
- 1STM32 基础学习——GPIO位结构(江科大老师教程)_江科大stm32教程
- 2数据库入门下篇(如何安装和登录MYSQL数据库)
- 3java毕业设计基于微信小程序和协同过滤推荐算法的校园二手交易平台
- 4网络安全的守护者:防火墙的五个主要功能解析
- 5Android 外部SD卡/U盘无法写入解决方法(需要root)_安卓11如何root后你能写u盘目录吗
- 6量子计算器的硬件发展_量子计算 硬件
- 7API请求报错 Required request body is missing_required request body is missing: public com.jhict
- 8英文文本情感分析textblob模块sentiment方法
- 9Xcode15报错:SDK does not contain ‘libarclite‘ at the path ‘/Applications/Xcode.app/Contents/Developer_sdk does not contain 'libarclite' at the path '/ap
- 10GitHub的2FA验证问题解决工具_github双重认证点不了确定
LLaVA-1.6:多模态AI新标准,中文零样本能力与低成本训练革命,性能全面超越Gemini Pro_llava-1.6测评方法
赞
踩
引言
2023年10月,LLaVA-1.5凭借其简洁高效的设计和在12个数据集上的出色表现,为大规模多模态模型(LMM)的研究和应用奠定了基础。进入2024年,我们迎来了LLaVA-1.6,一个在理性推理、光学字符识别(OCR)和世界知识方面均有显著改进的版本,甚至在多个评测中超越了业界领先的Gemini Pro。
-
Huggingface模型下载:https://huggingface.co/collections/liuhaotian/llava-16-65b9e40155f60fd046a5ccf2
-
AI快站模型免费加速下载:https://aifasthub.com/models/liuhaotian
