-
- function getName(firstName, lastName) {
- console.log(this.message + firstName + ' ' + lastName)
- }
-
- getName.apply(obj, ['5', 'ggg'])// My name is: 5 ggg
-
-
apply 和 call都是function原型对象上的方法,二者的用法几乎相同, 唯一的差别在于:当函数需要传递多个变量时, apply 可以接受一个数组作为参数输入, call 则是接受一系列的单独变量。
- var Person1 = function () {
- this.name = '4ggg';
- }
-
- var Person2 = function () {
- this.age = 18
- this.getname = function () {
- console.log(this.name);
- }
- this.getage = function () {
- console.log(this.age);
- }
- Person1.call(this); //借调
- }
-
-
- var person = new Person2();
- person.getname(); // 4ggg
- person.getage(); //18
从上面我们看到,Person2 实例化出来的对象 person 通过 getname 方法拿到了 Person1 中的 name。因为在 Person2 中,Person1.call(this) 的作用就是使用 Person1 对象代替 this 对象,那么 Person2 就有了 Person1 中的所有属性和方法了,相当于 Person2 继承了 Person1 的属性和方法。
对于什么时候该用什么方法,其实不用纠结。如果你的参数本来就存在一个数组中,那自然就用 apply,如果参数比较散乱相互之间没什么关联,就用 call。
也可以通过下面的图来进一步理解其过程:
- var Person1 = function () {
- console.log('11111');
- console.log(this);
- console.log('11111');
- this.name = '4ggg';
- console.log('2222');
- console.log(this);
- console.log('2222');
- }
-
- var Person2 = function () {
- console.log('开始实例化...');
- this.getname = function () {
- console.log(this.name);
- }
- console.log('33333');
- console.log(this);
- console.log('33333');
- Person1.call(this);
- console.log('44444');
- console.log(this);
- console.log('44444');
- console.log('实例化完成');
- }
-
- var person = new Person2();
- person.getname(); // 4ggg

bind和call很相似,第一个参数是this的指向,从第二个参数开始是接收的参数列表。区别在于bind方法返回值是函数以及bind接收的参数列表的使用。
- var obj = {
- name: '4ggg'
- }
-
- var fun1 = function printName() {
- console.log(this.name)
- }
-
- var a = fun1.bind(obj)
- console.log(a) // function () { … }
- a() // 4ggg
测试题1:
- var a = {
- name:'aa',
- func:function(){
- console.log(this.name);
- }
- }
-
- a.func()
-
- var fun1 = a.func;
- fun1()
-
- a.func.apply({name:'bb'})
答案是: aa 报错name未定义 bb
衍生问题:实现一个bind函数?
- Function.prototype._bind = function(scope,...args){
- return (...rest)=>{
- scope.apply(this,args.concat(rest))
- }
- }
3.说说下面打印出的值(typeof instanceof)?
- console.log(typeof null);
-
- console.log(typeof undefined);
-
- var a = function(){}
- console.log(typeof a);
-
- var b = Symbol()
- console.log(typeof b);
-
- console.log(typeof NaN);
-
- var c = []
- console.log(typeof c);
-
- var d = {}
- console.log(typeof d);
-
-
-
- //分别是object undefined function symbol number object object
-
-
-
- console.log([] instanceof Array);
- console.log([] instanceof Object);
-
- console.log({} instanceof Object);
-
- console.log(new Date() instanceof Date);
- console.log(new Date() instanceof Object);
-
- function Person(){};
- console.log(new Person() instanceof Person);
- console.log(new Person instanceof Object);
-
-
-
- //全都是true
衍生问题1:typeof instanceof有什么作用?
typeof的返回值是一个字符串,该字符串用来表示判断的变量的类型。
instanceof 是用于判断一个变量是否属于某个对象的实例,也可以在继承关系中用来判断一个实例是否属于它的父类型。
。返回值是布尔类型。
衍生问题2:使用instancdof判断数组会有什么弊端?
使用instancdof判断数组只适用于单执行环境(窗口),如果该窗口有其他框架(比如 iframe)则会出问题。
为什么?
因为Array在js中属于引用类型,并且Array是挂在window下的一个属性,window属性也就是一个窗口的实例,那就说明不同的页面是不同window实例,因此它们也就不同了。
衍衍生问题1:讲讲js中的原型?原型链?
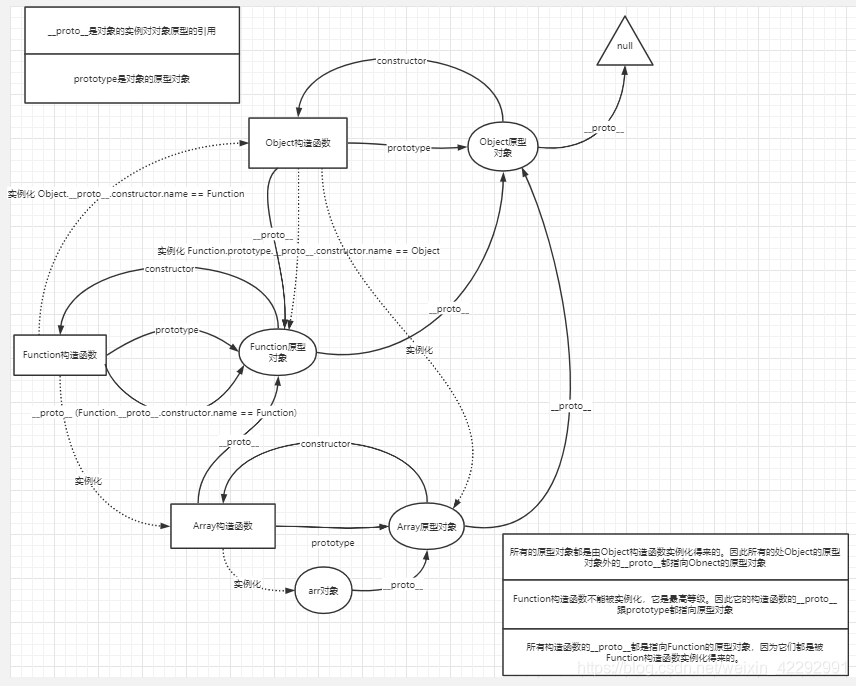
原型:所有的函数都有一个特殊的属性prototype(原型),prototype属性是一个指针,指向的是一个对象(原型对象),原型对象中的方法和属性都可以被函数的实例所共享。所谓的函数实例是指以函数作为构造函数创建的对象,这些对象实例都可以共享构造函数的原型的方法。
原型链:原型链是用于查找引用类型(对象)的属性,查找属性会沿着原型链依次进行,如果找到该属性会停止搜索并做相应的操作,否则将会沿着原型链依次查找直到结尾。常见的应用是用在创建对象和继承中。
衍衍生问题2:如何实现instanceof?
