
- 1leetcode 377. 组合总和 Ⅳ
- 2【开发日记】Error: error:0308010C:digital envelope routines::unsupported_95% emitting compressionplugin error error: error:
- 3贝叶斯算法(1)_贝叶斯共定位分析
- 4当艺术遇上AI:AI赋能生产力的可能场景和应用思路
- 5微信电脑客户端_手机远程控制电脑!牛逼!
- 6Jenkins镜像加速(清华大学镜像)_json模块清华镜像源
- 7python1_turtlependown的作用
- 8VOJ 金字塔数独 题解 DFS
- 9Datawhale 动手学大模型应用开发 第四五章笔记 向量数据库 / Prompt / 检索chain / 记忆_大模型如何将prompt和向量数据库进行检索
- 10华为ensp防火墙nat64案例配置_ensp nat64
结合listary以及百度网盘实现快捷的网盘化文件搜索_百度网盘api收费
赞
踩
listary是一款有年头的效率工具,通过快捷的方式打开(如双击连击CTRL),能够非常快速以关键字匹配的方式搜索本地存放的文件(注:是匹配文件名,而不是文件内容)。对于各种文档特别多,知识文档、开发文档装满了电脑的用户,这款工具大大的提高了工作效率,可以把时间和精力从搜索文件的繁琐中解放出来,人也不会因为烦恼和忧虑于大脑里记忆不了越来越多的知识,而受困。因为只需要保存文档或者重新命名时有意的把关键词作为文件名称的一部分。那知识和经验,不再需要真的记忆在自己的大脑中,或者说不怕忘记和找不到已经掌握的知识,通过效率工具对于采集过或者用过的文档、工程或者说承载着知识的文件,都能随时搜索获取到。知识不需要一定完整的保留在大脑里了,只在需要的时候快速、高概率的获得就可以了。大大的提高了效率和降低了知识工作的心智门槛。
