
- 1李开复「关门弟子」创业!AI自动化助手一站式搞定,入局大模型的另一种选择...
- 2春招秋招笔试题记录_对于每组数据,输出一个整数,代表最少需要删除的字符个数。
- 3技术干货 | 到底什么是ASIC和FPGA?_fpga板卡 asic板卡
- 4基于朴素贝叶斯和预训练Bert模型的中文句子情感分类实践_bert 中文 情感分析
- 52024年最新版Anaconda3的安装配置及使用教程(非常详细),从零基础入门到精通,看完这一篇就够了(附安装包)_anconda3
- 6数据中台系列2:rabbitMQ 安装使用之 window 篇_rabbitmq-server-windows-3.12.4
- 7七天.NET 8操作SQLite入门到实战 - 第五天引入SQLite-net ORM并封装常用方法(SQLiteHelper)_.net8 sqlcipher
- 8el-upload上传单个图片显示缩略图_el-upload缩略图
- 9四足机器人并联腿足端轨迹Matlab仿真_并联腿的摆线运动
- 10VIVADO仿真数据保存_vivado vio数据保存
GLM国产大模型训练加速:性能最高提升3倍,显存节省1/3,低成本上手_glm大模型
赞
踩

作者|BBuf、谢子鹏、冯文
2017 年,Google 提出了 Transformer 架构,随后 BERT 、GPT、T5等预训练模型不断涌现,并在各项任务中都不断刷新 SOTA 纪录。去年,清华提出了 GLM 模型(https://github.com/THUDM/GLM),不同于上述预训练模型架构,它采用了一种自回归的空白填充方法, 在 NLP 领域三种主要的任务(自然语言理解、无条件生成、有条件生成)上都取得了不错的结果。