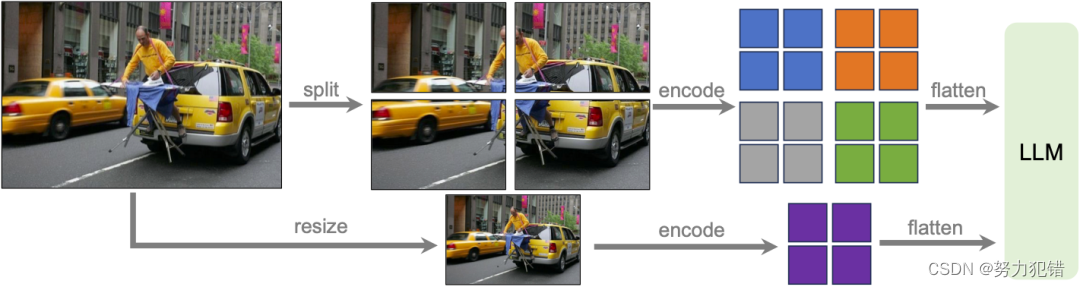
技术创新
-
动态高分辨率技术
LLaVA-1.6将输入图像的分辨率提高了4倍,支持三种长宽比,最高可达672x672分辨率。这一改进使得LLaVA-1.6能够捕捉到更多的视觉细节,从而提升了视觉推理和OCR的能力。
-
数据混合改进
通过改善视觉指令调优数据的混合方式,LLaVA-1.6在不同的应用场景中实现了更好的视觉对话能力。这一点体现在模型能够覆盖更广泛的应用,提供更丰富的世界知识和逻辑推理。
-
高效部署与推理
借助SGLang技术,LLaVA-1.6实现了高效的部署和推理能力,同时保持了LLaVA-1.5的简约设计和数据效率。
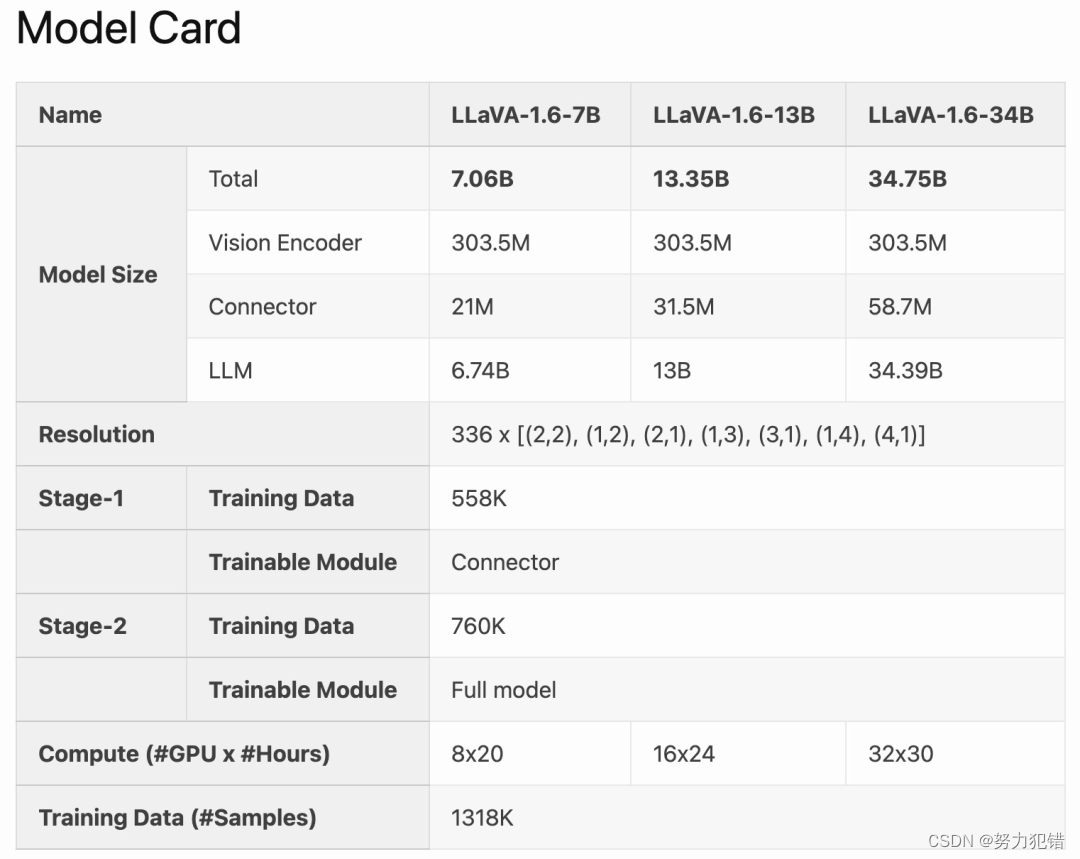
性能表现
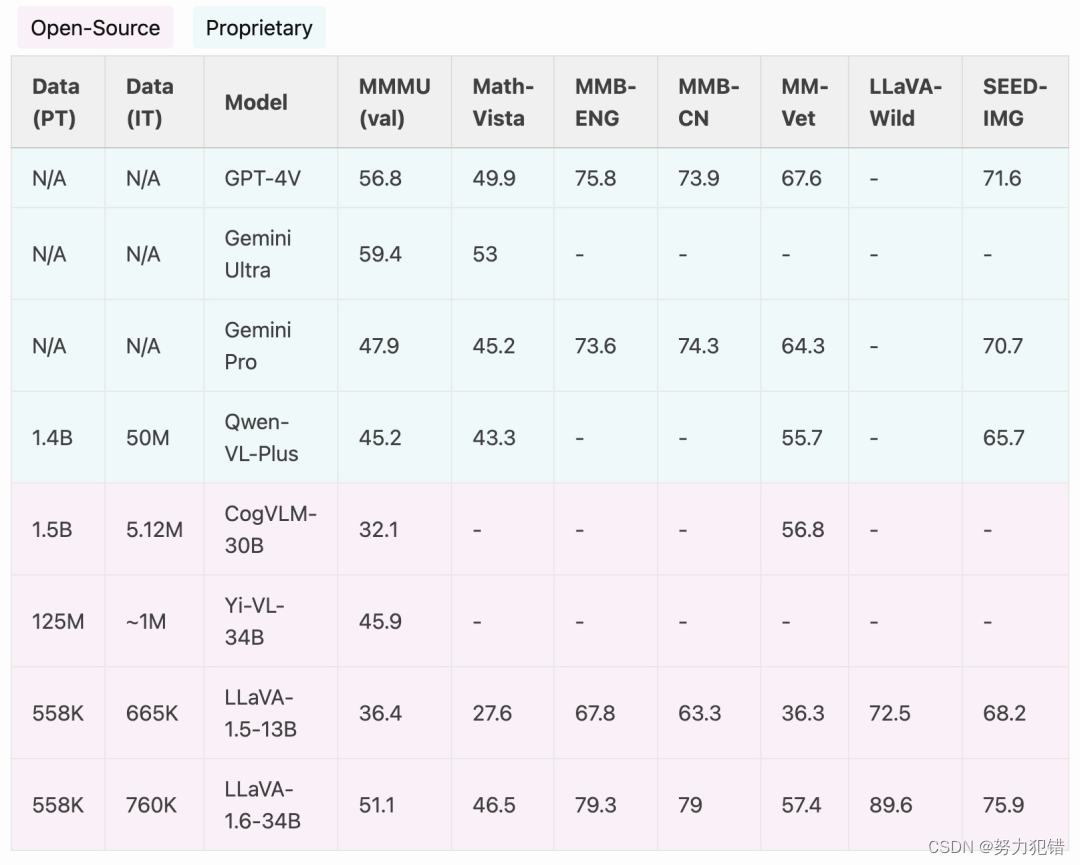
在与前一版本LLaVA-1.5相比,LLaVA-1.6不仅在视觉细节捕捉、OCR能力和视觉对话方面取得了显著进步,还在多项国际评测中表现优异,全面超越了Gemini Pro等商业模型。特别值得一提的是,LLaVA-1.6展现了出色的中文零样本能力,即使用仅考虑英文多模态数据的模型,在中文多模态场景下也能取得领先的性能。
开源与社区贡献
为了促进LMM在社区的未来发展,LLaVA-1.6的代码、数据和模型将全部开源。这一举措旨在降低研究和开发的门槛,推动多模态AI技术的创新和应用。
结论
LLaVA-1.6的推出,不仅设定了多模态AI的新标准,其在中文零样本能力展现和低成本训练方面的革命性进步,更是对AI领域的重大贡献。随着技术的不断演进,期待LLaVA系列模型能够在推动AI技术发展和应用方面继续发挥其重要作用。
模型下载
Huggingface模型下载
https://huggingface.co/collections/liuhaotian/llava-16-65b9e40155f60fd046a5ccf2
AI快站模型免费加速下载
https://aifasthub.com/models/liuhaotian

