
热门标签
热门文章
- 1VLSI Basic3——time borrowing_time borrowing information
- 2c++ STL vector容器的元素拷贝_拷贝一个vector的一段
- 3数据结构之最短路径_数据结构最短路径
- 4【MATLAB 分类算法教程】_3麻雀搜索算法优化支持向量机SVM分类 - 教程和对应MATLAB代码
- 5Idea中Git的使用和两种类型的冲突解决_git merge 冲突之后文件变红
- 6什么是扩散模型(Diffusion Models),为什么它们是图像生成的一大进步?
- 7hive一次查询多个分区表_《Hive用户指南》- Hive性能调优相关
- 8用C#操作Mongodb(c#mongodb驱动)_.net mongodb.driver.dll
- 9angular中的路由详解(3)—通过module和子路由来访问组件_routing.moudle
- 10css iphone安全底部_css 安全距离
当前位置: article > 正文
Hadoop 3.2.2 安装与使用文档超详细图文步骤
作者:Monodyee | 2024-04-23 11:03:23
赞
踩
hadoop
1、简介
1.1、概述
Hadoop是一个开源框架,允许使用简单的编程模型在跨计算机集群的分布式环境中存储和处理大数据。它的设计是从单个服务器扩展到数千个机器,每个都提供本地计算和存储。
1.2、官网
2、准备工作
2.1、修改主机名称
# 修改主机名称
hostnamectl set-hostname master
- 1
- 2
2.2、配置主机名跟 IP 地址映射
# 所有机器都需编辑 hosts 文件
vi /etc/hosts
# 添加如下内容
192.168.1.2 master
- 1
- 2
- 3
- 4
- 5
2.3、安装 JDK 8
3、Hadoop 下载


4、Hadoop 安装
4.1、创建 hadoop 相关目录
# 创建 hadoop 应用目录
mkdir -p /home/app/hadoop
# 创建 hadoop dfs 数据目录
mkdir -p /home/app/hadoop/data/dfs/data
# 创建 hadoop dfs 名称目录
mkdir -p /home/app/hadoop/data/dfs/name
# 创建 hadoop 临时数据目录
mkdir -p /home/app/hadoop/data/temp
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
4.2、解压 hadoop 软件包
# 访问 hadoop 应用目录
cd /home/app/hadoop
# 解压 hadoop 软件压缩包
tar -zxvf hadoop-3.2.2.tar.gz
- 1
- 2
- 3
- 4
- 5
4.3、配置环境变量
#配置当前用户环境变量
vi ~/.bash_profile
#在文件中添加如下命令,记得切换自己文件路径
export HADOOP_HOME=/home/app/hadoop/hadoop-3.2.2
export PATH=$HADOOP_HOME/bin:$PATH
#立即生效
source ~/.bash_profile
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
4.4、hadoop 配置
# 访问 hadoop 配置文件目录
cd $HADOOP_HOME/etc/hadoop
- 1
- 2
4.4.1、hadoop-env.sh
# 编辑 hadoop-env.sh
vi hadoop-env.sh
# 设置 java 环境变量
export JAVA_HOME=/usr/lib/jvm/jre-1.8.0-openjdk-1.8.0.292.b10-1.el7_9.x86_64
- 1
- 2
- 3
- 4
- 5

4.4.2、core-site.xml
# 编辑 core-site.xml
vi core-site.xml
# 在文件中添加如下命令
<configuration>
<!-- 指定HDFS中NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:6001</value>
</property>
<!-- 指定hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/app/hadoop/data/temp</value>
</property>
</configuration>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17

4.4.3、hdfs-site.xml
# 编辑 hdfs-site.xml
vi hdfs-site.xml
# 在文件中添加如下命令
<configuration>
<!-- 设置dfs副本数 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<!-- hdfs的web管理页面的端口 -->
<property>
<name>dfs.http.address</name>
<value>0.0.0.0:50070</value>
</property>
<!-- 设置secondname的端口 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:6002</value>
</property>
<!-- name目录 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/app/hadoop/data/dfs/name</value>
</property>
<!-- data目录 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/app/hadoop/data/dfs/data</value>
</property>
</configuration>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31

4.4.4、mapred-site.xml
# 编辑mapred-site.xml
vi mapred-site.xml
# 在文件中添加如下命令
<configuration>
<!-- 指定mr运行在yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11