- function instance_of(L, R) {//L 表示左表达式,R 表示右表达式
- var O = R.prototype;
- L = L.__proto__;
- while (true) {
- if (L === null) return false;
- if (O === L) return true; // 这里重点:当 O 严格等于 L 时,返回 true
- L = L.__proto__;
- }
- }
再来一个问题:__proto__与prototype有什么区别?prototype有什么作用?
prototype是一个对象的原型对象,而__proto__则是对象的实例对原型对象的引用。
js在实例化对象时,同一个构造函数的对象实例之间无法共享属性和方法,因此提供了prototype属性来解决该问题。
- var arr = [1,2,3];
-
- console.log(arr.constructor.name); //Array
- console.log(arr.__proto__.constructor.name); //Array
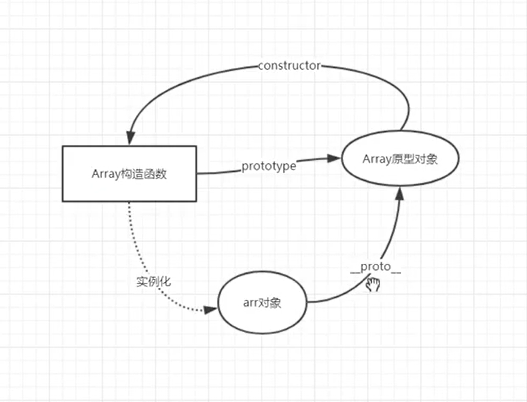
- console.log(Array.__proto__.constructor.name); //Function
- console.log(Function.__proto__.constructor.name); //Function Function处于原型链顶层
只有构造函数才有prototype。
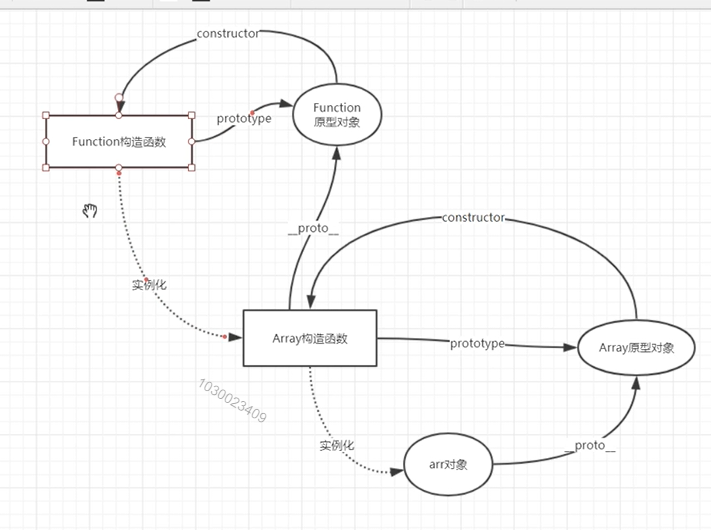
console.log(Function.prototype.__proto__.constructor.name); //Object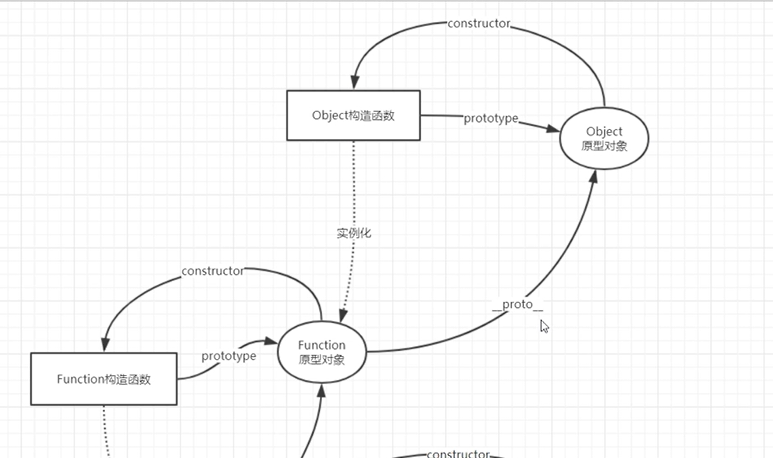
最难问题:画一下js中的原型链?
再来点问题:说说下列的结果?
- Function.prototype.a = 'a';
- Object.prototype.b = 'b';
-
- function Person(){};
- var p = new Person();
-
- console.log(p.a);
- console.log(p.b);
第一个是undefined 第二个是b
有不少人第一眼看上去就觉得很疑惑,p不是应该继承了Function原型里面的属性吗,为什么p.a返回值是undefined呢?
其实,只要仔细想一想就很容易明白了,Person函数才是Function对象的一个实例,所以通过Person.a可以访问到Function
原型里面的属性,但是new Person()返回来的是一个对象,它是Object的一个实例,是没有继承Function的,所以无法访问
Function原型里面的属性。但是,由于在js里面所有对象都是Object的实例,所以,Person函数可以访问到Object原型里面的
属性,Person.b => 'b'
衍生问题2:如何判断是否是数组?
