
- 1学Python常逛的10个网站,都总结在这里了_python代码分享网站
- 2从外行到外包,从手工测试到知名互联大厂测开,我经历了什么...
- 3api中文文档 mws_therscan API 中文文档-智能合约
- 4交换机端口安全配置
- 5基于SpringBoot的“实习管理系统”的设计与实现(源码+数据库+文档+PPT)_实习管理平台源码
- 62020,我的秋招
- 7Linux入侵排查
- 8全志平台BSP裁剪(1)kernel裁剪--调试工具和调试信息的裁剪_全志a40i vmalloc
- 9无人驾驶学习笔记--路径规划(二)【Dubins曲线和Reeds-Shepp曲线】_dubins曲线,这对无人车
- 10【NLP】Word2Vec模型文本分类_word2vec 词聚类
python爬取网页的方法总结,python爬虫获取网页数据_python爬取网页对应信息
赞
踩
大家好,小编来为大家解答以下问题,python爬取网页信息代码正确爬取不到,利用python爬取简单网页数据步骤,今天让我们一起来看看吧!
文章目录
Python用做数据处理还是相当不错的,如果你想要做爬虫,Python是很好的选择,它有很多已经写好的类包,只要调用,即可完成很多复杂的功能
在我们开始之前,我们需要安装一些环境依赖包,打开命令行

确保电脑中具有python和pip,如果没有的话则需要自行进行安装
之后我们可使用pip安装必备模块 requests
pip install requests

requests是python实现的简单易用的HTTP库,使用起来比urllib简洁很多,requests 允许你发送 HTTP/1.1 请求。指定 URL并添加查询url字符串即可开始爬取网页信息
1.抓取网页源代码
