
热门标签
热门文章
- 1后端开发有哪几种语言? - 易智编译EaseEditing_优采平台产品的后端开发语言是哪种
- 2毕业一年后,他转行软件测试成功拿到9.5K薪资,直言互联网行业真香_年后返岗学软件拿高薪
- 3Java基础知识解析:从入门到精通_java从入门到精通
- 4Navicat 连接虚拟机MySQL_navicat连接vmware上的mysql
- 5Home Assistant集成外部MQTT服务_configuration.yaml 找不到 mqtt
- 6AI绘画免费软件哪个好?宝藏AI绘画工具分享
- 7spark运行报错
- 8红蓝攻防基础-认识红蓝紫,初步学习网络安全属于那个队?
- 962、服务攻防——框架安全&CVE复现&Spring&Struts&Laravel&Thinkphp
- 10linux常用命令vim
当前位置: article > 正文
[HanLP]SpringBoot2.3整合HanLP1.7.7_hanlp 地址提取
作者:Monodyee | 2024-04-21 16:26:55
赞
踩
hanlp 地址提取
一、需求场景
提取地址字符串中的 区、街乡镇、村的字段,使用获取到的字段向经信局发起请求获取经纬度和点位名称,保存至数据库。
二、使用技术
HanLP+SpringBoot
三、设计思路

流程图下载:https://download.csdn.net/download/qq_36254699/13119828
四、具体实现
- pom引入jar
<dependency>
<groupId>com.hankcs</groupId>
<artifactId>hanlp</artifactId>
<version>1.7.7</version>
</dependency>
<dependency>
<groupId>com.hankcs</groupId>
<artifactId>hanlp-sources</artifactId>
<version>1.7.7</version>
</dependency>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 自定义词典,设置自定义词典中的词属性为na:
#自定义词典路径,用;隔开多个自定义词典,空格开头表示在同一个目录,使用“文件名 词性”形式则表示这个词典的词性默认是该词性。优先级递减。
#所有词典统一使用UTF-8编码,每一行代表一个单词,格式遵从[单词] [词性A] [A的频次] [词性B] [B的频次] ... 如果不填词性则表示采用词典的默认词性。
CustomDictionaryPath=data/dictionary/custom/add_place.txt na; non-place.txt n;
- 1
- 2
- 3
- 获取属性为na的字符串,拼接到一起实现利用自定义词典进行分词:
/** * 获取ns nt类型字符串,一旦遇到非规定类型直接结束 * ns 地名 * nt 机构团体名 */ public static String[] getNaStr(String address) { List<Term> termList = StandardTokenizer.segment(address); String word = ""; String hasNa = "false"; for (Term term : termList) { if ("na".equals(term.nature.toString())) { if (word.length() <= term.word.length()) { word = term.word; hasNa = "true"; } } } // 结果第一个是是否找到na属性字符串,第二个是最长的na字符串 return new String[]{hasNa, word}; }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
五、效果
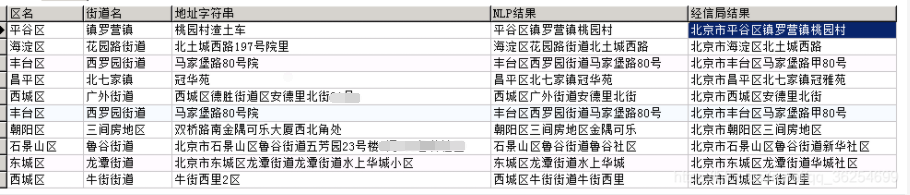
六、问题总结
本文内容由网友自发贡献,转载请注明出处:https://www.wpsshop.cn/w/Monodyee/article/detail/463970
推荐阅读
相关标签

