
- 1数据库干货 | 防止重复记录的发生_navicat 统计数据自动重计
- 2中小企业数字化转型痛点及解决方案_中小企业数智化转型痛点
- 3STM32--人体红外感应开关_基于stm32热释电红外传感器
- 4ScrollView无限循环阻尼居中(带缩放)
- 5git如何修改某次历史提交的commit信息和代码_git重新提交某次commit
- 6arXiv学术速递笔记12.8_receding horizon re-ordering of multi-agent execut
- 7实验问题记录-linux下不同python版本的flask相关的 flask_app设置问题_做flask项目,各版本对应
- 8“新KG”视点 | 任飞亮——大模型与知识图谱研究中的若干问题思考
- 9SpringBlade error/list SQL 注入漏洞
- 10MacOS M2:配置Tensorflow-GPU版_fast-whisper在m2上使用gpu运行
分割一切"3D高斯"来了!上交&华为提出SAGA:几毫秒完成3D分割一切!
赞
踩
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
扫码加入CVer知识星球,可以最快学习到最新顶会顶刊上的论文idea和CV从入门到精通资料,以及最前沿项目和应用!发论文,强烈推荐!

在CVer微信公众号后台回复:SAGA,即可下载论文pdf和代码链接!快学起来!
转载自:机器之心 | 编辑:杜伟、蛋酱
有了上海交大和华为提出的 SAGA,辐射场中的交互式 3D 分割任务实现起来会更快、效果更好。
今年 4 月,Meta 发布「分割一切(SAM)」AI 模型,这项成果不仅成为很多 CV 研究者心中的年度论文,更是在 ICCV 2023 上斩获最佳论文提名 。
「分割一切」实现了 2D 分割的「既能」和「又能」,可以轻松地执行交互式分割和自动分割,且能泛化到任意新任务和新领域。
现在,这种思路也延展到了 3D 分割领域。
辐射场中的交互式 3D 分割一直是个备受关注的课题,在场景操作、自动标注和 VR 等多个领域均有潜在应用价值。以往的方法主要是通过训练特征场来模仿自监督视觉模型提取的多视角 2D 特征,从而将 2D 视觉特征提升到 3D 空间,然后利用 3D 特征的相似性来衡量两个点是否属于同一个物体。
这种方法由于分割管道简单,因此速度很快,但代价是分割粒度较粗,因为它们缺乏解析嵌入特征信息的机制(如分割解码器)。
与此相反,另一种范式是将多视角细粒度 2D 分割结果直接投影到 3D 掩 ma 网格上,从而将 2D 分割基础模型提升到 3D。虽然这种方法可以获得精确的分割结果,但由于需要多次运行基础模型和体渲染,大量的时间开销限制了交互体验。特别是对于需要分割多个对象的复杂场景,这种计算成本变得难以承受。
近期,3D Gaussian Splatting(3DGS)因其高质量和实时渲染的能力,为辐射场交互式 3D 分割带来了新的突破。它采用一组 3D 彩色高斯来表示 3D 场景,高斯的平均值表示它们在 3D 空间中的位置,因此 3DGS 可以看作是一种点云,它有助于绕过对空旷 3D 空间的大量处理,并提供丰富的显式 3D 先验。有了这种类似于点云的结构,3DGS 不仅能实现高效的渲染,还能成为分割任务的理想候选对象。
受到这种方法的启发,在最近的一篇论文中,来自上海交大和华为的研究者在 3DGS 的基础上提出了将 2D 的「分割一切」模型的细粒度分割能力提炼到 3D 高斯中。

论文:https://arxiv.org/pdf/2312.00860
这一策略有别于以往将 2D 视觉特征提升到 3D 的方法,实现了精细的 3D 分割。此外,它还避免了推理过程中耗时的 2D 分割模型的多次 forward。这种蒸馏是通过使用 Segment Anything Model(SAM)根据自动提取的掩码训练高斯 3D 特征来实现的。在推理过程中,通过输入提示生成一组查询,然后通过高效的特征匹配检索预期的高斯。
研究者将这种方法命名为 Segment Any 3D GAussians (SAGA),可在几毫秒内实现精细的三维分割,并支持各种提示,包括点、涂鸦和掩码。对现有基准的评估表明,SAGA 的分割质量与之前的 SOTA 水平相当。

作为在 3D 高斯中进行交互式分割的首次尝试,SAGA 具有多功能性,可适应各种提示类型,包括掩码、点和涂鸦。值得注意的是,高斯特征的训练通常只需 5-10 分钟即可完成。随后,大多数目标对象的分割可在几毫秒内完成,实现了近 1000 倍的加速。

