
- 1优达学城 UdaCity 纳米学位
- 2跨界创立PayPal、特斯拉、SpaceX……,埃隆·马斯克是这样“掌控”知识的
- 3数据库头歌实训(MYSQL):头歌数据库symql实训作业相关知识点
- 4头歌-机器学习 第2次实验 K-means聚类方法
- 5ESL第十一章 神经网络 投影追踪回归/岭函数/通用近似、径向基函数网络、随机近似/共轭梯度/变量度量、权重消去、信噪比计算、贝叶斯神经网络/贝叶斯推断/混合蒙特卡罗洛/哈密顿动力学/自动相关确定_投影追踪回归网络模型
- 6【网站项目】在线办公小程序
- 7【Unity3D】如何在uniyt中切换画布实现切换界面的交互操作_unity可交互界面
- 8有关Python爬虫,看这几本书绝对就够了!_python 爬虫书籍
- 9vue项目中封装的带拦截器的axios请求_vue index.js里面可以写axios拦截器吗
- 102021级新生个人训练赛第38场_洛洛在外出旅游的时候发现社会上文明的现象越来越多,人们在买票的时候都会自发地
Elasticsearch 的嵌套聚合和递归查询_elasticsearch嵌套查询
赞
踩
1.介绍
Elasticsearch是一个分布式搜索和分析引擎,可以用于处理大规模和复杂的数据集。在实际应用中,经常会遇到需要对多层嵌套文档进行聚合分析和递归查询的需求。本文将详细介绍如何在Elasticsearch中实现这两种功能,并给出相关代码示例和参数介绍。
2.Elasticsearch的数据模型和嵌套文档
在Elasticsearch中,数据以索引的形式存储,并可以被分片和复制以实现高可用和高性能。每个索引可以包含一个或多个文档类型,每个文档类型又可以包含一个或多个字段。字段可以是基本类型(如字符串、数字等),也可以是嵌套类型(即一个文档类型包含另一个文档类型)。
嵌套文档在数据模型中扮演着重要的角色,它可以用于表示层级结构的数据。例如,我们可以用一个父文档表示一个部门,子文档表示该部门下的员工。这样的数据模型使得在查询和聚合过程中能够更好地表示和分析数据。
3.嵌套聚合
嵌套聚合是指对嵌套文档中的字段进行聚合操作。在嵌套聚合中,我们需要指定聚合函数和聚合字段,并使用嵌套路径来告诉Elasticsearch应该在哪个嵌套文档中进行聚合。
嵌套聚合可以在多个层级上进行。例如,我们可以先对部门进行聚合,然后对每个部门下的员工进行聚合。这样的聚合过程可以通过Elasticsearch的嵌套聚合API来实现。
下面是一个示例代码,用于对嵌套文档进行两级聚合,统计每个部门的总工资和平均年龄:
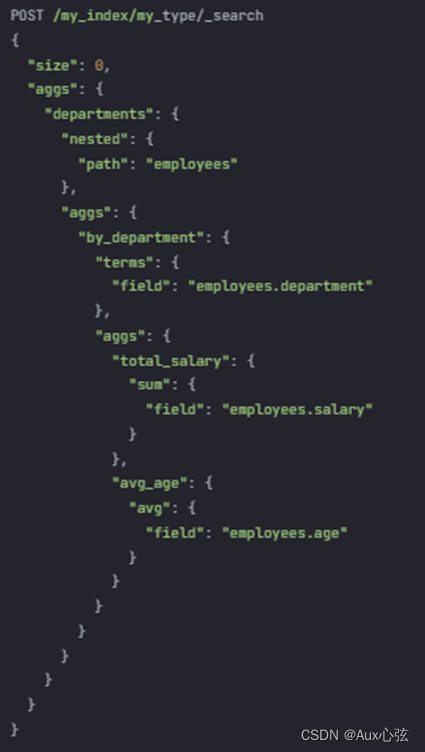
| POST /my_index/my_type/_search { "size": 0, "aggs": { "departments": { "nested": { "path": "employees" }, "aggs": { "by_department": { "terms": { "field": "employees.department" }, "aggs": { "total_salary": { "sum": { "field": "employees.salary" } }, "avg_age": { "avg": { "field": "employees.age" } } } } } } } } |
在上述代码中,首先使用nested参数指定了嵌套路径为employees,然后在by_department聚合中使用了terms参数指定了按部门字段进行分组,并在其内部定义了total_salary和avg_age两个子聚合。
4.递归查询
递归查询是指在嵌套文档中进行深度搜索。在递归查询中,我们需要指定查询条件,并使用嵌套路径来告诉Elasticsearch应该在哪个嵌套文档中进行搜索。
为了实现递归查询,Elasticsearch提供了has_child和has_parent两个查询API。has_child查询用于在父文档中搜索子文档,而has_parent查询用于在子文档中搜索父文档。这两个查询API可以结合使用,以实现在嵌套文档中进行递归搜索。
下面是一个示例代码,用于在嵌套文档中递归搜索名字包含"John"的员工:
| POST /my_index/my_type/_search { "query": { "has_child": { "type": "employee", "query": { "match": { "name": "John" } }, "inner_hits": {} } } } |
在上述代码中,使用了has_child查询来搜索名字包含"John"的员工。其中,type参数指定了子文档的类型为"employee",query参数指定了搜索条件为"name"字段包含"John",而inner_hits参数用于在搜索结果中返回匹配的子文档。
总结
本文介绍了Elasticsearch中的嵌套聚合和递归查询的原理和应用场景,并给出了相关的代码示例和参数介绍。嵌套聚合可用于对多层嵌套文档进行聚合分析,而递归查询可用于在嵌套文档中进行深度搜索。这两种功能可以帮助我们更好地理解和分析嵌套数据。在实际应用中,我们可以根据具体需求选择适合的聚合函数和查询条件,并使用相应的API来实现。

