
热门标签
热门文章
- 1NLP-信息抽取:概述【Information Extraction, 从纯文本中进行:①实体抽取与链指(命名实体识别)、②关系抽取、③事件抽取】_实体抽取和命名实体识别
- 2让人失望透顶的 CSDN 博客改版
- 3利用ROS做机器人手眼标定和Qt+rviz+图片话题显示的UI设计_ros手眼标定
- 4watermark java_GitHub - 272130525/BlindWatermark: Java 盲水印
- 5esp8266搭建智能家居系统_esp8266智能家居
- 6哲理故事三百篇(1-50)
- 7ubuntu20.04安装mongoDB
- 8python编程人工智能小例子,python人工智能有趣例子_python编程ai
- 9【Redis】哨兵
- 10鸿蒙入门11-DataPanel组件
当前位置: article > 正文
ElasticSearch-IK分词器介绍和下载_ik分词器下载
作者:Monodyee | 2024-04-20 05:52:39
赞
踩
ik分词器下载
IK分词器
什么是IK分词器?
分词:把一段中文或者别的划分成一个一个的关键字,我们在搜索的时候会把自己的信息进行分词,会把数据库中或者索引库中的数据进行分词,然后进行一个匹配操作,默认的中文分词是将每个字看成一个词,比如"我爱魏一鹤"会被分成"我",“爱”,“魏”,“一”,“鹤”,这显然是不符合要求的,索引我们需要安装中文分词器IK来解决这个问题
如果要使用中文,建议使用ik分词器