正如《知识的错觉》所说,“我们自以为那些有关事物运行规则的知识是印在自己脑袋里的,而事实上我们从周遭环境及他人身上获取了很多。这既是认知的特征也是认知的死结。我们知识库的绝大部分都存储于这世界和我们的社群里。多数人的理解力仅限于意识到知识就在那里。高级的理解力通常还包括知道可以去哪里获取知识。” 像listary这样的效率工具,使得我们的知识更不需要太依赖生理的大脑来存储和及时应用。我们只需要,在有的基础上,知道如何可能找到就可以了。
不过,对于笔者这种使用的笔记本电脑空间不大的人来说,一个新的问题出现了 ,也就是笔记本电脑的空间小、固态化硬盘不会太大导致的空间问题。关于文档(知识)存储遇到了瓶颈,硬盘太小,不够用。因此笔者就利用百度云盘及其开放API,进行了尝试解决这个问题,并得到了基本实现和验证。本文就是关于此过程以及有关代码细节的完整记录。
首先,由于文件(文档)太多,我将本地的大量文件都上传到了百度云盘上(我购买了VIP,所以空间比较大)。
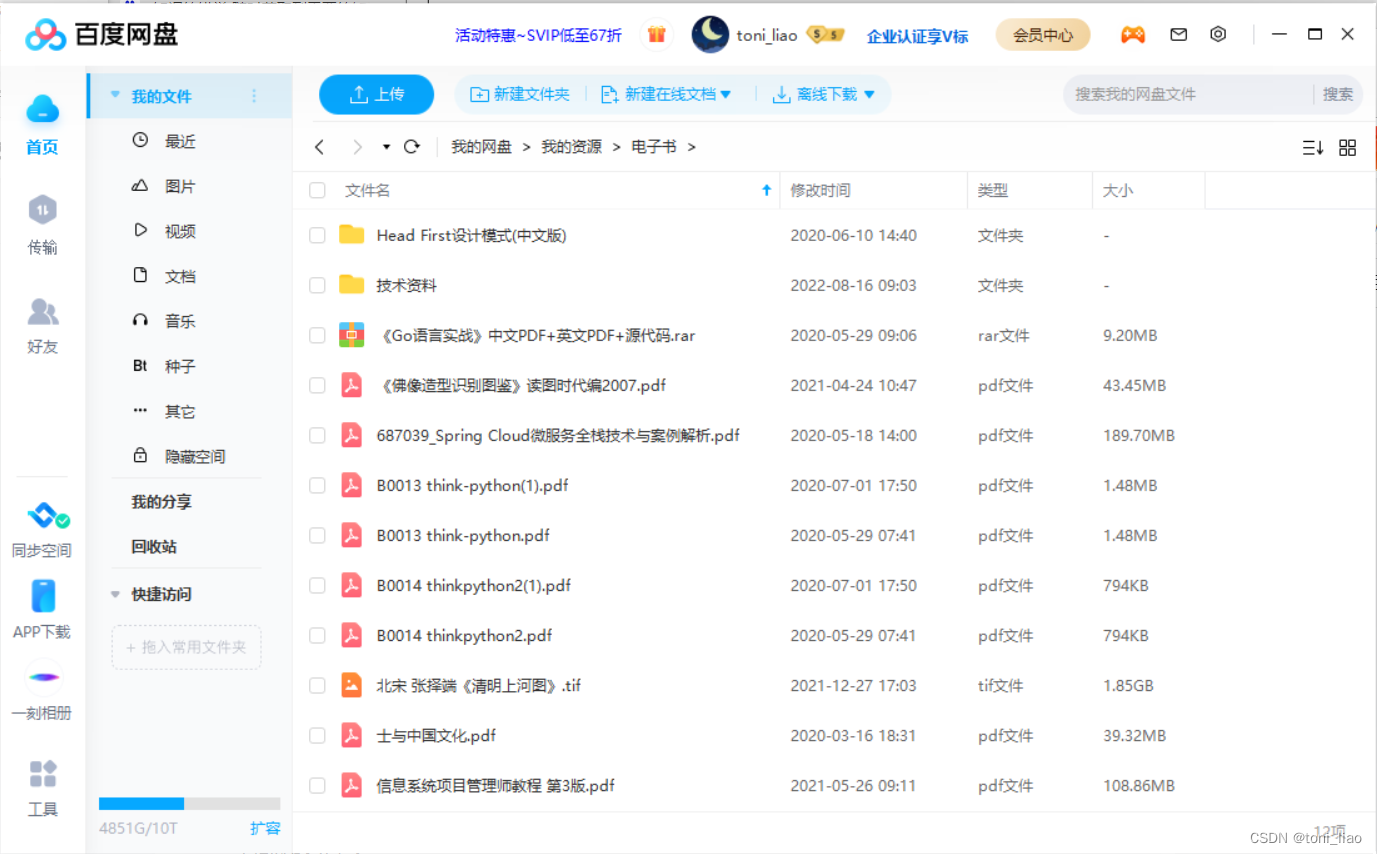
然后,利用百度云的开放API,基于PYTHON的SDK编写了本地(WIN10)可以运行的脚本程序,给命令行操作提供了条件,然后结合listary的关键字配置功能以命令行为触发基底,实现了快捷方式搜索网盘文件的效果。
具体处理内容和过程如下
首先,访问百度云网盘的开发API网站,下载PYTHON的SDK
开发指导站点URL
SDK下载站点URL
注意,本地要先安装python执行环境,至少是在3.8.5以上的版本(我的版本是3.8.9),需要执行
pip install urllib3==1.26.7 (2022年8月而言这个是最新的版本依赖)
下载的SDK,说白了是一堆python脚本,该脚本由工程根本目录(文件而言是空的)及demo,openapi_cient两个子目录及其文件组成,可在该目录下编辑开发一个脚本
- '''
- Created on 2022年8月16日
- @author: longlongago
- '''
-
- import os,sys
- BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
- RESULT_FILE_PATH = os.path.dirname(os.path.abspath(__file__))
