
- 1数据结构第四节——二叉树
- 2备战蓝桥杯 刷题笔记(第一期)
- 3Halcon Variable Inspect 安装失败_未能正确加载"hvariable_inspect_vsppackage_1712"包
- 4Springboot+MyBatis-Plus实现多租户动态数据源模式_springboot集成mybatis-plus实现多租户动态数据源
- 5TSINGSEE青犀推出河道/河湖/水域治理视频AI智能解决方案
- 6常用的7个Python库_python常用函数库
- 7让知识图谱成为大模型的伴侣
- 8STM32 (基于HAL库)4×4矩阵按键驱动详细教程_4*4矩阵模块hal
- 9初始Hadoop技术_hdfs收到那篇文章启发
- 10(一)基于IDEA的JAVA基础12
图论算法—图(Graph)的入门概念、存储结构、遍历方式以及Java代码的实现
赞
踩
首先介绍了图的入门概念,然后介绍了图的邻接矩阵和邻接表两种存储结构、以及深度优先遍历和广度优先遍历的两种遍历方式,最后提供了Java代码的实现。
图,算作一种比较复杂的数据结构,因此建议有一定数据结构基础的人再来学习!
1 图的定义和相关概念
定义:图(Graph)是由顶点的有穷非空集合和顶点之间边的集合组成,通常表示为:G(V,E),其中,G表示一个图,V是图G中顶点的集合,E是图G中边的集合。图在数据结构中是中多对多的关系,而树则是1对多的关系,树就是一种特别的没有闭环的图。
顶点:图中的顶点就是节点的意思,不过图中任意的节点都算作顶点。将顶点集合为空的图称为空图。图中任意两个顶点之间都可能存在关系,顶点之间的逻辑关系用边来表示,边集可以是空的。
无向图:若顶点vi到vj之间的边没有方向,则称这条边为无向边(Edge),用无序偶对(vi,vj)来表示。如果图中任意两个顶点之间的边都是无向边,则称该图为无向图(Undirected graphs)。
有向图:若从顶点vi到vj的边有方向,则称这条边为有向边,也称为弧(Arc)。如果图中任意两个顶点之间的边都是有向边,则称该图为有向图(Directed graphs)。
完全图、稠密图、稀疏图:具有n个顶点,n(n-1)/2条边的图,称为完全无向图;具有n个顶点,n(n-1) 条弧的有向图,称为完全有向图。完全无向图和完全有向图都称为完全图。当一个图接近完全图时,则称它为稠密图,当一个图中含有较少的边或弧时,则称它为稀疏图。
权、网:有些图的边或弧具有与它相关的数字,这种与图的边或弧相关的数叫做权(Weight)。这些权可以表示从一个顶点到另一个顶点的距离或耗费。这种带权的图通常称为网(Network)。
子图:若有两个图G=(V1,E1), G2=(V2,E2), 满足如下条件:V2⊆V1 ,E2⊆ E1,即V2为V1的子集,E2为E1的子集,则 称图G2为图G1的子图。
下图中带底纹的图均为左侧无向图与有向图的子图。

邻接点、度:相邻且有边直接连接的两个顶点称为邻接点。顶点所连边的数目称为度,在有向图中,由于边有方向,则顶点的度分为入度和出度。
简单路径、连通图:图中顶点间存在路径,两顶点存在路径则说明是连通的,如果路径最终回到起始点则称为环,当中不重复叫简单路径。若任意两顶点都是连通的,则图就是连通图,有向则称强连通图。图中有子图,若子图极大连通则就是连通分量,有向的则称强连通分量。
生成树:无向图中连通且n个顶点n-1条边叫生成树。有向图中一顶点入度为0其余顶点入度为1的叫有向树。一个有向图由若干棵有向树构成生成森林。
2 图的存储结构
由于图的结构比较复杂,任意两个顶点之间都可能存在联系,因此无法以单一的结构来表示。图最常见的表示形式为邻接链表和邻接矩阵,它们都是采用复合的结构来表示图。
2.1 邻接矩阵
邻接矩阵(Adjacency Matrix):采用两个数组来存储图,一个一维数组存储图顶点信息,一个二维数组存储图边或弧的信息,二维数组可以看作矩阵,这也是“邻接矩阵”名字的由来。这是最简单的图的存储方式,但是存在空间浪费的情况。
设图G有n个顶点,则邻接矩阵是一个n×n的方阵,定义为:
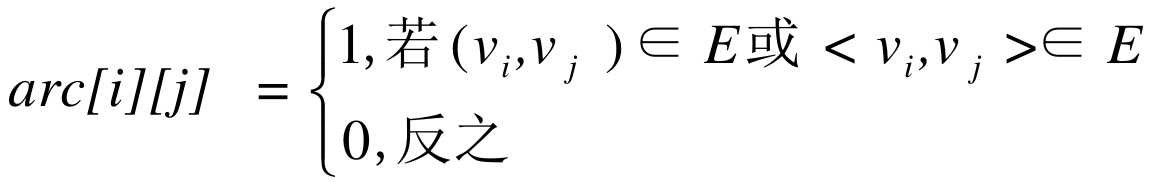
矩阵的对角线始终为0,因为顶点不能和自己连接。无向图的数据是对称的,有向图就不一定了。
下图就是采用邻接矩阵表示的无向图。