- function isArray (obj) {
- return obj instanceof Array;
- }
-
-
- function isArray (obj) {
- return Array.isArray(obj);
- }
-
-
- function isArray (obj) {
- return Object.prototype.toString.call(obj) === '[object Array]';
- }
衍生问题3:如何判断一个空对象?
- //1.JSON.stringify
- let obj= {};
- console.log(JSON.stringify(obj) === '{}'); // 返回true
-
-
- //2.Object.keys
- let obj= {};
- console.log(Object.keys(obj).length === 0); // true
-
- //3.for...in
- let obj= {};
- let checkObject = function (obj) {
- for (let keys in obj) {
- return false;
- }
- return true;
- }
- console.log(checkObject(obj)); // 返回true
4.下面打印出的是什么?
- console.log(null == undefined)
- console.log(null === undefined)
-
-
-
-
-
-
- //true false
null和undefined 两者相等,但是当两者做全等比较时,两者又不等。实际上,undefined值是派生自null值的,ECMAScript标准规定对二者进行相等性测试要返回true。
衍生问题:null和undefined的区别?
null: Null类型,代表“空值”,代表一个空对象指针,使用typeof运算得到 “object”,所以可以认为它是一个特殊的对象值。即表示"没有对象",即该处不应该有值。
undefined表示"缺少值",就是此处应该有一个值,但是还没有定义。
衍生问题1:说说下列打印的是什么?
- console.log([] == ![])
-
- console.log({} == !{})
true false

而对于{} == !{}
{} == ! {} -> {} == false -> {} == Number(false) -> {} == 0 -> ({}).toString() == 0 -> [object Object] == 0 -> false
- [] == 0 //返回结果是 true
- ![] == 0 //返回结果是 true
- [] == '' //返回结果是 true
- !![] == '' //返回结果是 false
- '' == true //返回结果是 false
5.什么是闭包?有什么作用?有什么缺点?
闭包是指有权访问另外一个函数作用域中的变量的函数。当一个嵌套的内部函数引用了嵌套的外部函数的变量(函数)时,就产生了闭包。如:
- function test1(){
- var age = 18;
- return function test2(){
- age++
- return age
- }
- }
-
- var fn = test1()
- console.log(fn()) //19
它的最大用处有两个,一个是可以读取函数内部的变量,另一个就是让这些变量的值0始终保持在内存中,不会在test1调用后被自动清除。
缺点:函数执行完成后,函数内部的局部变量没有释放,会持续占用内存,有可能导致内存泄漏。解决方法:把变量设置为null。
衍生问题1:闭包一定会造成内存泄漏吗?
由于IE的js对象和DOM对象使用不同的垃圾收集方法,因此闭包在IE中会导致内存泄露问题,也就是无法销毁驻留在内存中的元素 。
衍衍生问题1:内存泄漏和内存溢出的区别?
内存溢出
内存溢出一般是指执行程序时,程序会向系统申请一定大小的内存,当系统现在的实际内存少于需要的内存时,就会造成内存溢出。内存溢出造成的结果是先前保存的数据会被覆盖或者后来的数据会没地方存
内存泄漏
内存泄漏是指程序执行时,一些变量没有及时释放,一直占用着内存 而这种占用内存的行为就叫做内存泄漏。作为一般的用户,根本感觉不到内存泄漏的存在。真正有危害的是内存泄漏的堆积,这会最终消耗尽系统所有的内存。从这个角度来说,一次性内存泄漏并没有什么危害,因为它不会堆积。
内存泄漏如果一直堆积,最终会导致内存溢出问题
衍生问题2:闭包是不回收引用的那个对象还是不回收外部整个作用域,你是怎么验证这一点的?
我认为是不回收整个外部作用域的。例如如果将闭包函数赋值给一个全局变量,那么他就被全局变量所引用,整个外部作用域也就不会被回收。但是闭包函数内部没有被引用的对象可能就会被GC回收。
例如下面的age属性。虽然整个外部作用域被挂载,但是age本身没有被引用。
- function foo(){
- var name = "hello",
- age = 18;
-
- return function(){
- return name;
- }
- }
-
-
- var func = foo()
- console.log(func()) //hello
衍生问题2:说说下面输出的是什么?
- var name = "4ggg";
-
- var object = {
- name : "5ggg",
- getNameFunc : function(){
- return function(){
- return this.name;
- };
- }
- };
-
- console.log(object.getNameFunc()());
-
- //相当于
- var f = object.getNameFunc();
- f();
-
- //如果改变this的指向
- f.call(object) //5ggg
此时打印的是4ggg,因为此时里面的闭包函数是在window作用域下执行的,也就是说,this指向windows,因此打印的是全局变量。调用 f() 的是后是直接调用的!形象一点说就是裸调用。这样调用 f 没有和任何对象绑定,因此 f() 内部默认绑定到全局对象,所以里面的 this 指向的就是全局对象。
- var name = "4ggg";
-
- var object = {
- name : "5ggg",
- getNameFunc : function(){
- var that = this;
- return function(){
- return that.name;
- };
- }
- };
-
- console.log(object.getNameFunc()());
此时打印的是5ggg,因为在执行闭包函数时that就是父级函数getNameFunc的作用域,也就是object的内部。
再来一个:
- let name = 'global';
- function getName() {
- name = 'local';
- return function() {
- return name;
- }
- }
-
- let getPrivate = getName();
-
- console.log(name);
- console.log(getPrivate());
答案是:local local
如果改成:
- let name = 'global';
- function getName() {
- let name = 'local';
- return function() {
- return name;
- }
- }
- let getPrivate = getName();
- console.log(name);
- console.log(getPrivate());
则答案是:global local
衍衍生问题1:什么是节流?什么是防抖?有什么区别?它们的使用情景是什么?