以该平台为例,抓取网页中的公司名称数据,网页链接:https://www.crrcgo.cc/admin/crr_supplier.html?page=1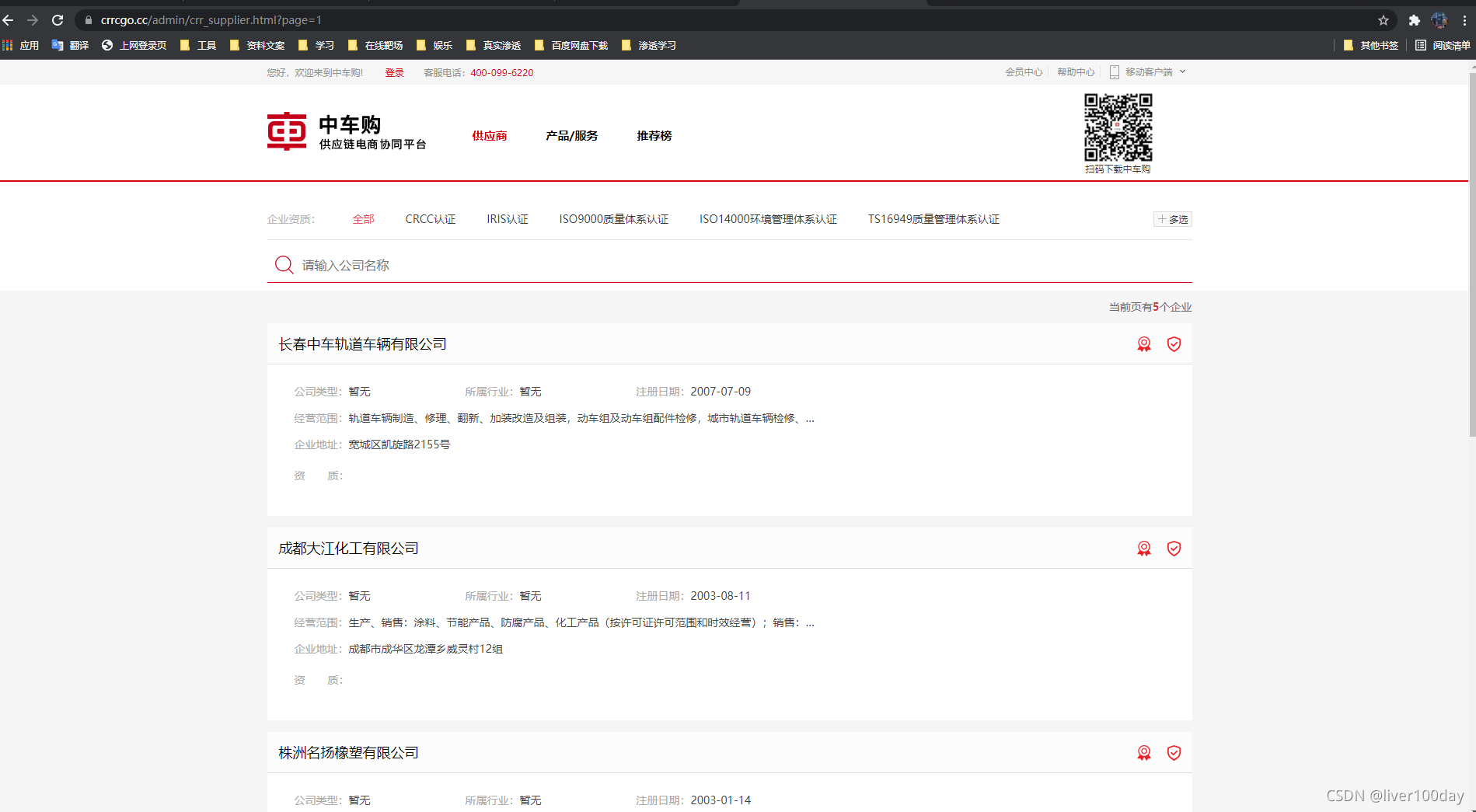
目标网页源代码如下: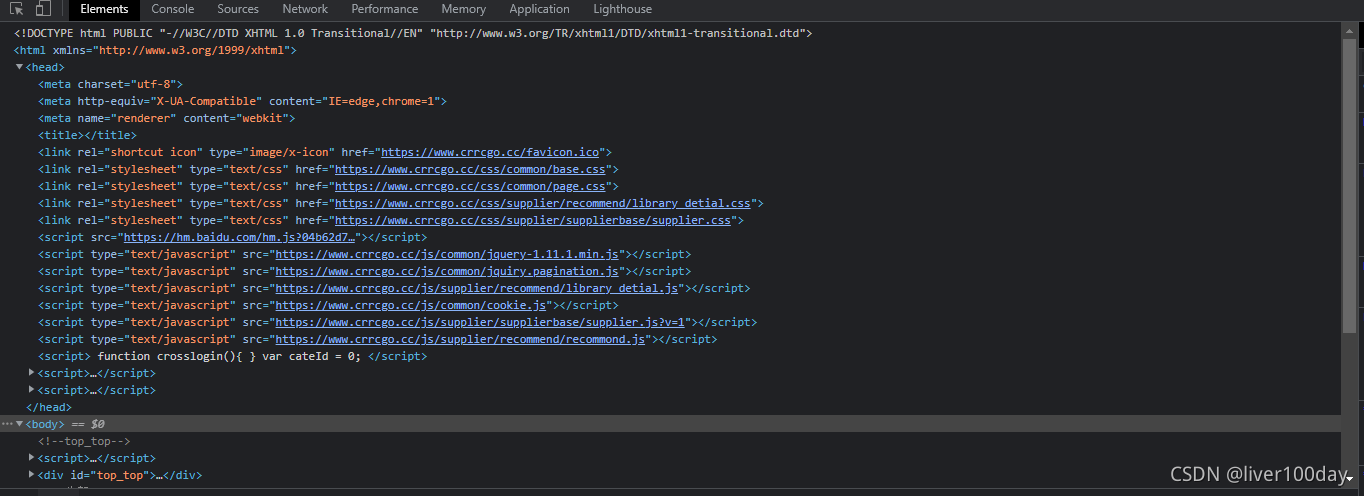
首先明确步骤
1.打开目标站点
2.抓取目标站点代码并输出
import requests
导入我们需要的requests功能模块
page=requests.get('https://www.crrcgo.cc/admin/crr_supplier.html?page=1')
这句命令的意思就是使用get方式获取该网页的数据神码ai火车头伪原创网址。实际上我们获取到的就是浏览器打开百度网址时候首页画面的数据信息
print(page.text)
这句是把我们获取数据的文字(text)内容输出(print)出来
- import requests
- page=requests.get('https://www.crrcgo.cc/admin/crr_supplier.html?page=1')
- print(page.text)

成功爬取到了目标网页源代码
2.抓取一个网页源代码中的某标签内容
但是上面抓取到的代码充满尖括号的一片字符,对我们没有什么作用,这样的充满尖括号的数据就是我们从服务器收到的网页文件,就像Office的doc、pptx文件格式一样,网页文件一般是html格式。我们的浏览器可以把这些html代码数据展示成我们看到的网页。
我们如果需要这些字符里面提取有价值的数据,就必须先了解标记元素
每个标记的文字内容都是夹在两个尖括号中间的,结尾尖括号用/开头,尖括号内(img和div)表示标记元素的类型(图片或文字),尖括号内可以有其他的属性(比如src)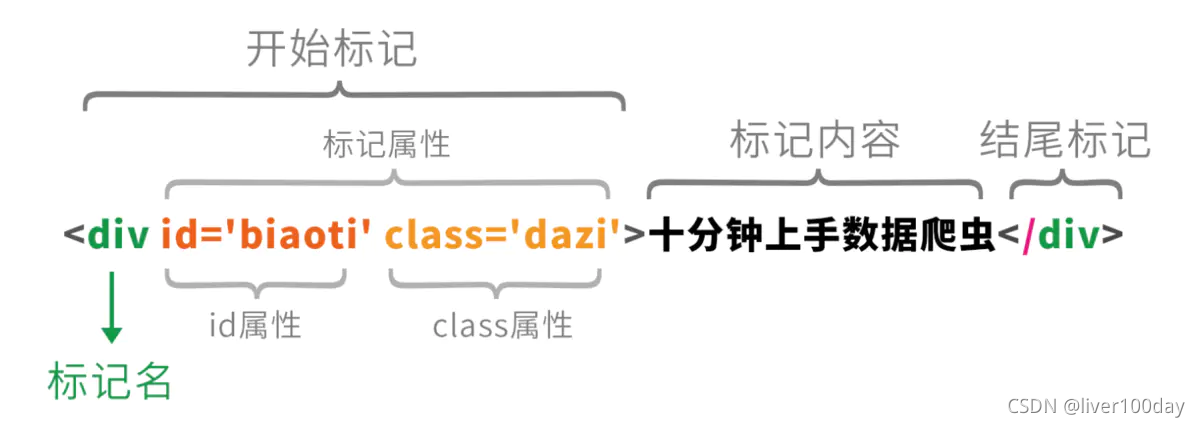
标记内容文字才是我们需要的数据,但我们要利用id或class属性才能从众多标记中找到需要的标记元素。