下图就是采用邻接矩阵表示的有向图。

有向图讲究入度与出度,顶点0的入度为3,正好是第1列各数之和。顶点0的出度为3,即第1行的各数之和。一个点的入度是点所表示的列的各数的和,出度就是个点所表示的行的各数的和。
下图就是采用邻接矩阵表示的带权有向图。

注意,边二维数组中的数字表示权,没有关系的顶点(没有权)使用”/”表示。
2.2 邻接表
邻接表(Adjacency List):采用数组和链表存储,一个数组存储顶点,同时顶点想外拉出链表表示边或者弧,链表称为边表,如度的边表称为入边表,出度的边表称为出边表。邻接表的实现只关心存在的边,不关心不存在的边,因此没有空间浪费。
下图就是采用邻接表表示的无向图。

下图就是采用邻接表表示的有向图。

下图就是采用邻接矩阵表示的带权有向图。

邻接表在表示稀疏图时非常紧凑而成为了通常的选择,相比之下,如果在稀疏图表示时使用邻接矩阵,会浪费很多内存空间,遍历的时候也会增加开销。如果图是稠密图,邻接表的优势就不明显了,那么就可以选择更加方便的邻接矩阵。
3 图的遍历
3.1 深度优先遍历
深度优先遍历(Depth First Search),也有称为深度优先搜索,简称为DFS。类似于树的先序遍历。基本思想是“一条路走到黑”,然后往回退,回退过程中如果遇到没探索过的支路,就进入该支路继续深入,直到所有顶点都被访问到。
假设初始状态是图中所有顶点均未被访问,则从某个顶点v出发,首先访问该顶点,然后依次从它的各个未被访问的邻接点出发深度优先搜索遍历图,直至图中所有和v有路径相通的顶点都被访问到。但此时还有可能有其他分支我们没有访问到,若此时尚有其他顶点未被访问到,需要回溯,另选一个未被访问的顶点作起始点,重复上述过程,直至图中所有顶点都被访问到为止。显然,深度优先搜索是一个递归的过程。
对如下左边无向图从0顶点开始进行深度优先遍历之后一种结果为:0、1、4、5、3、2,如右图。

从起始点0开始遍历,在访问了0后,选择其邻接点1。因为1未曾访问过,则从1出发进行深度优先遍历。依次类推,接着从4、5、3出发进行遍历。在访问了3后,由于3的邻接点都已被访问,则遍历回退到5。此时5的另一个邻接点2未被访问,则遍历又从5到2,再继续进行下去,于是得到节点的线性顺序为:0、1、4、5、3、2,如右图中红色箭头线为其深度优先遍历顺序。
对如下左边有向图从0顶点开始进行深度优先遍历之后一种结果为:0、1、4、2、5、3,如右图。

有向图的深度优先遍历顶点的领边需要考虑顶点的出度对应的顶点。该顶点的出度对应的顶点算作邻接点。
从起始点0开始遍历,在访问了0后,选择其出度邻接点1、2。这里选择1进行访问,从1出发进行有向图深度优先遍历。依次类推,在访问了4后,由于4的出度邻接点0、1都已被访问,则遍历回退直到0。此时0的另一个邻接点2未被访问,则遍历又从0到2,再继续进行下去,于是得到节点的线性顺序为:0、1、4、2、5、4,如右图中红色箭头线为有向图深度优先遍历顺序。
3.2 广度优先遍历
广度优先遍历(Breadth First Search) ,也有称为广度优先搜索,简称BFS,类似于树的层序遍历。基本思想是尽最大程度辐射能够覆盖的节点,并对其进行访问。
从图中某顶点v出发,在访问了v之后依次访问v的各个未曾访问过的邻接点,然后分别从这些邻接点出发依次访问它们的邻接点,并使得“先被访问的顶点的邻接点先于后被访问的顶点的邻接点被访问,直至图中所有已被访问的顶点的邻接点都被访问到。如果此时图中尚有顶点未被访问,则需要另选一个未曾被访问过的顶点作为新的起始点,重复上述过程,直至图中所有顶点都被访问到为止。换句话说,广度优先搜索遍历图的过程是以v为起点,由近至远。
对如下左边无向图从0顶点开始进行深度优先遍历之后一种结果为:0、1、2、3、4、5,如右图。

从起始点0开始遍历,在访问了0后,寻找邻接点,找到了1、2、3,一次遍历,访问完1、2、3之后,再依次访问它们的邻接点。首先访问1的邻接点4,再访问2的邻接点5。因此访问顺序是:0、1、2、3、4、5。
对如下左边有向图从0顶点开始进行广度优先遍历之后一种结果为:0、1、2、4、5、3,如右图。