很快,清华基于 GLM 架构又推出了 GLM-130B(https://keg.cs.tsinghua.edu.cn/glm-130b/zh/posts/glm-130b/),这是一个开源开放的双语(中文和英文)双向稠密模型,拥有 1300 亿参数,在语言理解、语言建模、翻译、Zero-Shot 等方面都更加出色。
预训练模型的背后离不开开源深度学习框架的助力。在此之前,GLM 的开源代码主要是由 PyTorch、DeepSpeed 以及 Apex 来实现,并且基于 DeepSpeed 提供的数据并行和模型并行技术训练了 GLM-Large(335M),GLM-515M(515M),GLM-10B(10B)等大模型,这在一定程度上降低了 GLM 预训练模型的使用门槛。
即便如此,对更广大范围的普通用户来说,训练 GLM 这样的模型依然令人头秃,同时,预训练模型的性能优化还有更大的提升空间。
为此,我们近期将原始的 GLM 项目移植到了使用 OneFlow 后端进行训练的 One-GLM 项目。得益于 OneFlow 和 PyTorch 无缝兼容性,我们快速且平滑地移植了 GLM,并成功跑通了预训练任务(训练 GLM-large)。
此外,由于 OneFlow 原生支持 DeepSpeed 和 Apex 的很多功能和优化技术,用户不再需要这些插件就可训练 GLM 等大模型。更重要的是,针对当前 OneFlow 移植的 GLM 模型,在简单调优后就能在性能以及显存占用上有大幅提升。
