
- 1闻风丧胆的算法(一)
- 2向量数据库:Milvus_milvus.exception.paramex row count not
- 3路口最短时间问题【华为OD机试】(JAVA&Python&C++&JS题解)
- 4长短期记忆网络(LSTM)详解
- 5防火墙的配置与应用_锐捷防火墙管理地址
- 6推荐收藏!九大最热门的开源大模型 Agent 框架来了_agent框架
- 7如何配置 Linux 服务在崩溃或重启后自动启动 – 第一部分:实际示例_/usr/sbin/sshd -d $options $crypto_policy $permitr
- 8【HTTPS】使用OpenSSL生成带有SubjectAltName的自签名证书_openssl subjectaltname
- 9Hive collect、explode函数详解(包括concat、Lateral View)_collect函数
- 10【CVPR_2023论文精读】E4S: Fine-grained Face Swapping via Regional GAN Inversion_e4s faceswap
YOLOV5改进:添加注意力机制_yolov5注意力机制
赞
踩
目录
一、什么是注意力机制?
注意力机制是指人类或机器在处理信息时,对于某些特定的信息或区域给予更高的关注和处理能力的一种认知机制。它模拟了人类在面对复杂的信息时,通过选择性地关注和集中注意力,从而提高信息处理和理解的效果。通俗地说,就是更好地寻找自己感兴趣的区域或目标。
作用:在机器学习和人工智能领域,注意力机制被广泛应用于各种任务,特别是在自然语言处理和计算机视觉中。通过引入注意力机制,模型可以自动地学习和集中关注输入数据中的关键信息,从而提高任务的准确性和效果。注意力机制可以帮助模型在处理序列数据时,动态地选择性地关注输入序列的不同位置或特征,从而更好地捕捉序列中的相关信息。在计算机视觉中,注意力机制可以使模型集中关注图像中的重要区域或特征,以便更好地理解和分析图像。
通道注意力机制
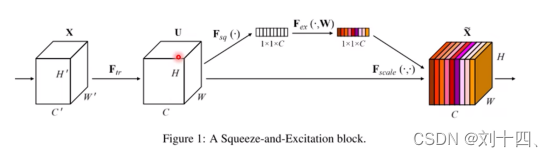
注意力机制的具体实现过程如上图所示。其中,W’表示特征宽度,H’表示特征高度,C’表示特征通道数,通过一系列的卷积操作后得到W*H*C的特征图,然后采用以下操作得到通道维数上引入注意力机制。
第一个操作(squeeze):通过全局池化,将每个通道的二维特征H*W压缩为一个实数,此处时通过平均池化的操作方式实现的。
第二个操作(excitation):通过参数来为每个特征通道生成一个权重值,此处时通过两个全连接层组成一个BottleNeck结构去建模通道间的相关性,并输出和特征同样数目的归一化通道值。
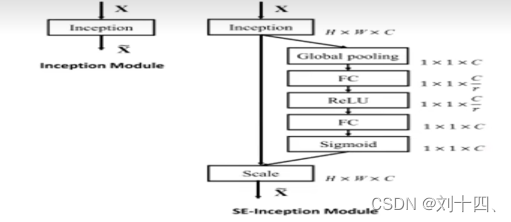
上图结构说明了如何为每个特征通道生成一个权重值,FC+ReLU+FC+Sigmoid就excitation操作。具体过程是首先通过一个全连接层(FC)将特征维度降到原来的1/r,然后经过ReLU函数激活后在通过一个全连接层(FC)生回到原来的特征维度C,生回到原来的特征维度C,最后通过Sigmoid函数转化为一个0-1的归一化权值。
第三个操作(scale):将前面得到的归一化权值加权到每个通道上。此处是采用乘法,逐通道乘以权重系数。
二、添加Attention机制方法
(本文以CA注意力机制为例,其他注意力添加方法依此类推)
1.common.py添加相应条件
将下面这段代码粘贴到common.py文件中;
- class CoordAtt(nn.Module):
- def __init__(self, inp, oup, reduction=32):
- super(CoordAtt, self).__init__()
- self.pool_h = nn.AdaptiveAvgPool2d((None, 1))
- self.pool_w = nn.AdaptiveAvgPool2d((1, None))
-
- mip = max(8, inp // reduction)
-
- self.conv1 = nn.Conv2d(inp, mip, kernel_size=1, stride=1, padding=0)
- self.bn1 = nn.BatchNorm2d(mip)
- self.act = h_swish()
-
- self.conv_h = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)
- self.conv_w = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)
-
- def forward(self, x):
- identity = x
-
- n, c, h, w = x.size()
- x_h = self.pool_h(x)
- x_w = self.pool_w(x).permute(0, 1, 3, 2)
-
- y = torch.cat([x_h, x_w], dim=2)
- y = self.conv1(y)
- y = self.bn1(y)
- y = self.act(y)
-
- x_h, x_w = torch.split(y, [h, w], dim=2)
- x_w = x_w.permute(0, 1, 3, 2)
-
- a_h = self.conv_h(x_h).sigmoid()
- a_w = self.conv_w(x_w).sigmoid()
-
- out = identity * a_w * a_h
-
- return out