IK提供了两个分词算法,ik_smart和ik_max_world,其中ik_smart为最少切分,ik_max_wold为最细颗粒度划分,一会都会分别来测试
下载IK分词器
注意 ik版本要和es,kibana版本保持统一(7.6.1)
下载网址:https://github.com/medcl/elasticsearch-analysis-ik

找到7.6.1版本
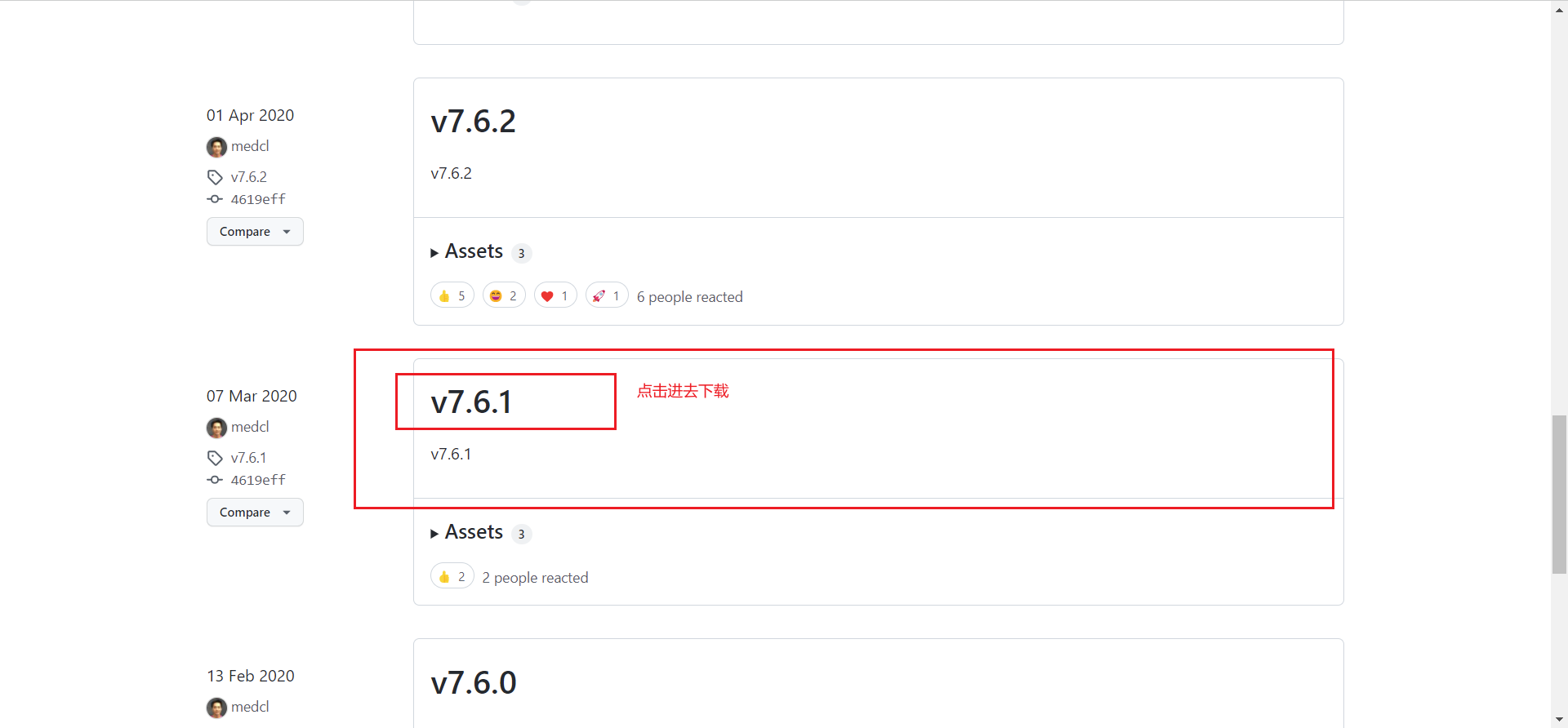
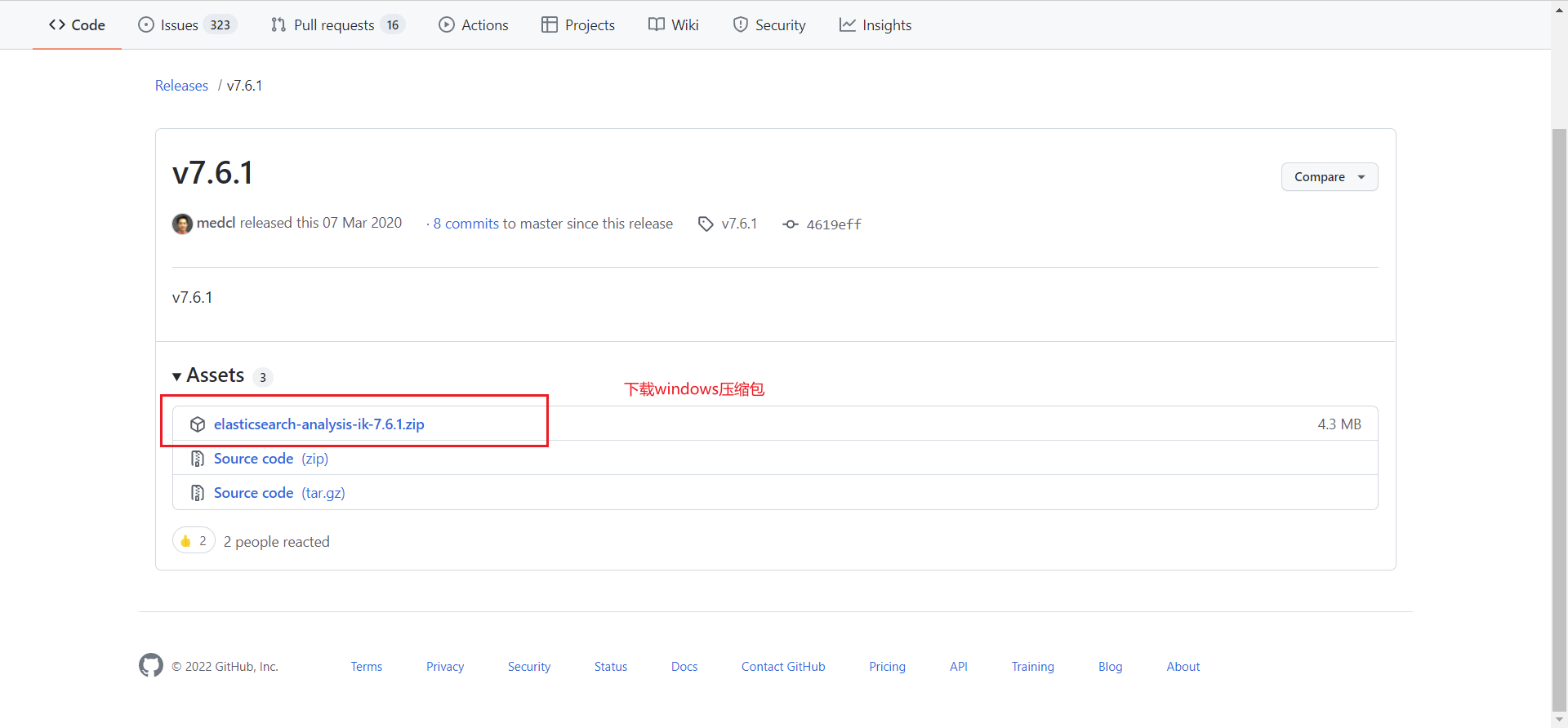
下载到本地,放入es插件中即可,这里我在es的plugins目录下创建一个IK目录
