- 1【SD插件】轻松一键修复脸部变形-After Detailer_sd 生成图 人脸不全
- 2【node:19212】 解决 Node.js 报错 “将文件视为 CommonJS 模块“
- 3十九、FPGrowth算法介绍_fpgrowth排序
- 4Git - 在PyCharm/Idea中集成使用Git
- 5PX4位置控制offboard模式说明_px4offboard
- 6Flink动态更新维表_lookup.partial-cache.expire-after-write
- 7Verilog 不可综合部分
- 8论文解读《Text Compression-aided Transformer Encoding》_隐式文本
- 9PMP重考流程与费用_pmp重考费用是多少
- 10Window 安装Hive_请截图显示hive的安装结果
RDD编程初级实践_.大学计算机系的成绩分析。已知“数据集”chapter4-data1.txt,该数据集包含了某大
赞
踩
1.pyspark交互式编程
请到教材官网的“下载专区”的“数据集”中下载chapter4-data1.txt,该数据集包含了某大学计算机系的成绩,数据格式如下所示:
| Tom,DataBase,80 Tom,Algorithm,50 Tom,DataStructure,60 Jim,DataBase,90 Jim,Algorithm,60 Jim,DataStructure,80 …… |
请根据给定的实验数据,在pyspark中通过编程来计算以下内容:
(1)该系总共有多少学生;
(2)该系共开设了多少门课程;
(3)Tom同学的总成绩平均分是多少;
(4)求每名同学的选修的课程门数;
(5)该系DataBase课程共有多少人选修;
(6)各门课程的平均分是多少;
(7)使用累加器计算共有多少人选了DataBase这门课。
2.编写独立应用程序实现数据去重
对于两个输入文件A和B,编写Spark独立应用程序,对两个文件进行合并,并剔除其中重复的内容,得到一个新文件C。下面是输入文件和输出文件的一个样例,供参考。
输入文件A的样例如下:
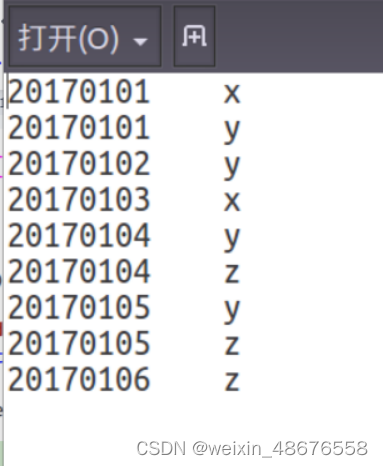
20170101 x
20170102 y
20170103 x
20170104 y
20170105 z
20170106 z
输入文件B的样例如下:
20170101 y
20170102 y
20170103 x
20170104 z
20170105 y
根据输入的文件A和B合并得到的输出文件C的样例如下:
20170101 x
20170101 y
20170102 y
20170103 x
20170104 y
20170104 z
20170105 y
20170105 z
20170106 z
3.编写独立应用程序实现求平均值问题
每个输入文件表示班级学生某个学科的成绩,每行内容由两个字段组成,第一个是学生名字,第二个是学生的成绩;编写Spark独立应用程序求出所有学生的平均成绩,并输出到一个新文件中。下面是输入文件和输出文件的一个样例,供参考。
Algorithm成绩:
小明 92
小红 87
小新 82
小丽 90
Database成绩:
小明 95
小红 81
小新 89
小丽 85
Python成绩:
小明 82
小红 83
小新 94
小丽 91
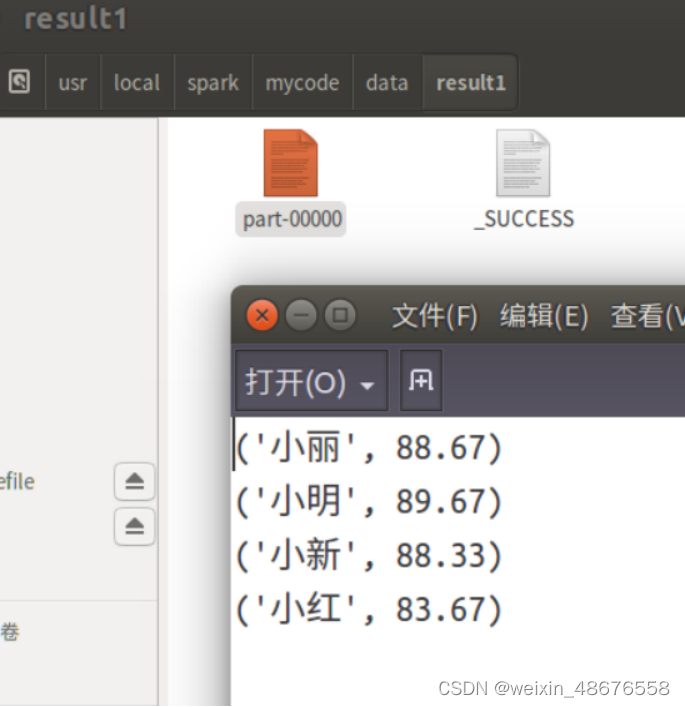
平均成绩如下:
(小红,83.67)
(小新,88.33)
(小明,89.67)
(小丽,88.67)
- 实验结果与分析
- pyspark交互式编程
0.先启动pyspark
(1)该系总共有多少学生;