4.4.5、yarn-site.xml
# 编辑 yarn-site.xml
vi yarn-site.xml
# 在文件中添加如下命令
<configuration>
<!-- reducer 获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定 YARN 的 ResourceManager 的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<!-- 该节点上YARN可使用的物理内存总量,默认是 8192(MB)-->
<!-- 注意,如果你的节点内存资源不够8GB,则需要调减小这个值 -->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>6144</value>
</property>
<!-- 单个任务可申请最少内存,默认 1024 MB -->
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>1024</value>
</property>
<!-- 单个任务可申请最大内存,默认 8192 MB -->
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>6144</value>
</property>
</configuration>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36

4.4.6、slaves
# 编辑slaves
vi slaves
# 在文件中添加如下
192.168.1.217
- 1
- 2
- 3
- 4
- 5
5、Hadoop 启动
5.1、启动需要格式化(注意:只有第一次需要)
# hadoop 格式化
hadoop namenode -format
- 1
- 2
5.2、启动 & 停止 hdfs
# 启动 hdfs
$HADOOP_HOME/sbin/start-dfs.sh
# 停止 hdfs
$HADOOP_HOME/sbin/stop-dfs.sh
- 1
- 2
- 3
- 4
- 5
5.2.1、异常情况一
Starting namenodes on [master]
ERROR: Attempting to operate on hdfs namenode as root
ERROR: but there is no HDFS_NAMENODE_USER defined. Aborting operation.
Starting datanodes
ERROR: Attempting to operate on hdfs datanode as root
ERROR: but there is no HDFS_DATANODE_USER defined. Aborting operation.
Starting secondary namenodes [master]
ERROR: Attempting to operate on hdfs secondarynamenode as root
ERROR: but there is no HDFS_SECONDARYNAMENODE_USER defined. Aborting operation.
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
解决方案
# 在 start-dfs.sh 和 stop-dfs.sh 两个文件顶部添加以下参数
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
- 1
- 2
- 3
- 4
- 5
- 6
5.2.2、异常情况二
WARNING: HADOOP_SECURE_DN_USER has been replaced by HDFS_DATANODE_SECURE_USER. Using value of HADOOP_SECURE_DN_USER.
Starting namenodes on [master]
Last login: Mon Sep 6 11:22:25 CST 2021 from 27.18.3.195 on pts/1
master: Warning: Permanently added 'master,172.17.200.78' (ECDSA) to the list of known hosts.
master: root@master: Permission denied (publickey,gssapi-keyex,gssapi-with-mic,password).
Starting datanodes
Last login: Mon Sep 6 11:33:07 CST 2021 on pts/1
localhost: Warning: Permanently added 'localhost' (ECDSA) to the list of known hosts.
localhost: root@localhost: Permission denied (publickey,gssapi-keyex,gssapi-with-mic,password).
Starting secondary namenodes [master]
Last login: Mon Sep 6 11:33:07 CST 2021 on pts/1
master: root@master: Permission denied (publickey,gssapi-keyex,gssapi-with-mic,password).
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
解决方案
设置 SSH 免密码登录
# 生成秘钥,无需指定口令密码,直接回车
ssh-keygen -t rsa
# 将公钥导入到认证文件
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
- 1
- 2
- 3
- 4
- 5
5.3、启动 & 停止 yarn
# 启动 yarn
$HADOOP_HOME/sbin/start-yarn.sh
# 停止yarn
$HADOOP_HOME/sbin/stop-yarn.sh
- 1
- 2
- 3
- 4
- 5
yarn 启动异常
Starting resourcemanager
ERROR: Attempting to operate on yarn resourcemanager as root
ERROR: but there is no YARN_RESOURCEMANAGER_USER defined. Aborting operation.
Starting nodemanagers
ERROR: Attempting to operate on yarn nodemanager as root
ERROR: but there is no YARN_NODEMANAGER_USER defined. Aborting operation.
- 1
- 2
- 3
- 4
- 5
- 6
解决方案
# 在 start-yarn.sh 和 stop-yarn.sh 两个文件顶部添加以下参数
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
- 1
- 2
- 3
- 4
- 5
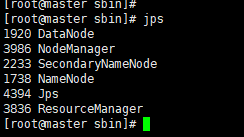
5.4、查看 hadoop 进程
# 查看 hadoop 进程
jps
- 1
- 2
6、Hadoop 访问
6.1、hdfs 平台
# 访问地址
http://IP:50070
- 1
- 2


6.2、yarn平台
# 访问地址
http://IP:8088
- 1
- 2

7、部署成功,开始体验吧 ~
推荐阅读
相关标签