函数防抖(debounce):短时间内多次触发同一事件,只执行最后一次,或者只执行最开始的一次,中间的不执行。
节流(throttle):指连续触发事件但是在 n 秒中只执行一次函数。即 2n 秒内执行 2 次... 。节流如字面意思,会稀释函数的执行频率。
防抖和节流本质上是不一样的,防抖是将多次操作变为最后一次操作,而节流是将多次操作变为连续多个间隔去执行。
使用场景:
1.搜索框搜索内容时请求后端接口
不防抖的方式:输入内容:12345 , 内容发生改变就请求接口。这样会请求五次接口
防抖的方式:同样输入内容:12345,防抖时间设置为 500ms,500ms 内用户输入新的内容重新读条。正常情况下只会请求一次接口
2.图片进行懒加载
不节流的方式:滚动条一滚动就监听页面元素显示情况,显示的元素就进行图片加载。滚动条滚动事件是一个非常频繁的操作,滚动一丢丢就会执行几十次。
节流的方式:还是同样的操作,但是执行代码进行节流。设置节流时间 30ms 。这就不管这 30ms 滚动事件出发了几次,我的执行代码都只执行一次
衍衍生问题1:手动实现节流与防抖的代码
防抖:非立即执行版。也就是触发事件后函数不会立即执行,而是在 delay毫秒后执行,如果在 delay毫秒内又触发了事件,则会重新计算函数执行时间。
- // 非立即执行版
- function debounce(func, delay) {
- let timer = null;
-
- return function() { //页面滚动的时候会多次触发这里面的代码
- let args = arguments;
-
- timer && clearTimeout(timer); //每触发一次timer都会被赋值到上面声明的timer里,因此有的话要清除
-
- timer = setTimeout(() => { //如果在delay周期内连续执行了两次的话,在timersetTimeout的回调函数还没执行的时候就又被重新赋值,因此里面的函数就运行不了了
- func.apply(this, args)
- }, delay)
- }
- }
防抖:立即执行版本。立即执行版的意思是触发事件后函数会立即执行,然后 delay毫秒内不触发事件才能继续执行函数的效果。
- // 立即执行版
- function debounce(func, delay) {
- let timer = null;
- return function() {
- let args = arguments;
-
- timer && clearTimeout(timer);
-
- let callNow = !timer; //如果delay周期内timer没有被重新设置为null的话,就可以执行func
-
- timer = setTimeout(() => {
- timer = null;
- }, delay)
-
- callNow && func.apply(this, args);
- }
- }
节流:时间戳版。函数触发是在时间段内开始的时候。
- // 时间戳版
- function throttle(func, delay) {
- let previous = 0;
- return function() {
- let now = Date.now(); //获取现在的时间
- let args = arguments;
- if (now - previous > delay) {
- func.apply(this, args);
- previous = now;
- }
- }
- }
节流:定时器版。函数触发是在时间段内结束的时候。
- // 定时器版
- function throttle(func, delay) {
- let timer = null;
- return function() {
- let args = arguments;
- if (!timer) {
- timer = setTimeout(() => {
- timer = null;
- func.apply(this, args)
- }, delay)
- }
- }
- }
衍衍生问题2:节流怎么用到的闭包?
以闭包角度解释:
- timer就是闭包函数调用的外部变量
- arguments是每一个funcation函数都会有的对象,在函数调用时,浏览器每次都会传递进两个隐式参数this和arguments,封装实参的对象arguments,在ES6中的箭头函数中使用…rest作为arguments.
- 函数debounce 返回的匿名函数调用了timer,导致timer脱离debounce函数的作用域存活于内存中,直到匿名函数也执行完毕,才会被回收。故当点击间隔小于delay毫秒时,timer就会不断更新值,导致setTimeout内的匿名函数无法执行(因为setTimeout内的函数会延迟delay毫秒执行),直到没有新的调用事件时,fn才会正常延迟到delay毫秒后执行。
衍衍衍生问题1:什么是重排?重绘?如何优化?
重绘(repaint):当元素样式的改变不影响布局时,浏览器将使用重绘对元素进行更新,此时由于只需要 UI 层面的重新像素绘制,因此损耗较少。
衍衍衍衍生问题1:重绘的触发条件有哪些?