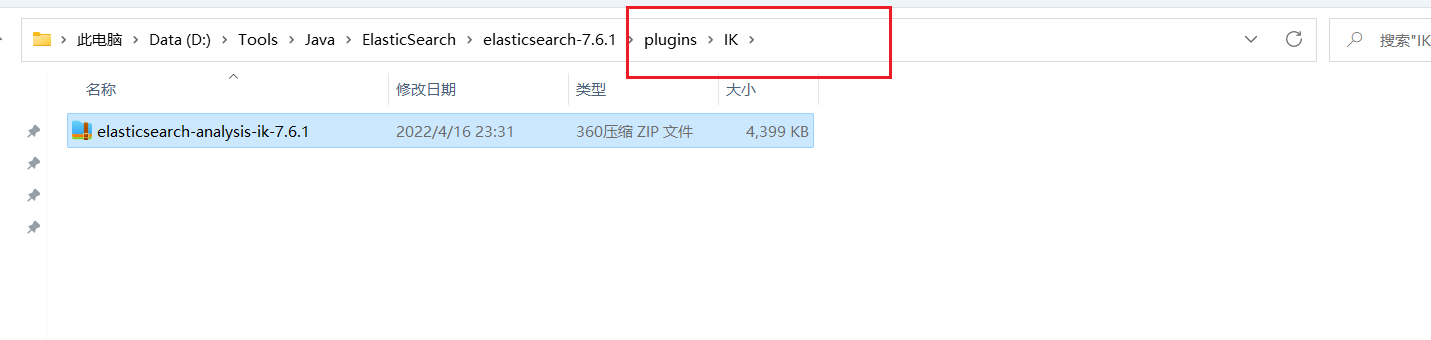
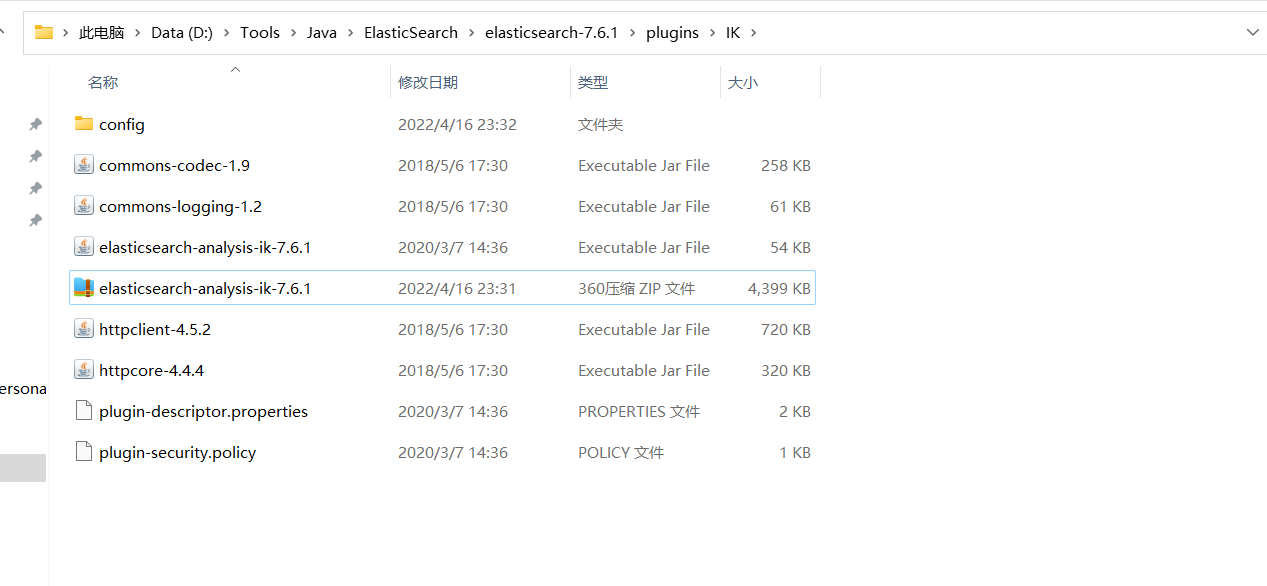
解压缩,目录如下
然后重启观察ES
注意:没有使用ik分词器插件的时候黑窗口会提示no plugins loaded(没有插件加载)
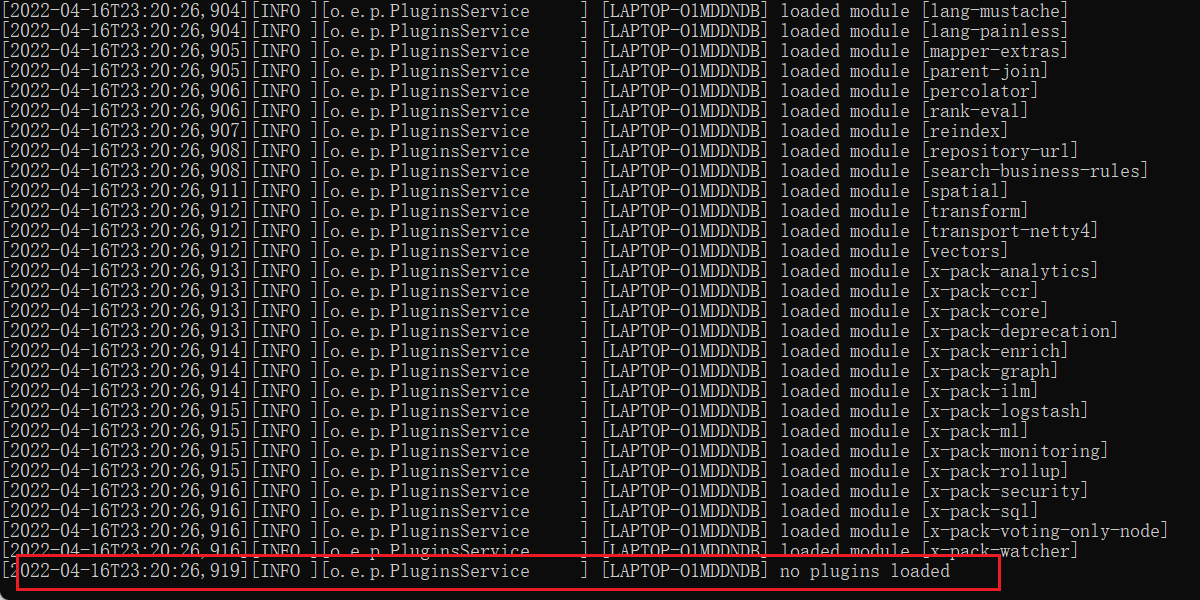
现在使用了ik分词器黑窗口也会提示ik分词器插件已经被加载

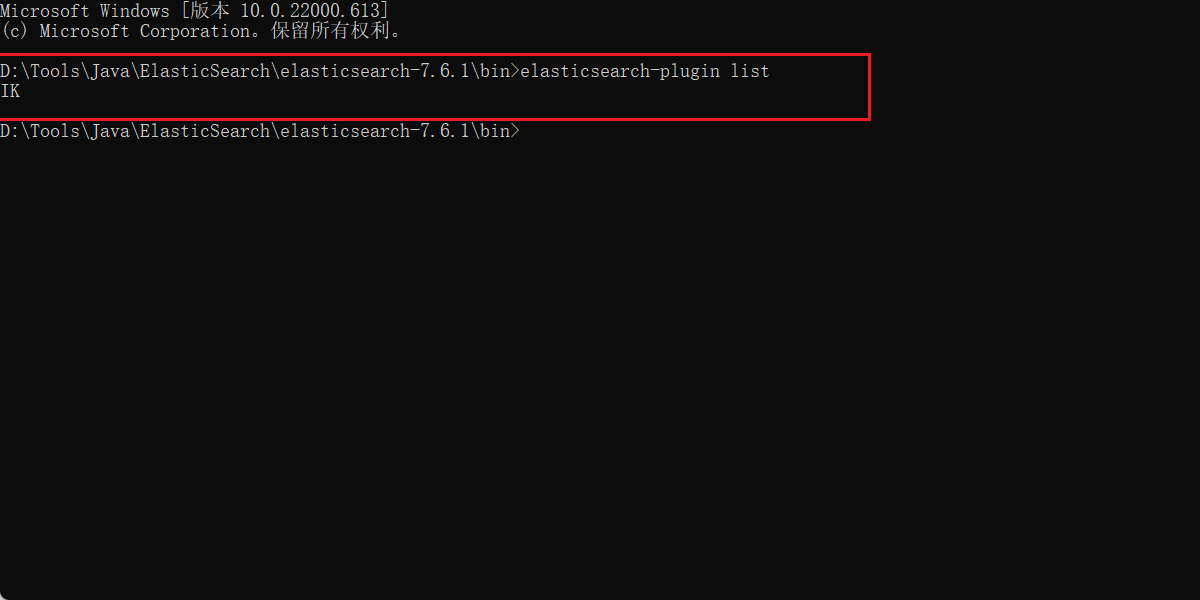
我们也可以使用命令(elasticsearch-plugin list)查看es下的全部加载的插件
elasticsearch-plugin list
推荐阅读
相关标签