我们可以在电脑浏览器中打开任意网页,按下f12键即可打开元素查看器(Elements),就可以看到组成这个页面的成百上千个各种各样的标记元素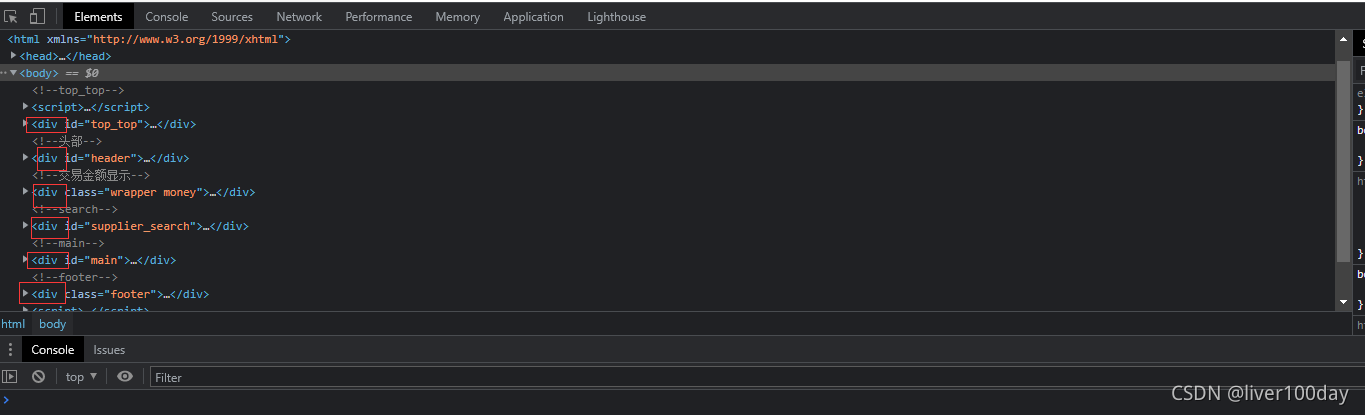
标记元素是可以一层一层嵌套的,比如下面就是body嵌套了div元素,body是父层、上层元素;div是子层、下层元素。
- <body>
- <div>十分钟上手数据爬虫</div>
- </body>
回到抓取上面来,现在我只想在网页中抓取公司名这个数据,其他的我不想要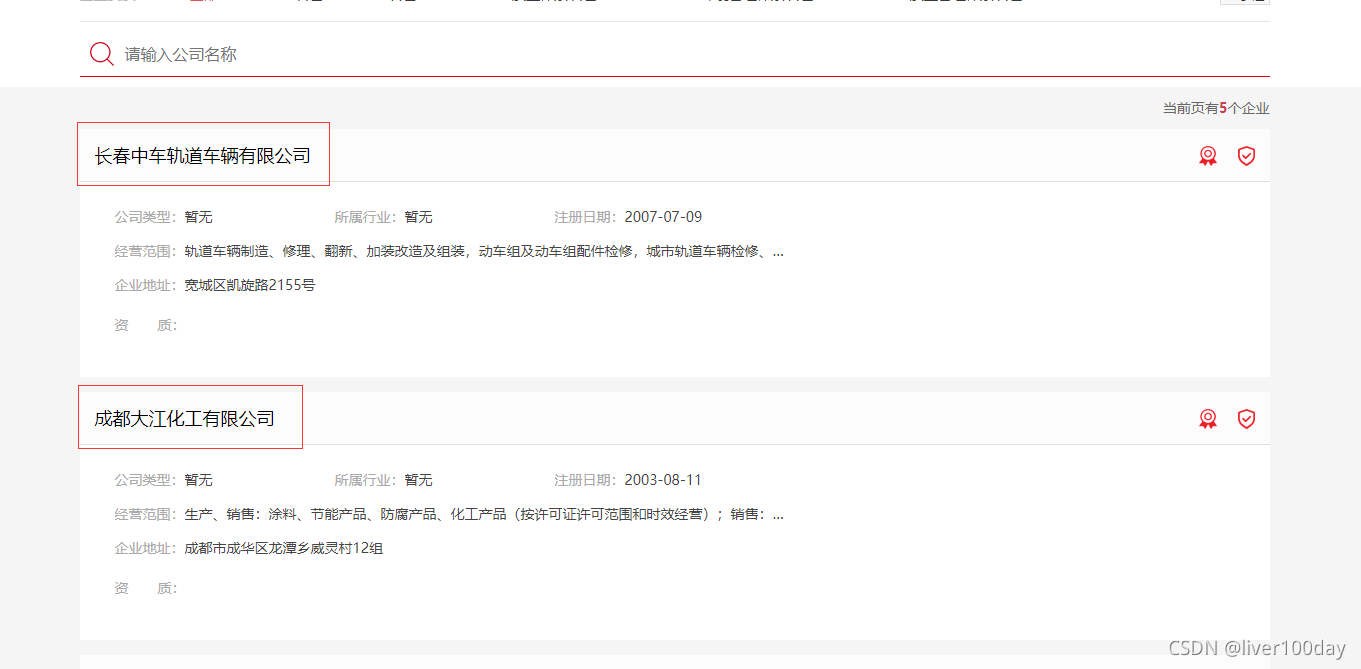
查看网页html代码,发现公司名在标签detail_head里面
- import requests
- req=requests.get('https://www.crrcgo.cc/admin/crr_supplier.html?page=1')
这两行上面解释过了,是获取页面数据
from bs4 import BeautifulSoup
我们需要使用BeautifulSoup这个功能模块来把充满尖括号的html数据变为更好用的格式,from bs4 import BeautifulSoup这个是说从bs4这个功能模块中导入BeautifulSoup,是的,因为bs4中包含了多个模块,BeautifulSoup只是其中一个
req.encoding = "utf-8"
指定获取的网页内容用utf-8编码
soup = BeautifulSoup(html.text, 'html.parser')
这句代码用html解析器(parser)来分析我们requests得到的html文字内容,soup就是我们解析出来的结果。
company_item=soup.find_all('div',class_="detail_head")