1.修改元素的background、color、border-color等
2.设置visibility: hidden隐藏一个DOM节点-只触发重绘,因为没有几何变化
回流(reflow):又叫重排(layout)。当元素的尺寸、结构或者触发某些属性时,浏览器会重新渲染页面,称为回流。此时,浏览器需要重新经过计算,计算后还需要重新页面布局,因此是较重的操作。
回流必定会触发重绘,重绘不一定会触发回流。重绘的开销较小,回流的代价较高。
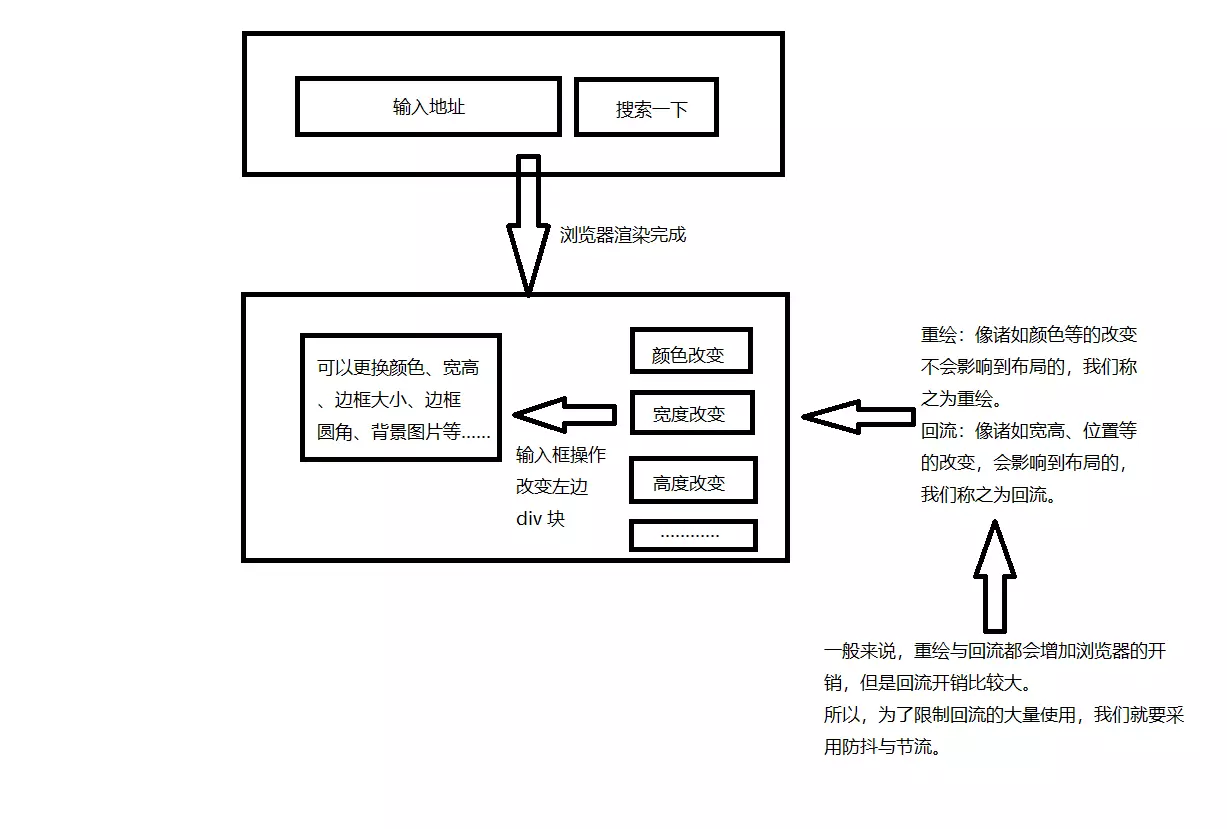
常见的会导致回流的元素:
常见的几何属性有 width、height、padding、margin、left、top、border 等等。
最容易被忽略的操作:获取一些需要通过即时计算得到的属性,当你要用到像这样的属性:offsetTop、offsetLeft、 offsetWidth、offsetHeight、scrollTop、scrollLeft、scrollWidth、scrollHeight、clientTop、clientLeft、clientWidth、clientHeight 时,浏览器为了获取这些值,也会进行回流。
当我们调用了 getComputedStyle 方法,或者 IE 里的 currentStyle 时,也会触发回流。原理是一样的,都为求一个“即时性”和“准确性”。
如何避免重绘重排?
- 避免逐条改变样式,使用类名去合并样式
- 将需要多次重排的元素,position属性设为absolute或fixed(触发BFC),元素脱离了文档流,它的变化不会影响到其他元素;
- display:none;先设置元素为display:none;然后进行页面布局等操作;设置完成后将元素设置为display:block;这样的话就只引发两次重绘和重排;
- 如果需要创建多个DOM节点,可以使用DocumentFragment创建完后一次性的加入document;
- 提升为合成层,如使用
will-change- #divId {
- will-change: transform;
- }
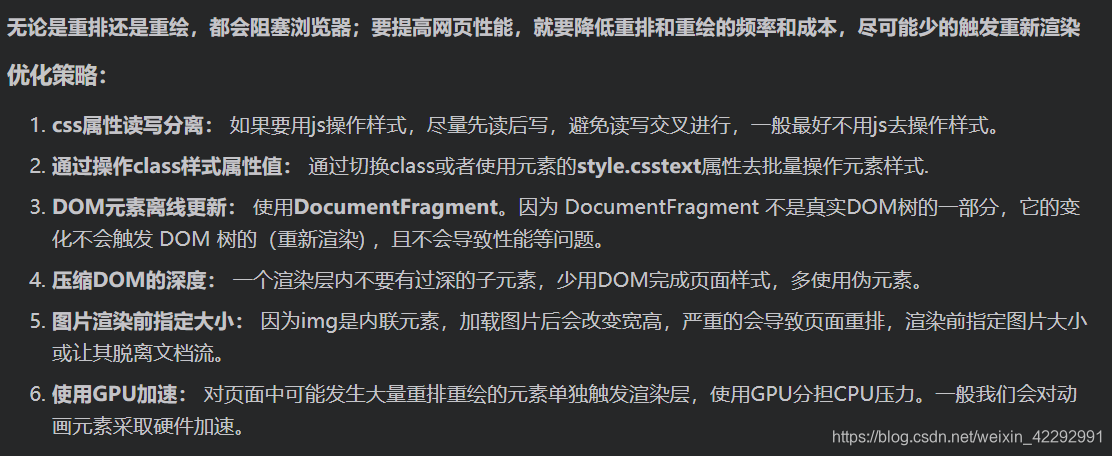
优点
- 合成层的位图,会交由 GPU 合成,比 CPU 处理要快
- 当需要 repaint 时,只需要 repaint 本身,不会影响到其他的层
- 对于 transform 和 opacity 效果,不会触发 layout 和 paint
衍生问题2:了解立即执行函数吗?立即执行函数是不是一种闭包?