方法概览
下图 2 为 SAGA 的整体 pipeline。给定预训练的 3DGS 模型及其训练集,研究者首先使用 SAM 编码器来提取一个 2D 特征图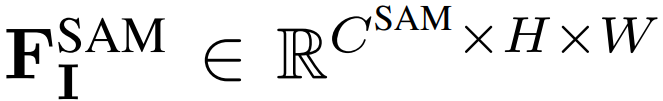 ,以及 I 中每个图像 I ∈ R^H×W 的一组多粒度掩码 M^SAM_I。接着基于提取的掩码来训练一个低维特征 f_g ∈ R^C,以聚合交叉视图一致的多粒度分割信息(其中 C 表示特征维度,默认值设置为了 32)。这些通过精心设计的 SAM 引导损失来实现。
,以及 I 中每个图像 I ∈ R^H×W 的一组多粒度掩码 M^SAM_I。接着基于提取的掩码来训练一个低维特征 f_g ∈ R^C,以聚合交叉视图一致的多粒度分割信息(其中 C 表示特征维度,默认值设置为了 32)。这些通过精心设计的 SAM 引导损失来实现。
为了进一步增强特征紧凑性,研究者从提取的掩码中导出点对应关系,并将它们提炼为特征(即对应损失)。
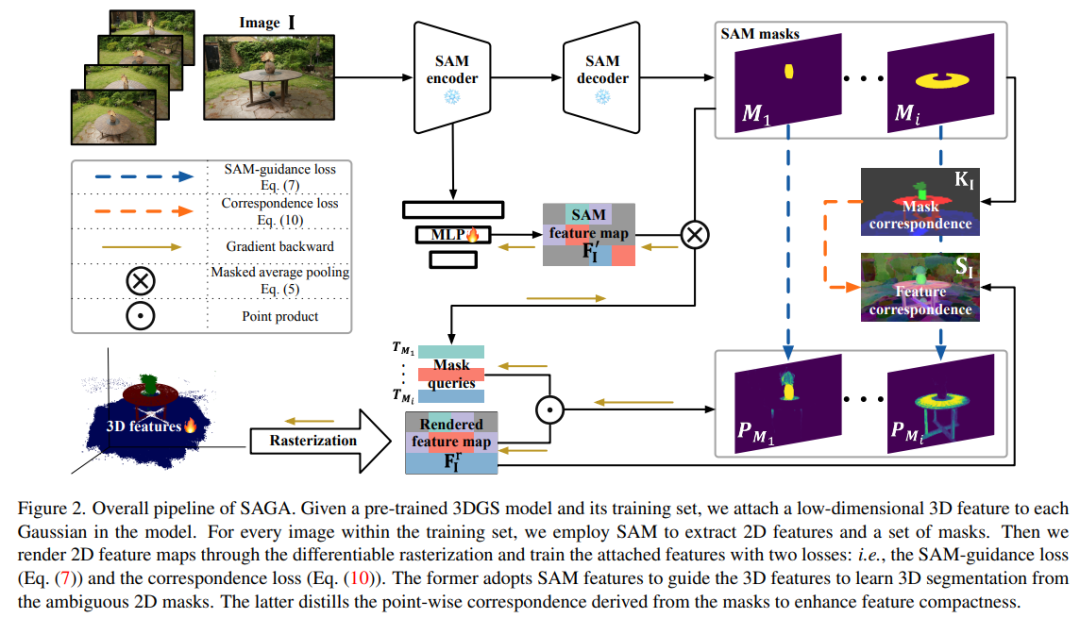
在推理阶段,对于具有相机姿态 v 的特定视图,研究者基于输入提示 P 来生成一组查询 Q。接着通过与学得的特征进行高效特征匹配,使用这些查询来检索对应目标的 3D 高斯。
此外,研究者还引入了一种高效的后处理操作,利用类点云结构的 3DGS 提供的强大 3D 先验来细化检索到的 3D 高斯。
高斯训练特征
给定一个具有特定相机姿态 v 的训练图像 I,研究者首先根据预训练的 3DGS 模型 来渲染对应的特征图。像素 p 的渲染后特征 F^r_I,p 计算为如下公式 (3)。
来渲染对应的特征图。像素 p 的渲染后特征 F^r_I,p 计算为如下公式 (3)。
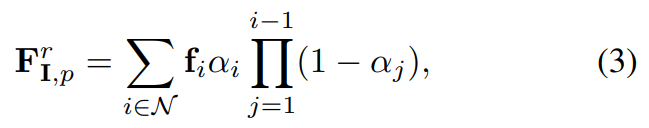
SAM 引导的损失。研究者提出使用 SAM 生成的特征来做引导。如上图 2 所示,他们首先采用一个 MLP φ,将 SAM 特征映射到与 3D 特征相同的低维空间。