2.yolo.py添加判断条件
找到yolo.py文件里的parse_model函数,将类名添加进去;

3.创建自己的注意力yaml文件
复制一份yolo.yaml文件并重新命名自己的yaml文件,然后将自己的文件中插入注意力机制。注意力机制放置的位置并不是唯一的,需要根据你的数据集来摸索测试,可能别人放这儿涨点了,但你放这儿并没效果,俗称“玄学”

注:当网络中加入新的层以后,后续的层随之发生改变, 要修改backbone、head里面的from系数;
4.验证是否成功添加注意力机制
找到train.py文件中的如下代码,改为自己的yaml文件,然后运行train.py文件,若出现类似下面带有添加的注意力层即为添加成功,未出现或报错即为失败;
- from n params module arguments
- 0 -1 1 3520 models.common.Focus [3, 32, 3]
- 1 -1 1 10144 models.experimental.GhostConv [32, 64, 3, 2]
- 2 -1 1 19904 models.common.BottleneckCSP [64, 64, 1]
- 3 -1 1 38720 models.experimental.GhostConv [64, 128, 3, 2]
- 4 -1 1 161152 models.common.BottleneckCSP [128, 128, 3]
- 5 -1 1 151168 models.experimental.GhostConv [128, 256, 3, 2]
- 6 -1 1 641792 models.common.BottleneckCSP [256, 256, 3]
- 7 -1 1 597248 models.experimental.GhostConv [256, 512, 3, 2]
- 8 -1 1 25648 models.common.CoordAtt [512, 512]
- 9 -1 1 656896 models.common.SPP [512, 512, [5, 9, 13]]
- 10 -1 1 1248768 models.common.BottleneckCSP [512, 512, 1, False]
- 11 -1 1 131584 models.common.Conv [512, 256, 1, 1]
- 12 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
- 13 [-1, 6] 1 0 models.common.Concat [1]
- 14 -1 1 361984 models.common.C3 [512, 256, 1, False]
- 15 -1 1 6680 models.common.CoordAtt [256, 256]
- 16 -1 1 66048 models.common.Conv [256, 256, 1, 1]
- 17 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
- 18 [-1, 4] 1 0 models.common.Concat [1]
- 19 -1 1 329216 models.common.C3 [384, 256, 1, False]
- 20 -1 1 6680 models.common.CoordAtt [256, 256]
- 21 -1 1 33024 models.common.Conv [256, 128, 1, 1]
- 22 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
- 23 [-1, 2] 1 0 models.common.Concat [1]
- 24 -1 1 82688 models.common.C3 [192, 128, 1, False]
- 25 -1 1 3352 models.common.CoordAtt [128, 128]
- 26 -1 1 147712 models.common.Conv [128, 128, 3, 2]
- 27 [-1, 21] 1 0 models.common.Concat [1]
- 28 -1 1 90880 models.common.C3 [256, 128, 1, False]
- 29 -1 1 3352 models.common.CoordAtt [128, 128]
- 30 -1 1 147712 models.common.Conv [128, 128, 3, 2]
- 31 [-1, 16] 1 0 models.common.Concat [1]
- 32 -1 1 329216 models.common.C3 [384, 256, 1, False]
- 33 -1 1 6680 models.common.CoordAtt [256, 256]
- 34 -1 1 590336 models.common.Conv [256, 256, 3, 2]
- 35 [-1, 11] 1 0 models.common.Concat [1]
- 36 -1 1 1182720 models.common.C3 [512, 512, 1, False]
- 37 -1 1 25648 models.common.CoordAtt [512, 512]
- 38 [28, 31, 34, 37] 1 34668 models.yolo.Detect [4, [[5, 6, 8, 14, 15, 11], [10, 13, 16, 30, 33, 23], [30, 61, 62, 45, 59, 119], [116, 90, 156, 198, 373, 326]], [128, 384, 256, 512]]