- sys.path.append(BASE_DIR)
- import openapi_client
- from openapi_client.api import fileinfo_api
- from pprint import pprint
-
- #2022年8月16日申请,有效期到9月16日
- global_access_token ="123.a5a8e6b9edd3451d9c5c51a2e050373f.YBwT1zMqR3_gUkDbEd-k4XePKwabnLtCzumXkJw.z-CXjA"
-
- import sys
- import time
-
- def find_files(search_target):
- """
- user_info demo
- """
- # Enter a context with an instance of the API client
- with openapi_client.ApiClient() as api_client:
- # Create an instance of the API class
- #api_instance = userinfo_api.UserinfoApi(api_client)
- api_instance = fileinfo_api.FileinfoApi(api_client)
- access_token = global_access_token # str |
-
- key = search_target # str |
- web = "0" # str | (optional) 默认0,为1时返回缩略图信息
- num = "200" # str | (optional) 每页多少条
- page = "1" # str | (optional) 从哪一页开始
- dir = "/" # str | (optional)
- recursion = "1" # str | (optional) 是否递归搜索子目录 1:是,0:否(默认)
- # example passing only required values which don't have defaults set
- try:
- api_response = api_instance.xpanfilesearch(
- access_token, key, web=web, num=num, page=page, dir=dir, recursion=recursion)
- if len(api_response['list']) == 0:
- pprint("百度云盘上没有匹配关键字的文件")
- time.sleep(3)
- return
- #print(RESULT_FILE_PATH+'/findfiles_result.txt') #获取当前目录文件下的文件目录路径
- fileName=RESULT_FILE_PATH+'/findfiles_result.txt'
- with open(fileName,'w')as file:
- for unit in api_response['list']:
- #pprint(unit['server_filename'])
- file.write("文件名及目录:["+unit['path']+"]")
- file.write("\n")
- file.close()
-
- print("尝试打开搜索结果文件")
- import subprocess as sp
- #打开文件,方便友好化的查看搜索结果。此种打开文件方式后续不会阻塞,脚本执行完毕后也不会自动关闭文档窗口
- programName = "notepad.exe"
- sp.Popen([programName, fileName],close_fds=True)
- #import os
- # osCommandString = "notepad.exe findfiles_result.txt"
- # os.system(osCommandString)#此种打开文档方式,后续会阻塞
-
- time.sleep(5)
- except openapi_client.ApiException as e:
- print("Exception when calling UserinfoApi->xpannasuinfo: %s\n" % e)
- time.sleep(100)
- except Exception as e_all:
- print(e_all)
- time.sleep(100)
-
-
-
- if __name__ == '__main__':
- pprint('搜索的关键字是2:'+sys.argv[1])
- find_files(sys.argv[1])
- time.sleep(10)

这个脚本的目的是提供一个小脚本程序,可以通过直接命令行模式 带参数(也就是要检索的关键字)执行并返回和自动打开展现执行结果。
具体执行是类似如:python baiduCloudDiskHandler.py 技术
上面这样命令可以在cmd模式下执行,意图为以“技术”为关键字,搜索百度网盘上(提供了access_token的用户所属网盘范围,关于access_token后面会提到)的文件(注意:是文件名匹配,目录名不会作为匹配范围)。
这里access_token是需要修改成使用者或者说网盘提供者用户授权码的。这个过程如下:
首先,如果没有百度开放平台用户,则需要申请注册一个
百度网盘开放平台 (baidu.com) 申请过程比较简单,下面不再细致描述。
然后创建应用,过程比较简单,也不再细致描述了。创建应用完成后,将进入类似如下界面。
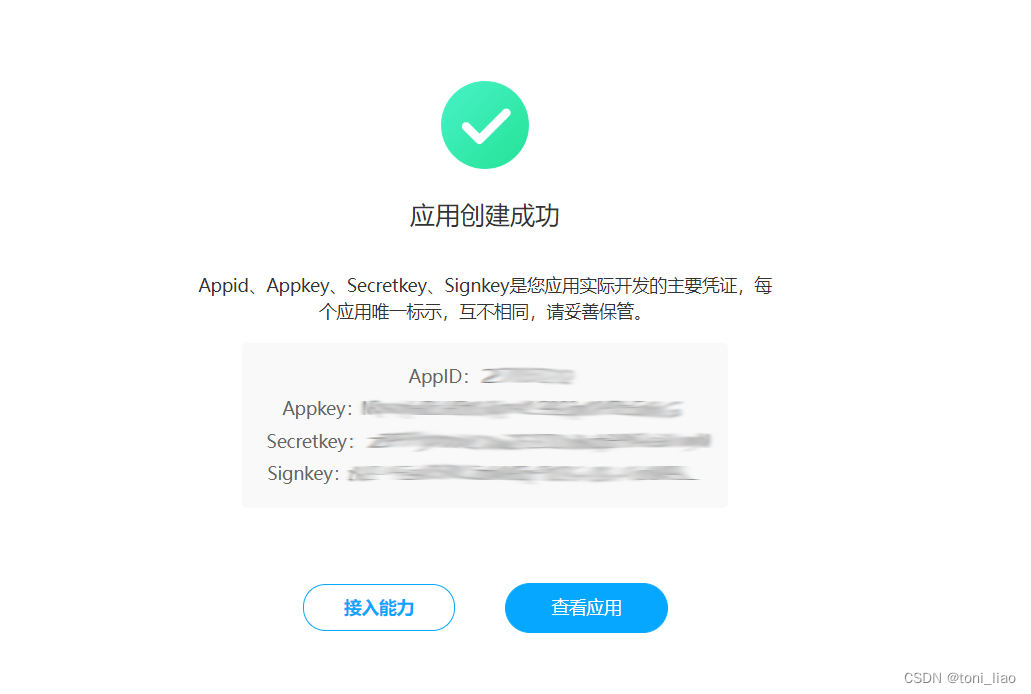
这里由分配的appid和appkey等信息。后续通过appid访问特定的URL经过授权行为可以获得access_token
具体操作可以如下:
打开一个浏览器,拷入URL地址
http://openapi.baidu.com/oauth/2.0/authorize?response_type=token&client_id=NR2sdyRkURtN456AC992qKVPIrtdihG&redirect_uri=oob&scope=basic,netdisk&display=popup&state=xxx
