
- 1【Python数据可视化】matplotlib之设置坐标:添加坐标轴名字、设置坐标范围、设置主次刻度、坐标轴文字旋转并标出坐标值_matplotlib设置xy轴刻度
- 2数据结构应用 - 栈
- 3喷药智能小车——附源代码_智能送药小车代码
- 4‘error:03000086:digital envelope routines::initialization“处理方法
- 5canopen
- 6大数据(四)主流大数据技术_主流的大数据技术
- 7python selenium打开新窗口,多窗口切换_selenium新开一个标签页
- 8人生需要执著——从二本三战到985博士_北理826专业课
- 9apriori数据集_Apriori算法详解
- 10用计算机打女生节快乐,2020年班级女生节快乐的祝福语
【python】Python详细语法教程以及案例教学之数据容器(中)(字符串、序列、集合、字典)_info.split(
赞
踩
前言:
Part1 学习了列表和元组,今天开始学习数据容器的下半部分吧
接上篇数据容器:
(28条消息) 【python】Python基础语法详细教程以及案例教学之数据容器(上)(列表、元组)_Ulpx的博客-CSDN博客
目录
五、再识字符串
尽管字符串看起来并不像:列表、元组那样,一看就是存放了许多数据的容器
但不可否认的是,字符串同样也是数据容器的一员。
字符串是字符的容器,一个字符串可以存放任意数量的字符
字符可以看作是字符的容器,支持下标索引等特性
如,字符串:“itheima"

1)字符串的下标(索引)
和其它容器如:列表、元组一样,字符串也可以通过下标进行访问
从前向后,下标从0开始
从后向前,下标从-1开始
示例:
2)无法修改性
同元组一样,字符串是一个: 无法修改的数据容器。
所以:
修改指定下标的宇符 (如:字符串[0]=“a”)
移除特定下标的宁符 (如: del 宇符串[0]、宇符串.remove()、宇符串,pop()等)追加字符等 (如:字符串.append())
均无法完成 如果必须要做,只能得到一个新的字符串
3)字符串的常用操作
查找特定字符串的下标索引值
语法: 字符串.index(字符串)
示例:
字符串的替换
语法: 字符串,replace(字符串1,字符串2)
功能:将字符串内的全部: 字符串1,替换为字符串2
注意: 不是修改字符串本身,而是得到了一个新字符串哦
示例:
字符串的分割
语法: 字符串.split(分隔符字符串)
功能:按照指定的分隔符字符串,将字符串划分为多个字符串,并存人列表对象中
注意:宁符串本身不变,而是得到了一个列表对象
示例:
字符串的规整操作(去前后空格)
语法: 字符串.strip()
字符串的规整操作(去前后指定字符串)
语法: 字符串.strip(字符串)
注意,传入的是“12”其实就是:”1”和”2”都会移除,是按照单个字符,将12划分为两个小子串
示例:
注意:不传入参数,去除首尾空格
统计字符串中某字符中出现次数
统计字符串的长度
4)字符串常用操作汇总
| 编号 | 操作 | 说明 |
| 1 | 字符串[下标] | 根据下标索引取出特定位置字符 |
| 2 | 字符串index(字符串) | 查找给定字符的第一个匹配项的下标 |
| 3 | 字符串.replace(字符串1,字符串2) | 将字符串内的全部字符串1,替换为字符串2 不会修改原字符串,而是得到一个新的 |
| 4 | 字符串.split(字符串) | 按照给定字符串,对字符串进行分隔不会修改原字符串,而是得到一个新的列表 |
| 5 | 字符串.strip() 字符串.strip(字符串) | 移除首尾的空格和换行符或指定字符串 |
| 6 | 字符串.count(字符串) | 统计字符串内某字符串的出现次数 |
| 7 | len(字符串) | 统计字符串的字符个熟 |
5)字符串的遍历:
同列表、元组一样,字符串也支持while循环和for循环进行遍历
6)字符串的特点:
作为数据容器,字符串有如下特点:
只可以存储字符串
长度任意 (取决于内存大小)
支持下标索引
允许重复字符串存在
不可以修改(增加或删除元素等)
支持for循环
7)练习案例:
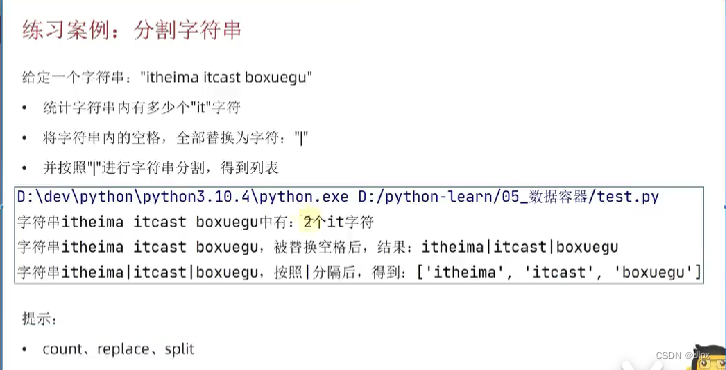
以上就是这次小小练习案例的代码
六、数据容器(序列)的切片
1)什么是序列?