立即执行函数也叫匿名函数自执行。
自执行函数,即定义和调用合为一体。我们创建了一个匿名的函数,并立即执行它,由于外部无法引用它内部的变量,因此在执行完后很快就会被释放,关键是这种机制不会污染全局对象。
(function(){})()不叫闭包叫立即执行函数,所谓闭包,要拆成闭和包,闭指代不想暴露给外部的数据,包指代将数据打包出去暴露给外部;之所以这么说原因在于JS的函数作用域,函数内部的变量函数外部无法访问,这形成了闭;函数外部想得到函数内部的变量,可以通过某些方法譬如通过return等语句将内部的变量暴露出去,这形成了包;因而——立即执行函数只是函数的一种调用方式,和闭包没有必然的联系;闭包是和作用域扯上关系的,而(function(){})()是函数声明完就执行,只是有时想要用到闭包那么可以用(function(){})()来构成闭包,而不是(function(){})()是闭包。
立即执行函数与闭包结合的实例:
- let single = (function () {
- let name = "小明";
- let age = 20;
- return {
- getName: function () {
- return name;
- },
- getAge: function () {
- return age;
- }
- }
- })();
- console.log(single.getName()); //小明
- console.log(single.getAge()); //20
6.用js实现一个计算器,采用链式调用的方式
- var Caculator = {
- //结果
- result:0,
- //行为
- jia:function(num){
- this.result += num;
- return this;
- },
-
- jian:function(num){
- this.result -= num;
- return this;
- },
-
- cheng:function(num){
- this.result *= num;
- return this;
- },
-
- chu:function(num){
- this.result /= num;
- return this;
- },
-
- clear:function(){
- this.result = 0;
- return this;
- }
- }
-
- console.log(Caculator.jia(6).jian(2).cheng(3).result); //(6-2)*3 = 12
- console.log(Caculator.clear().result); //归零
7.手写一个深拷贝?
- var obj = {
- name:'4ggg',
- age:18,
- friends:['小红','小兰'],
- test:[],
- familyInfo:{
- city:'广东',
- haveMoney:true,
- pets:[
- {animal:'dog',name:'小狗'},
- {animal:'cat',name:'小猫'},
- ]
- },
- bir:new Date()
- }
-
- function deepCopy(fromObj,toObj){
- //不需要这一行来判断
- //在函数中先检查第一个参数是否有值,如果没有值就初始化一个空对象
- //if(Object.keys(fromObj).length === 0) return {}
- for(var key in fromObj){
- var fromValue = fromObj[key]
- //如果是值数据类型
- if(!isObj(fromValue) && !isArray(fromValue)){
- toObj[key] = fromValue
- }else{
- //就算fromObj是一个空对象,这里也解决了
- var tempObj = new fromValue.__proto__.constructor;
- deepCopy(fromValue,tempObj)
- toObj[key] = tempObj
- }
- }
- }
-
- function isObj(data){
- return data instanceof Object
- }
-
- function isArray(data){
- return Array.isArray(data)
- }
-
- var newObj = {}
- deepCopy(obj,newObj)
-
- obj.friends.push('小绿')
- console.log(obj);
- console.log(newObj);

衍生问题1:浅拷贝和深拷贝的区别?
浅拷贝(shallowCopy)只是增加了一个指针指向已存在的内存地址,
深拷贝(deepCopy)是增加了一个指针并且申请了一个新的内存,使这个增加的指针指向这个新的内存。
8.写一下js中的几个继承?(原型继承、构造函数继承、组合继承、寄生式继承、寄生组合继承)
原型继承 原型链方式可以实现所有属性方法共享,但无法做到属性、方法独享(例如Sub1修改了父类的函数,其他所有的子类Sub2、Sub3...想调用旧的函数就无法实现了。当父类类中包含引用类型属性值时,其中一个子类的多个实例中,只要其中一个实例引用属性只发生修改一个修改,其他实例的引用类型属性值也会立即发生改变
)核心: 将父类的实例作为子类的原型。
- //原型继承
- function Father(){
- this.name = "4ggg"
- this.friends = ['小黄','小红']
- this.clogName = function(){
- console.log(this.name)
- }
- }
-
- Father.prototype.run = function(){
- console.log('run...');
- }
-
- function Son(){
- this.age = 18;
- }
-
- Son.prototype = new Father();
-
- var son = new Son();
- var son2 = new Son();
- console.log(son.name); // 4ggg
- console.log(son.age); // 18
- son.clogName() //4ggg
- son.run() //run...
-
- son.friends.push('小蓝');
- console.log(son.friends) //["小黄", "小红", "小蓝"]
- console.log(son2.friends) //["小黄", "小红", "小蓝"]
构造函数继承 借用构造函数除了能独享属性、方法外还能在子类构造函数中传递参数,但代码无法复用。总体而言就是可以实现所有属性方法独享,但无法做到属性、方法共享。
-
- function Father(){
- this.name = "4ggg"
- this.friends = ['小黄','小红']
- this.clogName = function(){
- console.log(this.name)
- }
- }
-
- Father.prototype.run = function(){
- console.log('run...');
- }
-
- function Son(){
- this.name = '5ggg'
- this.age = 18
- Father.call(this)
- }
-
-
- var son = new Son();
- var son2 = new Son();
- console.log(son.name); // 4ggg 如果Father.call(this)放在第一行的话打印的还是5ggg
- console.log(son.age); // 18
- son.clogName() // 4ggg
- son.run() // 报错 [system] TypeError: son.run is not a function
-
- son.friends.push('小蓝')
- console.log(son.friends); //["小黄", "小红", "小蓝"]
- console.log(son2.friends); //["小黄", "小红"]
组合继承(原型继承+构造函数继承) 组合继承就是把以上两种继承方式一起使用,把共享的属性、方法用原型链继承实现,独享的属性、方法用借用构造函数实现,所以组合继承几乎完美实现了js的继承;
- function Animal(type,name){
- this.type = type
- this.name = name
- }
-
- Animal.prototype.desc = function(){
- console.log('我养了一只' + this.type + ',它的名字叫:' + this.name)
- }
-
- function Dog(name){
- Animal.call(this,'小狗',name) //第一次调用超类
- }
-
- Dog.prototype = new Animal() //第二次调用超类 子类的原型上创建了多余的属性
-
- var dog = new Dog('阿黄');
- dog.desc() //我养了一只小狗,它的名字叫:阿黄
为什么说是“几乎”?