find是查找,find_all查找全部。查找标记名是div并且class属性是detail_head的全部元素
dd = company_item.text.strip()
strip() 方法用于移除字符串头尾指定的字符(默认为空格或换行符)或字符序列。在这里就是移除多余的尖括号的html数据
最后拼接之后代码如下:
- import requests
- from bs4 import BeautifulSoup
-
- req = requests.get(url="https://www.crrcgo.cc/admin/crr_supplier.html?page=1")
- req.encoding = "utf-8"
- html=req.text
- soup = BeautifulSoup(req.text,features="html.parser")
- company_item = soup.find("div",class_="detail_head")
- dd = company_item.text.strip()
- print(dd)

最后执行结果成功的抓取到了网页中我们想要的公司信息,但是却只抓取到了一个公司,其余的则并未抓取到
所以我们需要加入一个循环,抓取网页中所有公司名,并没多大改变
- for company_item in company_items:
- dd = company_item.text.strip()
- print(dd)
最终代码如下:
- import requests
- from bs4 import BeautifulSoup
-
- req = requests.get(url="https://www.crrcgo.cc/admin/crr_supplier.html?page=1")
- req.encoding = "utf-8"
- html=req.text
- soup = BeautifulSoup(req.text,features="html.parser")
- company_items = soup.find_all("div",class_="detail_head")
- for company_item in company_items:
- dd = company_item.text.strip()
- print(dd)
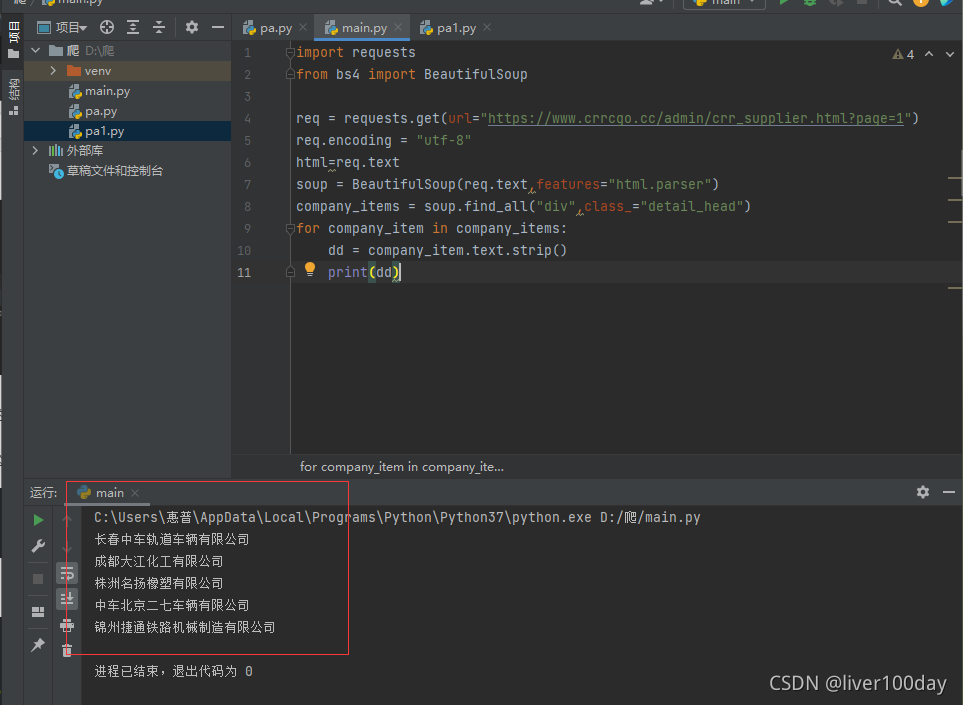
最终运行结果查询出了该网页中所有的公司名
3.抓取多个网页子标签的内容
那我现在想要抓取多个网页中的公司名呢?很简单,大体代码都已经写出,我们只需要再次加入一个循环即可
查看我们需要进行抓取的网页,发现当网页变化时,就只有page后面的数字会发生变化。当然很多大的厂商的网页,例如京东、淘宝 它们的网页变化时常让人摸不着头脑,很难猜测。
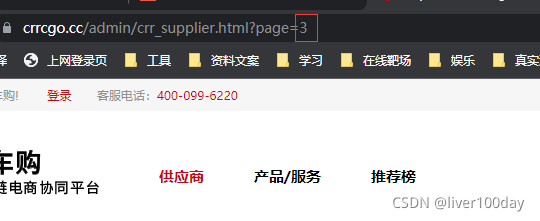
- inurl="https://www.crrcgo.cc/admin/crr_supplier.html?page="
- for num in range(1,6):
- print("================正在爬虫第"+str(num)+"页数据==================")
写入循环,我们只抓取1到5页的内容,这里的循环我们使用range函数来实现,range函数左闭右开的特性使得我们要抓取到5页必须指定6
- outurl=inurl+str(num)
- req = requests.get(url=outurl)
将循环值与url拼接成完整的url,并获取页面数据
完整代码如下:
- import requests
- from bs4 import BeautifulSoup
-