具体是怎么做到的?下文将进行揭晓。
-
One-GLM:https://github.com/Oneflow-Inc/one-glm
-
OneFlow:https://github.com/Oneflow-Inc/oneflow
1
GLM-large 训练性能和显存的表现
首先先展示一下分别使用官方的 GLM 仓库以及 One-GLM 仓库训练 GLM-large 网络的性能和显存表现(数据并行技术),硬件环境为 A100 PCIE 40G,BatchSize 设置为 8。
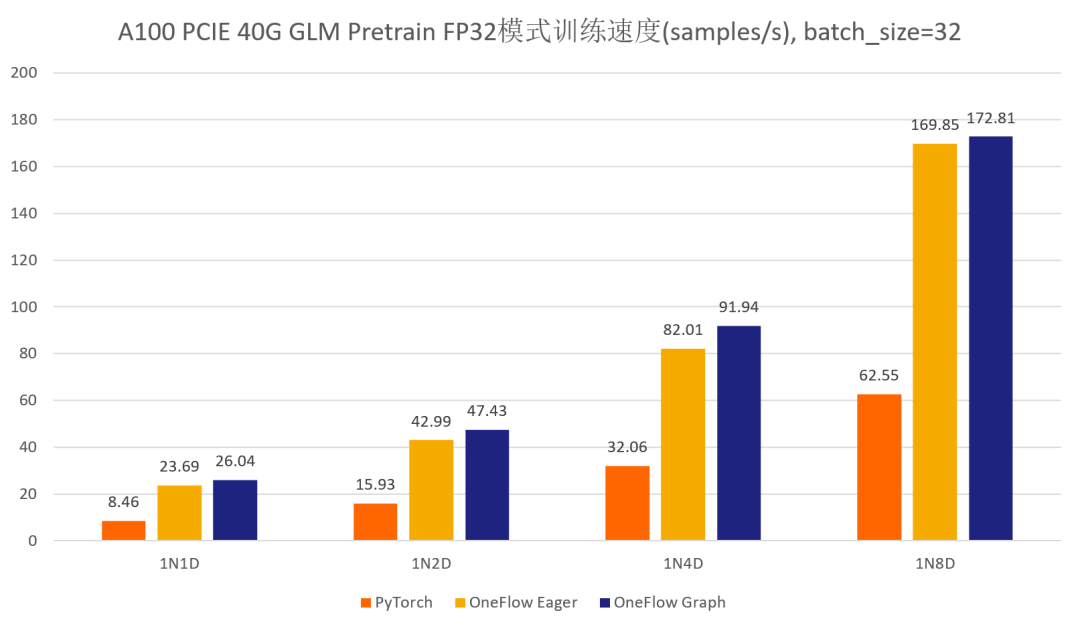
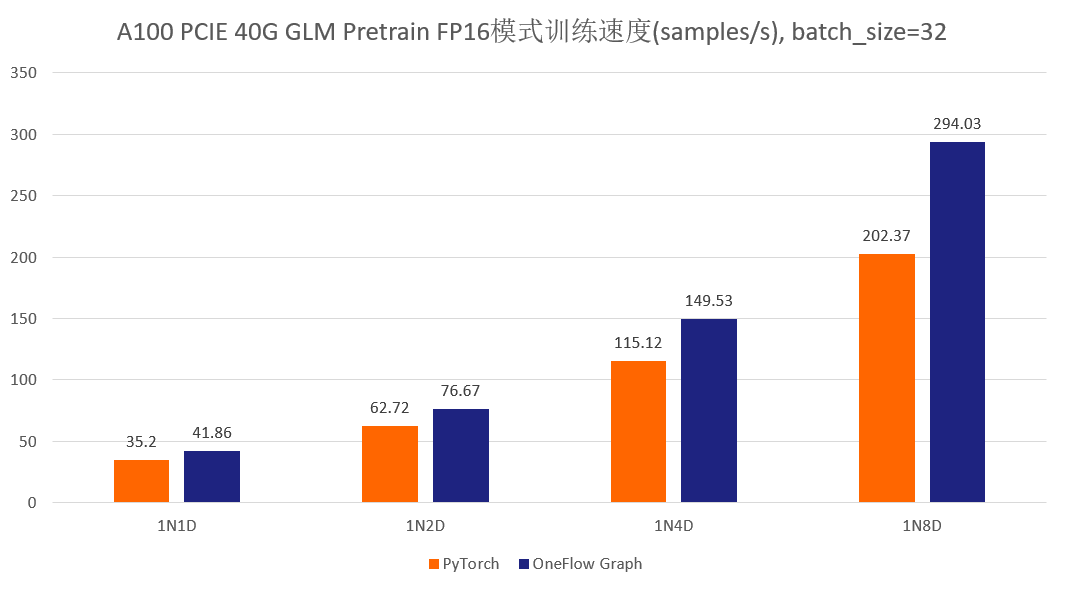
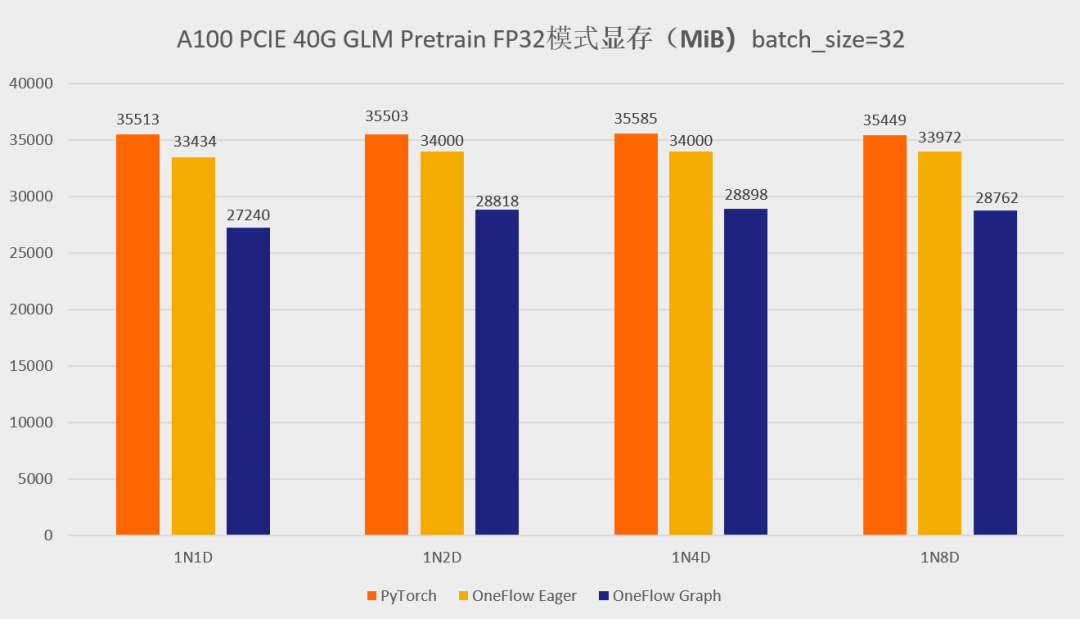
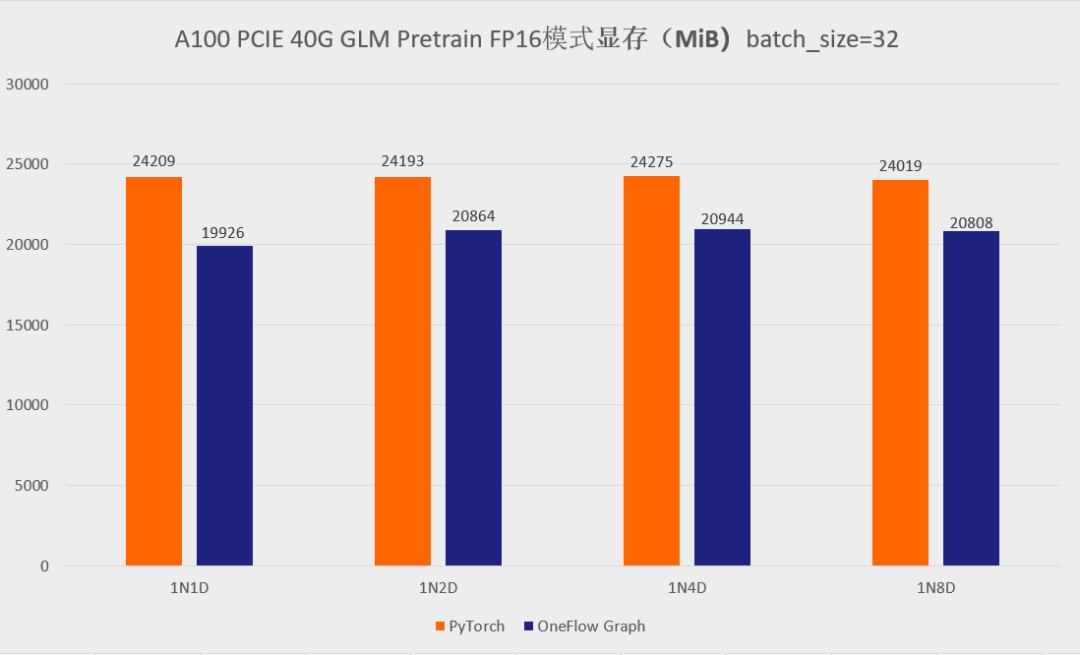
可以看到,在 GLM-large 的训练任务中,相比原始的基于 PyTorch、DeepSpeed、Apex 的 GLM 实现,OneFlow的性能有 120% - 276% 的加速,并且显存占用降低了10% -30%(测试结果均可用 oneflow >=0.9.0 复现)。
2
GLM 迁移,只需修改几行代码
由于 OneFlow 无缝兼容了 PyTorch 的生态,只需改动几行代码,就可以让用户轻松迁移 GLM 大模型到 One-GLM:
-
将 import torch 替换为 import oneflow as torch