序列是指:内容连续、有序,可使用下标索引的一类数据容器
列表、元组、字符串,均可以可以视为序列
2)序列的常用操作-切片
序列支持切片,即:列表、元组、字符串,均支持进行切片操作
切片: 从一个序列中,取出一个子序列
语法:序列[起始下标:结束下标:步长]
表示从席列中,从指定位置开始,依次取出元素,到指定位置结束,得到一个新序列:
起始下标表示从何处开始,可以留空,留空视作从头开始
结束下标(不含)表示何处结束,可以留空,留空视作截取到结尾
步长表示,依次取元素的间隔
步长1表示,一个个取元素
步长2表示,每次跳过1个元素取
步长N表示,每次跳过N-1个元素取
步长为负数表示,反向取(注意,起始下标和结束下标也要反向标记)
注意,此操作不会影响序列本身,而是会得到一个新的序列(列表、元组、字符串)
序列 [起始:结束:步长]
起始可以皆略,省骆从头开始结束可以省略,省略到尾结束
步长可以省略,省骆步长为1(可以为负数,表示倒序执行)
示例操作:
- # 对list进行切片, 从1开始,4结束,步长1
- my_list = [0, 1, 2, 3, 4, 5, 6]
- result1 = my_list[1:4] #步长默认为1,且取值为前开后闭
- print(f"结果1:{result1}")
-
- # 对tuple进行切片,从头开始,到最后结束,步长1
- my_tuple = (0, 1, 2, 3, 4, 5, 6)
- result2 = my_tuple[:] # 起始和结束不写表示从头到尾,步长为1可以省略
- print(f"结果2:{result2}")
-
- # str进行切片,从头开始,到最后结索,步长2
- my_str = "01234567"
- result3 = my_str[::2]
- print(f"结果3:{result3}")
-
- # 对str进行切片,从头开始,到最后结束,步长-1
- my_str = "01234567"
- result4 = my_str[::-1] # 等同于将序列反转了
- print(f"结果4:{result4}")
-
- # 对列表进行切片,从3开始,到1结束,步长-1
- my_list = [0, 1, 2, 3, 4, 5, 6]
- result5 = my_list[3:1:-1]
- print(f"结果5:{result5}")
-
- # 对元组进行访片,从头开龄,到尾结束,步长-2
- my_tuple = (0, 1, 2, 3, 4, 5, 6)
- result6 = my_tuple[::-2]
- print(f"结果6:{result6}")

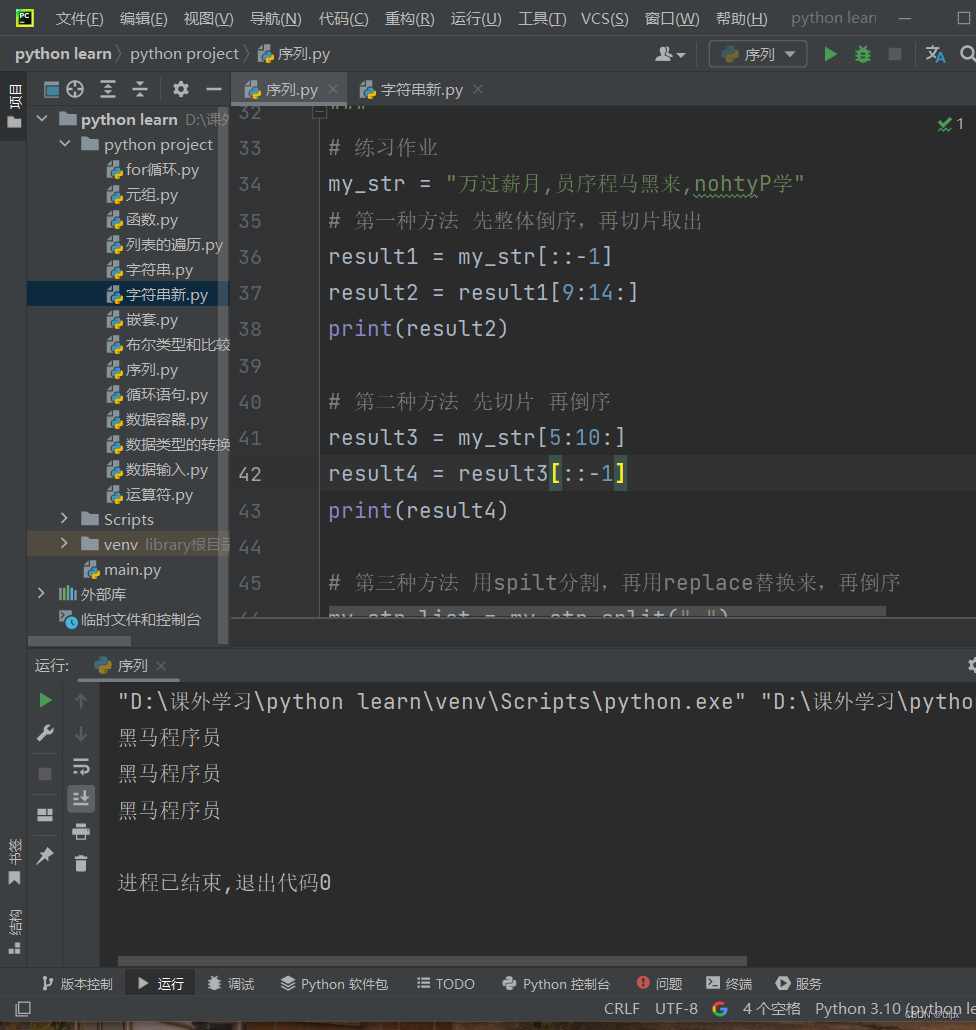
3)练习案例

- # 练习作业
- my_str = "万过薪月,员序程马黑来,nohtyP学"
- # 第一种方法 先整体倒序,再切片取出
- result1 = my_str[::-1]
- result2 = result1[9:14:]
- print(result2)
-
- # 第二种方法 先切片 再倒序
- result3 = my_str[5:10:]
- result4 = result3[::-1]
- print(result4)
-
- # 第三种方法 用spilt分割,再用replace替换来,再倒序
- my_str_list = my_str.split(",")