因为组合继承有一个小bug,实现的时候调用了两次超类(父类),性能上不合格啊!怎么解决呢?于是“寄生继承”就出来了。
两次调用父类构造函数:(第一次是在创建子类原型的时候,第二次是在子类构造函数内部)。子类继承父类的属性,一组在子类实例上,一组在子类原型上(在子类原型上创建不必要的多余的属性)(实例上的屏蔽原型上的同名属性),同时效率低。
寄生继承
这种继承方式是把原型继承+工厂模式结合起来,目的是封装创建的过程。
- function Temp(){}
- Temp.prototype = Person.prototype;
- var stuPrototype = new Temp()
- Student.prototype = stuPrototype;
- stuPrototype.constructor = Student;
寄生组合继承 寄生组合继承用了寄生继承修复了组合继承的小bug,因此寄生组合继承是引用类型最理想的继承范式。
- function Person(name,pets){
- this.name = name;
- this.pets = pets;
- }
-
- Person.prototype.run = function(){
- console.log('run');
- }
-
- function Student(age,name,pets){
- Person.call(this,name,pets) //借调
- this.age = age
- }
-
- //寄生式继承
- function Temp(){};
- Temp.prototype = Person.prototype;
- var stuPrototype = new Temp();
- Student.prototype = stuPrototype;
- stuPrototype.constructor = Student;
-
- var stu1 = new Student(18,'4ggg',['dog','cat'])
- var stu2 = new Student(28,'5ggg',['mouse'])
-
- console.log(stu1);
- console.log(stu2);
衍生问题1:讲讲寄生组合继承?
寄生组合继承是指使用寄生继承对组合继承的优化。寄生组合式高效率体现在它只调用了一次超类型的构造函数,避免在子类原型上创建不必要的,多余的属性,同时保证原型链的完整,还能够正常使用 instanceof 和 isPrototypeOf(),开发人员普遍认为寄生组合式继承是引用类型理想的继承范式
衍生问题2:ES6的继承是哪种继承?
ES6通过类的方式来实现继承。extends
-
- class A {
- constructor(a) {
- this.a = a;
- }
- getA() {
- console.log(a)
- }
- }
-
- class B extends A {
- constructor(b) {
- super()
- this.b = b;
- }
- }
-
-
-
衍衍生问题1:ES6 class 是怎么实现的?
ES6类的底层还是通过构造函数去创建的。
衍衍生问题2:ES6 class 和 ES5 function 的区别?
1.在ES5中,构造函数是可以直接运行的。而通过ES6创建的类,是不允许直接调用的。
2.es6不存在变量提升,声明的class在它之前拿不到
3.class内部会开启严格模式('use strict'), 比如constructor 直接写 a = 12, 不行的
4.class必须用new调用,不能被() call
5.es5原型链定义了Father和Son,Son.__proto__ == Father.prototype。而es6原型链中Son.__proto__ === Father
衍衍生问题3:什么是js的严格模式(js的严格模式有什么用)?
"use strict";//是进入严格模式的标志(老版本的浏览器会把它当作一行普通字符串,加以忽略。)
将"use strict"放在脚本文件的第一行,则整个脚本都将以"严格模式"运行。如果这行语句不在第一行,则无效,整个脚本以"正常模式"运行。
作用:
1.消除Javascript语法的一些不合理、不严谨之处,减少一些怪异行为;
2.消除代码运行的一些不安全之处,保证代码运行的安全;
3.提高编译器效率,增加运行速度;
4.为未来新版本的Javascript做好铺垫。
衍生问题3:ES6 的class Babel成ES5之后是什么样的?
通过babel转义的代码看出来应该是原型继承。
衍衍生问题1:什么是babel?
Babel是一个编译器,能将ES6及以上版本的代码转换为ES5的工具。
9.说说下列的打印结果?为什么?
- for(var i=0;i<10;i++){
- setTimeout(console.log(i),0);
- }
-
- for(var i=0;i<10;i++){
- setTimeout(console.log(i),1000);
- }
-
-
- for(var i=0;i<10;i++){
- setTimeout(function(){ console.log(i); },0);
- }
-
-
- for(var i=0;i<10;i++){
- setTimeout(function(){ console.log(i); },1000);
- }
第一第二都是立刻输出0,2,3...9 因为setTimeout里面没有回调函数,等于都是同步任务。
第三第四都是输出10个10。定时器里有回调函数。等于是一个异步任务,异步任务是只有等执行栈中同步任务执行完毕后才可以执行异步,因为js最大的特性就是单线程。当for循环同步任务结束后,此时i的值是10。for循环了10次,等于就是要调用10次这个回调函数,有10个异步任务在异步队伍列表里面等待,等执行栈同步任务执行完毕再执行,这10个任务就是log这个i变量。此时的i是10所以就是10个10。它们的区别在于第三个for在for执行完成后立刻打印出10个10,而第四个会在1s后打印出10个10。
由于JavaScript是单线程处理任务的,而setTimeout是异步事件,延时时间为0的时候,JavaScript引擎会把异步事件立刻放到任务队列里,而不是立刻执行,需要等到前面处于等待状态的事件处理程序全部执行完成后再调用它
10.下面两段代码有什么区别?