有向图的广度优先遍历顶点的领边同样需要考虑顶点的出度对应的顶点。该顶点的出度对应的顶点算作邻接点。
从起始点0开始遍历,在访问了0后,选择其出度邻接点1、2,然后访问1、2;访问完1,2之后,再依次访问它们的邻接点。首先访问1的邻接点4依次类推,再访问2的邻接点5。访问完5之后,再依次访问它们的邻接点,最后访问5的邻接点3。此时所有顶点访问完毕。因此访问顺序是:0、1、2、4、5、3。
4 图的实现
关于图的实现,Guava中的com.google.common.graph模块已经提供了图的各种实现,而且都非常完美,这里只提供四个简单实现。带权重的图的实现,将在后面的最小生成树和最短路径部分提供实现。
4.1 无向图的邻接表实现
/** * 无向图邻接链表简单实现 * {@link UndirectedAdjacencyList#UndirectedAdjacencyList(E[], E[][])} 构建无向图 * {@link UndirectedAdjacencyList#DFS()} 深度优先遍历无向图 * {@link UndirectedAdjacencyList#BFS()} 广度优先遍历无向图 * {@link UndirectedAdjacencyList#toString()} ()} 输出无向图 * * @author lx */ public class UndirectedAdjacencyList<E> { /** * 顶点类 * * @param <E> */ private class Node<E> { /** * 顶点信息 */ E data; /** * 指向第一条依附该顶点的边 */ LNode firstEdge; public Node(E data, LNode firstEdge) { this.data = data; this.firstEdge = firstEdge; } } /** * 边表节点类 */ private class LNode { /** * 该边所指向的顶点的索引位置 */ int vertex; /** * 指向下一条边的指针 */ LNode nextEdge; } /** * 顶点数组 */ private Node<E>[] vertexs; /** * 创建图 * * @param vexs 顶点数组 * @param edges 边二维数组 */ public UndirectedAdjacencyList(E[] vexs, E[][] edges) { /*初始化顶点数组,并添加顶点*/ vertexs = new Node[vexs.length]; for (int i = 0; i < vertexs.length; i++) { vertexs[i] = new Node<>(vexs[i], null); } /*初始化边表,并添加边节点到边表尾部,即采用尾插法*/ for (E[] edge : edges) { // 读取一条边的起始顶点和结束顶点索引值 int p1 = getPosition(edge[0]); int p2 = getPosition(edge[1]); /*这里需要相互添加边节点,无向图可以看作相互可达的有向图*/ // 初始化lnode1边节点 LNode lnode1 = new LNode(); lnode1.vertex = p2; // 将LNode链接到"p1所在链表的末尾" if (vertexs[p1].firstEdge == null) { vertexs[p1].firstEdge = lnode1; } else { linkLast(vertexs[p1].firstEdge, lnode1); } // 初始化lnode2边节点 LNode lnode2 = new LNode(); lnode2.vertex = p1; // 将lnode2链接到"p2所在链表的末尾" if (vertexs[p2].firstEdge == null) { vertexs[p2].firstEdge = lnode2; } else { linkLast(vertexs[p2].firstEdge, lnode2); } } } /** * 获取某条边的某个顶点所在顶点数组的索引位置 * * @param e 顶点的值 * @return 所在顶点数组的索引位置, 或者-1 - 表示不存在 */ private int getPosition(E e) { for (int i = 0; i < vertexs.length; i++) { if (vertexs[i].data == e) { return i; } } return -1; } /** * 将lnode节点链接到边表的最后,采用尾插法 * * @param first 边表头结点 * @param node 将要添加的节点 */ private void linkLast(LNode first, LNode node) { while (true) { if (first.vertex == node.vertex) { return; } if (first.nextEdge == null) { break; } first = first.nextEdge; } first.nextEdge = node; } /** * 深度优先搜索遍历图的递归实现,类似于树的先序遍历 * 因此模仿树的先序遍历,同样借用栈结构,这里使用的是方法的递归,隐式的借用栈 * * @param i 顶点索引 * @param visited 访问标志数组 */ private void DFS(int i, boolean[] visited) { //索引索引标记为true ,表示已经访问了 visited[i] = true; System.out.print(vertexs[i].data + " "); //获取该顶点的边表头结点 LNode node = vertexs[i].firstEdge; //循环遍历该顶点的邻接点,采用同样的方式递归搜索 while (node != null) { if (!visited[node.vertex]) { DFS(node.vertex, visited); } node = node.nextEdge; } } /** * 深度优先搜索遍历图,类似于树的前序遍历, */ public void DFS() { //新建顶点访问标记数组,对应每个索引对应相同索引的顶点数组中的顶点 boolean[] visited = new boolean[vertexs.length]; //初始化所有顶点都没有被访问 for (int i = 0; i < vertexs.length; i++) { visited[i] = false; } System.out.println("DFS: "); /*循环搜索*/ for (int i = 0; i < vertexs.length; i++) { //如果对应索引的顶点的访问标记为false,则搜索该顶点 if (!visited[i]) { DFS(i, visited); } } /*走到这一步,说明顶点访问标记数组全部为true,说明全部都访问到了,深度搜索结束*/ System.out.println(); } /** * 广度优先搜索图,类似于树的层序遍历 * 因此模仿树的层序遍历,同样借用队列结构 */ public void BFS() { // 辅组队列 Queue<Integer> indexLinkedList = new LinkedList<>(); //新建顶点访问标记数组,对应每个索引对应相同索引的顶点数组中的顶点 boolean[] visited = new boolean[vertexs.length]; //初始化所有顶点都没有被访问 for (int i = 0; i < vertexs.length; i++) { visited[i] = false; } System.out.println("BFS: "); for (int i = 0; i < vertexs.length; i++) { //如果访问方剂为false,则设置为true,表示已经访问,然后开始访问 if (!visited[i]) { visited[i] = true; System.out.print(vertexs[i].data + " "); indexLinkedList.add(i); } //判断队列是否有值,有就开始遍历 if (!indexLinkedList.isEmpty()) { //出队列 Integer j = indexLinkedList.poll(); LNode node = vertexs[j].firstEdge; while (node != null) { int k = node.vertex; if (!visited[k]) { visited[k] = true; System.out.print(vertexs[k].data + " "); //继续入队列 indexLinkedList.add(k); } node = node.nextEdge; } } } System.out.print("\n"); } @Override public String toString() { StringBuilder stringBuilder = new StringBuilder(); for (int i = 0; i < vertexs.length; i++) { stringBuilder.append(i).append("(").append(vertexs[i].data).append("): "); LNode node = vertexs[i].firstEdge; while (node != null) { stringBuilder.append(node.vertex).append("(").append(vertexs[node.vertex].data).append(")"); node = node.nextEdge; if (node != null) { stringBuilder.append("->"); } else { break; } } stringBuilder.append("\n"); } return stringBuilder.toString(); } public static void main(String[] args) { //顶点数组 添加的先后顺序对于遍历结果有影响 Character[] vexs = {'A', 'B', 'C', 'D', 'E', 'F', 'G'}; //边二维数组 添加的先后顺序对于遍历结果有影响 Character[][] edges = { {'A', 'C'}, //对于无向图来说是多余的边关系,在linkLast方法中做了判断,并不会重复添加 {'A', 'D'}, {'A', 'D'}, {'D', 'A'}, {'A', 'F'}, {'B', 'C'}, {'C', 'D'}, {'E', 'G'}, {'E', 'B'}, {'D', 'B'}, {'F', 'G'}}; //构建图 UndirectedAdjacencyList<Character> undirectedAdjacencyList = new UndirectedAdjacencyList<>(vexs, edges); //输出图 System.out.println(undirectedAdjacencyList); //深度优先遍历 undirectedAdjacencyList.DFS(); //广度优先遍历 undirectedAdjacencyList.BFS(); } }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
- 226
- 227
- 228
- 229
- 230
- 231
- 232
- 233
- 234
- 235
- 236
- 237
- 238
- 239
- 240
- 241
- 242
- 243
- 244
- 245
- 246
- 247
- 248
- 249
- 250
- 251
- 252
- 253
- 254
- 255
- 256
- 257
- 258
测试无向图对应的逻辑结构如下:

测试图的遍历结果如下:

4.2 有向图的邻接表实现
/** * 有向图邻接链表简单实现 * {@link AdjacencyList#AdjacencyList(E[], E[][])} 构建有向图 * {@link AdjacencyList#DFS()} 深度优先遍历有向图 * {@link AdjacencyList#BFS()} 广度优先遍历有向图 * {@link AdjacencyList#toString()} ()} 输出有向图 * * @author lx */ public class AdjacencyList<E> { /** * 顶点类 * * @param <E> */ private class Node<E> { /** * 顶点信息 */ E data; /** * 指向第一条依附该顶点的边 */ LNode firstEdge; public Node(E data, LNode firstEdge) { this.data = data; this.firstEdge = firstEdge; } } /** * 边表节点类 */ private class LNode { /** * 该边所指向的顶点的索引位置 */ int vertex; /** * 指向下一条弧的指针 */ LNode nextEdge; } /** * 顶点数组 */ private Node<E>[] vertexs; /** * 创建图 * * @param vexs 顶点数组 * @param edges 边二维数组 */ public AdjacencyList(E[] vexs, E[][] edges) { /*初始化顶点数组,并添加顶点*/ vertexs = new Node[vexs.length]; for (int i = 0; i < vertexs.length; i++) { vertexs[i] = new Node<>(vexs[i], null); } /*初始化边表,并添加边节点到边表尾部,即采用尾插法*/ for (E[] edge : edges) { // 读取一条边的起始顶点和结束顶点索引值 int p1 = getPosition(edge[0]); int p2 = getPosition(edge[1]); // 初始化lnode1边节点 即表示p1指向p2的边 LNode lnode1 = new LNode(); lnode1.vertex = p2; // 将LNode链接到"p1所在链表的末尾" if (vertexs[p1].firstEdge == null) { vertexs[p1].firstEdge = lnode1; } else { linkLast(vertexs[p1].firstEdge, lnode1); } } } /** * 获取某条边的某个顶点所在顶点数组的索引位置 * * @param e 顶点的值 * @return 所在顶点数组的索引位置, 或者-1 - 表示不存在 */ private int getPosition(E e) { for (int i = 0; i < vertexs.length; i++) { if (vertexs[i].data == e) { return i; } } return -1; } /** * 将lnode节点链接到边表的最后,采用尾插法 * * @param first 边表头结点 * @param node 将要添加的节点 */ private void linkLast(LNode first, LNode node) { while (true) { if (first.vertex == node.vertex) { return; } if (first.nextEdge == null) { break; } first = first.nextEdge; } first.nextEdge = node; } /** * 深度优先搜索遍历图的递归实现,类似于树的先序遍历 * 因此模仿树的先序遍历,同样借用栈结构,这里使用的是方法的递归,隐式的借用栈 * * @param i 顶点索引 * @param visited 访问标志数组 */ private void DFS(int i, boolean[] visited) { //索引索引标记为true ,表示已经访问了 visited[i] = true; System.out.print(vertexs[i].data + " "); //获取该顶点的边表头结点 LNode node = vertexs[i].firstEdge; //循环遍历该顶点的邻接点,采用同样的方式递归搜索 while (node != null) { if (!visited[node.vertex]) { DFS(node.vertex, visited); } node = node.nextEdge; } } /** * 深度优先搜索遍历图,类似于树的前序遍历, */ public void DFS() { //新建顶点访问标记数组,对应每个索引对应相同索引的顶点数组中的顶点 boolean[] visited = new boolean[vertexs.length]; //初始化所有顶点都没有被访问 for (int i = 0; i < vertexs.length; i++) { visited[i] = false; } System.out.println("DFS: "); /*循环搜索*/ for (int i = 0; i < vertexs.length; i++) { //如果对应索引的顶点的访问标记为false,则搜索该顶点 if (!visited[i]) { DFS(i, visited); } } /*走到这一步,说明顶点访问标记数组全部为true,说明全部都访问到了,深度搜索结束*/ System.out.println(); } /** * 广度优先搜索图,类似于树的层序遍历 * 因此模仿树的层序遍历,同样借用队列结构 */ public void BFS() { // 辅组队列 Queue<Integer> indexLinkedList = new LinkedList<>(); //新建顶点访问标记数组,对应每个索引对应相同索引的顶点数组中的顶点 boolean[] visited = new boolean[vertexs.length]; //初始化所有顶点都没有被访问 for (int i = 0; i < vertexs.length; i++) { visited[i] = false; } System.out.println("BFS: "); for (int i = 0; i < vertexs.length; i++) { //如果访问方剂为false,则设置为true,表示已经访问,然后开始访问 if (!visited[i]) { visited[i] = true; System.out.print(vertexs[i].data + " "); indexLinkedList.add(i); } //判断队列是否有值,有就开始遍历 if (!indexLinkedList.isEmpty()) { //出队列 Integer j = indexLinkedList.poll(); LNode node = vertexs[j].firstEdge; while (node != null) { int k = node.vertex; if (!visited[k]) { visited[k] = true; System.out.print(vertexs[k].data + " "); //继续入队列 indexLinkedList.add(k); } node = node.nextEdge; } } } System.out.println("\n"); } @Override public String toString() { StringBuilder stringBuilder = new StringBuilder(); for (int i = 0; i < vertexs.length; i++) { stringBuilder.append(i).append("(").append(vertexs[i].data).append("): "); LNode node = vertexs[i].firstEdge; while (node != null) { stringBuilder.append(node.vertex).append("(").append(vertexs[node.vertex].data).append(")"); node = node.nextEdge; if (node != null) { stringBuilder.append("->"); } else { break; } } stringBuilder.append("\n"); } return stringBuilder.toString(); } public static void main(String[] args) { //顶点数组 添加的先后顺序对于遍历结果有影响 Character[] vexs = {'A', 'B', 'C', 'D', 'E', 'F', 'G'}; //边二维数组 {'a', 'b'}表示顶点a->b的边 添加的先后顺序对于遍历结果有影响 Character[][] edges = { {'A', 'C'}, {'A', 'D'}, //对于有向图来说是多余的边关系,在linkLast方法中做了判断,并不会重复添加 {'A', 'D'}, //对于有向图来说不是多余的边关系 {'D', 'A'}, {'A', 'F'}, {'B', 'C'}, {'C', 'D'}, {'E', 'G'}, {'E', 'B'}, {'D', 'B'}, {'F', 'G'}}; // 构建图有向图 AdjacencyList<Character> adjacencyList = new AdjacencyList<>(vexs, edges); //输出图 System.out.println(adjacencyList); //深度优先遍历 adjacencyList.DFS(); //广度优先遍历 adjacencyList.BFS(); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
- 226
- 227
- 228
- 229
- 230
- 231
- 232
- 233
- 234
- 235
- 236
- 237
- 238
- 239
- 240
- 241
- 242
- 243
- 244
- 245
- 246
- 247
- 248
- 249
- 250
测试有向图对应的逻辑结构如下:

测试图的遍历结果如下:

4.3 无向图的邻接矩阵实现
/** * 无向图邻接矩阵简单实现 * {@link UndirectedAdjacencyMatrix#UndirectedAdjacencyMatrix(E[], E[][])} 构建无向图 * {@link UndirectedAdjacencyMatrix#DFS()} 深度优先遍历无向图 * {@link UndirectedAdjacencyMatrix#BFS()} 广度优先遍历无向图 * {@link UndirectedAdjacencyMatrix#toString()} ()} 输出无向图 * * @author lx */ public class UndirectedAdjacencyMatrix<E> { /** * 顶点数组 */ private Object[] vertexs; /** * 邻接矩阵 */ private int[][] matrix; /* * 创建图 * * 参数说明: * vexs -- 顶点数组 * edges -- 边数组 */ /** * 创建无向图 * * @param vexs 顶点数组 * @param edges 边二维数组 */ public UndirectedAdjacencyMatrix(E[] vexs, E[][] edges) { // 初始化顶点数组,并添加顶点 vertexs = Arrays.copyOf(vexs, vexs.length); // 初始化边矩阵,并填充边信息 matrix = new int[vexs.length][vexs.length]; for (E[] edge : edges) { // 读取一条边的起始顶点和结束顶点索引值 int p1 = getPosition(edge[0]); int p2 = getPosition(edge[1]); //对称的两个点位都置为1,无向图可以看作相互可达的有向图 matrix[p1][p2] = 1; matrix[p2][p1] = 1; } } /** * 获取某条边的某个顶点所在顶点数组的索引位置 * * @param e 顶点的值 * @return 所在顶点数组的索引位置, 或者-1 - 表示不存在 */ private int getPosition(E e) { for (int i = 0; i < vertexs.length; i++) { if (vertexs[i] == e) { return i; } } return -1; } /** * 深度优先搜索遍历图,类似于树的前序遍历, */ public void DFS() { //新建顶点访问标记数组,对应每个索引对应相同索引的顶点数组中的顶点 boolean[] visited = new boolean[vertexs.length]; //初始化所有顶点都没有被访问 for (int i = 0; i < vertexs.length; i++) { visited[i] = false; } System.out.println("DFS: "); for (int i = 0; i < vertexs.length; i++) { if (!visited[i]) { DFS(i, visited); } } System.out.println(); } /** * 深度优先搜索遍历图的递归实现,类似于树的先序遍历 * 因此模仿树的先序遍历,同样借用栈结构,这里使用的是方法的递归,隐式的借用栈 * * @param i 顶点索引 * @param visited 访问标志数组 */ private void DFS(int i, boolean[] visited) { visited[i] = true; System.out.print(vertexs[i] + " "); // 遍历该顶点的所有邻接点。若该邻接点是没有访问过,那么继续递归遍历领接点 for (int w = firstVertex(i); w >= 0; w = nextVertex(i, w)) { if (!visited[w]) { DFS(w, visited); } } } /** * 返回顶点v的第一个邻接顶点的索引,失败则返回-1 * * @param v 顶点v在数组中的索引 * @return 返回顶点v的第一个邻接顶点的索引,失败则返回-1 */ private int firstVertex(int v) { //如果索引超出范围,则返回-1 if (v < 0 || v > (vertexs.length - 1)) { return -1; } /*根据邻接矩阵的规律:顶点索引v对应着边二维矩阵的matrix[v][i]一行记录 * 从i=0开始*/ for (int i = 0; i < vertexs.length; i++) { if (matrix[v][i] == 1) { return i; } } return -1; } /** * 返回顶点v相对于w的下一个邻接顶点的索引,失败则返回-1 * * @param v 顶点索引 * @param w 第一个邻接点索引 * @return 返回顶点v相对于w的下一个邻接顶点的索引,失败则返回-1 */ private int nextVertex(int v, int w) { //如果索引超出范围,则返回-1 if (v < 0 || v > (vertexs.length - 1) || w < 0 || w > (vertexs.length - 1)) { return -1; } /*根据邻接矩阵的规律:顶点索引v对应着边二维矩阵的matrix[v][i]一行记录 * 由于邻接点w的索引已经获取了,所以从i=w+1开始寻找*/ for (int i = w + 1; i < vertexs.length; i++) { if (matrix[v][i] == 1) { return i; } } return -1; } /* * 广度优先搜索(类似于树的层次遍历) */ public void BFS() { // 辅组队列 Queue<Integer> indexLinkedList = new LinkedList<>(); //新建顶点访问标记数组,对应每个索引对应相同索引的顶点数组中的顶点 boolean[] visited = new boolean[vertexs.length]; for (int i = 0; i < vertexs.length; i++) { visited[i] = false; } System.out.println("BFS: "); for (int i = 0; i < vertexs.length; i++) { if (!visited[i]) { visited[i] = true; System.out.print(vertexs[i] + " "); indexLinkedList.add(i); } if (!indexLinkedList.isEmpty()) { //j索引出队列 Integer j = indexLinkedList.poll(); //继续访问j的邻接点 for (int k = firstVertex(j); k >= 0; k = nextVertex(j, k)) { if (!visited[k]) { visited[k] = true; System.out.print(vertexs[k] + " "); //继续入队列 indexLinkedList.add(k); } } } } System.out.println(); } @Override public String toString() { StringBuilder stringBuilder = new StringBuilder(); for (int i = 0; i < vertexs.length; i++) { for (int j = 0; j < vertexs.length; j++) { stringBuilder.append(matrix[i][j]).append(" "); } stringBuilder.append("\n"); } return stringBuilder.toString(); } public static void main(String[] args) { Character[] vexs = {'A', 'B', 'C', 'D', 'E', 'F', 'G'}; Character[][] edges = { {'A', 'C'}, //对于无向图来说是多余的边关系,在linkLast方法中做了判断,并不会重复添加 {'A', 'D'}, {'A', 'D'}, {'D', 'A'}, {'A', 'F'}, {'B', 'C'}, {'C', 'D'}, {'E', 'G'}, {'E', 'B'}, {'D', 'B'}, {'F', 'G'}}; //构建图 UndirectedAdjacencyMatrix<Character> undirectedAdjacencyMatrix = new UndirectedAdjacencyMatrix<>(vexs, edges); //输出图 System.out.println(undirectedAdjacencyMatrix); //深度优先遍历 undirectedAdjacencyMatrix.DFS(); //广度优先遍历 undirectedAdjacencyMatrix.BFS(); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
测试无向图对应的逻辑结构如下:
测试图的遍历结果如下:

可以看到,深度优先遍历出来的顺序不一致,实际上这是内部节点的实际存储顺序和结构的问题导致的,但是我们的思想并没有变,因此该遍历也是正确的,实际上如果图的实现不唯一,那么遍历顺序也不一定是唯一的。
4.4 有向图的邻接矩阵实现
/** * 有向图邻接矩阵简单实现 * {@link AdjacencyMatrix#AdjacencyMatrix(E[], E[][])} 构建有向图 * {@link AdjacencyMatrix#DFS()} 深度优先遍历无向图 * {@link AdjacencyMatrix#BFS()} 广度优先遍历无向图 * {@link AdjacencyMatrix#toString()} ()} 输出无向图 * * @author lx */ public class AdjacencyMatrix<E> { /** * 顶点数组 */ private Object[] vertexs; /** * 邻接矩阵 */ private int[][] matrix; /** * 创建有向图 * * @param vexs 顶点数组 * @param edges 边二维数组 */ public AdjacencyMatrix(E[] vexs, E[][] edges) { // 初始化顶点数组,并添加顶点 vertexs = Arrays.copyOf(vexs, vexs.length); // 初始化边矩阵,并填充边信息 matrix = new int[vexs.length][vexs.length]; for (E[] edge : edges) { // 读取一条边的起始顶点和结束顶点索引值 p1,p2表示边方向p1->p2 int p1 = getPosition(edge[0]); int p2 = getPosition(edge[1]); //p1 出度的位置 置为1 matrix[p1][p2] = 1; //无向图和有向图的邻接矩阵实现的区别就在于下面这一行代码 //matrix[p2][p1] = 1; } } /** * 获取某条边的某个顶点所在顶点数组的索引位置 * * @param e 顶点的值 * @return 所在顶点数组的索引位置, 或者-1 - 表示不存在 */ private int getPosition(E e) { for (int i = 0; i < vertexs.length; i++) { if (vertexs[i] == e) { return i; } } return -1; } /** * 深度优先搜索遍历图,类似于树的前序遍历, */ public void DFS() { //新建顶点访问标记数组,对应每个索引对应相同索引的顶点数组中的顶点 boolean[] visited = new boolean[vertexs.length]; //初始化所有顶点都没有被访问 for (int i = 0; i < vertexs.length; i++) { visited[i] = false; } System.out.println("DFS: "); for (int i = 0; i < vertexs.length; i++) { if (!visited[i]) { DFS(i, visited); } } System.out.println(); } /** * 深度优先搜索遍历图的递归实现,类似于树的先序遍历 * 因此模仿树的先序遍历,同样借用栈结构,这里使用的是方法的递归,隐式的借用栈 * * @param i 顶点索引 * @param visited 访问标志数组 */ private void DFS(int i, boolean[] visited) { visited[i] = true; System.out.print(vertexs[i] + " "); // 遍历该顶点的所有邻接点。若该邻接点是没有访问过,那么继续递归遍历领接点 for (int w = firstVertex(i); w >= 0; w = nextVertex(i, w)) { if (!visited[w]) { DFS(w, visited); } } } /** * 返回顶点v的第一个邻接顶点的索引,失败则返回-1 * * @param v 顶点v在数组中的索引 * @return 返回顶点v的第一个邻接顶点的索引,失败则返回-1 */ private int firstVertex(int v) { //如果索引超出范围,则返回-1 if (v < 0 || v > (vertexs.length - 1)) { return -1; } /*根据邻接矩阵的规律:顶点索引v对应着边二维矩阵的matrix[v][i]一行记录 * 从i=0开始*/ for (int i = 0; i < vertexs.length; i++) { if (matrix[v][i] == 1) { return i; } } return -1; } /** * 返回顶点v相对于w的下一个邻接顶点的索引,失败则返回-1 * * @param v 顶点索引 * @param w 第一个邻接点索引 * @return 返回顶点v相对于w的下一个邻接顶点的索引,失败则返回-1 */ private int nextVertex(int v, int w) { //如果索引超出范围,则返回-1 