- new_my_str_list = str(my_str_list).replace("来", "")
- result5 = new_my_str_list[14:9:-1]
- print(result5)
运行效果:
想要选择哪一种方法都可以,只要自己用的顺手就好
最后一种方法的简洁写法:
七、数据容器: set(集合)
我们目前接触到了列表、元组、字符串三个数据容器了。基本满足大多数的使用场景。
为何又需要学习新的集合类型呢?
通过特性来分析:
列表可修改、支持重复元素且有序
元组、字符串不可修改、支持重复元素且有序
局限就在于:它们都支持重复元素
如果场景需要对内容做去重处理,列表、元组、字符串就不方便了。
1)集合的定义
- # 基础语法:
- # 定义集合字面量
- {元素,元素,......,元素}
- # 定义集合变量
- 变量名称 = {元素,元案,......,元素》
- # 定义空集合
- 变量名称 = set()
-
和列表、元组、字符串等定义基本相同:
列表使用:[] 有序、可重复、可被修改
元组使用:() 有序、可重复、不可被修改
字符串使用:" " 有序、可重复、可被修改
集合使用:{} 无序、不重复、可被修改
需要注意的是:
集合不支持重复的元素
并且集合是无序的
2)集合的常用操作 - 修改
首先,因为集合是无序的,所以集合不支持: 下标索引访问
但是集合和列表一样,是允许修改的,所以我们来看看集合的修改方法:
添加新元素
语法:集合.add(元素)。将指定元素,添加到集合内
结果:集合本身被修改,添加了新元素
示例:
移除元素
语法:集合.remove(元素),将指定元素,从集合内移除
结果:集合本身被修改,移除了元素
示例:
从集合中随机取出元素
语法:集合.pop(),功能,从集合中随机取出一个元素
结果:会得到一个元素的结果。同时集合本身被修改,元素被移除3
示例:
清空集合
下面注意:这个在学习之前的数据容器中都没有接触到噢:
取出2个集合的差集
语法:集合1.difference(集合2),功能: 取出集合1和集合2的差集(集合1有而集合2没有的)
结果:得到一个新集合,集合1和集合2不变
去异留同
消除2个集合的差集
语法:集合1.difference(集合2),功能: 取出集合1和集合2的差集(集合1有而集合2没有的)
结果:得到一个新集合,集合1和集合2不变
去同存异
2个集合合并
语法:集合1.union(集合2)
功能:将集合1和集合2组合成新集合
结果:得到新集合,集合1和集合2不变
统计集合元素数量
集合的遍历
集合不支持下标索引,不能用while循环
可以用for循环
3)集合常用功能总结
| 编号 | 操作 | 说明 |
| 1 | 集合,add(元素) | 集合内添加一个元素 |
| 2 | 集合.remove(元素) | 移除集合内指定的元素 |
| 3 | 集合.pop() | 从集合中随机取出一个元素 |
| 4 | 集合.clear0) | 将集合清空 |
| 5 | 集合1.difference(集合2) | 得到一个新集合,内含2个集合的差集原有的2个集合内容不变 |
| 6 | 集合1.difference update(集合2) | 在集合1中,删除集合2中存在的元素集合1被修改,集合2不变 |
| 7 | 集合1.union(集合2) | 得到1个新集合,内含2个集合的全部元素原有的2个集合内容不变 |
| 8 | len集合) | 得到一个整数,记录了集合的元素数量 |
4)集合的特点
可以容纳多个数据