对应关系损失。在实践中,研究者发现使用 SAM 引导损失学得的特征在紧凑性上不够,从而导致各种提示的分割质量下降。他们从以往的对比对应关系蒸馏方法中汲取灵感,提出用对应关系损失来解决问题。掩码对应关系 K_I (p1, p2) 定义如下公式(8)。
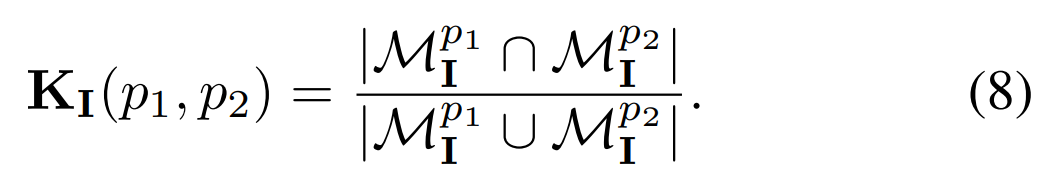
推理
3D 高斯的分割可以利用 2D 渲染的特征来实现。这一特性使得 SAGA 兼容了各种提示,包括点、涂鸦和掩码。此外基于 3DGS 提供的 3D 先验,研究者还引入了一种高效的后处理算法。
基于 3D 先验的后处理
3D 高斯的初始分割 存在两个问题,分别是存在多余的噪声高斯,缺少对目标对象至关重要的特定高斯。为了解决这两个问题,研究者利用了传统的点云分割技术,包括统计过滤和区域生长。
存在两个问题,分别是存在多余的噪声高斯,缺少对目标对象至关重要的特定高斯。为了解决这两个问题,研究者利用了传统的点云分割技术,包括统计过滤和区域生长。
对于基于点和涂鸦提示的分割,他们使用统计过滤来过滤掉噪声高斯。对于掩码提示和基于 SAM 的提示,他们分别将 2D 掩码映射到 和
和 上,前者得到一组验证后的高斯,后者消除不想要的高斯。
上,前者得到一组验证后的高斯,后者消除不想要的高斯。
所得到的验证后的高斯作为区域生成算法的种子(seed)。最后使用基于球查询的区域生长算法来从原始模型 中检索目标需要的所有高斯。
中检索目标需要的所有高斯。
实验评估
研究者在定量实验中使用了 NVOS(Neural Volumetric Object Selection)和 SPIn-NeRF 两个数据集,在定性实验中使用了 LLFF、MIP-360、T&T 和 LERF 数据集。此外他们使用 SA3D 来为 LERF-figurines 场景中的一些对象做注释,以展现 SAGA 能够取得更好的权衡效率和分割质量。
定量结果
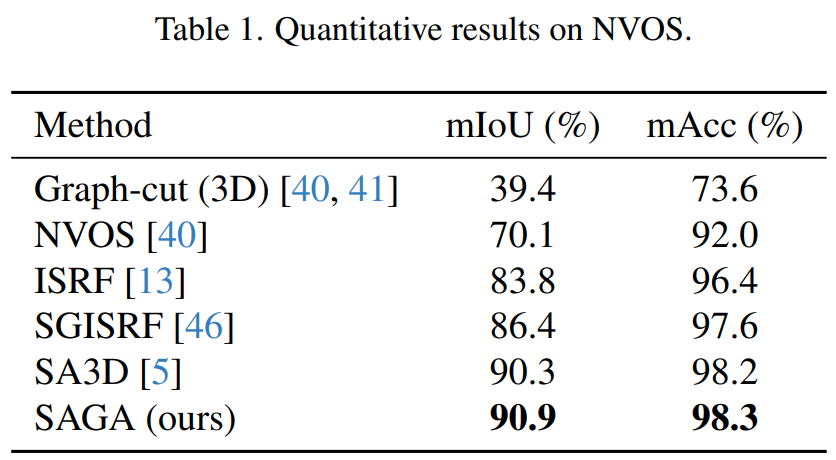
NVOS 数据集。研究者遵照 SA3D 的方法来处理 NVOS 数据集提供的涂鸦,以满足 SAM 的要求。结果如下表 1 所示,SAGA 能够媲美以往的 SOTA 方法 SA3D,并显著优于 ISRF 和 SGISRF 等以往基于特征模拟的方法,展现了自身的细粒度分割质量。
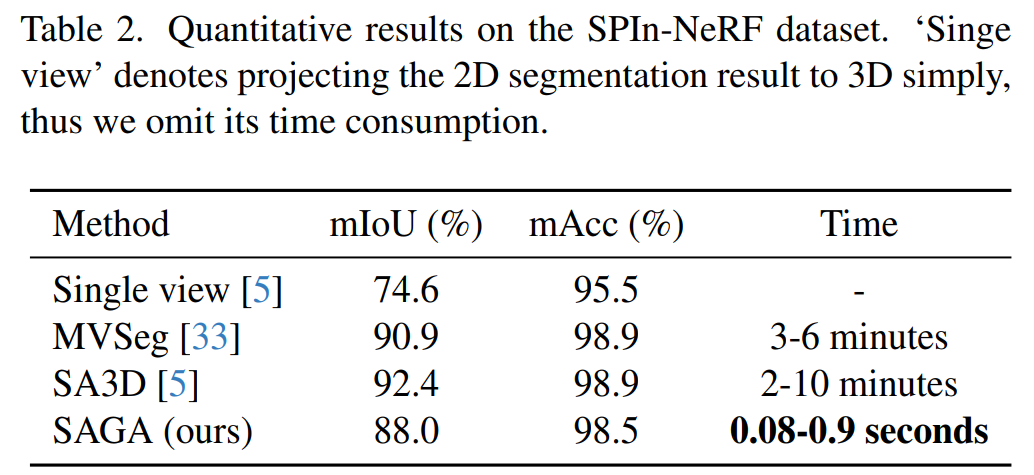
SPIn-NeRF 数据集。研究者遵照 SPIn-NeRF 方法来进行标签传播评估,其中指定了一个视图及它的 ground-truth 掩码,并将该掩码传播给其他视图以检查掩码的准确性,这一操作可以视为掩码提示。结果如下表 2 所示,SAGA 在仅用千分之一的时间便取得了与 MVSeg 和 SA3D 相当的性能。
与 SA3D 比较。为了进一步展示 SAGA 的有效性,研究者在分割时间和质量两个指标上与 SA3D 进行了比较。他们基于 LERF-figurines 场景运行 SA3D,为很多对象提供了一组注释。然后使用 SAGA 来分割相同的对象,并检查了每个对象的 IoU 和时间开销。结果如下表 3 所示,展示了 SAGA 可以使用更少的时间获得更高质量的 3D 资产。