if (v < 0 || v > (vertexs.length - 1) || w < 0 || w > (vertexs.length - 1)) { return -1; } /*根据邻接矩阵的规律:顶点索引v对应着边二维矩阵的matrix[v][i]一行记录 * 由于邻接点w的索引已经获取了,所以从i=w+1开始寻找*/ for (int i = w + 1; i < vertexs.length; i++) { if (matrix[v][i] == 1) { return i; } } return -1; } /* * 广度优先搜索(类似于树的层次遍历) */ public void BFS() { // 辅组队列 Queue<Integer> indexLinkedList = new LinkedList<>(); //新建顶点访问标记数组,对应每个索引对应相同索引的顶点数组中的顶点 boolean[] visited = new boolean[vertexs.length]; for (int i = 0; i < vertexs.length; i++) { visited[i] = false; } System.out.println("BFS: "); for (int i = 0; i < vertexs.length; i++) { if (!visited[i]) { visited[i] = true; System.out.print(vertexs[i] + " "); indexLinkedList.add(i); } if (!indexLinkedList.isEmpty()) { //j索引出队列 Integer j = indexLinkedList.poll(); //继续访问j的邻接点 for (int k = firstVertex(j); k >= 0; k = nextVertex(j, k)) { if (!visited[k]) { visited[k] = true; System.out.print(vertexs[k] + " "); //继续入队列 indexLinkedList.add(k); } } } } System.out.println(); } @Override public String toString() { StringBuilder stringBuilder = new StringBuilder(); for (int i = 0; i < vertexs.length; i++) { for (int j = 0; j < vertexs.length; j++) { stringBuilder.append(matrix[i][j]).append(" "); } stringBuilder.append("\n"); } return stringBuilder.toString(); } public static void main(String[] args) { Character[] vexs = {'A', 'B', 'C', 'D', 'E', 'F', 'G'}; Character[][] edges = { {'A', 'C'}, //对于无向图来说是多余的边关系,在linkLast方法中做了判断,并不会重复添加 {'A', 'D'}, {'A', 'D'}, {'D', 'A'}, {'A', 'F'}, {'B', 'C'}, {'C', 'D'}, {'E', 'G'}, {'E', 'B'}, {'D', 'B'}, {'F', 'G'}}; //构建图 AdjacencyMatrix<Character> undirectedAdjacencyMatrix = new AdjacencyMatrix<>(vexs, edges); //输出图 System.out.println(undirectedAdjacencyMatrix); //深度优先遍历 undirectedAdjacencyMatrix.DFS(); //广度优先遍历 undirectedAdjacencyMatrix.BFS(); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
测试有向图对应的逻辑结构以及遍历结果和有向图的邻接表实现的结果是一致的。
5 总结
首先介绍了图的入门概念,然后介绍了图的邻接矩阵和邻接表两种存储结构、以及深度优先遍历和广度优先遍历的两种遍历方式,最后提供了Java代码的实现。
关于图的实现,Guava中的com.google.common.graph模块已经提供了图的各种实现,而且都非常完美,这里只提供四个简单实现。带权重的图的实现,将在后面的最小生成树和最短路径的博客中提供实现,大家可以关注一下。
最新更新: 加权图的实现已经出来了,可以看看这篇文章:图的最小生成树的Prim算法和Kruskal算法原理解析以及Java代码的实现。
从上面的实现可以看出来,如果我们选择了合适的存储结构,那么图的实现相比于某些树(比如红黑树、平衡树),要想实现基本功能的话,还是非常简单的。
相关参考:
- 《算法》
- 《数据结构与算法》
- 《大话数据结构》
如果有什么不懂或者需要交流,可以留言。另外希望点赞、收藏、关注,我将不间断更新各种Java学习博客!