总共265名学生
(2)该系共开设了多少门课程;
取出第二列课程数据,进行去重操作

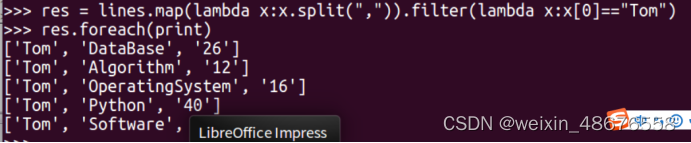
(3)Tom同学的总成绩平均分是多少;
先取出tom同学的成绩
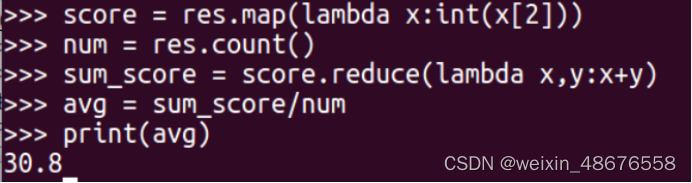
再取出成绩列,统计课程数量,再对分数用reduce函数求和,最后求出平均分。
(4)求每名同学的选修的课程门数;
取出每位同学的名字并且通过map函数形成键值对形式,键为名字,值为1.
再用reducebykey函数应用于键值对数据,得到聚合的结果。
(5)该系DataBase课程共有多少人选修;
直接用filter函数将数据库课程过滤出

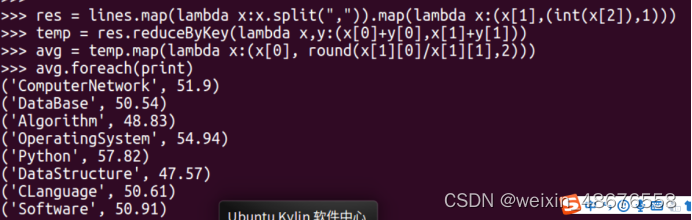
(6)各门课程的平均分是多少;
为每门课程的分数后面新增一列1,表示1个学生选择了该课程。
格式如('ComputerNetwork', (44, 1))
再按课程名聚合课程总分和选课人数。格式如('ComputerNetwork', (7370, 142))
最后:课程总分/选课人数 = 平均分,并利用round(x,2)保留两位小数
2.编写独立应用程序实现数据去重
实现两个文件合并并且去重:
在mycode/data目录下创建两个txt文件
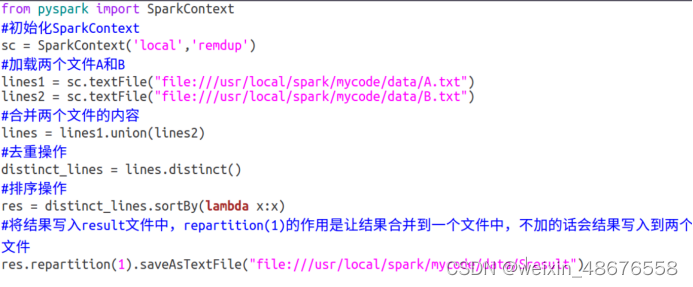
在当前目录下创建py文件,填写如下内容实现两个文件的合并去重
在当前目录下运行

结果如下:
3.编写独立应用程序实现求平均值问题
多个文件合并实现求平均值:
在data目录下创建三个成绩的文件
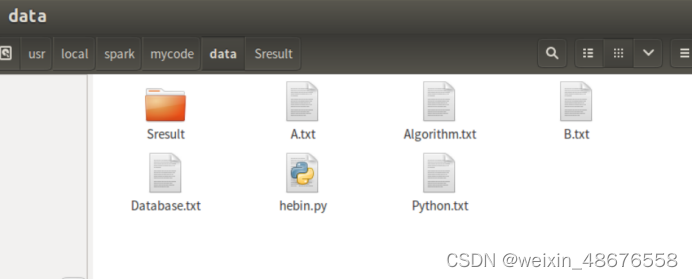
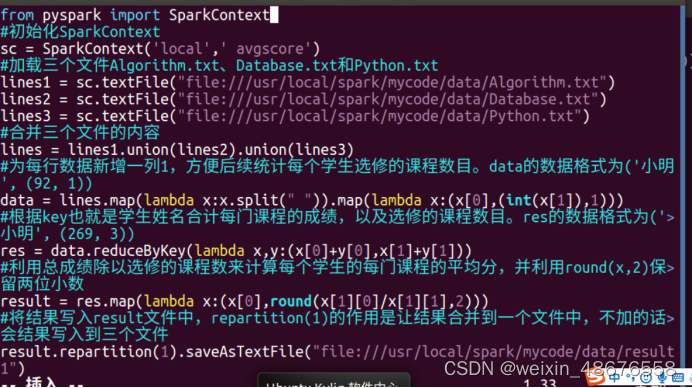
在data目录下创建mean.py文件,并添加如下代码:
运行
成功