- inurl="https://www.crrcgo.cc/admin/crr_supplier.html?page="
- for num in range(1,6):
- print("================正在爬虫第"+str(num)+"页数据==================")
- outurl=inurl+str(num)
- req = requests.get(url=outurl)
- req.encoding = "utf-8"
- html=req.text
- soup = BeautifulSoup(req.text,features="html.parser")
- company_items = soup.find_all("div",class_="detail_head")
- for company_item in company_items:
- dd = company_item.text.strip()
- print(dd)
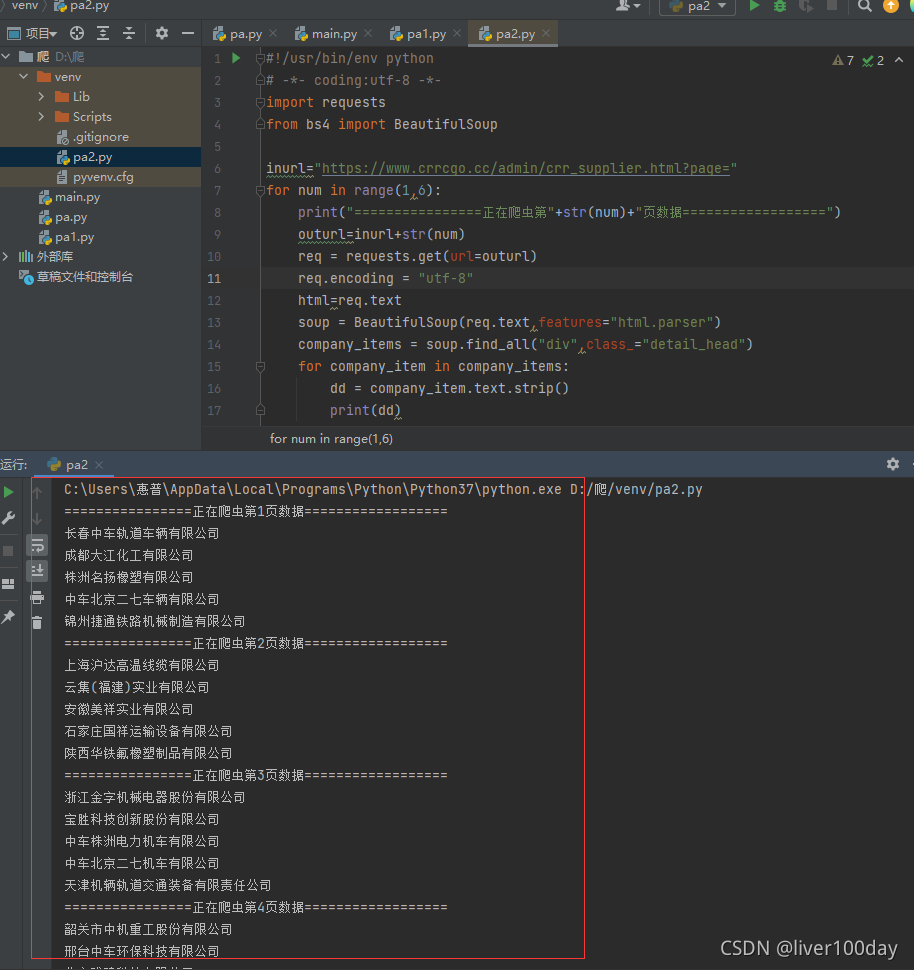
成功的抓取到了1-5页所有的公司名(子标签)内容
最近一直在学习,但是学习的东西很多很杂,于是便把自己的学习成果记录下来,便利自己,帮助他人。希望本篇文章能对你有所帮助,有错误的地方,欢迎指出!!!喜欢的话,不要忘记点赞哦!!!
先自我介绍一下,小编13年上师交大毕业,曾经在小公司待过,去过华为OPPO等大厂,18年进入阿里,直到现在。深知大多数初中级java工程师,想要升技能,往往是需要自己摸索成长或是报班学习,但对于培训机构动则近万元的学费,着实压力不小。自己不成体系的自学效率很低又漫长,而且容易碰到天花板技术停止不前。因此我收集了一份《java开发全套学习资料》送给大家,初衷也很简单,就是希望帮助到想自学又不知道该从何学起的朋友,同时减轻大家的负担。添加下方名片,即可获取全套学习资料哦