定性结果
研究者首先确定了 SAGA 的分割精度与先前的 SOTA SA3D 相当,同时显著降低了时间成本。随后,他们展示了 SAGA 在部件和目标分割任务中比 ISRF 更强的性能。结果如图 3 所示。

第一行显示了 SA3D 和 SAGA 对 LERF-figurines 场景的分割结果,每个分割对象的右下方标注了分割时间;第二行比较了 SAGA 和 ISRF,后者通过模仿自监督视觉 transformer(如 DINO [4])提取的 2D 特征来训练特征字段;第三行展示了 MIP360-counter 和 T&T-truck 场景的其他分割结果。
在表 2 中有一些失败案例,与之前的 SOTA 方法相比,SAGA 的性能并不理想。这是因为 LLFF-room 场景的分割失败,暴露了 SAGA 的局限性。图 4 展示了彩色高斯平均值,它可以看作是一种点云,SAGA 容易受到 3DGS 模型几何重建不足的影响。

更多技术细节和实验结果请阅读原论文。
在CVer微信公众号后台回复:SAGA,即可下载论文pdf和代码链接!快学起来!
CVPR / ICCV 2023论文和代码下载
后台回复:CVPR2023,即可下载CVPR 2023论文和代码开源的论文合集
后台回复:ICCV2023,即可下载ICCV 2023论文和代码开源的论文合集- 图像分割交流群成立
- 扫描下方二维码,或者添加微信:CVer444,即可添加CVer小助手微信,便可申请加入CVer-图像分割 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer、NeRF等。
- 一定要备注:研究方向+地点+学校/公司+昵称(如图像分割+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
- ▲扫码或加微信号: CVer444,进交流群
- CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉(知识星球),已汇集近万人!
-
- ▲扫码加入星球学习
▲点击上方卡片,关注CVer公众号
整理不易,请点赞和在看