其中client_id=的值改成你生成应用的appid,redirect_uri=oob表明用的是百度自己的授权页面
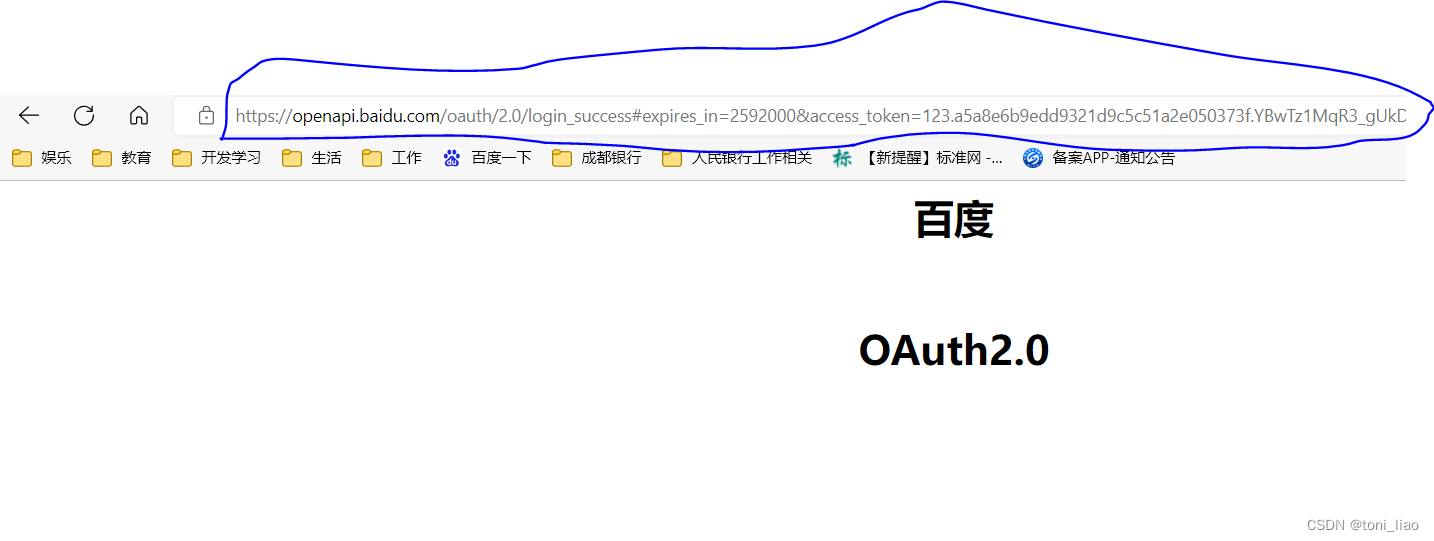
注意,浏览器地址栏里面的字符串中 access_token的值就是我们所需要的值,本质上就是使用API的合法性令牌。该令牌是后续访问百度网盘API时将要用到的访问授权码(该授权码有效期应为:2592000秒,也就是30天)拷贝到代码中,替代global_access_token 变量即可。
可以测试一下,建议测试一下。在CMD命令行模式或者ecipse等ide中执行一下该脚本,记得带上要匹配的关键字参数。
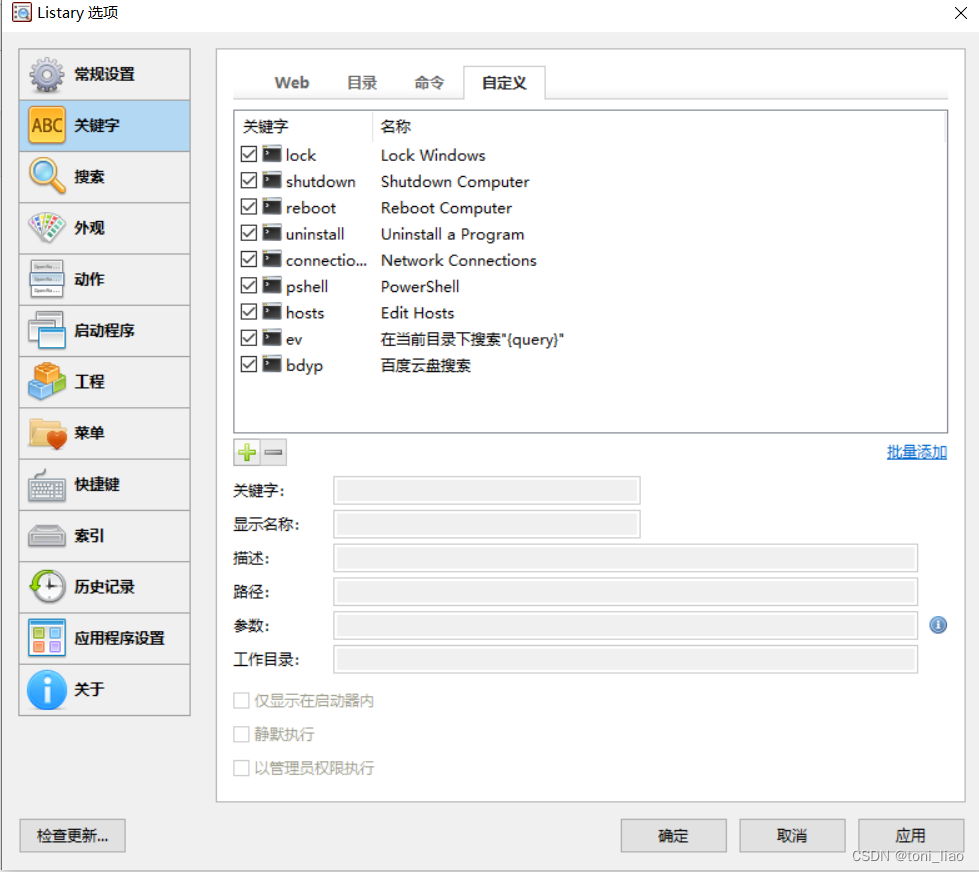
剩下来,就是 设置listary的把搜索能力匹配起来。进入listary设置(选项)界面,选择“关键字”到“自定义”,增加一个搜索关键字。我用的是拼音缩写作为此关键字bdyp(百度云盘),设置显示名称,路径和参数如下图。路径,是你自己放置脚本的位置,以及脚本名称。
然后就可以实验了。假如listary的快捷键没有修改过,则快速连击“CTRL",打开搜索栏,在搜索栏中输入bdyp(你自己定义的那个关键字)空格 本次搜索的关键字 (如"技术“)
 回车,即可触发搜索,自动展开一个记事本文件,效果如下图:
回车,即可触发搜索,自动展开一个记事本文件,效果如下图:
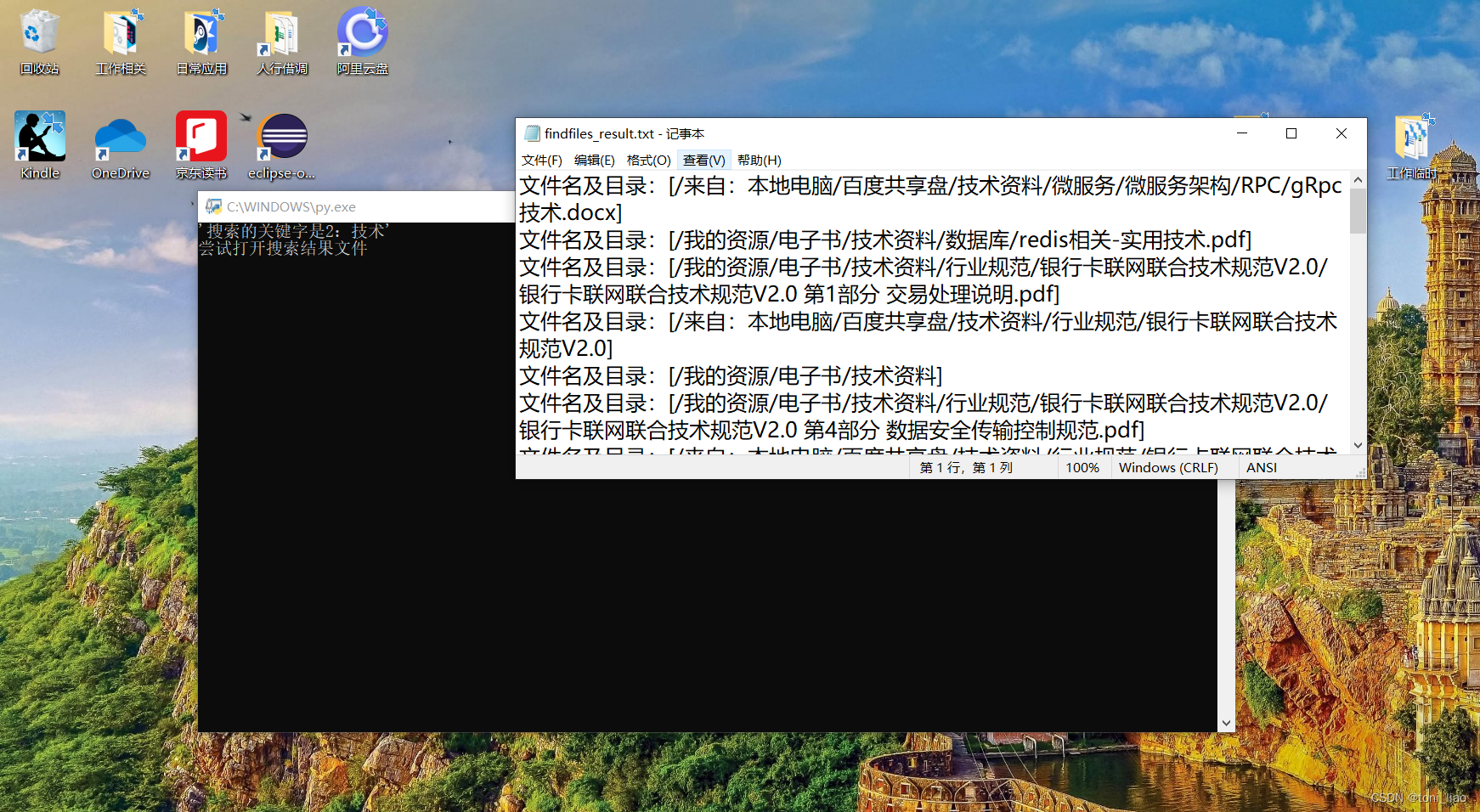
虽然,谈不上直接下载和打开有关的文件。
但对于搜索有关的知识文档、文件是否存在以及所在位置,这本身已经很有价值了。有时候,能理清方向,能快速理清方向就是那么的重要和有价值。
listary有免费的,有收费的,我花了几十元买的收费的,支持一下开发人员。不过实际上这个功能而言,免费版就可以了。另外百度网盘API本身不收费,不过最终应用时会不会依赖于百度网盘的VIP,这个就不好说了,没有条件测试。各位可以试试,如果不需要请在留言中告诉我。谢谢。