- setTimeout(function () {
- func1()
- }, 0)
-
-
-
- setTimeout(function () {
- func1()
- })
0秒延迟,此回调将会放到一个能立即执行的时段进行触发。javascript代码大体上是自顶向下的,但中间穿插着有关DOM渲染,事件回应等异步代码,他们将组成一个队列,零秒延迟将会实现插队操作(宏任务队列中)。
不写第二个参数,浏览器自动配置时间,在IE,FireFox中,第一次配可能给个很大的数字,100ms上下,往后会缩小到最小时间间隔,Safari,chrome,opera则多为10ms上下。
11.讲讲js的垃圾回收机制?
垃圾回收机制会定期(周期性)找出那些不再用到的内存(变量),然后释放其内存。现在各大浏览器通常采用的垃圾回收机制有两种方法:标记清除,引用计数。
标记清除:工作原理:是当变量进入环境时,将这个变量标记为“进入环境”。当变量离开环境时,则将其标记为“离开环境”。标记“离开环境”的就回收内存。
工作流程:
1. 垃圾回收器,在运行的时候会给存储在内存中的所有变量都加上标记。
2. 去掉环境中的变量以及被环境中的变量引用的变量的标记。
3. 再被加上标记的会被视为准备删除的变量。
4. 垃圾回收器完成内存清除工作,销毁那些带标记的值并回收他们所占用的内存空间。
引用计数:工作原理:跟踪记录每个值被引用的次数。
工作流程:
1. 声明了一个变量并将一个引用类型的值赋值给这个变量,这个引用类型值的引用次数就是1。
2. 同一个值又被赋值给另一个变量,这个引用类型值的引用次数加1.
3. 当包含这个引用类型值的变量又被赋值成另一个值了,那么这个引用类型值的引用次数减1.
4. 当引用次数变成0时,说明没办法访问这个值了。
5. 当垃圾收集器下一次运行时,它就会释放引用次数是0的值所占的内存。
垃圾回收的缺陷
和其他语言一样,javascript的GC策略也无法避免一个问题:GC时,停止响应其他操作,这是为了安全考虑。而Javascript的GC在100ms甚至以上,对一般的应用还好,但对于JS游戏,动画对连贯性要求比较高的应用,就麻烦了。这就是新引擎需要优化的点:避免GC造成的长时间停止响应。
如何减少垃圾回收开销
由于每次的垃圾回收开销都相对较大,并且由于机制的一些不完善的地方,可能会导致内存泄露,我们可以利用一些方法减少垃圾回收,并且尽量避免循环引用。
在对象结束使用后 ,令obj = null。这样利于解除循环引用,使得无用变量及时被回收;
js中开辟空间的操作有new(), [ ], { }, function (){..}。最大限度的实现对象的重用;
慎用闭包。闭包容易引起内存泄露。本来在函数返回之后,之前的空间都会被回收。但是由于闭包可能保存着函数内部变量的引用,且闭包在外部环境,就会导致函数内部的变量不能够销毁。
优化GC
分代回收(Generation GC):与Java回收策略思想是一致的。目的是通过区分“临时”与“持久”对象;多回收“临时对象”区(young generation),少回收“持久对象”区(tenured generation),减少每次需遍历的对象,从而减少每次GC的耗时。
增量GC:它的存在是为了解决标记清除的长停顿问题。这个方案的思想很简单,就是“每次处理一点,下次再处理一点,如此类推。
12.什么是内存泄漏?为什么会发生内存泄漏?什么情况会引起内存泄漏?如何监控内存泄漏
?
内存泄漏(Memory Leak)是指程序中己动态分配的堆内存由于某种原因程序未释放或无法释放,造成系统内存的浪费,导致程序运行速度减慢甚至系统崩溃等严重后果。
虽然前端有垃圾回收机制,但当某块无用的内存,却无法被垃圾回收机制认为是垃圾时,也就发生内存泄漏了
哪些情况会引起内存泄漏:
1. 意外的全局变量。全局变量的生命周期最长,直到页面关闭前,它都存活着,所以全局变量上的内存一直都不会被回收
2. 遗忘的定时器。setTimeout 和 setInterval 是由浏览器专门线程来维护它的生命周期,所以当在某个页面使用了定时器,当该页面销毁时,没有手动去释放清理这些定时器的话,那么这些定时器还是存活着的。也就是说,定时器的生命周期并不挂靠在页面上,所以当在当前页面的 js 里通过定时器注册了某个回调函数,而该回调函数内又持有当前页面某个变量或某些 DOM 元素时,就会导致即使页面销毁了,由于定时器持有该页面部分引用而造成页面无法正常被回收,从而导致内存泄漏了。如果此时再次打开同个页面,内存中其实是有双份页面数据的,如果多次关闭、打开,那么内存泄漏会越来越严重。因此要记得清除定时器。
3. 使用不当的闭包。函数本身会持有它定义时所在的词法环境的引用,但通常情况下,使用完函数后,该函数所申请的内存都会被回收了。但当函数内再返回一个函数时,由于返回的函数持有外部函数的环境,而返回的函数又被其他生命周期东西所持有,导致外部函数虽然执行完了,但内存却无法被回收。正常来说,闭包并不是内存泄漏,因为这种持有外部函数词法环境本就是闭包的特性,就是为了让这块内存不被回收,因为可能在未来还需要用到,但这无疑会造成内存的消耗,所以,不宜烂用就是了。
4. 遗漏的 DOM 元素。DOM 元素的生命周期正常是取决于是否挂载在 DOM 树上,当从 DOM 树上移除时,也就可以被销毁回收了,但如果某个 DOM 元素,在 js 中也持有它的引用时,那么它的生命周期就由 js 和是否在 DOM 树上两者决定了,记得移除时,两个地方都需要去清理才能正常回收它。
5. 网络回调。
某些场景中,在某个页面发起网络请求,并注册一个回调,且回调函数内持有该页面某些内容,那么,当该页面销毁时,应该注销网络的回调,否则,因为网络持有页面部分内容,也会导致页面部分内容无法被回收。
使用内存监控工具如chorme的插件lighthouse等。