可以容纳不同类型的数据 (混装 )
数据是无序存储的(不支持下标索引)
不允许重复数据存在
可以修改(增加或删除元素等 )
支持for循环
5)练习案例

- # 练习案例
- my_list = ['黑马程序员', '传智播客', '黑马程序员', '传智播客', 'itheima', 'itcast', 'itheima', 'itcast']
- # 定义一个空集合
- my_set = set()
- # 遍历列表
- for element in my_list:
- my_set.add(element)
-
- print(f"集合为:{my_set}")
八、数据容器: dict(字典、映射)
1)字典的定义
为什么要使用字典?



字典的定义,同样使用 {} ,不过存储的元素是一个个的: 键值对 如下语法:
2)字典的常用操作
字典数据的获取
字典同集合一样,不可以使用下标索引
但是字典可以通过Key值来取得对应的Value
字典的嵌套
字典的Key和Value可以是任意数据类型(Key不可为字典)
那么,就表明,字典是可以嵌套的
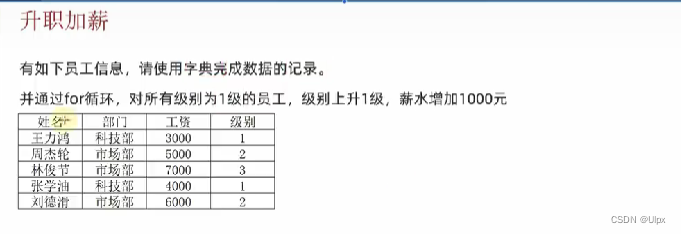
需求如下:记录学生各科的考试信息

- # 定义嵌套字典
- stu_score_dict = {
- "lxl": {
- "语文": 100,
- "数学": 100,
- "英语": 100
- }, "asd":{
- "语文": 90,
- "数学": 90,
- "英语": 90
- }, "sdf":{
- "语文": 80,
- "数学": 80,
- "英语": 80
- }
- }
- print(f"学生的考试信息是:{stu_score_dict}")
- # 从嵌套字典中获取数据
- chinese_score = stu_score_dict["asd"]["语文"]
- print(f"asd的语文成绩是:{chinese_score}")
新增元素
语法: 字典[Key]= Value,结果: 字典被修改,新增了元素
更新元素
语法:字典[Key]= Value,结果: 字典被修改,元素被更新
注意: 字典Key不可以重复,所以对已存在的Key执行上述操作,就是更新Value值
删除元素
清空元素
获取全部的key
遍历字典
3)字典的常用操作总结
| 编号 | 操作 | 说明 |
| 1 | 字典[Key] | 获取指定Key对应的Value值 |
| 2 | 字典[Key]=Value | 添加或更新键值对 |
| 3 | 宇典.pop(Key) | 取出Key对应的Value并在字典内删除此Key的键值对 |
| 4 | 字典.clear() | 清空字典 |
| 5 | 字典.keys() | 获取字典的全部Key,可用于for循环遍历字典 |
| 6 | len(字典) | 计算字典内的元素数量 |
4)字典的特点
经过上述对字典的学习,可以总结出字典有如下特点:
可以容纳多个数据
可以容纳不同类型的数据
每一份数据是KevValue键值对
可以通过Key获取到Value,Key不可重复 (重复会覆盖)
不支持下标索引
可以修改(增加或删除更新元素等)
支持for循环,不支持while循环
5)练习案例
# 个人觉得 两层循环更好理解一些
ok,以上就是今天学习的部分数据容器的知识啦
还有剩下一部分是关于所有数据容器的总结比较,今天先更新到这里咯
一起愉快的学习python吧lol


